
乘风破浪,遇见最佳跨平台跨终端框架.Net Core/.Net生态 - 浅析ASP.NET Core领域驱动设计,通过MediatR中介者模式实现CQRS和领域事件
什么是领域驱动设计
领域驱动设计(Domain-Driven Design, DDD)是一套原则和模式的集合,它帮助开发者制作优雅的对象系统。

领域驱动设计(DDD)是一种主要的软件设计方法,专注于根据领域专家的意见对软件进行建模以匹配该领域。
在领域驱动设计下,软件代码的结构和语言(类名、类方法、类变量)应该与业务领域相匹配。例如,如果软件处理贷款申请,它可能有像LoanApplication和Customer这样的类,以及像AcceptOffer和Withdraw这样的方法。
领域驱动的设计是以下列目标为前提的。
- 将项目的主要重点放在核心领域和领域逻辑上。
- 将复杂的设计建立在领域模型的基础上。
- 发起技术专家和领域专家之间的创造性合作,反复完善解决特定领域问题的概念模型。
对领域驱动设计的批评认为,开发人员通常必须实现大量的隔离和封装,以保持模型的纯粹和有用的构造。虽然领域驱动设计提供了诸如可维护性等好处,但微软只推荐给复杂的领域,在这些领域中,模型在制定领域的共同理解方面提供了明显的好处。
这个术语是由Eric Evans在他2003年出版的同名书籍中创造的。
概述
领域驱动设计阐明了一些高层次的概念和实践。
其中最重要的是领域,用户应用程序的主题领域就是软件的领域。一个软件的领域支配着它的上下文,即一个词或语句出现的环境,决定了它的意义。由此,开发者建立了一个领域模型:一个抽象的系统,它描述了一个领域的选定方面,可以用来解决与该领域有关的问题。
领域驱动设计的这些方面旨在促进无所不在的语言,也就是说,领域模型应该形成一种由领域专家描述系统需求、商业用户、赞助商和开发者共享的通用语言。
在领域驱动设计中,领域层是面向对象的多层结构中的一个普通层。
模型的种类
领域驱动的设计承认多种类型的模型。
例如,一个实体是一个不是由其属性,而是由其身份定义的对象。举个例子,大多数航空公司为每个航班的座位分配一个唯一的号码:这就是座位的身份。
相比之下,价值对象是一个不可改变的对象,它包含属性但没有概念上的身份。例如,当人们交换名片时,他们只关心名片上的信息(其属性),而不是试图区分每张独特的名片。
模型也可以定义事件(过去发生的事情)。领域事件是领域专家所关心的事件。
模型可以被一个根实体绑定在一起,成为一个聚合体。聚合体之外的对象可以持有对根的引用,但不能持有对聚合体中任何其他对象的引用。聚合根检查聚合中变化的一致性。例如,司机不需要单独控制汽车的每个车轮:他们只需驾驶汽车。在这种情况下,汽车是其他几个对象(发动机、刹车、大灯等)的集合。
与模型一起工作
在领域驱动的设计中,一个对象的创建往往与对象本身是分开的。
例如,一个存储库是一个具有从数据存储(如数据库)中检索领域对象的方法的对象。同样地,工厂是一个具有直接创建领域对象方法的对象。
当一个程序的部分功能在概念上不属于任何对象时,它通常被表达为一个服务。
与其他想法的关系
尽管领域驱动设计本身并不与面向对象的方法相联系,但在实践中,它利用了这些技术的优势。其中包括实体/聚合根作为命令/方法调用的接收者,在最重要的聚合根中封装状态,以及在更高的架构层面上,有边界的上下文。
因此,领域驱动设计经常与Plain Old Java Objects和Plain Old CLR Objects联系起来。虽然从技术上讲,这些术语分别是针对Java和.NET框架的技术实现细节,但它们反映了一种日益增长的观点,即领域对象应该纯粹由领域的业务行为来定义,而不是由更具体的技术框架来定义。
同样地,裸露的对象模式认为,用户界面可以简单地反映足够好的领域模型。要求用户界面是领域模型的直接反映,将迫使设计出更好的领域模型。
领域驱动的设计已经影响到了其他的软件开发方法。
例如,特定领域的建模,就是用特定领域的语言来进行领域驱动设计。领域驱动设计并不特别要求使用特定领域的语言,尽管它可以用来帮助定义特定领域的语言并支持特定领域的多模型。
反过来,面向方面的编程使得从领域模型中剔除技术问题(如安全、事务管理、日志)变得容易,让他们纯粹地关注业务逻辑。
模型驱动的工程和架构(Model-driven engineering and architecture)
虽然领域驱动设计与模型驱动工程和架构是兼容的,但这两个概念背后的意图是不同的。模型驱动的架构更关注于将模型转化为不同技术平台的代码,而不是定义更好的领域模型。
然而,模型驱动工程所提供的技术(对领域进行建模,创建特定领域的语言以促进领域专家和开发者之间的交流......)促进了实践中的领域驱动设计,并帮助从业者从他们的模型中获得更多。由于模型驱动工程的模型转换和代码生成技术,领域模型可以用来生成管理它的实际软件系统。
命令查询责任隔离(Command Query Responsibility Segregation)
命令查询责任隔离(Command Query Responsibility Segregation, CQRS)是一种将读取数据("查询")和写入数据("命令")分开的架构模式。CQRS源于Greg Young所创造的命令和查询分离(CQS)。
命令会改变状态,大约等同于对聚合根或实体的方法调用。查询读取状态,但不改变它。
虽然CQRS不需要领域驱动的设计,但它通过聚合根的概念使命令和查询之间的区别变得明确。这个想法是,一个给定的聚合根有一个与命令相对应的方法,命令处理程序在聚合根上调用这个方法。
聚合根负责执行操作的逻辑,并产生一些事件,一个失败的响应,或者只是突变自己的状态,可以写入数据存储中。命令处理程序将与保存聚合根的状态和创建所需的上下文(例如,事务)有关的基础设施拉进来。
事件源(Event sourcing)
事件源(Event sourcing)是一种架构模式,其中实体不通过直接序列化或对象关系映射来跟踪其内部状态,而是通过读取和提交事件到事件存储。
当事件源与CQRS和领域驱动设计相结合时,聚合根负责验证和应用命令(通常是通过从命令处理程序调用其实例方法),然后发布事件。这也是聚合根处理方法调用的逻辑的基础。因此,输入是一个命令,输出是一个或多个事件,这些事件被保存到一个事件存储区,然后经常在消息代理上发布给那些感兴趣的人(如应用程序的视图)。
对输出事件的聚合根进行建模,可以比从实体中投射读数据时更进一步地隔离内部状态,就像在标准的N层数据传递架构中一样。一个显著的好处是,公理定理证明器(例如微软的Contracts和CHESS)更容易应用,因为聚合根全面地隐藏了其内部状态。事件通常基于聚合根实例的版本而被持久化,这就产生了一个通过乐观的并发性在分布式系统中同步的领域模型。
为什么需要它
2003年,Eric Evan出版了第一本名为《解决软件核心的复杂性(Tackling Complexity in the Heart of Software)》的书,为DDD带来了第一批概念。此后,该模式的受欢迎程度呈指数级增长。许多软件开发团队、企业或组织都应用了这种模式,并在软件开发方面取得了巨大的成功。像微软这样的几个科技巨头也没有脱离这种趋势,他们提到了领域驱动设计,具体如下。
"领域驱动设计(DDD)主张根据与你的用例相关的现实业务进行建模。在构建应用程序的背景下,DDD把问题当作领域来谈。它将独立的问题领域描述为边界上下文(每个边界上下文都与一个微服务相关),并强调用一种共同的语言来谈论这些问题。它还提出了许多技术概念和模式,如具有丰富模型的领域实体(没有贫血的领域模型)、价值对象、聚合和聚合根(或根实体)规则,以支持内部实施...."
DDD是一种以业务为中心的软件开发方法。在软件开发和维护过程中发生的问题和挑战大多来自于业务的不断增长。因此,DDD有助于将软件开发与业务模式的演变紧密联系起来。
DDD有助于解决构建复杂系统的问题。这种模式要求架构师、开发人员和领域专家首先准确理解需求。然后,他们定义行为,理解规则,将原则和业务逻辑应用于条款集(抽象、接口等)。接下来,工程师将在其他层(如应用层、基础设施层)实现它们。如今,DDD被设定为开发不同流行架构的标准,如洋葱架构、清洁架构、六边形架构等。
在深入了解细节之前,我们将解释领域驱动设计的一些优点和缺点,以帮助你了解这种模式是否很适合你的项目。
DDD微服务中的分层设计
大多数具有重大业务和技术复杂性的企业应用都是由多个层定义的。这些层是一个逻辑工件,与服务的部署没有关系。它们的存在是为了帮助开发人员管理代码中的复杂性。不同的层(如领域模型层与表现层等)可能有不同的类型,这就要求在这些类型之间进行翻译。
例如,一个实体可以从数据库中加载。然后,该信息的一部分,或包括来自其他实体的额外数据的信息聚合,可以通过REST Web API发送到客户端UI。这里的重点是,领域实体包含在领域模型层中,不应该被传播到其他不属于它的区域,比如说表现层。
此外,你需要有始终有效的实体(见领域模型层中的设计验证部分),由聚合根(根实体)控制。因此,实体不应该被绑定到客户端视图,因为在UI层,一些数据可能仍然没有被验证。这个原因就是ViewModel的作用。ViewModel是一个专门针对表现层需求的数据模型。领域实体并不直接属于ViewModel。相反,你需要在ViewModel和领域实体之间进行转换,反之亦然。
在处理复杂性问题时,重要的是要有一个由聚合根控制的领域模型,确保所有与该组实体(聚合)有关的不变性和规则都是通过一个入口或门,即聚合根来执行的。
分层设计是如何在eShopOnContainers应用程序中实现的。
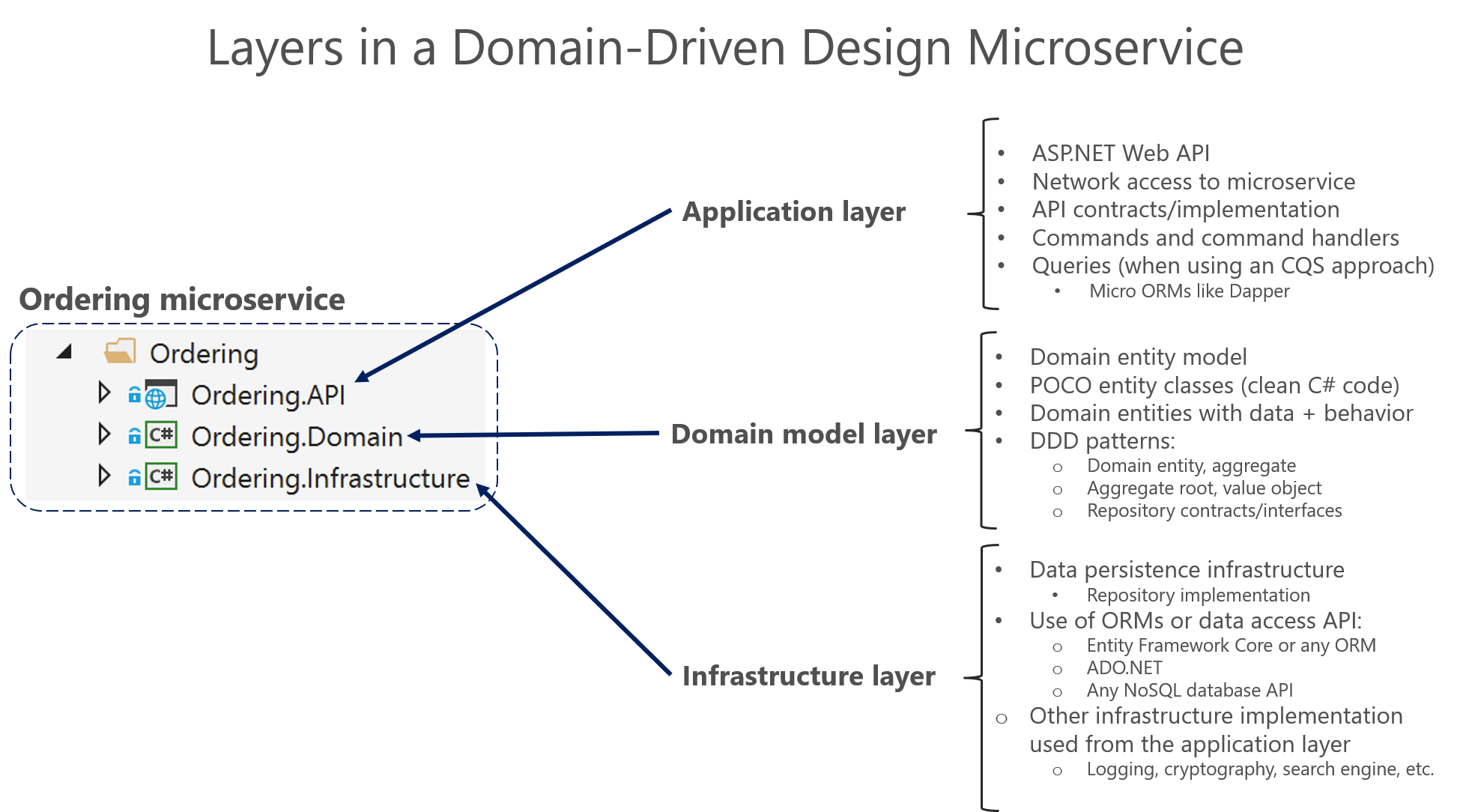
像订购这样的DDD微服务中的三层。每一层都是一个VS项目。应用层是Ordering.API,领域层是Ordering.Domain,基础设施层是Ordering.Infrastructure。你想设计这个系统,使每一层只与某些其他层进行通信。如果各层被实现为不同的类库,这种方法可能更容易执行,因为你可以清楚地识别库之间设置了哪些依赖关系。例如,领域模型层不应该依赖任何其他层(领域模型类应该是Plain Old Class Objects,或POCO,类)。
Ordering.Domain层库只对.NET库或NuGet包有依赖关系,而对其他任何自定义库,如数据库或持久化库没有依赖关系。

作为库实现的层允许更好地控制层之间的依赖关系
领域模型层(The domain model layer)
Eric Evans的优秀著作《领域驱动设计》对领域模型层和应用层有如下论述。
领域模型层,负责表示业务的概念、关于业务情况的信息和业务规则。反映业务情况的状态在这里被控制和使用,尽管存储它的技术细节被委托给了基础设施。这一层是商业软件的核心。
领域模型层是表达业务的地方。当你在.NET中实现一个微服务领域模型层时,该层被编码为一个类库,其中有捕捉数据的领域实体加上行为(有逻辑的方法)。
遵循无视持久性(Persistence Ignorance)和无视基础设施(Infrastructure Ignorance)的原则,该层必须完全忽略数据的持久性细节。这些持久化任务应该由基础设施层来完成。因此,这一层不应该直接依赖基础设施,这意味着一个重要的规则是,你的领域模型实体类应该是POCOs。
领域实体不应该对任何数据访问基础设施框架(如Entity Framework或NHibernate)有任何直接依赖(如从基类派生)。理想情况下,你的领域实体不应该派生或实现任何基础设施框架中定义的任何类型。
大多数现代ORM框架,如Entity FrameworkCore,都允许这种做法,这样你的领域模型类就不会被耦合到基础设施上。然而,在使用某些NoSQL数据库和框架(如Azure Service Fabric中的Actors和Reliable Collections)时,拥有POCO实体并不总是可能的。
即使对你的领域模型遵循无视持久性原则很重要,你也不应该忽视持久性问题。了解物理数据模型以及它如何映射到你的实体对象模型仍然很重要。否则,你会创造出不可能的设计。
另外,这一方面并不意味着你可以把为关系型数据库设计的模型直接移到NoSQL或面向文档的数据库中。在某些实体模型中,该模型可能适合,但通常情况下,它不适合。在存储技术和ORM技术的基础上,你的实体模型仍然有必须遵守的约束。
无视持久性(Persistence Ignorance)
无视持久性原则(PI)认为,在软件应用中对业务领域进行建模的类不应该受到它们如何被持久化的影响。因此,它们的设计应该尽可能地反映出解决手头业务问题所需的理想设计,而不应该被与对象的状态如何被保存和随后被检索有关的问题所污染。一些常见的违反持久性知识的行为包括领域对象必须继承于特定的基类,或者必须暴露某些属性。有时,持久性知识的形式是必须应用于类的属性,或只支持某些类型的集合或属性的可见性水平。持久性无知有不同的程度,最高的程度被描述为.NET中的Plain Old CLR Objects(POCOs),以及Java世界中的Plain Old Java Objects(POJOs)。
无视基础设施(Infrastructure Ignorance)
最近,在ALT.Net邮件列表中,有一个关于自动嘲弄容器的长期讨论。我们在那里讨论了很多内容,而且很有意思。
我想谈的是这个讨论的内容。不久前,有一个关于持久性无知的大棒。我不会重申这些论点,但我想把这个想法也扩展到其他概念。你的代码不应该只对持久性一无所知,它是所有基础设施的总体关注。
我不在乎你的基础设施代码有多好,它仍然是技术性的讨厌的陷阱。我知道我所有的代码都是这样的。
你使用的IoC容器不应该出现在你代码的任何地方,持久性问题也不应该把自己和实际的代码混在一起。侵入性的方法,不管他们做什么,都应该被反对。

很多人认为下面的模型是一个不错的选择。
我个人认为,它太强调基础设施了。基础设施不应该位于应用程序的核心。它应该被推到一些被忽视的角落,只有在没有其他选择的情况下才会出现在阳光下。
下图显示了我认为应该是这样的。

实际的应用程序代码应该比基础设施代码有更大的权重,只有在定义好的位置才会有领域服务调用到基础设施上。事实上,我希望尽可能地将其隔离。依赖注入、AOP和少量的包装应该可以让你得到一个对基础设施无知的应用。
这样做的直接结果是,你会得到更多关于实际业务价值的关注,而不是使用FAT12文件系统实现的两阶段提交。
这并不是说基础设施不重要,它是极其重要的。但是,基础设施不应该是侵入性的。
应用层(The application layer)
进入应用层,我们可以再次引用Eric Evans的书《领域驱动设计》。
应用层,定义了软件应该做的工作,并指导表达式领域对象去解决问题。这一层所负责的工作对业务有意义,或者对与其他系统的应用层的交互有必要。这一层被保持得很薄。它不包含业务规则或知识,而只是协调任务并将工作委托给下一层的领域对象的协作。它没有反映业务情况的状态,但它可以有反映用户或程序的任务进展的状态。
.NET中微服务的应用层通常被编码为ASP.NET Core Web API项目。该项目实现了微服务的交互、远程网络访问,以及从用户界面或客户端应用程序使用的外部Web API。如果使用CQRS方法,它包括查询,微服务接受的命令,甚至微服务之间的事件驱动的通信(集成事件)。代表应用层的ASP.NET Core Web API不得包含业务规则或领域知识(尤其是交易或更新的领域规则);这些应该由领域模型类库拥有。应用层必须只协调任务,不能持有或定义任何领域状态(领域模型)。它将业务规则的执行委托给领域模型类本身(聚合根和领域实体),这将最终更新这些领域实体中的数据。
基本上,应用逻辑是你实现所有依赖于特定前端的用例的地方。例如,与Web API服务相关的实现。
我们的目标是,领域模型层中的领域逻辑、其不变性、数据模型和相关的业务规则必须完全独立于表现层和应用层。最重要的是,领域模型层必须不直接依赖于任何基础设施框架。
基础设施层(The infrastructure layer)
基础设施层是如何将最初保存在领域实体中的数据(在内存中)持久化在数据库或其他持久化存储中。一个例子是使用Entity FrameworkCore代码来实现Repository模式的类,这些类使用DBContext来持久化关系数据库中的数据。
根据前面提到的无视持久性和无视基础设施的原则,基础设施层不能"污染"领域模型层。你必须保持领域模型实体类与你用来持久化数据的基础设施(EF或任何其他框架)不相干,不要对框架产生硬性依赖。你的领域模型层类库应该只有你的领域代码,只有实现你的软件核心的POCO实体类,并与基础设施技术完全解耦。
因此,你的层或类库和项目最终应该依赖于你的领域模型层(库),而不是反过来。

DDD中各层之间的依赖关系
在DDD服务中的依赖关系,应用层依赖于领域和基础设施,基础设施依赖于领域,但领域不依赖于任何层。这种层的设计对于每个微服务都应该是独立的。如前所述,你可以按照DDD模式实现最复杂的微服务,同时以更简单的方式实现更简单的数据驱动型微服务(单层的简单CRUD)。
数据传输对象DTO
数据传输对象(Data Transfer Object, DTO)用作数据传输。在落地DDD的实践中,由于采用CQRS模式,所以会有大量的Command对象、Query对象以及返回给前端用的ViewModel对象,和其他系统交互的DTO对象,这些对象都应该归类为DTO对象。
DTO对象位置
- 针对对领域模型的命令对象,应该将命令
Command对象创建在ApplicationService层,因ApplicationService是领域层的边界,类似于细胞壁,所有进入到ApplicationService层里面的数据都应该是领域对象。Command对象创建在应用层可以避免应用层对其他层的依赖。 - 针对查询对象,查询
Query对象如果采用CQRS模式相对要求比较松,既可以放在ApplicationService层,也可以放在Interface层,查询对象不改变领域模型。 - 针对领域层产生的值对象,领域层产生的值对象应该在
ApplicationService层出口之前封装成DTO,避免领域层对象泄露到外部,导致其他层或者其他系统产生依赖。
DO对象复用
与数据库交互的DO(Data Object)对象,在CQRS查询的时候一般直接通过Mapper进行查询,那么查出来的对象就是DO对象,在这个过程中如果直接返回给前端会存在一个问题,即参数格式、名称等可能不对应的情况,因此一般也是封装一个DTO返回给前端,但是针对小项目可以按照传统方式直接返回DO。
劣势
- 重复代码
- 对Domain的修改可能会影响多个DTO,需同时修改这些DTO
- 需要写大量的Converter、Assembler的翻译代码
优势
- 解耦领域层与外部系统
- API层相对稳定
- 只返回其他系统真正需要的属性,节约网络带宽且不会暴露数据结构
- 使用代码生成工具可以有效减少开发工作量
为什么需要DDD
传统架构的劣势
- 面向数据库建模,更加关注数据、关注有哪些表哪些列,只要数据最终落库,中间逻辑可以采取任何形式。忽略了业务中非常重要的"行为\动作\业务逻辑"的建模,导致中间层要么臃肿、要么流水账、要么逻辑分散,没有真正"面向对象"。最终导致系统被数据库"绑架",业务走向复杂。
- 传统
Controller、Service、Dao三层架构的业务逻辑分散到多个地方、如一部分逻辑在SQL中、一部分在Service中、甚至有的直接在Controller中,导致更换开发人员后代码不易维护。 - 传统三层架构面向数据库编程,本质上是数据库的事务脚本,
Service里充斥着过程代码、胶水代码,多人维护过程中会不断修改、添加Service中的逻辑,Service会随着开发时间越来越臃肿,当然,为了避免臃肿也会有诸如策略模式等设计模式的引入,但不能改变胶水代码本质,比如Service代码中即可能有RedisTemplate又可能有Mapper和KafkaTemplate等,最终导致Service代码因为不同原因而改变,不符合单一职责原则。 - 传统三层架构虽然在形式上分为三层,但是并没有在编译器级别对代码有约束,实现分层全靠程序员自己的意识,这种代码并没有充分利用到编程语言提供的封装性质,最后轻则
Service之间形成网状结构调用,重则Service层调用Controller层反向调用,导致代码逻辑混乱。 - Wiki是知识的坟墓在传统三层架构中体现的淋漓尽致,文档不易维护,并且随着时间推移旧知识将逐渐被代码的爆发式发展抛弃,最后新人过来不知所云,找不到一个关于业务的完整知识,出现面对老代码不敢改,怕改后出现问题,怕改不全等问题。
上述描述的问题可以通过架构手段和其他技术手段来规避或者避免,但可能会失去这种分层架构带来的简单性
DDD的优势
- 面向领域建模,不被某项存储技术绑架。
- 领域逻辑高内聚,真正的面向对象编程。
- 不需要Wiki维护,业务代码自解释,后来人员好接手。
- 技术细节变更如数据库、缓存、定时器等的变更对业务逻辑影响比较小,非常适合插件式架构。本条实际上是DDD和整洁架构综合带来的优势。
- 程序员的代码更加可读、更加清晰、更加贴合业务,离客户更近。代码即业务\设计、业务\设计即代码,直接映射。
DDD的收益
- 思想带来的收益,代码直接映射现实世界概念
- 整洁架构带来的收益,底层技术如框架、数据库、缓存、kafka等变更不会对核心业务逻辑造成影响
- 整洁架构带来的收益,代码可维护性更强,对后续扩展、移植等支持更好,分层更加科学
- 思想带来的收益,程序员通过DDD对业务理解更加透彻,写的代码可以更好的传达客户的业务诉求
- 思想带来的收益,解耦业务、为服务化提供指导思想。架构更加清晰
DDD的劣势
- 学习曲线陡峭,落地无框架支持
- 前期相比传统架构代码量更多,主要集中在DTO等数据对象
- 开发人员前期投入要更多,如事件风暴、聚合划分、事务处理等,工作量更多
DDD的事件风暴

事件风暴(Event Storming)是一种以协作探索复杂业务领域为目标的,灵活的工作坊(workshop)形式的活动。
它有不同的玩法,适用于多种不同的场景:
- 发掘现有的健康业务线中最有改进价值的地方
- 探索新业务模式的可行性
- 设想新的服务,为每个参与方带来最好的正向结果
- 设计整洁可维护的事件驱动型(Event-Driven)软件,以支持快速发展的业务
事件风暴的适应性,决定了它允许有不同背景的项目干系人进行复杂的,跨学科的沟通交流,提供了一种跨越信息孤岛和专业界限的新型协作方式。
所谓事件风暴就是所有人相关人员包括客户,在一起头脑风暴出领域内所发生的所有事件,事件一般以过去时描述,比如订单已下单、订单已删除。然后再在事件的前面加上产生这个事件的动作,如下单、删除订单。标记出这个动作需要遵循的一些规则,比如下单前检查库存,删除前确认订单是否完毕等,这些就是领域逻辑。
经过以上步骤之后标记处领域内的聚合,所谓聚合就是操作相关联的一些事件的主体,比如订单聚合。然后识别出聚合内的实体、值对象等。
最后把相关联的一些聚合放到一起,组成一个限界上下文,一般一个限界上下文对应一个服务,这个限界上下文(服务)会解决一个领域内的某个子域的问题。这个限界上下文就是一个大模型,里边由多个聚合小模型。
事件风暴中的基础概念
事件Event
事件即事实,即在业务领域中那些已经发生的事件就是事实,并可能需要保存下来或者让“别人”响应。
事件是对系统产生了业务上的影响的动作,相对的,如果仅仅是数据查询操作,则只会对系统产生技术上的影响,如CPU上升或者内存上升等。
注意:一般查询操作都不会触发事件的产生,所以查询操作不是事件,如点击了查询按钮显示了数据列表,一般情况下不会有类似于:数据已查询或列表已查询,这样的事件。
事件使用正方形橘黄色的便利贴表示,并且是过去式,如:用户已注册(User Registered),激活邮件已发送(ActivationEmail Sended)等。

热点Hotspot(IDEAS, RISKS)
热点表示不确定的点、有风险的点或者需要特别注意的点,一般贴在事件旁边,代表这件事情值得特别关注。
热点使用紫色的便利贴表示,文字描述可以随意点,没有格式要求。

事件与它旁边紫色的热点(图片来自《Introducing Eventstorming》By Alberto Brandolini)
决策命令Command
决策命令产生了事件,可理解为产生事件的动作,与事件一一对应。如用户已注册(User Registered)事件对应的决策命令就是注册用户(Register User)。
决策命令用正方形蓝色便利贴表示,在实践中只需要将事件“反过来”就行了。

发起命令的参与者User/Actor
前面的决策命令一定是由某个人或系统来发起的。比如:前面的注册用户这个命令,是由普通用户这个Actor发起的,进而可以联想到可能整个系统中还会有非普通用户,如管理员。

注意:在Big-Picture Event Storming workshop的实践中,不将决策命令贴出来
使用小长方形亮黄色便利贴,结合Command和Event,看起来整体像这样。
外部系统External System和规则Policy
Event不一定由前面所说的某个Actor触发Command而产生,也可能是由外部系统或者某种规则自动触发Command而产生。
外部系统使用大长方形的粉红色即时贴表示,规则Policy使用大长方形的紫色即时贴表示。

读模型Read Model
某个Actor做出决策Command的前提是需要看到某些信息,或者说,支撑Actor更容易做出决策命令Command的信息。读模型一般是通过Web页面(UI/UX)来展示更多的信息,以让用户更容易做出决策。

读模型用绿色正方形的即时贴来表示。
聚合Aggregate
某个Actor在某个聚合调用某种Command产生了某个Event。
比如前面的用户已注册(User Registered)事件,是由普通用户(Normal User)在注册薄(Register)上调用注册用户(Register User)这个命令而产生。
聚合使用大长方形的黄色即时贴表示。
整体解释
根据下图中的名字将整体串起来解释下。

一个Actor根据看到的Query Model/Information,决定对External System或者Aggregate执行一个Command/Action,进而产生了某种Domain Event。此Domain Event可能触发了某种Policy,此Policy可能又对External System或者Aggregate执行一个Command/Action。此Domain Event也可能会导致Query Model/Information发生变化,从而给Actor提供更多信息以进行其他操作。
Big-Picture Event Storming
What:一种进行业务全景探索的EventStorming形式
Who:产品经理或者开发Leader/架构师作为主持人,市场分析员、业务人员、财务、UX和其他需要配合的部门代表。总人数控制在8-12人。
When:当一个项目或者产品立项之后,并且业务人员(产品人员)已经基本有了项目/产品的构思。
Why:需要和所有的利益相关人(Stakeholders)一起探索发现业务全景,搭建一个平台让Stakeholder能贡献自己的专业知识,让所有人知道全景/边界、风险点、在此项目中的职责并发现产品/项目的逻辑漏洞。

Design-Level Event Storming
What:一种用于更细节的软件设计的EventStorming形式
Who:开发Leader/架构师作为主持人, 业务人员/产品经理,研发团队所有其他人员:测试、前端/后端、UI等。总人数控制在6-12人左右(为减少沟通成本,研发团队不宜过大)。
When:Big-Pic EventStorming之后,产品经理/业务人员自行进行了进一步业务梳理之后,或者某个业务的上下文需要研发团队介入研发之前。
Why:研发团队所有人都需要知道某个上下文的业务全景,需要学习更多的业务知识,以便开始研发工作;研发团队需要进行业务建模、统一业务语言以及知道业务优先级;业务/产品经理需要补充更多关于实现落地的细节,以便进行User Story的补充和优先级的调整。
两种形式的区别
人员
Big-Picture Event Storming侧重在业务方,重点是所有的干系人(StakeHolders),含研发Leader或者架构师
Design-level Event Storming侧重在研发团队内部,含研发Leader或者架构师
目的
Big-Picture Event Storming侧重在探索业务全景,发现热点(风险点或值得特别关注的点),补充不同领域的知识(如财务、运营等),并让stakeholder了解整个项目以及自己在这个项目中的职责(后期需要配合)。
Design-level Event Storming侧重在向研发团队传播业务知识,并进行业务建模,是研发和业务之间沟通的桥梁。
范围
Big-Picture Event Storming侧重在业务全景
Design-level Event Storming侧重在全景中的某个业务上下文
换个角度看企业软件研发
软件研发就是学习
现实情况是,工程师需要花大量时间来搞明白他们到底要做什么,大多数情况下,他们都是第一次接触某个业务,这是一个学习的过程,而且不是他们擅长的技术领域。
对于工程师来说,业务学习是最容易忽略且不被看重的,甚至还有点不屑。然而忽略业务学习,只关注技术学习,基本就是在浪费资源,是假装在解决一个很可能不会带来任何业务价值的问题,典型的现象是:没有清晰需求的情况下就开始写代码。
学习的过程肯定是累且不舒服的,如果感觉轻松,那很可能是在进行无效的学习(定义和解决一个自以为是的需求)。学习的动力来自于探索的好奇心以及成就感(比如尝试用数据模型来表示问题空间,以便解决比原来的问题更多问题的成就感),业务建模是进行探索式业务学习的一种有效方式。
软件研发不仅仅是写代码
不同的人对上面这句话理解不同,从资深工程师的角度来看,写代码只占软件研发的一部分,写代码之前还有设计,还有上线与运维;从业务的角度来看,软件研发就是写代码;从老板的角度来看,特别是不懂技术的老板,软件研发肯定就是写代码。这里的问题是,如何让相关的人都知道全局,知道除了写代码还有其他哪些工作要做。
现实情况是,在企业软件中的整个生命周期中,维护(运维、运营)成本以及软件需求调整/增加的成本才是大头,而不是将软件开发出来上线。如果前期需求不清晰,那么就会极大的增加后期需求调整的成本,造成整体成本的增加。如果需求没有和干系人对齐,就不能说需求是清晰的。
软件研发就是等待
这是工程师的小秘密,也是合理摸鱼的最佳实践。等待Build完成、等待UT跑完、等待业务把需求明确、等待别人主动讨论问题、等待申请审批通过、等待Leader布置任务等等,更难以注意到的是,在等一件重要的事情的时候,去做无关紧要的事情,让自己忙起来。 可以通过简化流程和尽可能的自动化来减少等待,但不能完全消除(也没有必要,合理的“等待”并不会降低效率)。
软件研发就是做决策
业务需求的明确的过程是一个决策的过程,架构师做设计方案的过程是一个决策的过程,制定具体实现方案,技术选型的过程是一个决策的过程,类和方法以及变量的命名也是一个决策过程。基本上一个企业软件的诞生就是一群人做了很多决策的结果。决策的质量决定了企业软件的生命力,足够的输入和讨论决定了决策的质量。与干系人相关却没有达成一致的决策是无效的决策。
事件风暴能解决的问题
事件风暴主要有两种形式用于解决不同的问题。总结来看,它打破了“部门墙”,能让所有人了解到业务的全貌,能让技术和业务在同一个游戏平台上解决真正的问题,能让所有人快速学习业务知识。
- 当软件系统需要进行跨部门的协作与对齐时,能帮助所有stakeholder看到整个系统的全貌、让技术和业务在同一个问题上进行讨论、发现有价值的问题、定义与明确各stakeholder的职责、发现逻辑漏洞、划分系统上下文、统一语言。
- 当软件系统开始研发之前,能帮助研发团队所有人看到系统的全貌或者一个上下文的全貌、协助进行业务建模,统一语言、非常适合项目研发的kickoff。
- 当有新人入职时,能帮助新人快速的学习系统的全貌、边界以及统一的语言。
事件风暴不能解决所有问题
不能解决所有的沟通协作问题
不同的沟通形式和方法用于解决不同的问题,事件风暴不可能解决所有沟通问题。如Scrum的站会用于快速同步项目进度、困难,梳理会用于梳理用户故事、评估工作量、同步项目milestone等,回顾会用于团队反思改进、分享最佳实践、表扬激励等。
不能解决Why的问题,更适合解决How的问题
一件事做与不做,取决于长期或者短期带来的价值。如对于企业中产品研发来说,一个产品的做与不做,取决于前期的市场调研与分析,有很多工具和方法论用于解决这个问题,比如SWOT、5 Force analysis、BRD,AWS的逆向工作法等。事件风暴并不能解决“为什么做”的问题,更适合解决“怎么做”的问题。
不适合用做底层技术的讨论
实践证明,事件风暴并不适用于存储系统、API网关、网络通信等底层技术或基础设施的讨论。这些更多需要专业的技术能力,且落地的时候有标准或者最佳实践可以遵循。一般的做法是,架构师或者技术专家进行这些系统的设计,然后跟技术团队沟通并实施,沟通的更多是关于技术人员容易理解的技术上的问题,而不是业务知识。
事件风暴与DDD的关系
DDD是以强调业务领域为核心的应对复杂业务系统研发的一套体系。而事件风暴是探索业务领域的其中一种方式(也可以说是工具),事件风暴的产出对应类DDD的统一语言和战略设计中的领域分析。
事件风暴对应事件建模范式,是以事件为视角来观察真实世界,通过事件引起的领域对象状态迁移来驱动出领域模型,进而影响软件实现的整体架构。与之对应的是对象建模范式,是以对象为视角来观察世界,一切皆为对象。而DDD则不关心使用哪种建模范式,只要以业务为核心,对系统进行建模即可,也就是说,事件和对象都可以是业务模型。
领域事件触发
- 用户->命令->Domain Event 由给定用户/人员触发的命令
- 外部系统->Domain Event 某个外部系统触发
- 时间流逝的结果 也许只是时间流逝的结果,没有任何特别的动作(如付款条款已过期)
- Domain Event->Whenever ->Domain Event 每当一件事发生时,就会发生另一件事
微服务的设计原则
“设计原则千万条,高内聚低耦合第一条,架构设计不规范,开发运维两行泪!”。
在分布式架构下,单体应用被拆分为多个微服务,为了保证微服务的单一职责和合理拆分,“高内聚、松耦合”是最宝贵的设计原则。
通俗点讲,高内聚就是把相关的行为聚集在一起,把不相关的行为放在别处,如果你要修改某个服务的行为,最好只在一处修改。如果做到了服务之间的松耦合,那么修改一个服务就不需要修改另一服务,一个松耦合的服务应该尽可能少的知道与之协作的那些服务的信息。
从集中式架构向分布式架构的技术转型,正如从盖砖瓦房向盖高楼大厦转变一样,必然要有组织、文化、理念和设计方法的同步更新,其中最不可或缺的能力就是架构设计能力。
领域驱动设计分层架构
分层架构的一个重要原则是每层只能与位于其下方的层发生依赖。
分层架构的好处是显而易见的。
首先,由于层间松散的耦合关系,使得我们可以专注于本层的设计,而不必关心其他层的设计,也不必担心自己的设计会影响其它层,对提高软件质量大有裨益。其次,分层架构使得程序结构清晰,升级和维护都变得十分容易,更改某层的代码,只要本层的接口保持稳定,其他层可以不必修改。即使本层的接口发生变化,也只影响相邻的上层,修改工作量小且错误可以控制,不会带来意外的风险。
关于分层架构的权威观点,Martin Fowler 在《Patterns of Enterprise Application Architecture》一书中给出了答案:
- 开发人员只关注整个架构中的某一层。
- 很容易的用新的方法来替换原有层次的方法。
- 降低层与层之间的依赖。
- 有利于标准化。
- 利于各层逻辑的复用。
要保持程序分层架构的优点,就必须坚持层间的松耦合关系。设计程序时,应先划分出可能的层次,以及此层次提供的接口和需要的接口。设计某层时,应尽量保持层间的隔离,仅使用下层提供的接口。

DDD(领域驱动设计)分层架构
DDD分层架构各层定义与职能:
- 展现层:它负责向用户显示信息和解释用户命令,完成前端界面逻辑。这里的用户不一定是使用用户界面的人,也可以是另一个计算机系统。
- 应用层:它是很薄的一层,负责展现层与领域层之间的协调,也是与其它系统应用层进行交互的必要渠道。应用层要尽量简单,不包含业务规则或者知识,不保留业务对象的状态,只保留有应用任务的进度状态,更注重流程性的东西。它只为领域层中的领域对象协调任务,分配工作,使它们互相协作。
- 领域层:它是业务软件的核心所在,包含了业务所涉及的领域对象(实体、值对象)、领域服务以及它们之间的关系,负责表达业务概念、业务状态信息以及业务规则,具体表现形式就是领域模型。领域驱动设计提倡富领域模型,即尽量将业务逻辑归属到领域对象上,实在无法归属的部分则以领域服务的形式进行定义。
- 基础设施层:它向其他层提供通用的技术能力,为应用层传递消息(API 网关等),为领域层提供持久化机制(如数据库资源)等。
三种架构模型关系

整洁、六边形以及DDD三种架构模型关系
分析和设计模式的演进
软件分析和设计方法经历了三个阶段的演进:
-
第一阶段是单机架构时代:采用面向过程的设计方法,系统包括 UI 层和数据库两层,采用 C/S 架构模式,整个系统围绕数据库驱动设计和开发,新项目总是从设计数据库及其字段开始。
-
第二阶段是集中式架构时代:采用面向对象的设计方法,系统包括 UI 层、业务逻辑层和数据库层,采用经典的三层架构,也有部分应用采用传统的 SOA 架构,这种架构易使服务变得臃肿,难于维护拓展,伸缩性能差。这个阶段系统分析、软件设计和开发大多是分阶段进行的。
-
第三阶段是分布式架构时代:由于微服务架构的流行,采用领域驱动设计方法,应用系统包括 UI 层、应用层、领域层和基础层。这个阶段融合了分析和设计阶段,通过建立领域模型,划分领域边界,做到领域模型既设计,代码与设计保持一致。
领域驱动设计主要优势:1. 业务导向。2. 业务逻辑内聚,应用边界清晰。3. 建立领域模型优先。4. 分析、设计、代码和数据有机结合。5. 代码即设计。6. 扩展性好。
数据驱动设计主要特点:1. 技术导向。2. 数据库优先。3. 代码不能反映业务和设计。4. 业务逻辑分散。5. 扩展性不好。
领域驱动设计收获
1、领域驱动设计是一套完整而系统的设计方法,它能带给你从战略设计到战术设计的规范过程,使得你的设计思路能够更加清晰,设计过程更加规范。
2、领域驱动设计尤其善于处理与领域相关的高复杂度业务的产品研发,通过它可以为你的产品建立一个核心而稳定的领域模型内核,有利于领域知识的传递与传承。
3、领域驱动设计强调团队与领域专家的合作,能够帮助团队建立一个沟通良好的团队组织,构建一致的架构体系。 领域驱动设计强调对架构与模型的精心打磨,尤其善于处理系统架构的演进设计。
4、领域驱动设计的思想、原则与模式有助于提高团队成员的架构设计能力。
5、领域驱动设计与微服务架构天生匹配,无论是在新项目中设计微服务架构,还是将系统从单体架构演进到微服务设计,都可以遵循领域驱动设计的架构原则。
为什么领域驱动设计是微服务架构的最佳设计方法
领域驱动设计作为一种架构设计方法,微服务作为一种架构风格,两者从本质上都是为追求高响应力目标而从业务视角去分离复杂度的手段。 两者都强调从业务出发,其核心要义强调根据业务发展,合理划分领域边界,持续调整现有架构,优化现有代码,以保持架构和代码的生命力(演进式架构) 。
领域驱动设计主要关注:业务领域,划分领域边界;构建通用语言,高效沟通;对业务进行抽象,建立领域模型;维持业务和代码的逻辑一致性。
微服务主要关注:运行时进程间通信,能够容错和故障隔离;去中心化管理数据和去中心化治理;服务可以独立的开发、测试、构建和部署,按业务组织全功能团队;高内聚低耦合,职责单一。
如果你的业务焦点在领域和领域逻辑,那么你就可以选择 DDD 进行微服务架构设计
什么是中台
2015 年年底,阿里巴巴集团对外宣布全面启动阿里巴巴集团2018年中台战略,构建符合数字时代的更具创新性、灵活性的“大中台、小前台”组织机制和业务机制,即作为前台的一线业务会更敏捷、更快速适应瞬息万变的市场,而中台将集合整个集团的运营数据能力、产品技术能力,对各前台业务形成强力支撑。
中台的本质是提炼各个业务条线的共同需求,并将这些功能打造成组件化产品,然后以 API 接口的形式提供给前台各业务部门使用。前台要做什么业务,需要什么资源可以直接找中台,不需要每次去改动自己的底层,而是在底层不变动的情况下,在更丰富灵活的“大中台”基础上获取支持,让“小前台”更加灵活敏捷。
中台战略的主要目标是实现公共需求和功能的中台化共享,减少重复建设和投入,为前台提供统一的一致服务。至于前台应用是否可以有数据库?抑或采用什么样的开发技术,这些都不是重点,重点需要考虑的是那些公共需求和需要共享的功能是否通过中台的方式被前台使用了。
领域驱动设计中领域的定义
一个领域本质上可以理解为就是一个问题域,只要是同一个领域,那问题域就相同。所以只要我们确定了系统所属的领域,那这个系统的核心业务,即要解决的关键问题、问题的范围边界就基本确定了。领域的本质是问题域,问题域可能根据需要逐层细分,因此领域可分解为子域,子域或可继续分为子子域。。。
在领域驱动设计中根据重要性与功能属性将领域分为三类子域,分别是:核心子域、支撑子域和通用子域。决定产品和企业独特竞争力的子域是核心子域,它是业务成功的主要因素和企业的核心竞争力。没有个性化的诉求,属于通用功能的子域是通用子域,如登陆认证。 还有一种所提供的功能是必须的,但不是通用也不是企业核心竞争力的子域是支撑子域,如单证。

DDD: 核心域、支撑域和通用域
DDD领域设计过程
DDD 领域设计过程包括产品愿景、场景分析、领域建模和服务地图阶段,也可根据需要裁剪不必要的阶段和参与角色。领域驱动设计一般经历 2-6 周的时间,领域模型设计完成后,即可投入微服务实施。

产品愿景
产品愿景是对产品的顶层价值设计,对产品目标用户、核心价值、差异化竞争点等策略层信息达成一致,避免产品在演进过程中偏离方向。
阶段输入:产品初衷、用户研究、竞品知识和差异性想法 。
参与角⾊:业务需求方、产品经理、开发组长和产品发起人。
阶段产出:电梯演讲画布。
场景分析
场景分析是针对核心用户及顶层服务的一种定性分析,从⽤户视角出发,探索问题域中的典型场景分析。同时也是从用户视角对问题域的探索,产出问题域中需要支撑的场景分类及典型场景,用以支撑领域建模阶段。
阶段输⼊:核⼼干系人和服务价值定位。
参与角色:产品经理、开发组长和测试组长。
阶段产出:场景分类清单。
领域建模
领域建模是通过对业务和问题域进⾏分析,建⽴领域模型,向上通过限界上下⽂指导微服务的边界设计,向下通过聚合指导实体的对象设计。领域建模主要采用事件风暴方法。
阶段输入:业务领域知识和场景分类清单。
参与角色:领域专家、架构师、产品经理、开发组长和测试组长。
阶段产出:聚合模型和限界上下⽂地图。
服务地图
服务地图是整个产品服务架构的体现。结合业务与技术因素,对服务的粒度、边界划分、集 成关系进⾏梳理,得到反映系统微服务层面设计的服务地图。
阶段输⼊:限界上下⽂地图。
参与角⾊:产品经理、开发组长、测试组长和产品发起人。
阶段产出:服务地图。
在进行服务地图设计时需要考虑以下要素:
- 围绕限界上下⽂边界。
- 考虑不同业务变化速度 / 相关度、发布频率。
- 考虑系统非功能性需求,如系统弹性伸缩要求、安全性要求和可⽤性要求。
- 考虑团队组织和沟通效率。
- 软件包限制。
- 技术和架构的异构。
通过DDD战略和战术全流程设计可建立业务架构与系统架构的一一映射,保证业务和代码模型的一致性。
逻辑边界与物理边界
在领域模型设计时,我们通常会根据限界上下文将领域分解成不同的子域,划分业务领域的逻辑边界。在限界上下文内不同的实体和值对象可以组合成不同的聚合,从而形成聚合与聚合之间的逻辑边界。一般来说,限界上下文可以作为微服务拆分的依据,而限界上下文内的聚合由于其业务逻辑的高度内聚,也可以根据需要将同一领域内的聚合业务逻辑代码拆分为微服务,聚合是领域中可以拆分为微服务的最小单元。
限界上下文与限界上下文之间以及聚合与聚合之间的边界是逻辑边界,微服务与微服务的边界是物理边界。逻辑边界强调业务领域逻辑或代码分层的隔离,物理边界强调部署和运行的隔离。
逻辑边界的划分是否可以细于物理边界
过度的微服务拆分会导致服务、安全和运维管理更复杂,领域之间的服务协同或应用层的处理逻辑更复杂,总之一句话就是:需要更高的研发技能要求和软件维护成本。因此领域和代码分层的逻辑边界的细分是必要的,但是物理边界不宜过细,也就是说在不违反微服务拆分原则的情况下,不宜过度拆分微服务。
为什么要细分业务和代码逻辑边界
在从单体向微服务演进后,随着新需求的出现,新的微服务会开始慢慢的膨胀起来,有一天你会发现膨胀的微服务有一部分业务能力需要拆分出去时,如果没有提前进行逻辑边界的细分,微服务内代码的过度耦合将会让你无从下手,你是否还需要再做一次从单体向微服务的拆分?
如果你在微服务设计时已经根据业务领域边界提前进行了领域代码的分层和逻辑隔离,在微服务再次拆分时,分别对逻辑分离的领域代码打包,同步进行数据库拆分,就可以快速完成微服务的拆分,而不需要重复从单体应用向微服务痛苦的演进过程。
当然,在同一个微服务内逻辑隔离的代码,在内部领域服务之间调用以及数据访问设计上需要有合理的松耦合的设计和开发规范,否则也不能很快的完成微服务再次拆分。
总之,我们需要内外部逻辑边界清晰的微服务,而不是从一个大单体重构为多个小单体。
评判微服务设计合理
评判微服务设计合理的一个简单标准就是:微服务在随着业务发展而不断拆分或者重新组合过程中不会过度增加软件维护成本,并且这个过程是非常轻松且简单的。

要做微服务而不是小单体
什么是业务逻辑
业务逻辑就是领域逻辑,是对现实世界中的业务规则的编码,业务逻辑决定了数据的创建、存储和变更。
In computer software, business logic or domain logic is the part of the program that encodes the real-world business rules that determine how data can be created, stored, and changed
业务规则描述了一个业务可以干什么、不能干什么、有什么约束。每个业务都是利用一套相对固定的程序来组织系统,并利用这套步骤来完成业务,这套步骤里就包括了完成业务可以做的一些行为,事实上业务规则无论是否用代码实现都是可以工作的,代码只是提高生产力的手段。
银行转账,比如你是银行业务员,先不通过代码考虑,单纯考虑这个银行业务
首先,你需要了解:
1、发起转账的人是谁
2、转出的金额是多少
3、发起转账的账号
4、接受转账的账号
以下业务规则约束了业务员要做的业务
a、发起转账的人必须有这个权限
b、转账过程必须是原子的
c、如果超过10万,必须通知政府
d、金额必须小于账户剩余总额
e、要转账的银行必须与当前银行可以直接互通
f、其他。。。
业务规则是组织赚钱的核心逻辑,即便没有代码人家一样可以运转,赚钱,代码不过是提高生产力的一种手段。
业务逻辑就是针对业务规则进行的编码操作,以上面的业务规则为例,编码的时候可以采用
A:三层架构
抽象一个TransferServiceImpl,然后里边有一个方法叫transfer(Account a, Account b),然后再transfer方法中写这些业务逻辑,做各种判断等,Account账户是单纯的数据容器,里面包含各种get、set方法,可以获取账户所有信息。
B:DDD架构
抽象两个Account聚合,和一个领域服务,领域服务TransferService中有一个方法是transfer(Account a, Account b),真正转账的动作是a.judge、a.reduce,b.judge、b.increase,即真正做业务逻辑是在两个账户里而不是在领域服务里。
充血模型和失血模型
充血模型
充血模型包含业务逻辑,更加符合高内聚的代码设计目标,同时代码也更加可读,比如account.reduce(10)表示账户减少10元。
失血模型
失血模型只包含数据和get、set方法,业务逻辑分散在多个service中,如果要减少10元,那么需要account.set(account.get()-10),并且这部分代码是在某个service中完成的,代码不可读的同时也不方便维护。后续代码膨胀的时候一个账户方法可能被多个service引用。
区分领域逻辑和应用服务逻辑
- 领域逻辑(业务逻辑、业务规则、领域知识)是做关键业务决策的主角,即业务决定都是由领域逻辑完成的
- 协调做关键业务决策的逻辑是应用服务逻辑
银行取钱:
- 先确定该账户是否可以取钱
- 如果可取,计算扣除手续费的余额
- 执行取钱
- 短信通知
上述业务是一个应用服务逻辑,只有执行取钱的时候是由领域模型作的决定,其他的都是协调做取钱这个业务逻辑的辅助逻辑。
限界上下文的思考
1、领域就是有一个范围,在这个范围内有不同的角色,每个角色都有该角色应该具备的领域知识,各角色之间通过自己掌握的知识完成彼此协作,完成一些领域活动,产生一些领域事件,最终完成领域职责。
2、划分领域的依据就是领域职责(目标)、领域关注点、完成职责需要的角色、角色需要的知识、角色需要执行的活动。
3、事件风暴的过程也是识别领域活动、领域职责、领域角色、领域事件、领域知识的过程。
引入领域服务的时机
领域服务以多个聚合作为入参,最后通过聚合完成业务逻辑。
a、在聚合A中引入聚合B的Repository
b、在聚合A的方法中以入参形式引入聚合B
c、直接在聚合A中组合聚合B
第一种和第三种有违领域驱动设计初衷,第二种虽然可行,但是语义上会存在不通顺的情况。所以,在我们遇到以上三种情况的困惑是领域服务就是我们的解药。
避免贫血模型
- 过度的使用领域服务会导致贫血领域模型,业务逻辑尽量写到聚合和值对象中
- 有些情况下我们会逼不得已使用领域服务完成一个“显著”的业务过程,这个显著的业务过程会非常“厚”。此时我们应该提高警惕,是不是领域限界上下文划分错误,导致一些不属于领域限界上下文的聚合被建模进来。
领域服务尽量避免写太多业务逻辑,导致贫血模型产生。
- 领域服务尽量只依赖Aggregates去完成领域事件,通过Application层从repo获取聚合注入进来,此时领域服务的实现位于领域层
- 次之,需要调用其他上下文的服务来完成领域事件,此时需要明确建立“防腐层”,使用依赖倒置,在领域层定义接口,在infrastructure层定义实现
- 除此之外,领域服务不应该通过调用外部来收集数据执行逻辑,这些应该属于应用服务
动手实践
解决方案分层
基于领域驱动设计思想的指导,将解决方案分为如下几层
- 领域模型层(Domain Model Layer)
- 基础设施层(Infrastructure Layer)
- 应用层(Application Layer)
- 共享层(Share Layer)
根据解决方案分层方案建立如下文件夹
- Applications
- Domain
- Infrastructure
- Shared
- Tests

共享层(
Shared)中包括三个项目:TeslaOrder.Core、TeslaOrder.Domain.Abstractions、TeslaOrder.Infrastructure.Core

TeslaOrder.Core核心类库,承载基础的简单类型,比如异常类、帮助类TeslaOrder.Domain.Abstractions领域的抽象层,在领域模式定义的基类、接口TeslaOrder.Infrastructure.Core基础设施核心层,对仓储、EFContext定义共享代码
建议将Shared这些项目通过Nuget方式进行多项目共享。
领域模型层(
Domain)中包括一个项目:TeslaOrder.Domain,这里是定义领域模型的地方。

在TeslaOrder.Domain里面不同的聚合下面就是领域模型

基础设施层(
Infrastructure)中包括一个项目:TeslaOrder.Infrastruture,这里是仓储层和一些共享代码的实现,包括EF的Domain的Context(DomainContext)、不同领域模型对应的仓储层(Repositories)、领域模型与数据库之间的映射关系(EntityConfigurations)

应用层(
Application)中包括两个项目:TeslaOrder.API、TeslaOrder.BackgroudTasks

其中TeslaOrder.API负责承载Web API和Web应用,TeslaOrder.BackgroudTasks是后台任务,它是控制台程序,用来执行一些特殊的Job,作为Job的宿主运行。
在
TeslaOrder.API中有进一步的细分,其中
- Application,使用OQRS设计模式,将命令查询职责分离,其下分为命令(Commands)、查询(Queries)、领域模型的领域事件处理(DomainEventHandlers)、集成事件处理(IntegrationEvents)
- Controllers,用来定义Web API
- Extensions,放置将服务注册到容器、中间件配置的代码
- Infrastructure,可放置身份认证(Auth)和缓存(Caching)之类的与基础设施交互的基础代码。

分层之间的依赖关系

Shared层不依赖任何层,这里存储了共享代码

Infrastructure层依赖Shared层中领域模型抽象层来实现仓储,还依赖Domain层

Domain层依赖Shared层中领域模型抽象层,需要继承领域模型基类和聚合根接口

这里可以看下Infrastructure层中OrderRepository的定义
public class OrderRepository : Repository<Order, long, OrderingContext>, IOrderRepository
{
public OrderRepository(OrderingContext context) : base(context)
{
}
}
这里复用了Infrastructure.Core层中Repository的实现,已经实现了一部分增删改查的方法。
接下来看下DomainContext的定义,它继承了Infrastructure.Core层中EFContext的实现
public class DomainContext : EFContext
{
public DomainContext(DbContextOptions options, IMediator mediator, ICapPublisher capBus) : base(options, mediator, capBus)
{
}
public DbSet<Order> Orders { get; set; }
public DbSet<User> Users { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// 注册领域模型与数据库的映射关系
modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration());
modelBuilder.ApplyConfiguration(new UserEntityTypeConfiguration());
base.OnModelCreating(modelBuilder);
}
}
再看下特殊的事务处理对象DomainContextTransactionBehavior用来管理整个请求上下文的事务,避免手动处理这些事务
public class DomainContextTransactionBehavior<TRequest, TResponse> : TransactionBehavior<DomainContext, TRequest, TResponse>
{
public DomainContextTransactionBehavior(DomainContext dbContext, ILogger logger) : base(dbContext, logger)
{
}
}
Application层依赖Infrastructure层,而Infrastructure层依赖了Domain层

应用分层的要领
- 领域模型专注业务的设计,不依赖仓储等基础设施层
- 基础设施的仓储层仅包括领域模型的获取和存储
- 推荐使用CQRS模式设计应用层,使代码更加合理
- Web API是面向前端的交互的接口,避免依赖领域模型
- 将共享代码设计为共享包,使用私有Nuget包仓库分发管理

区分领域模型的内在逻辑和外在行为
领域模型分为两层,一层是领域模型的抽象类、接口层,在Shared组的TeslaOrder.Domain.Abstractions,一层是位于Domain组的领域模型实现的TeslaOrder.Domain。
看下抽象层
TeslaOrder.Domain.Abstractions的定义

实体接口
IEntity.cs定义为
/// <summary>
/// 实体接口
/// </summary>
public interface IEntity
{
object[] GetKeys();
}
/// <summary>
/// 实体泛型接口
/// </summary>
/// <typeparam name="TKey"></typeparam>
public interface IEntity<TKey> : IEntity
{
TKey Id { get; }
}
IEntity只有一个方法就是获取ID,但是一个实体不排除有多个ID的情况,所以这里是GetKeys
而IEntity<TKey>接口表示实体只有一个Id,它的Id的类型是一个TKey,使用泛型模式代替,这样实体就可以任意定义自己的Id的类型。
实体抽象类
Entity.cs定义为
/// <summary>
/// 实体抽象类
/// </summary>
public abstract class Entity : IEntity
{
public abstract object[] GetKeys();
public override string ToString()
{
return $"[Entity: {GetType().Name}] Keys = {string.Join(",", GetKeys())}";
}
#region 领域事件
private List<IDomainEvent> _domainEvents;
public IReadOnlyCollection<IDomainEvent> DomainEvents => _domainEvents?.AsReadOnly();
public void AddDomainEvent(IDomainEvent eventItem)
{
_domainEvents = _domainEvents ?? new List<IDomainEvent>();
_domainEvents.Add(eventItem);
}
public void RemoveDomainEvent(IDomainEvent eventItem)
{
_domainEvents?.Remove(eventItem);
}
public void ClearDomainEvents()
{
_domainEvents?.Clear();
}
#endregion
}
/// <summary>
/// 实体抽象类(泛型)
/// </summary>
/// <typeparam name="TKey"></typeparam>
public abstract class Entity<TKey> : Entity, IEntity<TKey>
{
int? _requestedHashCode;
public virtual TKey Id { get; protected set; }
public override object[] GetKeys()
{
return new object[] { Id };
}
public override bool Equals(object obj)
{
if (obj == null || !(obj is Entity<TKey>))
return false;
if (Object.ReferenceEquals(this, obj))
return true;
if (this.GetType() != obj.GetType())
return false;
Entity<TKey> item = (Entity<TKey>)obj;
if (item.IsTransient() || this.IsTransient())
return false;
else
return item.Id.Equals(this.Id);
}
public override int GetHashCode()
{
if (!IsTransient())
{
if (!_requestedHashCode.HasValue)
_requestedHashCode = this.Id.GetHashCode() ^ 31;
return _requestedHashCode.Value;
}
else
return base.GetHashCode();
}
/// <summary>
/// 表示对象是否为全新创建的,未持久化的
/// </summary>
/// <returns></returns>
public bool IsTransient()
{
return EqualityComparer<TKey>.Default.Equals(Id, default);
}
public override string ToString()
{
return $"[Entity: {GetType().Name}] Id = {Id}";
}
public static bool operator ==(Entity<TKey> left, Entity<TKey> right)
{
if (Object.Equals(left, null))
return (Object.Equals(right, null)) ? true : false;
else
return left.Equals(right);
}
public static bool operator !=(Entity<TKey> left, Entity<TKey> right)
{
return !(left == right);
}
}
聚合根接口
IAggregateRoot.cs定义为
/// <summary>
/// 聚合根接口
/// </summary>
public interface IAggregateRoot
{
}
聚合根接口是个空接口,不实现任何方法,作用是在实现仓储层的时候,让一个仓储对应的一个聚合根。
领域事件接口
IDomainEvent.cs定义为
/// <summary>
/// 领域事件接口
/// </summary>
public interface IDomainEvent : INotification
{
}
领域事件处理接口
IDomainEventHandler.cs定义为
/// <summary>
/// 领域事件处理接口
/// </summary>
/// <typeparam name="TDomainEvent"></typeparam>
public interface IDomainEventHandler<TDomainEvent> : INotificationHandler<TDomainEvent> where TDomainEvent : IDomainEvent
{
}
值对象的定义
/// <summary>
/// 值对象
/// </summary>
public abstract class ValueObject
{
protected static bool EqualOperator(ValueObject left, ValueObject right)
{
if (ReferenceEquals(left, null) ^ ReferenceEquals(right, null))
{
return false;
}
return ReferenceEquals(left, null) || left.Equals(right);
}
protected static bool NotEqualOperator(ValueObject left, ValueObject right)
{
return !(EqualOperator(left, right));
}
protected abstract IEnumerable<object> GetAtomicValues();
public override bool Equals(object obj)
{
if (obj == null || obj.GetType() != GetType())
{
return false;
}
ValueObject other = (ValueObject)obj;
IEnumerator<object> thisValues = GetAtomicValues().GetEnumerator();
IEnumerator<object> otherValues = other.GetAtomicValues().GetEnumerator();
while (thisValues.MoveNext() && otherValues.MoveNext())
{
if (ReferenceEquals(thisValues.Current, null) ^ ReferenceEquals(otherValues.Current, null))
{
return false;
}
if (thisValues.Current != null && !thisValues.Current.Equals(otherValues.Current))
{
return false;
}
}
return !thisValues.MoveNext() && !otherValues.MoveNext();
}
public override int GetHashCode()
{
return GetAtomicValues()
.Select(x => x != null ? x.GetHashCode() : 0)
.Aggregate((x, y) => x ^ y);
}
}
值对象是没有Id的,重点是实现是否相等的判断。其中定义了一个获取原子值的方法GetAtomicValues。
看完领域模型的抽象层,接下来我们看下领域模型的定义。
Order的定义
/// <summary>
/// 订单实体类
/// </summary>
public class Order : Entity<long>, IAggregateRoot
{
public string UserId { get; private set; }
public string UserName { get; private set; }
public Address Address { get; private set; }
public int ItemCount { get; private set; }
protected Order()
{ }
public Order(string userId, string userName, int itemCount, Address address)
{
this.UserId = userId;
this.UserName = userName;
this.Address = address;
this.ItemCount = itemCount;
this.AddDomainEvent(new OrderCreatedDomainEvent(this));
}
public void ChangeAddress(Address address)
{
this.Address = address;
}
}
这里Order有继承了Entity<long>和IAggregateRoot,同时所有的字段都采用了私有的set,意味着所有的数据操作都是由实体负责的,这样好处是让我们领域模型符合封闭开放原则。
对领域的操作都是应该定义具有业务含义的方法来进行操作,比如说修改地址(ChangeAddress)
Address的定义
/// <summary>
/// 收获地址
/// </summary>
public class Address : ValueObject
{
public string Street { get; private set; }
public string City { get; private set; }
public string ZipCode { get; private set; }
public Address() { }
public Address(string street, string city, string zipcode)
{
Street = street;
City = city;
ZipCode = zipcode;
}
protected override IEnumerable<object> GetAtomicValues()
{
// Using a yield return statement to return each element one at a time
yield return Street;
yield return City;
yield return ZipCode;
}
}
它是被定义为值对象,所有的字符都是私有set,意味着需要通过构造函数来赋值,另外这里重载了获取原子值的方法,这里使用了yield return的方式。
总结
- 将领域模型字段的修改设置为私有
- 使用构造函数表示对象的创建
- 使用具有业务含义的动作来操作模型字段
- 领域模型负责对自己的数据进行处理
- 领域服务或命令处理者负责调用领域模型业务动作
仓储层的实现
工作单元模式,管理好事务
仓储层最重要的就是事务的管理,可以通过工作单元模式(UnitOfWork)来实现事务的管理。
工作单元模式特性
- 使用同一个上下文
- 跟踪实体的状态
- 保障事务的一致性,对实体的操作最终状态都是如实保存到存储中进行持久化。
查看Shared层TeslaOrder.Infrastructure.Core的相关定义。
工作单元接口(
IUnitOfWork)的定义
/// <summary>
/// 工作单元接口
/// </summary>
public interface IUnitOfWork : IDisposable
{
/// <summary>
/// 保存修改
/// </summary>
/// <param name="cancellationToken"></param>
/// <returns>返回Int是指影响的数据条数</returns>
Task<int> SaveChangesAsync(CancellationToken cancellationToken = default);
/// <summary>
/// 保存实体
/// </summary>
/// <param name="cancellationToken"></param>
/// <returns>返回Bool是指保存是否成功</returns>
Task<bool> SaveEntitiesAsync(CancellationToken cancellationToken = default);
}
其中SaveChangesAsync和SaveEntitiesAsync本质效果是一样的,只是前者返回的是Int型,表示影响数据的条数。
事务管理接口(
ITransaction)的定义
/// <summary>
/// 事务管理接口
/// </summary>
public interface ITransaction
{
/// <summary>
/// 获取当前事务
/// </summary>
/// <returns></returns>
IDbContextTransaction GetCurrentTransaction();
/// <summary>
/// 判断当前事务是否开启
/// </summary>
bool HasActiveTransaction { get; }
/// <summary>
/// 开启事务
/// </summary>
/// <returns></returns>
Task<IDbContextTransaction> BeginTransactionAsync();
/// <summary>
/// 提交事务
/// </summary>
/// <param name="transaction"></param>
/// <returns></returns>
Task CommitTransactionAsync(IDbContextTransaction transaction);
/// <summary>
/// 事务回滚
/// </summary>
void RollbackTransaction();
}
我们借助EF来实现我们的工作单元,可以再看下EFContext的定义
/// <summary>
/// EFContext
/// </summary>
public class EFContext : DbContext, IUnitOfWork, ITransaction
{
#region IUnitOfWork
/// <summary>
/// 保存实体
/// </summary>
/// <param name="cancellationToken"></param>
/// <returns></returns>
public async Task<bool> SaveEntitiesAsync(CancellationToken cancellationToken = default)
{
var result = await base.SaveChangesAsync(cancellationToken);
return true;
}
#endregion
#region ITransaction
private IDbContextTransaction _currentTransaction;
/// <summary>
/// 获取当前事务
/// </summary>
/// <returns></returns>
public IDbContextTransaction GetCurrentTransaction() => _currentTransaction;
/// <summary>
/// 判断当前事务是否开启
/// </summary>
public bool HasActiveTransaction => _currentTransaction != null;
/// <summary>
/// 开启事务
/// </summary>
/// <returns></returns>
public Task<IDbContextTransaction> BeginTransactionAsync()
{
if (_currentTransaction != null) return null;
_currentTransaction = Database.BeginTransaction();
return Task.FromResult(_currentTransaction);
}
/// <summary>
/// 提交事务
/// </summary>
/// <param name="transaction"></param>
/// <returns></returns>
/// <exception cref="ArgumentNullException"></exception>
/// <exception cref="InvalidOperationException"></exception>
public async Task CommitTransactionAsync(IDbContextTransaction transaction)
{
if (transaction == null) throw new ArgumentNullException(nameof(transaction));
if (transaction != _currentTransaction) throw new InvalidOperationException($"Transaction {transaction.TransactionId} is not current");
try
{
await SaveChangesAsync();
transaction.Commit();
}
catch
{
RollbackTransaction();
throw;
}
finally
{
if (_currentTransaction != null)
{
_currentTransaction.Dispose();
_currentTransaction = null;
}
}
}
/// <summary>
/// 事务回滚
/// </summary>
public void RollbackTransaction()
{
try
{
_currentTransaction?.Rollback();
}
finally
{
if (_currentTransaction != null)
{
_currentTransaction.Dispose();
_currentTransaction = null;
}
}
}
#endregion
}
这里EFContext继承了Entity Framework Core中的DbContext,并且继承了我们定义的IUnitOfWork和ITransaction接口。
我们看到IUnitOfWork中SaveEntitiesAsync方法是可以调用EFCore中SaveChangesAsync方法来实现的。
而EFCore中本身其实已经有SaveChangesAsync的实现了,就不需要重复实现了。
对于ITransaction的部分,我们把当前事务用一个字段来存储:_currentTransaction
在开启事务(BeginTransactionAsync)的方法中,先判断当前事务是否为空,如果不为空,那么返回空,不需要重复开启。
如果为空,那么通过Entity Framework Core中Database.BeginTransaction来开启事务。
在提交事务(CommitTransactionAsync)的方法中,将事务对象传进来,先判断这个事务对象是否为空,为空就抛出异常。继续判断传入事务和当前事务是否相等,如果不等的话,说明拿到的是一个外部创建的事务,也要抛出异常。
在提交事务之前,安全起见,先做一次SaveChangesAsync方法,将当前所有的变更都保存到数据库,然后再去提交,如果提交过程中间我们出现了异常,我们就事务回滚,最终我们需要把当前的事务进行释放,并且赋值为空,这样我们就可以多次开启事务、提交事务。
在事务回滚(RollbackTransaction)的方法中,直接判断当前事务是否为空,不为空,则调用Entity Framework Core中Rollback方法进行回滚,并且最终也是把当前事务进行释放,并且赋值为空。
最后来看下事务行为管理类TransactionBehavior的定义
/// <summary>
/// 事务行为管理类
/// </summary>
/// <typeparam name="TDbContext"></typeparam>
/// <typeparam name="TRequest"></typeparam>
/// <typeparam name="TResponse"></typeparam>
public class TransactionBehavior<TDbContext, TRequest, TResponse> : IPipelineBehavior<TRequest, TResponse> where TDbContext : EFContext
{
ILogger _logger;
TDbContext _dbContext;
public TransactionBehavior(TDbContext dbContext, ILogger logger)
{
_dbContext = dbContext ?? throw new ArgumentNullException(nameof(dbContext));
_logger = logger ?? throw new ArgumentNullException(nameof(logger));
}
public async Task<TResponse> Handle(TRequest request, CancellationToken cancellationToken, RequestHandlerDelegate<TResponse> next)
{
var response = default(TResponse);
var typeName = request.GetGenericTypeName();
try
{
// 如果当前开启了事务,那么就继续后面的动作
if (_dbContext.HasActiveTransaction)
{
return await next();
}
var strategy = _dbContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
Guid transactionId;
using (var transaction = await _dbContext.BeginTransactionAsync())
using (_logger.BeginScope("TransactionContext:{TransactionId}", transaction.TransactionId))
{
_logger.LogInformation("----- 开始事务 {TransactionId} ({@Command})", transaction.TransactionId, typeName, request);
response = await next();
_logger.LogInformation("----- 提交事务 {TransactionId} {CommandName}", transaction.TransactionId, typeName);
await _dbContext.CommitTransactionAsync(transaction);
transactionId = transaction.TransactionId;
}
});
return response;
}
catch (Exception ex)
{
_logger.LogError(ex, "处理事务出错 {CommandName} ({@Command})", typeName, request);
throw;
}
}
}
EFContext是实现UnitOfWork工作单元模式的核心,它实现了事务的管理和工作单元模式,我们就可以借助它来实现我们后续的仓储层。
使用EF Core来实现仓储层
先看下仓储层接口(IRepository)的定义
/// <summary>
/// 仓储层接口
/// </summary>
/// <typeparam name="TEntity"></typeparam>
public interface IRepository<TEntity> where TEntity : Entity, IAggregateRoot
{
/// <summary>
/// 获取工作单元
/// </summary>
IUnitOfWork UnitOfWork { get; }
/// <summary>
/// 添加实体
/// </summary>
/// <param name="entity"></param>
/// <returns></returns>
TEntity Add(TEntity entity);
/// <summary>
/// 添加实体(异步)
/// </summary>
/// <param name="entity"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
Task<TEntity> AddAsync(TEntity entity, CancellationToken cancellationToken = default);
/// <summary>
/// 更新实体
/// </summary>
/// <param name="entity"></param>
/// <returns></returns>
TEntity Update(TEntity entity);
/// <summary>
/// 更新实体(异步)
/// </summary>
/// <param name="entity"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
Task<TEntity> UpdateAsync(TEntity entity, CancellationToken cancellationToken = default);
/// <summary>
/// 删除实体
/// </summary>
/// <param name="entity"></param>
/// <returns></returns>
bool Remove(Entity entity);
/// <summary>
/// 删除实体(异步)
/// </summary>
/// <param name="entity"></param>
/// <returns></returns>
Task<bool> RemoveAsync(Entity entity);
}
如果带主键Id的实体接口定义如下
/// <summary>
/// 仓储层接口(带主键)
/// </summary>
/// <typeparam name="TEntity"></typeparam>
/// <typeparam name="TKey"></typeparam>
public interface IRepository<TEntity, TKey> : IRepository<TEntity> where TEntity : Entity<TKey>, IAggregateRoot
{
/// <summary>
/// 删除实体
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
bool Delete(TKey id);
/// <summary>
/// 删除实体(异步)
/// </summary>
/// <param name="id"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
Task<bool> DeleteAsync(TKey id, CancellationToken cancellationToken = default);
/// <summary>
/// 获取实体
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
TEntity Get(TKey id);
/// <summary>
/// 获取实体(异步)
/// </summary>
/// <param name="id"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
Task<TEntity> GetAsync(TKey id, CancellationToken cancellationToken = default);
}
它是继承了上面没有带主键Id的实体接口定义的,它拥有上面定义的所有的方法,另外它实现了几个根据Id相关的操作。
接下里,我们看下实体抽象类(Repository<TEntity, TDbContext>)的定义
/// <summary>
/// 实体抽象类
/// </summary>
/// <typeparam name="TEntity"></typeparam>
/// <typeparam name="TDbContext"></typeparam>
public abstract class Repository<TEntity, TDbContext> : IRepository<TEntity> where TEntity : Entity, IAggregateRoot where TDbContext : EFContext
{
protected virtual TDbContext DbContext { get; set; }
public Repository(TDbContext context)
{
this.DbContext = context;
}
public virtual IUnitOfWork UnitOfWork => DbContext;
public virtual TEntity Add(TEntity entity)
{
return DbContext.Add(entity).Entity;
}
public virtual Task<TEntity> AddAsync(TEntity entity, CancellationToken cancellationToken = default)
{
return Task.FromResult(Add(entity));
}
public virtual TEntity Update(TEntity entity)
{
return DbContext.Update(entity).Entity;
}
public virtual Task<TEntity> UpdateAsync(TEntity entity, CancellationToken cancellationToken = default)
{
return Task.FromResult(Update(entity));
}
public virtual bool Remove(Entity entity)
{
DbContext.Remove(entity);
return true;
}
public virtual Task<bool> RemoveAsync(Entity entity)
{
return Task.FromResult(Remove(entity));
}
}
以及带主键Id的实体抽象类
/// <summary>
/// 实体抽象类(带主键)
/// </summary>
/// <typeparam name="TEntity"></typeparam>
/// <typeparam name="TKey"></typeparam>
/// <typeparam name="TDbContext"></typeparam>
public abstract class Repository<TEntity, TKey, TDbContext> : Repository<TEntity, TDbContext>, IRepository<TEntity, TKey> where TEntity : Entity<TKey>, IAggregateRoot where TDbContext : EFContext
{
public Repository(TDbContext context) : base(context)
{
}
public virtual bool Delete(TKey id)
{
var entity = DbContext.Find<TEntity>(id);
if (entity == null)
{
return false;
}
DbContext.Remove(entity);
return true;
}
public virtual async Task<bool> DeleteAsync(TKey id, CancellationToken cancellationToken = default)
{
var entity = await DbContext.FindAsync<TEntity>(new object[] { id }, cancellationToken);
if (entity == null)
{
return false;
}
DbContext.Remove(entity);
return true;
}
public virtual TEntity Get(TKey id)
{
return DbContext.Find<TEntity>(id);
}
public virtual async Task<TEntity> GetAsync(TKey id, CancellationToken cancellationToken = default)
{
return await DbContext.FindAsync<TEntity>(new object[] { id }, cancellationToken);
}
}
这里我们看到带主键的实体抽象类中,我们看到Delete方法,具体实现也是先根据Id从DbContext中获取实体,然后再删除,这样有个好处就是可以跟踪对象的状态,代价就是任意的删除都是需要先去数据库里面做查询的动作。
有了上面的实体抽象类的基础,我们再来看看领域上下文类(DomainContext)的定义
/// <summary>
/// 领域上下文
/// </summary>
public class DomainContext : EFContext
{
public DomainContext(DbContextOptions options, IMediator mediator) : base(options, mediator)
{
}
public DbSet<Order> Orders { get; set; }
public DbSet<User> Users { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// 注册领域模型与数据库的映射关系
modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration());
modelBuilder.ApplyConfiguration(new UserEntityTypeConfiguration());
base.OnModelCreating(modelBuilder);
}
}
它继承了前面的EFContext,我们把实体Order和User都定义进来。
并且重写OnModelCreating方法,将领域模型和实体之间的转换关系配置添加进来。
这里看下领域模型和数据库之间的映射关系管理OrderEntityTypeConfiguration定义
public class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> builder)
{
builder.HasKey(p => p.Id);
builder.OwnsOne(o => o.Address, a =>
{
a.WithOwner();
});
}
}
这里通过HasKey定义主键是什么,通过OwnsOne定义导航属性。
另外,还需要创建一个Domain的事务管理类,它只需要继承TransactionBehavior<DomainContext, TRequest, TResponse>即可
/// <summary>
/// 领域事务行为管理类
/// </summary>
/// <typeparam name="TRequest"></typeparam>
/// <typeparam name="TResponse"></typeparam>
public class DomainContextTransactionBehavior<TRequest, TResponse> : TransactionBehavior<DomainContext, TRequest, TResponse>
{
public DomainContextTransactionBehavior(DomainContext dbContext, ILogger<DomainContextTransactionBehavior<TRequest, TResponse>> logger) : base(dbContext, logger)
{
}
}
使用自定义的仓储层
在ConfigureServices方法中添加AddMySqlDomainContext的方法,并且把Mysql配置传进去。
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddMySqlDomainContext(Configuration.GetValue<string>("Mysql"));
}
这里的AddMySqlDomainContext是包含在ServiceCollectionExtensions下的静态扩展方法
依赖包
https://www.nuget.org/packages/Pomelo.EntityFrameworkCore.MySql
dotnet add package Pomelo.EntityFrameworkCore.MySql
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddMySqlDomainContext(this IServiceCollection services, string connectionString)
{
return services.AddDomainContext(builder =>
{
builder.UseMySql(connectionString);
});
}
}
首次初始化创建数据库
添加配置文件appsettings.json中对Mysql的连接字符串
{
"Logging": {
"LogLevel": {
"Default": "Trace",
"Microsoft": "Trace",
"Microsoft.Hosting.Lifetime": "Trace"
}
},
"Mysql": "server=localhost;port=3306;user=root;password=sblW^kojcNXiuXGG;database=teslaorder;charset=utf8mb4;ConnectionReset=false;",
"AllowedHosts": "*"
}
在ConfigureServices方法中添加AddRepositories方法把相关领域模型仓储类注册到容器中。
public void ConfigureServices(IServiceCollection services)
{
services.AddRepositories();
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddRepositories(this IServiceCollection services)
{
services.AddScoped<IOrderRepository, OrderRepository>();
services.AddScoped<IUserRepository, UserRepository>();
return services;
}
}
在ConfigureServices方法中添加AddMediatRServices方法把相关领域事务管理类注入进来
public void ConfigureServices(IServiceCollection services)
{
services.AddMediatRServices();
如果升级到MediatR v12以上,写法变更为:
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddMediatRServices(this IServiceCollection services)
{
return services.AddMediatR(cfg => {
cfg.RegisterServicesFromAssemblies(typeof(Order).Assembly, typeof(Program).Assembly);
cfg.AddBehavior<IPipelineBehavior<,>, DomainContextTransactionBehavior<,>>();
});;
}
}
低于MediatR v12以下,写法为:
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddMediatRServices(this IServiceCollection services)
{
services.AddTransient(typeof(IPipelineBehavior<,>), typeof(DomainContextTransactionBehavior<,>));
return services.AddMediatR(typeof(Order).Assembly, typeof(Program).Assembly);
}
}
在Startup.cs的Configure方法中添加确保数据库创建EnsureCreated的瞬时方法。
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
using (var scope = app.ApplicationServices.CreateScope())
{
var dc = scope.ServiceProvider.GetService<DomainContext>();
dc.Database.EnsureCreated();
}
这里补充针对EFCore中创建和删除两个方法的解释
dbContext.Database.EnsureCreated(),将创建数据库(如果不存在)并初始化数据库架构。dbContext.Database.EnsureDeleted(),将删除数据库(如果存在),如果没有适当的权限,则会引发异常。
数据库刚开始的样子

启动运行之后

相关数据库teslaorder和实体表Orders、Users被创建成功。
添加日志输出
dotnet add package Serilog.AspNetCore
public class Program
{
public static IConfiguration Configuration { get; } = new ConfigurationBuilder()
.SetBasePath(Directory.GetCurrentDirectory())
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddJsonFile($"appsettings.{Environment.GetEnvironmentVariable("ASPNETCORE_ENVIRONMENT") ?? "Production"}.json", optional: true)
.AddEnvironmentVariables()
.Build();
public static int Main(string[] args)
{
Log.Logger = new LoggerConfiguration().ReadFrom.Configuration(Configuration)
.MinimumLevel.Debug()
.Enrich.FromLogContext()
//.WriteTo.Console(new RenderedCompactJsonFormatter())
.WriteTo.Console()
.CreateLogger();
try
{
Log.Information("Starting web host");
CreateHostBuilder(args).Build().Run();
return 0;
}
catch (Exception ex)
{
Log.Fatal(ex, "Host terminated unexpectedly");
return 1;
}
finally
{
Log.CloseAndFlush();
}
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
})
.UseSerilog();
}
相关日志配置
{
"Logging": {
"LogLevel": {
"Default": "Trace",
"Microsoft": "Trace",
"Microsoft.Hosting.Lifetime": "Trace"
}
},
"Serilog": {
"MinimumLevel": {
"Default": "Debug",
"Override": {
"Microsoft": "Debug",
"System": "Debug"
}
}
},
"AllowedHosts": "*"
}
相关日志输出

优化领域模型和数据表映射
我们打开Orders的设计视图看下。

主键Id是为空的,并且自增,但是其他字段的类型不符合我们预期,默认创建是LONGTEXT类型。
这里我们可以进一步完善一下Order的领域模型和实体表之间的关系,修改下OrderEntityTypeConfiguration类。
public class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> builder)
{
builder.HasKey(p => p.Id);
builder.ToTable("order");
builder.Property(p => p.UserId).HasMaxLength(20);
builder.Property(p => p.UserName).HasMaxLength(30);
builder.OwnsOne(o => o.Address, a =>
{
a.WithOwner();
a.Property(p => p.City).HasMaxLength(20);
a.Property(p => p.Street).HasMaxLength(50);
a.Property(p => p.ZipCode).HasMaxLength(10);
});
}
}
这里我们增加了ToTable逻辑,这里可以自定义表名为小写的order,并且我们给其他字段设置一些最长属性HasMaxLength。
这里设置Address使用的是OwnsOne,这样可以将Address这个值类型作为同一个表的字段去设置。

我们将数据库删除掉,再次运行下

看到这次创建结果符合我们预期了。

我们看到Address对应的数据库字段名称是通过下划线连接的,如果想要优化它,还可以使用HasColumnName来自定义列名。
public class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> builder)
{
builder.HasKey(p => p.Id);
builder.ToTable("order");
builder.Property(p => p.UserId).HasMaxLength(20);
builder.Property(p => p.UserName).HasMaxLength(30);
builder.OwnsOne(o => o.Address, a =>
{
a.WithOwner();
a.Property(p => p.Province).HasColumnName("Province").HasMaxLength(50);
a.Property(p => p.City).HasColumnName("City").HasMaxLength(30);
a.Property(p => p.Street).HasColumnName("Street").HasMaxLength(50);
a.Property(p => p.ZipCode).HasColumnName("ZipCode").HasMaxLength(10);
});
}
}
这意味着,我们可以在仓储层定义我们领域模型和数据库的映射关系,我们可以将这个映射关系组织为一个目录,为每一个领域模型设置一个类型去定义,并且这个过程是强类型的,这样的结构便于我们后期维护。
数据表仓储层设计
我们看下Order的仓储接口(IOrderRepository)是怎么设计的。
/// <summary>
/// 订单仓储接口
/// </summary>
public interface IOrderRepository : IRepository<Order, long>
{
}
它非常的简单,将Order、DomainContext进行关联。
再来看下Order的仓储的实现(OrderRepository)是怎么设计的。
/// <summary>
/// 订单仓储
/// </summary>
public class OrderRepository : Repository<Order, long, DomainContext>, IOrderRepository
{
public OrderRepository(DomainContext context) : base(context)
{
}
}
仓储的代码很薄,它已经有了基本的操作方法。
领域模型和领域事件的关系
通过领域事件来提升业务内聚,实现模块解耦
什么是MediatR
MediatR是一个目标不高的库,试图解决一个简单的问题--将进程中的消息发送与消息处理脱钩。跨平台,支持netstandard 2.1。
其作者是大名鼎鼎的Jimmy Bogard,因为它还是另外一个OOM组件AutoMapper的作者。

MediatR是一种基于中介者模式的.Net实现,是一种基于进程内的数据传递。主要用于同一个应用内实现数据传递。
在软件开发中,中介者模式则是要求我们根据实际的业务去定义一个包含各种对象之间交互关系的对象类,之后,所有涉及到该业务的对象都只关联于这一个中介对象类,不再显式的调用其它类。
核心对象
IMediatorINotificationINotificationHandler<in TNotifation>
演示通过MediaR实现领域事件和事件处理
依赖包
dotnet add package MediatR.Extensions.Microsoft.DependencyInjection
dotnet add package Microsoft.Extensions.DependencyInjection

定义事务TaslaOrderEvent和事务处理TaslaOrderEventHandler方法、TaslaAddressEventHandler方法
internal class TaslaOrderEvent : INotification
{
public string EventName { get; set; }
}
internal class TaslaOrderEventHandler : INotificationHandler<TaslaOrderEvent>
{
public Task Handle(TaslaOrderEvent notification, CancellationToken cancellationToken)
{
Console.WriteLine($"TaslaOrderEventHandler : {notification.EventName}");
return Task.FromResult(10L);
}
}
internal class TaslaAddressEventHandler : INotificationHandler<TaslaOrderEvent>
{
public Task Handle(TaslaOrderEvent notification, CancellationToken cancellationToken)
{
Console.WriteLine($"TaslaAddressEventHandler : {notification.EventName}");
return Task.FromResult(10L);
}
}
命名方法要继承INotification接口,命令处理方法要继承INotificationHandler接口。
在Main函数中发布事件
internal class Program
{
async static Task Main(string[] args)
{
var services = new ServiceCollection();
// 将MediatR添加到容器中,它会扫描我们传入的程序集
services.AddMediatR(typeof(Program).Assembly);
// 从容器中获取Mediator对象
var serviceProvider = services.BuildServiceProvider();
var mediator = serviceProvider.GetService<IMediator>();
// 发布事件
await mediator.Publish(new TaslaOrderEvent { EventName = "Hello Event" });
Console.WriteLine("Hello World!");
}
}
运行结果

我们看到两个处理程序都执行了,和之前的命令处理程序不一样的是,领域事件和领域事件处理程序是一对多的关系,一个领域事件可以对应多个领域事件处理程序,他们都会被触发。
引入MediatR的Nuget包和服务
依赖包
https://www.nuget.org/packages/MediatR.Extensions.Microsoft.DependencyInjection
dotnet add package MediatR.Extensions.Microsoft.DependencyInjection

在Startup.cs的ConfigureServices方法中注册MediatR服务
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddMediatR(typeof(Startup).GetTypeInfo().Assembly);
}
这里AddMediatR定义和入参是
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddMediatR(this IServiceCollection services, params Assembly[] assemblies)
{
return services.AddMediatR(assemblies, null);
}
抽象层
领域事件我们定义了名为IDomainEvent
/// <summary>
/// 领域事件接口
/// </summary>
public interface IDomainEvent : INotification
{
}
这里继承自MediatR中的INotification接口。
namespace MediatR
{
public interface INotification
{
}
}
再来看看领域事件处理IDomainEventHandler<TDomainEvent>接口的定义
/// <summary>
/// 领域事件处理接口
/// </summary>
/// <typeparam name="TDomainEvent"></typeparam>
public interface IDomainEventHandler<TDomainEvent> : INotificationHandler<TDomainEvent> where TDomainEvent : IDomainEvent
{
}
它也是继承了MediatR中的INotificationHandler<TDomainEvent>接口。
它有一个泛型参数,是TDomainEvent,但是这里我们约束where TDomainEvent : IDomainEvent它,也就是只处理IDomainEvent的入参。
namespace MediatR
{
public interface INotificationHandler<in TNotification> where TNotification : INotification
{
Task Handle(TNotification notification, CancellationToken cancellationToken);
}
}
它已经有了Handle的定义。
同时,在Entity中我们也添加了针对领域事件处理的部分
/// <summary>
/// 实体抽象类
/// </summary>
public abstract class Entity : IEntity
{
public abstract object[] GetKeys();
public override string ToString()
{
return $"[Entity: {GetType().Name}] Keys = {string.Join(",", GetKeys())}";
}
#region 领域事件
/// <summary>
/// 领域事件列表
/// </summary>
private List<IDomainEvent> _domainEvents;
/// <summary>
/// 获取领域事件列表
/// </summary>
public IReadOnlyCollection<IDomainEvent> DomainEvents => _domainEvents?.AsReadOnly();
/// <summary>
/// 添加领域事件
/// </summary>
/// <param name="eventItem"></param>
public void AddDomainEvent(IDomainEvent eventItem)
{
_domainEvents = _domainEvents ?? new List<IDomainEvent>();
_domainEvents.Add(eventItem);
}
/// <summary>
/// 移除领域事件
/// </summary>
/// <param name="eventItem"></param>
public void RemoveDomainEvent(IDomainEvent eventItem)
{
_domainEvents?.Remove(eventItem);
}
/// <summary>
/// 清除领域事件
/// </summary>
public void ClearDomainEvents()
{
_domainEvents?.Clear();
}
#endregion
}
这里将领域事件作为实体的一个属性存储进来,它应该是一个列表,因为在一个实体操作过程中间可能会发生多个事件:List<IDomainEvent> _domainEvents。
同时领域事件列表是可以被外部读取到的:IReadOnlyCollection<IDomainEvent> DomainEvents
这里还定义了领域添加(AddDomainEvent)、领域移除(RemoveDomainEvent)、领域清除(ClearDomainEvents)三个方法。
上诉事件方法都可以在领域模型中直接使用,比如说,在Order领域模型中,在完成领域模型创建后,可以添加一个OrderCreatedDomainEvent事件。
领域模型层
在领域模型层,我们来负责领域事件的定义和添加。
/// <summary>
/// 订单实体类
/// </summary>
public class Order : Entity<long>, IAggregateRoot
{
public Order(string userId, string userName, int itemCount, Address address)
{
this.UserId = userId;
this.UserName = userName;
this.Address = address;
this.ItemCount = itemCount;
this.AddDomainEvent(new OrderCreatedDomainEvent(this));
}
OrderCreatedDomainEvent领域事件的入参就是一个Order
/// <summary>
/// 订单创建领域事件
/// </summary>
public class OrderCreatedDomainEvent : IDomainEvent
{
public Order Order { get; private set; }
public OrderCreatedDomainEvent(Order order)
{
this.Order = order;
}
}
同理,针对订单地址修改我们也可以类似定义
/// <summary>
/// 修改订单地址
/// </summary>
/// <param name="address"></param>
public void ChangeOrderAddress(Address address)
{
this.Address = address;
this.AddDomainEvent(new OrderAddressChangedDomainEvent(this.Address));
}
这样有个显而易见的好处就是,针对领域模型相关的这些动作,都通过事件的方式公布出去,而不是从外部来进行调用。
应用层
在应用层,我们负责领域事件的接收和处理。
在TeslaOrder.API的Application文件夹下,我们定义了领域事件处理的目录DomainEventHandlers

看下订单创建领域事件处理方法OrderCreatedDomainEventHandler的定义
/// <summary>
/// 订单创建领域事件处理方法
/// </summary>
public class OrderCreatedDomainEventHandler : IDomainEventHandler<OrderCreatedDomainEvent>
{
/// <summary>
/// 处理方法
/// </summary>
/// <param name="notification"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
public Task Handle(OrderCreatedDomainEvent notification, CancellationToken cancellationToken)
{
return Task.CompletedTask;
}
}
发送领域事件的时机
实际上领域事件是和领域模型绑定在一起的。
那么当我们执行创建订单的命令处理程序时,我们通过订单仓储的事务实现了对领域事件的发送。
/// <summary>
/// 创建订单命令处理方法
/// </summary>
public class CreateOrderCommandHandler : IRequestHandler<CreateOrderCommand, long>
{
/// <summary>
/// 订单仓储
/// </summary>
IOrderRepository _orderRepository;
/// <summary>
/// 创建订单命令处理方法
/// </summary>
/// <param name="orderRepository"></param>
public CreateOrderCommandHandler(IOrderRepository orderRepository)
{
_orderRepository = orderRepository;
}
/// <summary>
/// 处理方法
/// </summary>
/// <param name="request"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
public async Task<long> Handle(CreateOrderCommand request, CancellationToken cancellationToken)
{
var address = new Address("广东省","沙头街道", "深圳", "518048");
var order = new Order("414675056", "taylorshi", request.ItemCount, address);
_orderRepository.Add(order);
await _orderRepository.UnitOfWork.SaveEntitiesAsync(cancellationToken);
return order.Id;
}
}
在这里的SaveEntitiesAsync方法中
/// <summary>
/// 保存实体
/// </summary>
/// <param name="cancellationToken"></param>
/// <returns></returns>
public async Task<bool> SaveEntitiesAsync(CancellationToken cancellationToken = default)
{
var result = await base.SaveChangesAsync(cancellationToken);
await _mediator.DispatchDomainEventsAsync(this);
return true;
}
这里在调用EFCore的SaveChangesAsync之后调用了下_mediator.DispatchDomainEventsAsync
public static class MediatorExtension
{
/// <summary>
/// 调度领域事件
/// </summary>
/// <param name="mediator"></param>
/// <param name="ctx"></param>
/// <returns></returns>
public static async Task DispatchDomainEventsAsync(this IMediator mediator, DbContext ctx)
{
// 从上下文中跟踪实体
var domainEntities = ctx.ChangeTracker
.Entries<Entity>()
.Where(x => x.Entity.DomainEvents != null && x.Entity.DomainEvents.Any());
// 从跟踪实体中获取到事件
var domainEvents = domainEntities
.SelectMany(x => x.Entity.DomainEvents)
.ToList();
// 将实体取出将实体内的事件清除
domainEntities.ToList()
.ForEach(entity => entity.Entity.ClearDomainEvents());
// 将事件逐条的通过中间者发送出去
foreach (var domainEvent in domainEvents)
await mediator.Publish(domainEvent);
}
}
在这里最终实现了将所有领域事件收集起来并且逐个发布出去。
基于CQRS模式响应服务
什么是命令查询职责分离模式
命令查询职责分离模式(Command Query Responsibility Segregation, CQRS),该模式从业务上分离修改和查询,从而使得逻辑更加清晰,便于对不同部分进行针对性的优化。

传统的CRUD(Create, Read, Update, Delete)方法有一些问题
- 使用同一个对象实体来进行数据库读写可能会太粗糙,大多数情况下,比如编辑的时候可能只需要更新个别字段,但是却需要将整个对象都穿进去,有些字段其实是不需要更新的。在查询的时候在表现层可能只需要个别字段,但是需要查询和返回整个实体对象。
- 使用同一实体对象对同一数据进行读写操作的时候,可能会遇到资源竞争的情况,经常要处理的锁的问题,在写入数据的时候,需要加锁。读取数据的时候需要判断是否允许脏读。这样使得系统的逻辑性和复杂性增加,并且会对系统吞吐量的增长会产生影响。
- 同步的,直接与数据库进行交互在大数据量同时访问的情况下可能会影响性能和响应性,并且可能会产生性能瓶颈。
- 由于同一实体对象都会在读写操作中用到,所以对于安全和权限的管理会变得比较复杂。
系统中的读写频率比,是偏向读,还是偏向写,就如同一般的数据结构在查找和修改上时间复杂度不一样,在设计系统的结构时也需要考虑这样的问题。解决方法就是我们经常用到的对数据库进行读写分离。 让主数据库处理事务性的增,删,改操作(Insert,Update,Delete)操作,让从数据库处理查询操作(Select操作),数据库复制被用来将事务性操作导致的变更同步到集群中的从数据库。这只是从DB角度处理了读写分离,但是从业务或者系统上面读和写仍然是存放在一起的。他们都是用的同一个实体对象。

CQRS最早来自于Betrand Meyer(Eiffel语言之父,开-闭原则OCP提出者)在Object-Oriented Software Construction这本书中提到的一种命令查询分离(Command Query Separation,CQS)的概念。
其基本思想在于,任何一个对象的方法可以分为两大类:
- 命令(Command):不返回任何结果(void),但会改变对象的状态。
- 查询(Query):返回结果,但是不会改变对象的状态,对系统没有副作用。
操作和查询分离使得我们能够更好的把握对象的细节,能够更好的理解哪些操作会改变系统的状态。
CQRS是对CQS模式的进一步改进成的一种简单模式。 它由Greg Young在[CQRS, Task Based UIs, Event Sourcing agh!] (http://codebetter.com/gregyoung/2010/02/16/cqrs-task-based-uis-event-sourcing-agh/)这篇文章中提出。“CQRS只是简单的将之前只需要创建一个对象拆分成了两个对象,这种分离是基于方法是执行命令还是执行查询这一原则来定的(这个和CQS的定义一致)”。
CQRS使用分离的接口将数据查询操作(Queries)和数据修改操作(Commands)分离开来,这也意味着在查询和更新过程中使用的数据模型也是不一样的。这样读和写逻辑就隔离开来了。

主数据库处理CUD,从库处理R,从库的的结构可以和主库的结构完全一样,也可以不一样,从库主要用来进行只读的查询操作。在数量上从库的个数也可以根据查询的规模进行扩展,在业务逻辑上,也可以根据专题从主库中划分出不同的从库。从库也可以实现成ReportingDatabase,根据查询的业务需求,从主库中抽取一些必要的数据生成一系列查询报表来存储。

使用ReportingDatabase的一些优点通常可以使得查询变得更加简单高效:
- ReportingDatabase的结构和数据表会针对常用的查询请求进行设计。
- ReportingDatabase数据库通常会去正规化,存储一些冗余而减少必要的Join等联合查询操作,使得查询简化和高效,一些在主数据库中用不到的数据信息,在ReportingDatabase可以不用存储。
- 可以对ReportingDatabase重构优化,而不用去改变操作数据库。
- 对ReportingDatabase数据库的查询不会给操作数据库带来任何压力。
- 可以针对不同的查询请求建立不同的ReportingDatabase库。
核心对象
IMediatorIRequest、IRequest<T>IRequestHandler<in TRequest, TResponse>
演示通过MediaR实现命令和查询职责分离
新建TeslaOrder.MediatorConsole项目,添加相关包引用
依赖包
dotnet add package MediatR.Extensions.Microsoft.DependencyInjection
dotnet add package Microsoft.Extensions.DependencyInjection

定义命令TeslaOrderCommand和命令处理TeslaOrderCommandHandler方法
internal class TeslaOrderCommand : IRequest<long>
{
public string CommandName { get; set; }
public TeslaOrderCommand()
{
}
public TeslaOrderCommand(string commandName)
{
this.CommandName = commandName;
}
}
internal class TeslaOrderCommandHandler : IRequestHandler<TeslaOrderCommand, long>
{
public Task<long> Handle(TeslaOrderCommand request, CancellationToken cancellationToken)
{
Console.WriteLine($"TeslaOrderCommandHandler : {request.CommandName}");
return Task.FromResult(10L);
}
}
命名方法要继承IRequest接口,命令处理方法要继承IRequestHandler接口。
在Main函数中发送命令
internal class Program
{
async static Task Main(string[] args)
{
var services = new ServiceCollection();
// 将MediaR添加到容器中,它会扫描我们传入的程序集
services.AddMediatR(typeof(Program).Assembly);
// 从容器中获取Mediator对象
var serviceProvider = services.BuildServiceProvider();
var mediator = serviceProvider.GetService<IMediator>();
// 发送命令
await mediator.Send(new TeslaOrderCommand { CommandName = "Hello" });
Console.WriteLine("Hello World!");
}
}
运行结果

通过Mediator这种中介者模式的好处是,将命令的构造和命令的处理分离开,如果在程序里面针对同一个命令实现了多个Handler,它将执行写在后面的,这是因为MediaR在扫描程序集的时候,会把同一个命令对应的Handler依次扫描进来,后面的不会覆盖前面的。
internal class TeslaOrderCommandHandler : IRequestHandler<TeslaOrderCommand, long>
{
public Task<long> Handle(TeslaOrderCommand request, CancellationToken cancellationToken)
{
Console.WriteLine($"TeslaOrderCommandHandler : {request.CommandName}");
return Task.FromResult(10L);
}
}
internal class TeslaOrderCommandHandler2 : IRequestHandler<TeslaOrderCommand, long>
{
public Task<long> Handle(TeslaOrderCommand request, CancellationToken cancellationToken)
{
Console.WriteLine($"TeslaOrderCommandHandler2 : {request.CommandName}");
return Task.FromResult(10L);
}
}
这时候运行结果还是一样

通过命令和命令处理的方式来响应创建
在TeslaOrder.API的应用层Application中,我们创建了CQRS模式的两个关键目录:
- Commands
- Queries
将命令和查询进行分离。
在Commands文件夹中,我们首先创建了一个订单创建命令CreateOrderCommand看看定义
/// <summary>
/// 创建订单命令
/// </summary>
public class CreateOrderCommand : IRequest<long>
{
/// <summary>
/// 商品数量
/// </summary>
public int ItemCount { get; private set; }
/// <summary>
/// 创建订单命令
/// </summary>
public CreateOrderCommand()
{
}
/// <summary>
/// 创建订单命令
/// </summary>
/// <param name="itemCount"></param>
public CreateOrderCommand(int itemCount)
{
ItemCount = itemCount;
}
}
它继承自MediatR中Request<out TResponse>接口
namespace MediatR
{
public interface IRequest<out TResponse> : IBaseRequest
{
}
}
针对这个订单创建命令,我们同时定义了订单创建命令处理程序类CreateOrderCommandHandler
/// <summary>
/// 创建订单命令处理方法
/// </summary>
public class CreateOrderCommandHandler : IRequestHandler<CreateOrderCommand, long>
{
/// <summary>
/// 订单仓储
/// </summary>
IOrderRepository _orderRepository;
/// <summary>
/// 创建订单命令处理方法
/// </summary>
/// <param name="orderRepository"></param>
public CreateOrderCommandHandler(IOrderRepository orderRepository)
{
_orderRepository = orderRepository;
}
/// <summary>
/// 处理方法
/// </summary>
/// <param name="request"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
public async Task<long> Handle(CreateOrderCommand request, CancellationToken cancellationToken)
{
var address = new Address("沙头街道", "深圳", "518048");
var order = new Order("414675056", "taylorshi", request.ItemCount, address);
_orderRepository.Add(order);
await _orderRepository.UnitOfWork.SaveEntitiesAsync(cancellationToken);
return order.Id;
}
}
它继承自MediatR中IRequestHandler<in TRequest, TResponse>接口
namespace MediatR
{
public interface IRequestHandler<in TRequest, TResponse> where TRequest : IRequest<TResponse>
{
Task<TResponse> Handle(TRequest request, CancellationToken cancellationToken);
}
}
在这个订单创建命令的处理逻辑中,我们定义了address、order两个领域模型对象,将其添加到订单仓储中并调用订单仓储中的工作单元对其进行保存操作。
使用命令来创建数据
在OrderController中,我们定义创建和查询两个接口
/// <summary>
/// 订单服务
/// </summary>
[Route("api/[controller]")]
[ApiController]
public class OrderController : ControllerBase
{
IMediator _mediator;
/// <summary>
/// 订单服务
/// </summary>
/// <param name="mediator"></param>
public OrderController(IMediator mediator)
{
_mediator = mediator;
}
/// <summary>
/// 创建订单
/// </summary>
/// <param name="cmd"></param>
/// <returns></returns>
[HttpPost]
public async Task<long> CreateOrder([FromBody]CreateOrderCommand cmd)
{
// 发送订单创建的命令
return await _mediator.Send(cmd, HttpContext.RequestAborted);
}
/// <summary>
/// 查询订单
/// </summary>
/// <param name="myOrderQuery"></param>
/// <returns></returns>
[HttpGet]
public async Task<List<string>> QueryOrder([FromQuery] MyOrderQuery myOrderQuery)
{
return await _mediator.Send(myOrderQuery);
}
}
这里我们看到,直接通过命令的方式,发送CreateOrderCommand创建命令即可。
运行项目试试
第一步,我们看到先走到了OrderController的Action这里

第二步,走到CreateOrderCommandHandler的Handle这里

第三步,走到Order领域模型的AddDomainEvent这里

第四步,走到EFContext的SaveEntitiesAsync这里

第五步,走到OrderCreatedDomainEventHandler的Handle这里

最终结果,数据按我们预期落库了

这里第四步到第五步之间执行了一个扩展的领域事件调度方法DispatchDomainEventsAsync
public static class MediatorExtension
{
/// <summary>
/// 调度领域事件
/// </summary>
/// <param name="mediator"></param>
/// <param name="ctx"></param>
/// <returns></returns>
public static async Task DispatchDomainEventsAsync(this IMediator mediator, DbContext ctx)
{
// 从上下文中跟踪实体
var domainEntities = ctx.ChangeTracker
.Entries<Entity>()
.Where(x => x.Entity.DomainEvents != null && x.Entity.DomainEvents.Any());
// 从跟踪实体中获取到事件
var domainEvents = domainEntities
.SelectMany(x => x.Entity.DomainEvents)
.ToList();
// 将实体取出将实体内的事件清除
domainEntities.ToList()
.ForEach(entity => entity.Entity.ClearDomainEvents());
// 将事件逐条的通过中间者发送出去
foreach (var domainEvent in domainEvents)
await mediator.Publish(domainEvent);
}
}
它先从实体中获取了领域事件,然后清除了实体中的领域事件,最后依次将前面获取到的领域事件发布出去。
所以就能理解为啥,我们第三步就添加了领域事件,但是到了第五步才进入领域事件执行逻辑来,因为第四步这里才把这些领域事件给发送出去。
使用命令来查询数据
在Application下面有个查询Queries目录,这里我们可以定义我们的查询命令TeslaOrderQuery和命令对应的处理程序TeslaOrderQueryHandler。
/// <summary>
/// 订单查询命令
/// </summary>
public class TeslaOrderQuery : IRequest<List<string>>
{
/// <summary>
/// 用户名
/// </summary>
public string UserName { get; set; }
}
/// <summary>
/// 订单查询命令处理程序
/// </summary>
public class TeslaOrderQueryHandler : IRequestHandler<TeslaOrderQuery, List<string>>
{
/// <summary>
/// 处理
/// </summary>
/// <param name="request"></param>
/// <param name="cancellationToken"></param>
/// <returns></returns>
public Task<List<string>> Handle(TeslaOrderQuery request, CancellationToken cancellationToken)
{
return Task.FromResult(new List<string>() { DateTime.Now.ToString() });
}
}
这时候我们在OrderController这里新增一个查询QueryOrder的Action
/// <summary>
/// 查询订单
/// </summary>
/// <param name="myOrderQuery"></param>
/// <returns></returns>
[HttpGet]
public async Task<List<string>> QueryOrder([FromQuery]TeslaOrderQuery myOrderQuery)
{
return await _mediator.Send(myOrderQuery);
}
运行看看结果




在命令处理的前后插入逻辑
MediatR也有类似中间件的处理逻辑,它有个IPipelineBehavior<in TRequest, TResponse>接口
namespace MediatR
{
public interface IPipelineBehavior<in TRequest, TResponse>
{
Task<TResponse> Handle(TRequest request, CancellationToken cancellationToken, RequestHandlerDelegate<TResponse> next);
}
}
这里我们自定义了继承自它的实现TransactionBehavior
/// <summary>
/// 事务行为管理类
/// </summary>
/// <typeparam name="TDbContext"></typeparam>
/// <typeparam name="TRequest"></typeparam>
/// <typeparam name="TResponse"></typeparam>
public class TransactionBehavior<TDbContext, TRequest, TResponse> : IPipelineBehavior<TRequest, TResponse> where TDbContext : EFContext
{
ILogger _logger;
TDbContext _dbContext;
public TransactionBehavior(TDbContext dbContext, ILogger logger)
{
_dbContext = dbContext ?? throw new ArgumentNullException(nameof(dbContext));
_logger = logger ?? throw new ArgumentNullException(nameof(logger));
}
/// <summary>
/// 处理程序
/// </summary>
/// <param name="request"></param>
/// <param name="cancellationToken"></param>
/// <param name="next"></param>
/// <returns></returns>
public async Task<TResponse> Handle(TRequest request, CancellationToken cancellationToken, RequestHandlerDelegate<TResponse> next)
{
var response = default(TResponse);
var typeName = request.GetGenericTypeName();
try
{
// 如果当前开启了事务,那么就继续后面的动作
if (_dbContext.HasActiveTransaction)
{
return await next();
}
var strategy = _dbContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
Guid transactionId;
using (var transaction = await _dbContext.BeginTransactionAsync())
using (_logger.BeginScope("TransactionContext:{TransactionId}", transaction.TransactionId))
{
_logger.LogInformation("----- 开始事务 {TransactionId} ({@Command})", transaction.TransactionId, typeName, request);
response = await next();
_logger.LogInformation("----- 提交事务 {TransactionId} {CommandName}", transaction.TransactionId, typeName);
await _dbContext.CommitTransactionAsync(transaction);
transactionId = transaction.TransactionId;
}
});
return response;
}
catch (Exception ex)
{
_logger.LogError(ex, "处理事务出错 {CommandName} ({@Command})", typeName, request);
throw;
}
}
}
整个逻辑也很简单,和我们以前知道的中间件逻辑很类似,如果时执行它这个中间件后面的逻辑,那么直接执行await next()即可,除此之外,我们就可以在前后添加自己的逻辑。
这里添加的逻辑就是,检测当前DBContext是否开启事务,如果没有开启事务,那么创建一个新的事务并且提交。
这里还定义了一个领域事务行为管理类DomainContextTransactionBehavior来继承它TransactionBehavior
/// <summary>
/// 领域事务行为管理类
/// </summary>
/// <typeparam name="TRequest"></typeparam>
/// <typeparam name="TResponse"></typeparam>
public class DomainContextTransactionBehavior<TRequest, TResponse> : TransactionBehavior<DomainContext, TRequest, TResponse>
{
public DomainContextTransactionBehavior(DomainContext dbContext, ILogger<DomainContextTransactionBehavior<TRequest, TResponse>> logger) : base(dbContext, logger)
{
}
}
最终我们还需要在添加MediatR服务之前把它注册进来。
public static class ServiceCollectionExtensions
{
/// <summary>
/// 添加MediatR相关服务和中间件策略
/// </summary>
/// <param name="services"></param>
/// <returns></returns>
public static IServiceCollection AddMediatRServices(this IServiceCollection services)
{
services.AddTransient(typeof(IPipelineBehavior<,>), typeof(DomainContextTransactionBehavior<,>));
return services.AddMediatR(typeof(Order).Assembly, typeof(Program).Assembly);
}
回到示例的例子就是
internal class Program
{
async static Task Main(string[] args)
{
var services = new ServiceCollection();
services.AddTransient(typeof(IPipelineBehavior<,>), typeof(TeslaOrderBehavior<,>));
// 将MediatR添加到容器中,它会扫描我们传入的程序集
services.AddMediatR(typeof(Program).Assembly);
// 从容器中获取Mediator对象
var serviceProvider = services.BuildServiceProvider();
var mediator = serviceProvider.GetService<IMediator>();
// 发送命令
await mediator.Send(new TeslaOrderCommand { CommandName = "Hello" });
Console.WriteLine("Hello World!");
}
}
internal class TeslaOrderCommand : IRequest<long>
{
public string CommandName { get; set; }
public TeslaOrderCommand()
{
}
public TeslaOrderCommand(string commandName)
{
this.CommandName = commandName;
}
}
internal class TeslaOrderCommandHandler : IRequestHandler<TeslaOrderCommand, long>
{
public Task<long> Handle(TeslaOrderCommand request, CancellationToken cancellationToken)
{
Console.WriteLine($"TeslaOrderCommandHandler : {request.CommandName}");
return Task.FromResult(10L);
}
}
internal class TeslaOrderCommandHandler2 : IRequestHandler<TeslaOrderCommand, long>
{
public Task<long> Handle(TeslaOrderCommand request, CancellationToken cancellationToken)
{
Console.WriteLine($"TeslaOrderCommandHandler2 : {request.CommandName}");
return Task.FromResult(10L);
}
}
internal class TeslaOrderBehavior<TRequest, TResponse> : IPipelineBehavior<TRequest, TResponse> where TRequest : IRequest<TResponse>
{
public async Task<TResponse> Handle(TRequest request, RequestHandlerDelegate<TResponse> next, CancellationToken cancellationToken)
{
Console.WriteLine($"TeslaOrderBehavior Start");
var response = await next();
Console.WriteLine($"TeslaOrderBehavior End");
return response;
}
}

总结
- 由领域模型内部创建事件
- 由专有的领域事件处理类处理领域事件
- 根据实际情况来决定是否在同一个事务中处理(如一致性、性能等因素)

定义API的最佳实践
传统方式对比中间者模式
传统方式会这么写
[HttpPost]
public Task<long> CreateOrder([FromBody] CreateOrderVeiwModel viewModel)
{
var model = viewModel.ToModel();
return await orderService.CreateOrder(model);
}
class OrderService : IOrderService
{
public long CreateOrder(CreateOrderModel model)
{
var address = new Address("wen san lu", "hangzhou", "310000");
var order = new Order("xiaohong1999", "xiaohong", 25, address);
_orderRepository.Add(order);
await _orderRepository.UnitOfWork.SaveEntitiesAsync(cancellationToken);
return order.Id;
}
}
通过MediaR采用中介者模式
/// <summary>
/// 订单服务
/// </summary>
[Route("api/[controller]")]
[ApiController]
public class OrderController : ControllerBase
{
IMediator _mediator;
/// <summary>
/// 订单服务
/// </summary>
/// <param name="mediator"></param>
public OrderController(IMediator mediator)
{
_mediator = mediator;
}
/// <summary>
/// 创建订单
/// </summary>
/// <param name="cmd"></param>
/// <returns></returns>
[HttpPost]
public async Task<long> CreateOrder([FromBody]CreateOrderCommand cmd)
{
// 发送订单创建的命令
return await _mediator.Send(cmd, HttpContext.RequestAborted);
}
通过命令将查询过程分离,而不是在Controller这里定义和引入一堆的服务。
在Controller这层,它的作用是定义输入和输出,实现我们的身份认证、授权等功能,它不应该去负责处理我们领域模型、处理我们的仓储、所以不建议使用传统方式去写。
Controller还需要去定义路由的规则、URL的规则,Action的请求方式。
Controller所依赖的服务都推荐使用Controller的构造函数来进行注入,如果个别服务只是个别Action需要用到的,那么我们就可以使用[FromSerives]的方式去注入。
建议尽可能地定义异步的Action,使用Async和Await方式组合来去实现我们的代码,这样对提高应用程序吞吐量是有帮助的。
总结
- 负责用户的输入输出定义
- 负责身份认证与授权
- 与领域服务职责区分开,不承载业务逻辑
参考
- Book of Domain Driven Design
- Domain-driven design
- Design a DDD-oriented microservice
- Layered architecture in Domain-Driven Design
- Domain-Driven Design in ASP.NET Core applications
- Best Practice - An Introduction To Domain-Driven Design
- EnsureCreated、EnsureDeleted 创建和删除API
- Asp.Net Core使用MediatR
- jbogard/MediatR
- 在ASP.NET Core项目中使用MediatR实现中介者模式
- 中介者模式— Graphic Design Patterns - 图说设计模式
- MediatR知多少
- CRUD (Create, Read, Update, Delete)
- 浅谈命令查询职责分离(CQRS)模式
- CQRS, Task Based UIs, Event Sourcing agh!
- Object-Oriented Software Construction
- 开-闭原则
- Mediatr IPipelineBehavior not triggered
- 快速入门:使用 Docker 运行 SQL Server Linux 容器映像
- DDD落地过程中关于DTO的思考
- 为什么要DDD
- DDD在产品设计阶段的实践
- http://www.eventstorming.net.cn
- 当中台遇上DDD,我们该如何设计微服务
- DDD到底什么是业务逻辑
- DDD可落地的架构长什么样
- What is PostgreSQL?
- https://www.nuget.org/packages/MediatR


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【.NET】调用本地 Deepseek 模型
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
2021-10-15 乘风破浪,遇见最美Windows 11之系统官宣壁纸(Wallpaper) - Insider七周年纪念壁纸(4K)