DaSiamRPN学习
🏆News: We won the VOT-18 real-time challenge
🏆News: We won the second place in the VOT-18 long-term challenge
DaSiamRPN
This repository includes PyTorch code for reproducing the results on VOT2018.
Distractor-aware Siamese Networks for Visual Object Tracking
Zheng Zhu*, Qiang Wang*, Bo Li*, Wei Wu, Junjie Yan, and Weiming Hu
European Conference on Computer Vision (ECCV), 2018
Introduction
SiamRPN
DaSiamRPN improves the performances of SiamRPN by (1) introducing an effective sampling strategy to control the imbalanced sample distribution, (2) designing a novel distractor-aware module to perform incremental learning, (3) making a long-term tracking extension. ECCV2018. (Slides at VOT-18 Real-time challenge winners talk)

Prerequisites
CPU: Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz GPU: NVIDIA GTX1060
-
python2.7
-
pytorch == 0.3.1
-
numpy
-
opencv
Pretrained model for SiamRPN
In our tracker, we use an AlexNet variant as our backbone, which is end-to-end trained for visual tracking. The pretrained model can be downloaded from google drive: SiamRPNBIG.model. Then, you should copy the pretrained model file SiamRPNBIG.model to the subfolder './code', so that the tracker can find and load the pretrained_model.
Detailed steps to install the prerequisites
-
install pytorch, numpy, opencv following the instructions in the
run_install.sh. Please do not use conda to install. -
you can alternatively modify
/PATH/TO/CODE/FOLDER/intracker_SiamRPN.mIf the tracker is ready, you will see the tracking results. (EAO: 0.3827)
Results
All results can be downloaded from Google Drive.
| VOT2015</br>A / R / EAO | VOT2016</br>A / R / EAO | VOT2017 & VOT2018</br>A / R / EAO | OTB2015</br>OP / DP | UAV123</br>AUC / DP | UAV20L</br>AUC / DP | |
|---|---|---|---|---|---|---|
| SiamRPN </br> CVPR2017 | <sub>0.58 / 1.13 / 0.349<sub> | <sub>0.56 / 0.26 / 0.344<sub> | <sub>0.49 / 0.46 / 0.244<sub> | <sub>81.9 / 85.0<sub> | <sub>0.527 / 0.748<sub> | <sub>0.454 / 0.617<sub> |
| DaSiamRPN</br> ECCV2018 | <sub>0.63 / 0.66 / 0.446<sub> | <sub>0.61 / 0.22 / 0.411<sub> | <sub>0.56 / 0.34 / 0.326<sub> | <sub>86.5 / 88.0<sub> | <sub>0.586 / 0.796<sub> | <sub>0.617 / 0.838<sub> |
| DaSiamRPN</br> VOT2018 | <sub>-<sub> | <sub>-<sub> | <sub>0.59 / 0.28 / 0.383<sub> | <sub>-<sub> | <sub>-<sub> | <sub>-<sub> |
Demo and Test on OTB2015

-
To reproduce the reuslts on paper, the pretrained model can be downloaded from Google Drive:
SiamRPNOTB.model. ⚡️ ⚡️ This model is the fastest (~200fps) Siamese Tracker with AUC of 0.655 on OTB2015. ⚡️ ⚡️ -
You must download OTB2015 dataset (download script) at first.
A simple test example.
cd code
python demo.py
If you want to test the performance on OTB2015, please using the follwing command.
cd code
python test_otb.py
python eval_otb.py OTB2015 "Siam*" 0 1
Code reading
在vot_SiamRPN.py中的line 32中调用了
self._files = [x.strip('\n') for x in open('images.txt', 'r').readlines()]
是用来给第一帧的图像初始化坐标用的,在第一帧以后的后续帧,用来更新坐标信息
cx = (x1+x2+x3+x4)/4 cy = (y1+y2+y3+y4)/4 w = ((x2-x1)+(x3-x4))/2 h = ((y3-y2)+(y4-y1))/2
vot-2018-short term数据集里面的groundtruth是这样的
137.21,458.36,156.83,460.78,148.35,529.41,128.72,526.99
分别是四个点的横纵坐标——(x1,y1) (x2,y2) (x3,y3) (x4,y4)。
(cx,cy) 就是(x1,y1) (x2,y2) (x3,y3) (x4,y4)的中心点的坐标。关于w和h,我是简单的认为是两个对应横纵坐标差的均值,草图说明:
Citing DaSiamRPN
If you find DaSiamRPN and SiamRPN useful in your research, please consider citing:
@inproceedings{Zhu_2018_ECCV,
title={Distractor-aware Siamese Networks for Visual Object Tracking},
author={Zhu, Zheng and Wang, Qiang and Bo, Li and Wu, Wei and Yan, Junjie and Hu, Weiming},
booktitle={European Conference on Computer Vision},
year={2018}
}
@InProceedings{Li_2018_CVPR,
title = {High Performance Visual Tracking With Siamese Region Proposal Network},
author = {Li, Bo and Yan, Junjie and Wu, Wei and Zhu, Zheng and Hu, Xiaolin},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
摘要
视觉目标跟踪在这些年来已经成为一个基础的主题,许多基于深度学习的跟踪器在多个跟踪基准上已经取得了优越的性能。但是大多数人性能优越的跟踪器很难有实时速度。在这篇文章中,作者提出了孪生候选区域生成网络(Siamese region proposal network),简称Siamese-RPN,它能够利用大尺度的图像对离线端到端训练。具体来讲,这个结构包含用于特征提取的孪生子网络(Siamese subnetwork)和候选区域生成网络(region proposal subnetwork),其中候选区域生成网络包含分类和回归两条支路。在跟踪阶段,作者提出的方法被构造成为单样本检测任务(one-shot detection task)。作者预先计算孪生子网络中的模板支路,也就是第一帧,并且将它构造成一个检测支路中区域提取网络里面的一个卷积层,用于在线跟踪。得益于这些改良,传统的多尺度测试和在线微调可以被舍弃,这样做也大大提高了速度。Siamese-RPN跑出了160FPS的速度,并且在VOT2015,VOT2016和VOT2017上取得了领先的成绩。
1.引言
作者说现代的跟踪器分为两个分支,一个是基于相关滤波器的方法,不再赘述;另一个是利用非常好的深度特征的方法,此方法不更新模型,所以性能方面不如基于相关滤波的方法。当然,如果微调网络的话,速度会变得非常慢。 本文是离线训练好的基于深度学习跟踪器,主要是提出了Siamese-RPN结构,不同于标准的RPN,作者在相关特征图谱上提取候选区域,然后作者将模板分支上的目标外观信息编码到RPN特征中来判别前景和背景。 在跟踪阶段,作者将此任务视为单目标检测任务(one-shot detection),什么意思呢,就是把第一帧的BB视为检测的样例,在其余帧里面检测与它相似的目标。 综上所述,作者的贡献有以下三点:
提出了Siamese region proposal network,能够利用ILSVRC和Youtube-BB大量的数据进行离线端到端训练。 在跟踪阶段将跟踪任务构造出局部单目标检测任务。 在VOT2015, VOT2016和VOT2017上取得了领先的性能,并且速度能都达到160fps。
2.相关工作
2.2 RPN
说了这么多,那到底什么是RPN呢? RPN即Region Proposal Network,首先是在Faster-RCNN中提出的,用于目标检测。分为两个支路,一个用于分类前景和背景,一个用于边界框回归。
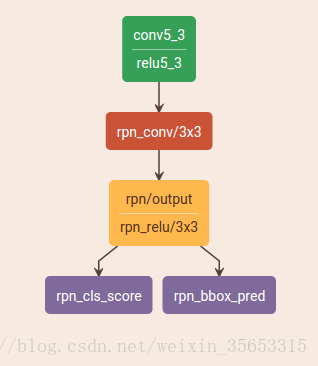
通俗来讲,就是用RPN来选择感兴趣区域的,即proposal extraction。例如,如果一个区域的p>0.5,则认为这个区域中可能是我们想要的类别中的某一类,具体是哪一类现在还不清楚。到此为止,网络只需要把这些可能含有物体的区域选取出来就可以了,这些被选取出来的区域又叫做ROI (Region of Interests),即感兴趣的区域。当然了,RPN同时也会在feature map上框定这些ROI感兴趣区域的大致位置,即输出Bounding Box。 这篇文章有详细的讲解:https://blog.csdn.net/qq_31442743/article/details/80775923 不得不去了解的几个知识有:
anchor box 翻译为锚点框,就是通过RPN对每个锚点上的k个矩形分类和回归,得到感兴趣区域。每个anhcor box要分前景和背景,所以cls=2k;而每个anchor box都有[x, y, w, h]对应4个偏移量,所以reg=4k
Bounding Box Regression 对每个锚点上预定义的k个框进行边界框回归,来更好的框住目标,具体操作会在后文讲。
2.3 One-shot learning
最常见的例子就是人脸检测,只知道一张图片上的信息,用这些信息来匹配出要检测的图片,这就是单样本检测,也可以称之为一次学习,可以观看吴恩达的相关视频课.
3.Siamese-RPN framework
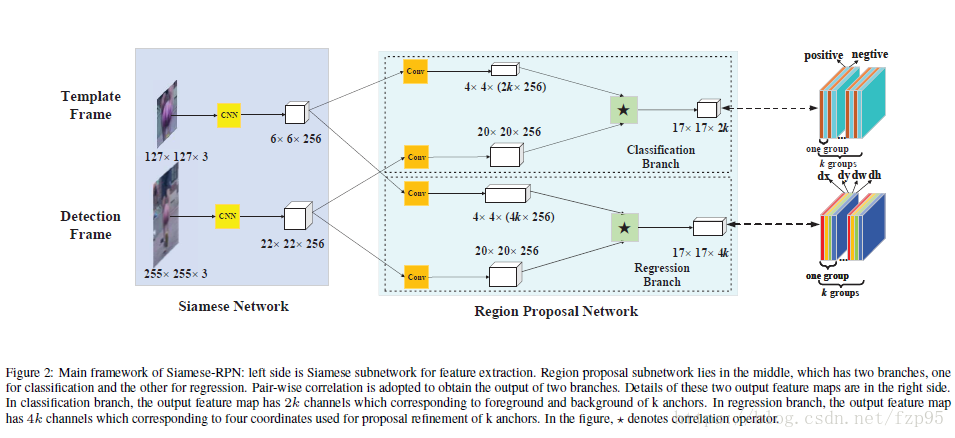
左边是孪生网络结构,上下支路的网络结构和参数完全相同,上面是输入第一帧的bounding box,靠此信息检测候选区域中的目标,即模板帧。下面是待检测的帧,显然,待检测帧的搜索区域比模板帧的区域大。中间是RPN结构,又分为两部分,上部分是分类分支,模板帧和检测帧的经过孪生网络后的特征再经过一个卷积层,模板帧特征经过卷积层后变为2k*256通道,k是anchor box数量,因为分为两类,所以是2k。下面是边界框回归支路,因为有四个量[x, y, w, h],所以是4k.右边是输出。
3.1 孪生特征提取子网络
预训练的AlexNet,剔除了conv2 conv4两层 是模板帧输出, 是检测帧输出
3.2 候选区域提取子网络
分类支路和回归支路分别对模板帧和检测帧的特征进行卷积运算(互相关操作): 包含2k个通道向量,中的每个点表示正负激励,通过softmax损失分类;包含4k个通道向量,每个点表示anchor和ground truth之间的dx,dy,dw,dh,通过smooth L1 loss:
Ax, Ay, Aw, Ah是anchor boxes中心点坐标和长宽; Tx, Ty, Tw, Th是ground truth boxes,为什么要这样呢,因为不同图片之间的尺寸存在差异,要对它们做正规化。
smoothL1损失:
3.3 训练阶段:端到端训练孪生RPN
因为跟踪中连续两帧的变化并不是很大,所以anchor只采用一种尺度,5种不同的长宽比[0.33, 0.5, 1, 2, 3] 当IoU大于0.6时是前景,小于0.3时是背景.
4. Tracking as one-shot detection
是标签,是孪生网络权重,是经过RPN操作
这张图直观的表示出了将跟踪当做的单样本检测任务,模板帧在RPN中经过卷积层, 和当作检测所用的核
经过网络后
那么怎么选择呢?分两步 第一步,舍弃掉距离中心太远的BB,只在一个比原始特征图小的固定正方形范围里选择,如下图:
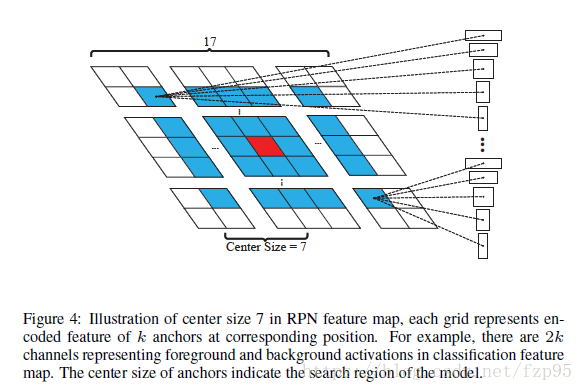
中心距离为7,仔细看图可以看出,每个网格都有k个矩形。 第二步,用余弦窗和尺度变化惩罚来对proposal进行排序,选最好的。余弦窗是为了抑制距离过大的,尺度惩罚是为了抑制尺度大的变化。具体公式可看论文。
用这些点对应的anchor box结合回归结果得出bounding box: 就是anchor的框,是最终得出的回归后的边界框 至此,proposals set就选好了。
然后再通过非极大抑制(NMS),顾名思义,就是将不是极大的框都去除掉,去除冗余的重叠框,具体操作就是先选择一个置信度最高的框,其余的框与之的IoU大于某个阈值,就剔除掉,从未处理的框中继续选一个得分最高的,重复上述过程。 最后得出最终的跟踪目标BB。
模板是和待检测图像做卷积,还是和proposal做卷积?只看流程图的话,没有提取proposal的过程啊?
从分类结果的特征图中选取了前K个点,然后对这前K个点的anchors做回归得到的propsal
3.2里面的星号好像不是卷积操作,看论文写的应该是计算相关性的操作
对,你说的对,这里的卷积严格意义上其实就是互相关操作,包括网络中卷积核的卷积也是互相关
原文:https://blog.csdn.net/fzp95/article/details/80982201
1,在做完SiamRPN之后,我们发现虽然跟踪的框已经回归地比较好了,但是响应的分数仍然相当不可靠,具体表现为在丢失目标的时候,分类的分数仍然比较高(例如0.8+),换句话说,其实我们推断SiamRPN只是学习到了objectness/non-objectness的区分,一个具体的例子见下图(左半部分):
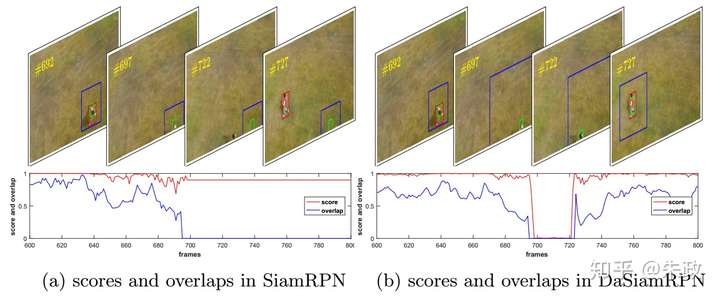
2, 之所以出现上面的问题,我们的结论是 训练过程中的样本不均衡造成的. 一个是正样本种类不够多,导致模型的泛化性能不够强;我们的解决方案是加入detection的图片数据, pair可以由静态图片通过数据增益生成;加入detection数据生成的正样本之后,模型的泛化性能得到了比较大的提升. 第二个样本不均衡来自于难例负样本,在之前的Siamese网络训练中, 负样本过于简单,很多事是没有语义信息的;我们的解决办法是用不同类之间的样本(还有同类的不同instance)构建难例负样本,从而增强分类器的判别能力. 不同种类的正负样本的构建可以参见下图. 以上两个改进大大改善了相应分数的质量,见上图的右半部分:在丢失目标的时候,相应分数随之变得很低,说明跟踪器的判别能力得到了改善.

3, 有了高质量的响应分数之后,一个bonus(奖金、额外补贴)是可以做long-term的tracking. 我们采用了一个比较简单local-to-global的扩展搜索区域方法,在UAV20L上面取得了state-of-the-art的结果:
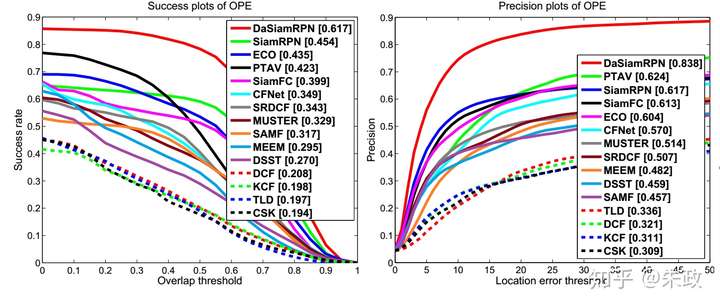
4, 在VOT实验方面,DaSiamRPN超过了ECO,速度是160+FPS. (看到这里还不点赞吗,哈哈), 下面是一些实验结果图:
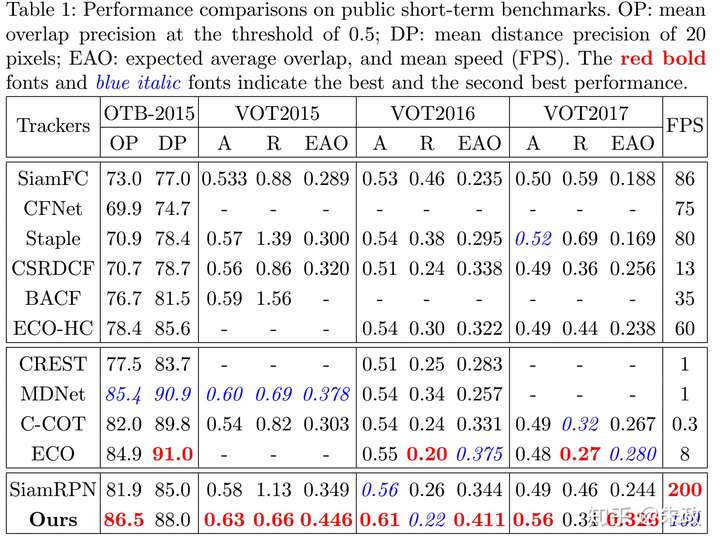
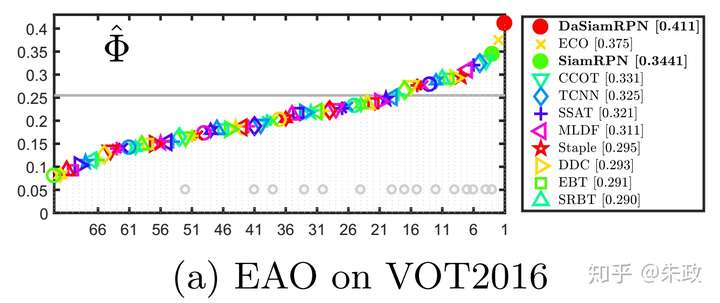
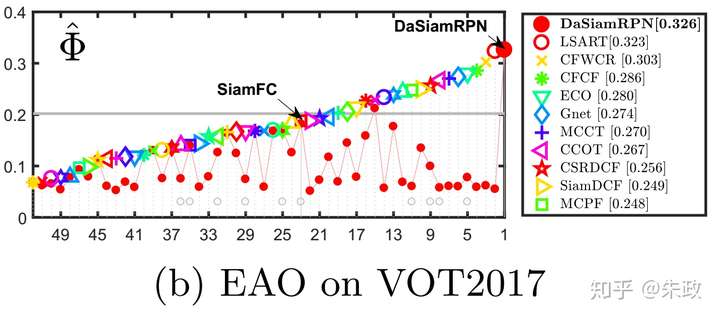
上面的VOT2017的结果(0.326)是三月份的,在参加VOT2018的时候,EAO已经来到了0.38+(手动优秀).
还有UAV123数据集上的实验结果:
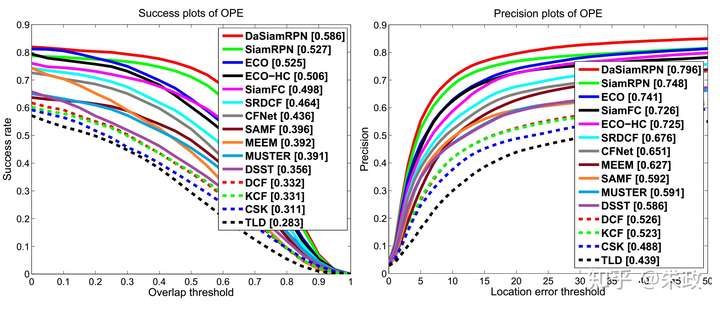
对了,还有ablation(消融)的分析(怎么感觉像在写rebuttal(反驳,反证)。。。):

以及不同GPU平台上的速度比较(话说老黄昨晚又双叒叕发布新显卡了。。。):

-
这是SiamRPN代码,用的DaSIamRPN的参数模型。不知大佬的DaSIamRPN代码在哪
-
这是DaSiamRPN,除去了在线更新部分
详细看了代码,感觉是Siam RPN的方法,没发现Distractor内容,性能受益于大量的数据增强以及高精度的检测,最近构思一个快速在线更新方案,受制于Siam FC的纵横比固定问题,使性能下降不少。
-
DaSiam采用了三种策略(训练样本均衡、抗相似干扰、扩大搜索范围),感觉对提升性能都是很有帮助的。VOT和UAV数据集上的结果也证明了这个。但是DASiam在OTB数据集上的结果并不是特别好,我感觉应该不止于此,你们有分析过原因吗?
-
嗯。。。我是觉得OTB有点饱和了。。。
-
感觉论文里Distractor-aware Incremental Learning 这一部分没交代清楚,知乎这里也没提呀 argmax计算出来的distractor q是要做什么? 看后面有一句貌似是说模型中有一个在线的分类器,使用q和z来训练这个分类器么?
-
论文里有明确说,The final selected object is denoted as q。是指最终确定的物体位置是q。
-
Hi, 请问你们在计算q,即寻找 和target相似度得分 与 和其他distractors的得分差值最大的proposal,还会用cosine window吗?还是不用cosine window直接在整个图片search?谢谢。
-
使用cosine window。只是在计算score的时候使用新的公式。
-
谢谢。想再多问一下,那个公式可以帮助我们找到一个最优结果的object,这个只是在inference阶段使用吗?在training阶段,还是像普通的SiamFc那样通过z和x的特征进行卷积直接找到最优的target object bbox?
-
是的。这是inference阶段的方法,为什么不加入训练当中,是因为这样会得失训练过程不充分。而且,还非常慢。在初期肯定发散了。(因为初期的instance feature不太好)
本团队凭借在视频跟踪领域丰富的研究积累,在实时目标跟踪任务中提出干扰对象感知的孪生神经网络(Distractor-aware Siamese Networks for Visual Object Tracking)。通过主动调节具有语义样本和简单样本的数据分布,增强网络的判别能力;同时,在网络架构方面进行了深入探索,将网络宽度进行提升,增大网络容量;动态调节网络搜索范围,以适应不同尺度目标的运动。最后取得了非常优异的跟踪精度。
网友阅读整理:
三个问题: 1.常见的siam类跟踪方法只能区分目标和无语义信息的背景,当有语义的物体是背景时,也就是有干扰物(distractor)时,表现不是很好。 2.大部分siam类跟踪器在跟踪阶段不能更新模型,训练好的模型对不同特定目标都是一样的。这样带来了高速度,也相应牺牲了精度。 3.在长时跟踪的应用上,siam类跟踪器不能很好的应对全遮挡、目标出画面等挑战。
针对这三个问题
1. 作者发现,训练数据中的非语义背景和具有语义的干扰物背景的数据不平衡进一步学习的主要障碍。高质量的训练数据非常重要,Diverse categories of positive pairs can promote the generalization ability,Semantic negative pairs can improve the discriminative ability.为此,在训练阶段,作者引入现有的检测数据集来充实正样本数据,以此来提升跟踪器的泛化能力;接着,作者又充实了困难负样本数据,以此来提升跟踪器的判别能力。如下图:
前一项工作(SiamRPN)所用的训练集ILSVRC2015-VID和Youtube-BB所包含的种类不太充分,为了提高跟踪器的泛化能力,作者在此基础上又引入了ILSVRC2015和COCO数据集静态图片,通过一系列增强手段(平移、调整大小、灰度化等)来扩充了正样本对的种类。 为了提高判别能力,在负样本中,作者发现有语义的背景和类内干扰物都很少,所以增加了不同类别的困难负样本来避免跟踪结果飘逸,以及增加了相同类别的困难负样本来更加关注目标的细节表达。
2. 数据上做了增强后,在跟踪特定目标时,还是很难将一般模型转化为特定视频域所用,这时候上下文信息就显得很重要了,为此作者设计了干扰物感知模型(distractor-aware module),怎么说呢? 也就是在跟踪时,上一帧上选择出好多proposals,最高的值是跟踪结果,通过非极大值抑制,选出大于某阈值的一些proposals就是干扰物didi,然后到跟踪帧时,响应得分要减去这些干扰物与搜索区域的响应,最终位置如下面公式所示,â a^是权重因子,设为0.5,每个干扰物的权重aiai设为1,
因为互相关操作是线性的,遵从结合律,所以可以写成下式:
加入增量学习:
这里βt=∑t−1i=0(η1−η)iβt=∑i=0t−1(η1−η)i,η=0.01 η=0.01 3. DaSiamRPN可以很好的应对长时跟踪问题,作者提出了在短时跟踪和失败情况的切换法,即跟踪失败时,采用局部到全局的搜索策略来重新检测目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号