pytorch01——pytorch并行计算
并行计算
在利用pytorch做深度学习的过程中,可能会遇到数据量较大,无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。
1.为什么要做并行计算?
我们学习pytorch的目的是可以编写我们自己的框架,来完成特定地任务。可以说在深度学习时代,GPU的出现让我们可以训练的更快,更好。所以,如何充分利用GPU的性能来提高我们模型学习的效果,这就需要学习pytorch的并行计算。pytorch可以在编写完模型之后,让多个GPU来参与训练。
2.CUDA是个啥
CUDA是我们使用GPU的提供商——NVIDIA提供的GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。但是,在我们使用PyTorch编写深度学习代码时,使用的CUDA又是另一个意思。在PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 cuda() 时,其功能是让我们的模型或者数据迁移到GPU当中,通过GPU开始计算。
3.目前采用的并行计算方案
不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
它的逻辑是,我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。其架构如下:
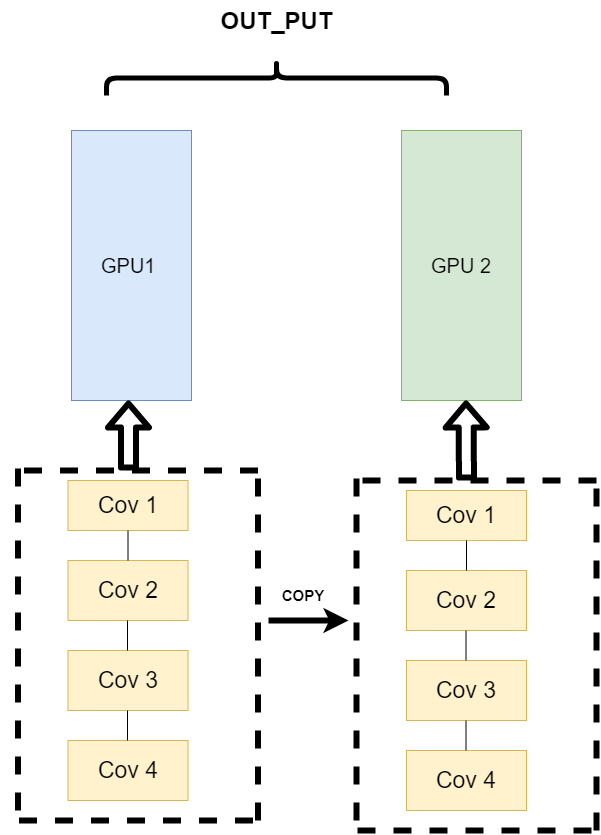
这种方式可以解决之前模式遇到的通讯问题。
PS:现在的主流方式是数据并行的方式(Data parallelism)
本文来自博客园,作者:TCcjx,转载请注明原文链接:https://www.cnblogs.com/tccjx/articles/15985110.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号