
爬虫_pandas
Pandas 安装
安装 pandas 需要基础环境是 Python,开始前我们假定你已经安装了 Python 和 Pip。
使用 pip 安装 pandas:
pip install pandas
实例1
mydataset = {
'sites': ["Google", "Runoob", "Wiki"],
'number': [1, 2, 3]
}
myvar = pd.DataFrame(mydataset)
print(myvar)
Pandas 数据结构 - Series
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
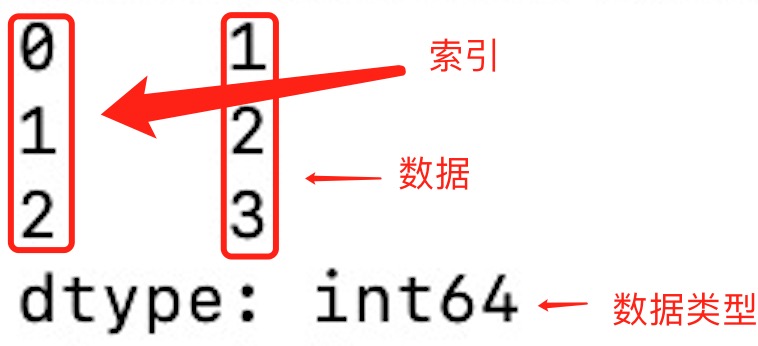
实例
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
输出结果如下:
实例
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
输出结果如下:

实例
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
输出结果如下:

实例
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

Pandas 数据结构 - DataFrame
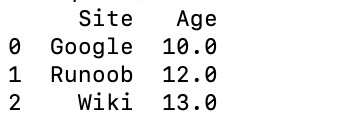
实例 - 使用列表创建
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
输出结果如下:
实例 - 使用 ndarrays 创建
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
输出结果如下:
实例 - 使用字典创建
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
输出结果为:
a b c 0 1 2 NaN 1 5 10 20.0
实例
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
输出结果如下:
calories 420 duration 50 Name: 0, dtype: int64 calories 380 duration 40 Name: 1, dtype: int64
实例
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])
输出结果为:
calories duration
0 420 50
1 380 40
实例
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)
输出结果为:
calories duration day1 420 50 day2 380 40 day3 390 45
实例
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.loc["day2"])
输出结果为:
calories 380
duration 40
Name: day2, dtype: int64
Pandas CSV 文件
实例
df = pd.read_csv('nba.csv')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
实例
df = pd.read_csv('nba.csv')
print(df)
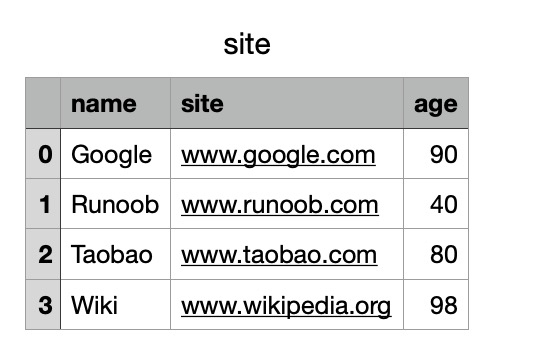
实例
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
执行成功后,我们打开 site.csv 文件,显示结果如下:
数据处理
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
head()
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
实例 - 读取前面 5 行
df = pd.read_csv('nba.csv')
print(df.head())
info()
info() 方法返回表格的一些基本信息:
实例
df = pd.read_csv('nba.csv')
print(df.info())
Pandas JSON
实例
实例
df = pd.read_json('sites.json')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
实例
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
以上实例输出结果为:
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
JSON 对象与 Python 字典具有相同的格式,所以我们可以直接将 Python 字典转化为 DataFrame 数据:
实例
# 字典格式的 JSON
s = {
"col1":{"row1":1,"row2":2,"row3":3},
"col2":{"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
以上实例输出结果为:
col1 col2
row1 1 x
row2 2 y
row3 3 z
从 URL 中读取 JSON 数据:
实例
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df)
以上实例输出结果为:
id name url likes
0 A001 菜鸟教程 www.runoob.com 61
1 A002 Google www.google.com 124
2 A003 淘宝 www.taobao.com 45
内嵌的 JSON 数据
假设有一组内嵌的 JSON 数据文件 nested_list.json :
nested_list.json 文件内容
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
使用以下代码格式化完整内容:
实例
df = pd.read_json('nested_list.json')
print(df)
以上实例输出结果为:
school_name class students
0 ABC primary school Year 1 {'id': 'A001', 'name': 'Tom', 'math': 60, 'phy...
1 ABC primary school Year 1 {'id': 'A002', 'name': 'James', 'math': 89, 'p...
2 ABC primary school Year 1 {'id': 'A003', 'name': 'Jenny', 'math': 79, 'p...
这时我们就需要使用到 json_normalize() 方法将内嵌的数据完整的解析出来:
实例
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(data, record_path =['students'])
print(df_nested_list)
以上实例输出结果为:
id name math physics chemistry
0 A001 Tom 60 66 61
1 A002 James 89 76 51
2 A003 Jenny 79 90 78
data = json.loads(f.read()) 使用 Python JSON 模块载入数据。
json_normalize() 使用了参数 record_path 并设置为 ['students'] 用于展开内嵌的 JSON 数据 students。
显示结果还没有包含 school_name 和 class 元素,如果需要展示出来可以使用 meta 参数来显示这些元数据:
实例
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path =['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
以上实例输出结果为:
id name math physics chemistry school_name class
0 A001 Tom 60 66 61 ABC primary school Year 1
1 A002 James 89 76 51 ABC primary school Year 1
2 A003 Jenny 79 90 78 ABC primary school Year 1
接下来,让我们尝试读取更复杂的 JSON 数据,该数据嵌套了列表和字典,数据文件 nested_mix.json 如下:
nested_mix.json 文件内容
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "admin@e.com",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
nested_mix.json 文件转换为 DataFrame:
实例
import json
# 使用 Python JSON 模块载入数据
with open('nested_mix.json','r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path =['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df)
以上实例输出结果为:
id name math physics chemistry class info.president info.contacts.tel
0 A001 Tom 60 66 61 Year 1 John Kasich 123456789
1 A002 James 89 76 51 Year 1 John Kasich 123456789
2 A003 Jenny 79 90 78 Year 1 John Kasich 123456789
读取内嵌数据中的一组数据
以下是实例文件 nested_deep.json,我们只读取内嵌中的 math 字段:
nested_deep.json 文件内容
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
这里我们需要使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性。
第一次使用我们需要安装 glom:
pip3 install glom
实例
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
以上实例输出结果为:
0 60
1 89
2 79
Name: students, dtype: int64
Pandas 数据清洗
我们可以通过 isnull() 判断各个单元格是否为空。
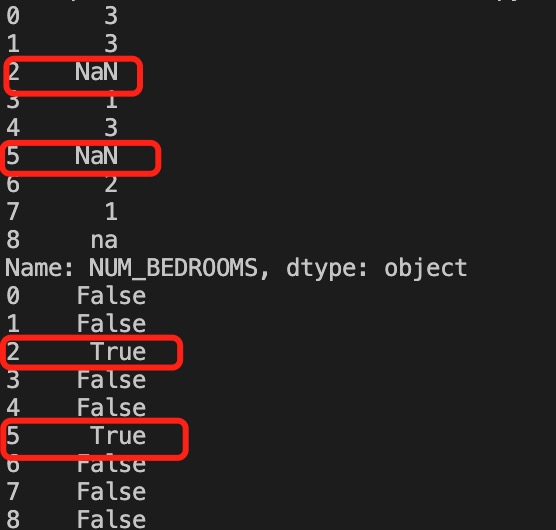
实例
df = pd.read_csv('property-data.csv')
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
以上实例输出结果如下:
以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
实例
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
以上实例输出结果如下:
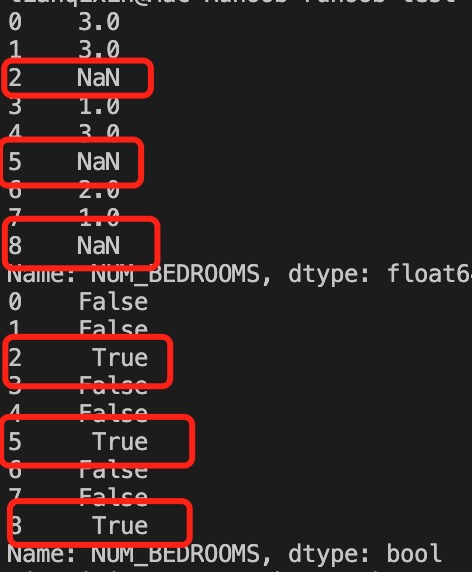
接下来的实例演示了删除包含空数据的行。
实例
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())
以上实例输出结果如下:

注意:默认情况下,dropna() 方法返回一个新的 DataFrame,不会修改源数据。
如果你要修改源数据 DataFrame, 可以使用 inplace = True 参数:
实例
df = pd.read_csv('property-data.csv')
df.dropna(inplace = True)
print(df.to_string())
以上实例输出结果如下:
我们也可以移除指定列有空值的行:
实例
移除 ST_NUM 列中字段值为空的行:
df = pd.read_csv('property-data.csv')
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
以上实例输出结果如下:
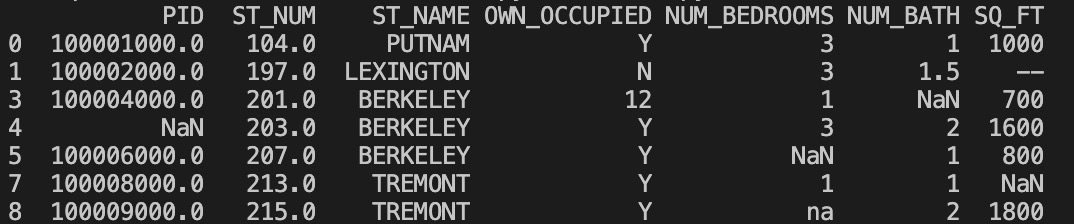
我们也可以 fillna() 方法来替换一些空字段:
实例
使用 12345 替换空字段:
df = pd.read_csv('property-data.csv')
df.fillna(12345, inplace = True)
print(df.to_string())
以上实例输出结果如下:
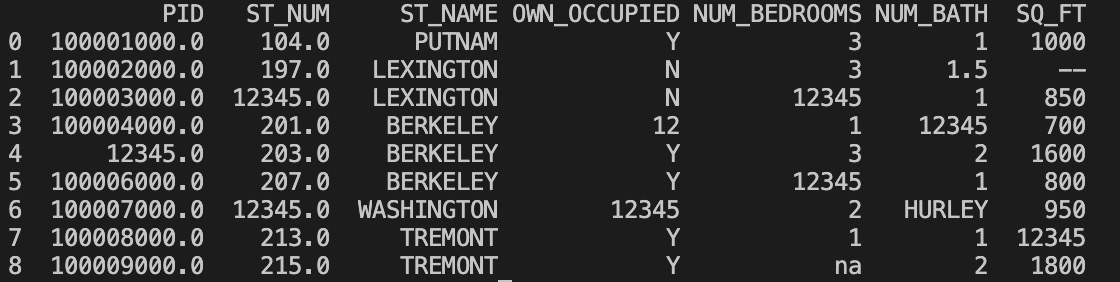
我们也可以指定某一个列来替换数据:
实例
使用 12345 替换 PID 为空数据:
df = pd.read_csv('property-data.csv')
df['PID'].fillna(12345, inplace = True)
print(df.to_string())
以上实例输出结果如下:
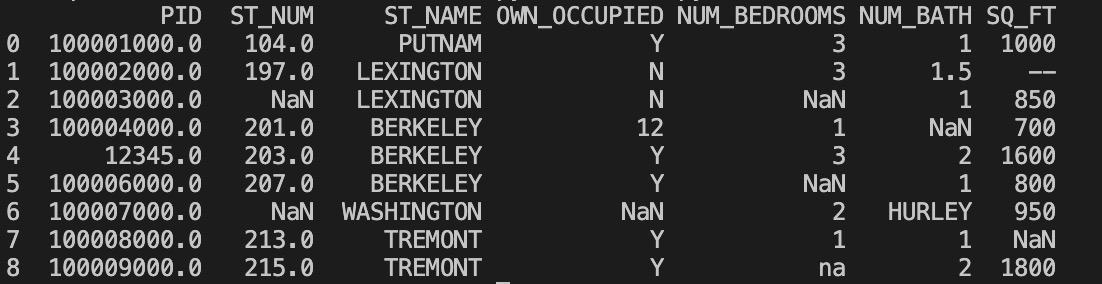
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
实例
使用 mean() 方法计算列的均值并替换空单元格:
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mean()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
以上实例输出结果如下,红框为计算的均值替换来空单元格:
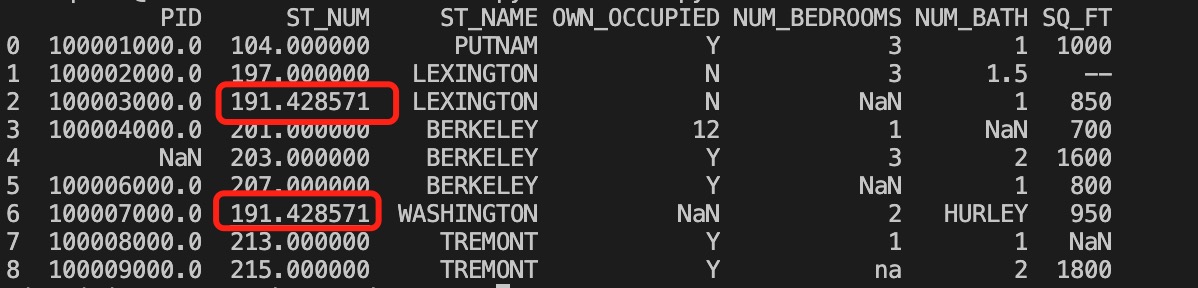
实例
使用 median() 方法计算列的中位数并替换空单元格:
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].median()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
以上实例输出结果如下,红框为计算的中位数替换来空单元格:
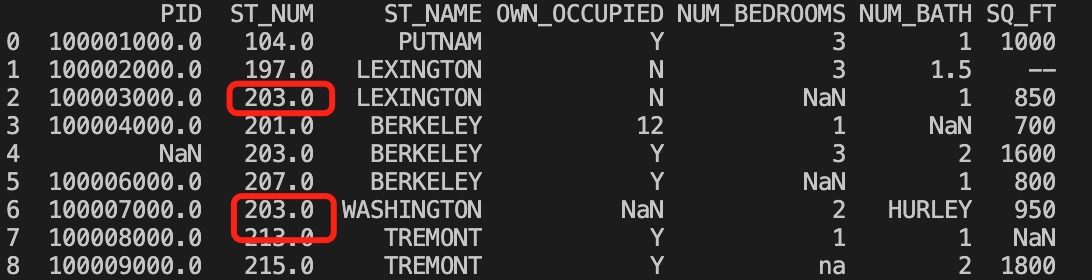
实例
使用 mode() 方法计算列的众数并替换空单元格:
df = pd.read_csv('property-data.csv')
x = df["ST_NUM"].mode()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
以上实例输出结果如下,红框为计算的众数替换来空单元格:
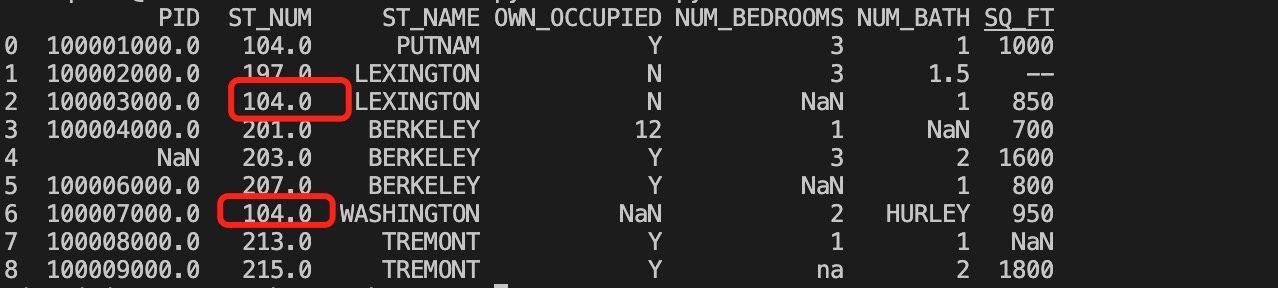
Pandas 清洗格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能。
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
以下实例会格式化日期:
实例
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
以上实例输出结果如下:
Date duration
day1 2020-12-01 50
day2 2020-12-02 40
day3 2020-12-26 45
Pandas 清洗错误数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
以下实例会替换错误年龄的数据:
实例
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
df.loc[2, 'age'] = 30 # 修改数据
print(df.to_string())
以上实例输出结果如下:
name age
0 Google 50
1 Runoob 40
2 Taobao 30
也可以设置条件语句:
实例
将 age 大于 120 的设置为 120:
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
print(df.to_string())
以上实例输出结果如下:
name age
0 Google 50
1 Runoob 120
2 Taobao 120
也可以将错误数据的行删除:
实例
将 age 大于 120 的删除:
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 40, 12345] # 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace = True)
print(df.to_string())
以上实例输出结果如下:
name age
0 Google 50
1 Runoob 40
Pandas 清洗重复数据
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
实例
person = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
print(df.duplicated())
以上实例输出结果如下:
0 False
1 False
2 True
3 False
dtype: bool
删除重复数据,可以直接使用drop_duplicates() 方法。
实例
persons = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(persons)
df.drop_duplicates(inplace = True)
print(df)
以上实例输出结果如下:
name age
0 Google 50
1 Runoob 40
3 Taobao 23


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义