STL
C++标准库体系结构与内核分析
第一讲
所谓泛型编程,就是使用template(模板)为主要工具来编写程序。
本课程以STL为标准、深层次地探讨泛型编程。
level 0:使用C++标准库
level 1:认识C++标准库
level 2:良好使用C++标准库
level 3:扩充C++标准库
C++ Standard Library
C++标准库
Standard Template Library
STL,标准模板库
标准库以头文件的形式呈现
-
C++标准库的头文件不带副档名(.h),例如#include
-
新式C语言头文件不带副档名(.h),例如#include
-
旧式C语言头文件带有副档名(.h),例如#include<stdio.h>
-
新式头文件内的组件封装于namespace“std”
-
using namespace std; or
-
using std::cout;(for example)
-
-
旧式头文件内的组件不封装于namespace“std”
#include<string>
#include<iostream>
#include<vector>
#include<algorithm>
#include<functional>
using namespace std;
重要网站:
- CPlusPlus.com
- CppReference.com
- gcc.gnu.org
书籍
- 《The C++ Standard Library》
- 《STL源码剖析》
第二讲
STL六大部件(Components):
- 容器(Constainers)
- 分配器(Allocators)
- 算法(Algorithms)
- 迭代器(Iterators)
- 适配器(Adapters)
- 防函式(Functors)

13 14行的意思是判断容器内从头到尾的元素是否大于等于40。
复杂度
- 1.O(1)或O(c):称为常数时间
- 2.O(n):称为线性时间
- 3.O(log2n):称为次线性时间
- 4.O(n^2):称为平方时间
- 5.O(n^3):称为立方时间
- 6.O(2^n):称为指数时间
- 7.O(nlog2n):介于线性及二次方成长的中间之行为模式
“前闭后开”区间
容器所指向的内存空间是一个“前闭后开”的区间,c.begin() 指向容器第一个元素,c.end()指向的是最后一个元素后面一个元素的位置。
//老版的遍历容器方式
Container<T> c;
Container<T>::iterator ite = c.begin();
for(; ite != c.end();++ite)
//新版的遍历方式(从C++11开始)
//for(del:coll) {statement}
for(int i:{2,3,5,7,9,13,17,19})
{
std::cout<<i<<std::endl;
}
std::vector<double> vec;
for(auto elem:vec)
{
std::cout<<elem<<std::endl;
}
//引用
for(auto& elem:vec)
{
elem*=3;
}
//auto关键字
list<string> c;
list<string>::iterator ite;
ite = ::find(c.begin(),c.end(),target);
//可以用auto
auto = ::find(c.begin(),c.end(),target);
第三讲
容器——结构与分类

Sequence:顺序、次序 Vector:栈 Deque:双向队列 Associative:相关联的 Unordered:无序的
Set:集合 Multiset:多重集合
C++ STL :vector封装数组,list封装了链表,map和set封装了二叉树(内部是红黑树/高度平衡二叉树)。
Map和Set的区别就是Map有key和value,Set就只有value。
Multi表示多重,就是value可以有多个。
以下测试程序之辅助函数
#include <iostream>
#include <string>
using namespace std;
const long ASIZE = 500L;
long get_a_target_long()
{
long target = 0;
cout << "target(0~" << RAND_MAX << "):";
cin >> target;
return target;
}
string get_a_target_string()
{
long target = 0;
char buf[10];
cout << "target(0~" << RAND_MAX << "):";
cin >> target;
snprintf(buf, 10 , "%d", target);//把target转换成字符串
return string(buf);
}
//比较函数,从小到大排序
//为了后面的快速排序法,比较大小
int compareLongs(const void* a, const void* b)
{
return (*(long*)a - *(long*)b);
}
int compareStrings(const void* a, const void* b)
{
if (*(string*)a > * (string*)b) return 1;
else if (*(string*)a < *(string*)b) return -1;
else return 0;
}
使用容器array
(前闭后闭)
#include <array>
#include <iostream>
#include <ctime>
#include <cstdlib> //qsort, bsearch, NULL
namespace jj01
{
void test_array()
{
cout << "\ntest_array().......... \n";
array<long, ASIZE> c; //第二个参数是数组的大小
clock_t timeStart = clock();
for (long i = 0; i < ASIZE; ++i)
{
c[i] = rand(); //放入随机数
}
//放入数组所需要的时间
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "array.size()= " << c.size() << endl;
cout << "array.front()= " << c.front() << endl;
cout << "array.back()= " << c.back() << endl;
//传回数组首元素的地址
cout << "array.data()= " << c.data() << endl;
long target = get_a_target_long();
timeStart = clock();
//将数组从小到大排序
qsort(c.data(), ASIZE, sizeof(long), compareLongs);
//用二分法去查找
long* pItem = (long*)bsearch(&target, (c.data()), ASIZE, sizeof(long), compareLongs);
cout << "qsort()+bsearch(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != NULL)
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
}
int main()
{
jj01::test_array();
return 0;
}
测试结果:
第四讲
使用容器vector
(前闭后开)
#include <vector>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
#include <algorithm> //sort()
//不同的namespace变量就不会重名,也能够知道要引用哪些头文件,便于复习代码
namespace jj02
{
void test_vector(long& value)
{
cout << "\ntest_vector().......... \n";
//用到变量时再定义声明
vector<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
//用try和catch处理异常,如果输入的元素数量大于最大容器数量,则发出异常
try
{ //把随机数转化为字符串放进buf中,10是要写入的字符的最大数目
snprintf(buf, 10, "%d", rand());
//把元素放到尾部,vector会动态分配空间,当溢出的时候空间就呈二倍增长
c.push_back(string(buf));
}
catch (exception & p)
{
cout << "i=" << i << " " << p.what() << endl;
//曾經最高 i=58389486 then std::bad_alloc
abort(); //发生异常则退出
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "vector.max_size()= " << c.max_size() << endl;
cout << "vector.size()= " << c.size() << endl;
cout << "vector.front()= " << c.front() << endl;
cout << "vector.back()= " << c.back() << endl;
cout << "vector.data()= " << c.data() << endl;
//vector的容量(我测试的结果有点奇怪,不是二倍递增地分配空间)
cout << "vector.capacity()= " << c.capacity() << endl << endl;
string target = get_a_target_string();
{
timeStart = clock();
//加::是指全局模板函数
auto pItem = ::find(c.begin(), c.end(), target);
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl << endl;
else
cout << "not found! " << endl << endl;
}
{
timeStart = clock();
sort(c.begin(), c.end());
cout << "sort(), milli-seconds : " << (clock() - timeStart) << endl;
timeStart = clock();
string* pItem = (string*)::bsearch(&target, (c.data()),
c.size(), sizeof(string), compareStrings);
cout << "bsearch(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != NULL)
cout << "found, " << *pItem << endl << endl;
else
cout << "not found! " << endl << endl;
}
c.clear();
//test_moveable(vector<MyString>(), vector<MyStrNoMove>(), value);
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj02::test_vector(value);
return 0;
}
测试结果:
第五讲
使用容器list
list就是双向链表
#include <list>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <algorithm> //find()
#include <iostream>
#include <ctime>
namespace jj03
{
void test_list(long& value)
{
cout << "\ntest_list().......... \n";
list<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "list.size()= " << c.size() << endl;
cout << "list.max_size()= " << c.max_size() << endl; //357913941
cout << "list.front()= " << c.front() << endl;
cout << "list.back()= " << c.back() << endl;
string target = get_a_target_string();
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target);
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
timeStart = clock();
//list自带的sort函数
c.sort();
cout << "c.sort(), milli-seconds : " << (clock() - timeStart) << endl;
c.clear();
//test_moveable(list<MyString>(), list<MyStrNoMove>(), value);
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj03::test_list(value);
return 0;
}
测试结果:
使用容器forward_list
单向链表
#include <forward_list>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj04
{
void test_forward_list(long& value)
{
cout << "\ntest_forward_list().......... \n";
forward_list<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.push_front(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "forward_list.max_size()= " << c.max_size() << endl; //536870911
cout << "forward_list.front()= " << c.front() << endl;
//没有c.back() c.size这种成员函数
string target = get_a_target_string();
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target);
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
timeStart = clock();
c.sort();
cout << "c.sort(), milli-seconds : " << (clock() - timeStart) << endl;
c.clear();
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj04::test_forward_list(value);
return 0;
}
测试结果:
使用容器slist
这也是一个单向链表
#include <ext\slist>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj10
{
void test_slist(long& value)
{
cout << "\ntest_slist().......... \n";
__gnu_cxx::slist<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.push_front(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
}
}
使用容器deque
deque就是队列和栈的结合,两端开口, 双向进出,在内存中是分段存取

#include <deque>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj05
{
void test_deque(long& value)
{
cout << "\ntest_deque().......... \n";
deque<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "deque.size()= " << c.size() << endl;
cout << "deque.front()= " << c.front() << endl;
cout << "deque.back()= " << c.back() << endl;
cout << "deque.max_size()= " << c.max_size() << endl; //1073741821
string target = get_a_target_string();
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target);
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
timeStart = clock();
sort(c.begin(), c.end());
cout << "sort(), milli-seconds : " << (clock() - timeStart) << endl;
c.clear();
//test_moveable(deque<MyString>(), deque<MyStrNoMove>(), value);
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj05::test_deque(value);
return 0;
}
测试结果: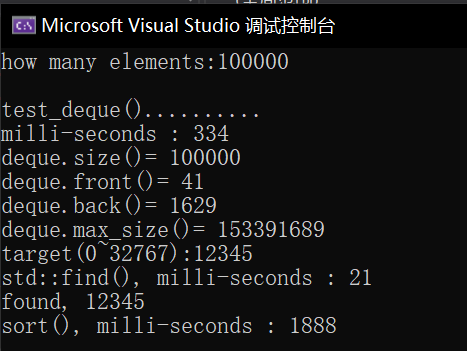
使用容器stack
栈 先进后出
#include <stack>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj17
{
void test_stack(long& value)
{
cout << "\ntest_stack().......... \n";
stack<string> c;
char buf[10];
clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.push(string(buf));
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "stack.size()= " << c.size() << endl;
cout << "stack.top()= " << c.top() << endl;
c.pop();
cout << "stack.size()= " << c.size() << endl;
cout << "stack.top()= " << c.top() << endl;
}
使用容器queue
队列 先进先出
#include <queue>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj18
{
void test_queue(long& value)
{
cout << "\ntest_queue().......... \n";
queue<string> c;
char buf[10];
clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.push(string(buf));
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "queue.size()= " << c.size() << endl;
cout << "queue.front()= " << c.front() << endl;
cout << "queue.back()= " << c.back() << endl;
c.pop();
cout << "queue.size()= " << c.size() << endl;
cout << "queue.front()= " << c.front() << endl;
cout << "queue.back()= " << c.back() << endl;
}
技术上不将stack和queue称为容器,把它们叫做容器适配器(containers adapters)。
第六节
关联式容器
使用容器multiset
红黑树所形成的
#include <set>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj06
{
void test_multiset(long& value)
{
cout << "\ntest_multiset().......... \n";
multiset<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
//放数字的同时会给数字进行排序
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "multiset.size()= " << c.size() << endl;
cout << "multiset.max_size()= " << c.max_size() << endl; //214748364
string target = get_a_target_string();
{
timeStart = clock();
//使用标准库的find查找元素
auto pItem = find(c.begin(), c.end(), target); //比 c.find(...) 慢很多
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
{
timeStart = clock();
//使用multiset自带的find
auto pItem = c.find(target); //比 std::find(...) 快很多
cout << "c.find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
c.clear();
//test_moveable(multiset<MyString>(), multiset<MyStrNoMove>(), value);
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj06::test_multiset(value);
return 0;
}
测试结果:
使用容器multimap
multimap和multiset的区别就是multimap多了一个键值key,multiset只有value。
#include <map>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj07
{
void test_multimap(long& value)
{
cout << "\ntest_multimap().......... \n";
//key是long类型,string是value
multimap<long, string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
//multimap 不可使用 [] 做 insertion
//pair把i和buf组合到c中,pair是标准库的函数
c.insert(pair<long, string>(i, buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "multimap.size()= " << c.size() << endl;
cout << "multimap.max_size()= " << c.max_size() << endl; //178956970
long target = get_a_target_long();
timeStart = clock();
//通过键值找元素
auto pItem = c.find(target);
cout << "c.find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
//(*pItem)取出的那一对,value是第二个元素second
cout << "found, value=" << (*pItem).second << endl;
else
cout << "not found! " << endl;
c.clear();
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj07::test_multimap(value);
return 0;
}
测试结果:
使用容器unordered_multiset
刚刚的那两种容器是用红黑树实现的,而unordered_multi则是用hashtable哈希表实现的,结构如图所示:

#include <unordered_set>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj08
{
void test_unordered_multiset(long& value)
{
cout << "\ntest_unordered_multiset().......... \n";
unordered_multiset<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "unordered_multiset.size()= " << c.size() << endl;
cout << "unordered_multiset.max_size()= " << c.max_size() << endl;
//篮子比元素多:有些篮子挂元素,有些篮子不挂
cout << "unordered_multiset.bucket_count()= " << c.bucket_count() << endl;
cout << "unordered_multiset.load_factor()= " << c.load_factor() << endl;
cout << "unordered_multiset.max_load_factor()= " << c.max_load_factor() << endl;
cout << "unordered_multiset.max_bucket_count()= " << c.max_bucket_count() << endl;
//将前二十个篮子挂几个元素打印出来
for (unsigned i = 0; i < 20; ++i) {
cout << "bucket #" << i << " has " << c.bucket_size(i) << " elements.\n";
}
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); //比 c.find(...) 慢很多
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
{
timeStart = clock();
auto pItem = c.find(target); //比 std::find(...) 快很多
cout << "c.find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
c.clear();
//test_moveable(unordered_multiset<MyString>(), unordered_multiset<MyStrNoMove>(), value);
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj08::test_unordered_multiset(value);
return 0;
}
测试结果:
使用容器unordered_multimap
#include <unordered_map>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj09
{
void test_unordered_multimap(long& value)
{
cout << "\ntest_unordered_multimap().......... \n";
unordered_multimap<long, string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
//multimap 不可使用 [] 進行 insertion
c.insert(pair<long, string>(i, buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "unordered_multimap.size()= " << c.size() << endl;
cout << "unordered_multimap.max_size()= " << c.max_size() << endl; //357913941
long target = get_a_target_long();
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, value=" << (*pItem).second << endl;
else
cout << "not found! " << endl;
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj09::test_unordered_multimap(value);
return 0;
}
测试结果:
以上四种容器使用于需要大量搜索元素的情况。
前面的四种都是multi,值key可以有多个,接下来的四种容器key是独一无二的。
使用容器set
不可以有重复的元素/重复的元素不会放进去。
#include <set>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj13
{
void test_set(long& value)
{
cout << "\ntest_set().......... \n";
set<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
//重复的元素不会放进去,所以只有30000+元素
cout << "set.size()= " << c.size() << endl;
cout << "set.max_size()= " << c.max_size() << endl; //214748364
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); //比 c.find(...) 慢很多
cout << "std::find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
{
timeStart = clock();
auto pItem = c.find(target); //比 std::find(...) 快很多
cout << "c.find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj13::test_set(value);
return 0;
}
测试结果:
使用容器map
#include <map>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj14
{
void test_map(long& value)
{
cout << "\ntest_map().......... \n";
map<long, string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c[i] = string(buf);
}
catch (exception & p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock() - timeStart) << endl;
cout << "map.size()= " << c.size() << endl;
cout << "map.max_size()= " << c.max_size() << endl; //178956970
long target = get_a_target_long();
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(), milli-seconds : " << (clock() - timeStart) << endl;
if (pItem != c.end())
cout << "found, value=" << (*pItem).second << endl;
else
cout << "not found! " << endl;
c.clear();
}
}
int main()
{
long value;
cout << "how many elements:";
cin >> value;
jj14::test_map(value);
return 0;
}
测试结果:
使用容器unordered_set
总的来说,unordered_set 容器具有以下几个特性:
- 不再以键值对的形式存储数据,而是直接存储数据的值;
- 容器内部存储的各个元素的值都互不相等,且不能被修改。
- 不会对内部存储的数据进行排序(这和该容器底层采用哈希表结构存储数据有关,可阅读《C++ STL无序容器底层实现原理》一文做详细了解)
//---------------------------------------------------
#include <unordered_set>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj15
{
void test_unordered_set(long& value)
{
cout << "\ntest_unordered_set().......... \n";
unordered_set<string> c;
char buf[10];
clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "unordered_set.size()= " << c.size() << endl;
cout << "unordered_set.max_size()= " << c.max_size() << endl; //357913941
cout << "unordered_set.bucket_count()= " << c.bucket_count() << endl;
cout << "unordered_set.load_factor()= " << c.load_factor() << endl;
cout << "unordered_set.max_load_factor()= " << c.max_load_factor() << endl;
cout << "unordered_set.max_bucket_count()= " << c.max_bucket_count() << endl;
for (unsigned i=0; i< 20; ++i) {
cout << "bucket #" << i << " has " << c.bucket_size(i) << " elements.\n";
}
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = find(c.begin(), c.end(), target); //比 c.find(...) 慢很多
cout << "std::find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
{
timeStart = clock();
auto pItem = c.find(target); //比 std::find(...) 快很多
cout << "c.find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
}
}
测试结果:
使用容器unordered_map
#include <unordered_map>
#include <stdexcept>
#include <string>
#include <cstdlib> //abort()
#include <cstdio> //snprintf()
#include <iostream>
#include <ctime>
namespace jj16
{
void test_unordered_map(long& value)
{
cout << "\ntest_unordered_map().......... \n";
unordered_map<long, string> c;
char buf[10];
clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
try {
snprintf(buf, 10, "%d", rand());
c[i] = string(buf);
}
catch(exception& p) {
cout << "i=" << i << " " << p.what() << endl;
abort();
}
}
cout << "milli-seconds : " << (clock()-timeStart) << endl;
cout << "unordered_map.size()= " << c.size() << endl; //357913941
cout << "unordered_map.max_size()= " << c.max_size() << endl;
long target = get_a_target_long();
timeStart = clock();
//! auto pItem = find(c.begin(), c.end(), target); //map 不適用 std::find()
auto pItem = c.find(target);
cout << "c.find(), milli-seconds : " << (clock()-timeStart) << endl;
if (pItem != c.end())
cout << "found, value=" << (*pItem).second << endl;
else
cout << "not found! " << endl;
}
}
测试结果
第七节
分配器之测试
容器的背后需要一个东西支持它对内存的使用,它就是分配器allocator。每个容器都有一个默认的分配器。
使用分配器allocator
这部分的头文件ext无法引用,以后再补笔记
第八节
源代码之分布
接下来需要的基础:C++基本语法 模板 数据结构和算法。
第九节
面向对象编程(OOP)VS 泛型编程(GP)
OOP企图将数据和方法关联在一起
类list中就有方法sort

为什么list不能使用标准库的sort函数?
- 因为标准库的标准库中对迭代器的操作必须要随机访问迭代器才能实现,随机访问迭代器需要容器存放在一段连续的内存空间中,而链表中的元素在内存中的存储地址是分散的,所以必须写list类自己的sort函数。
GP却是将数据和方法分开来

第一个sort就是头尾定位容器范围,第二个sort多加了一个判断条件。
采用GP的优点:
- 容器和算法团队可各自闭门造车,其间以迭代器联通即可。
- 算法通过迭代器确定操作范围,并通过迭代器取用容器元素。**

第十节
阅读源代码需要的基础:操作符重载和模板
操作符重载
四种操作符不能被重载: :: . .* ?:
** <> & | 这几个也不能被重载
当运算符出现在表达式中,且其操作数中至少有一个具有类类型或枚举类型时,就会使用重载解析来确定要在其签名与以下所有函数之间调用的用户定义函数:

(这个表格就是告诉你一个操作数/两个操作数的运算符怎么去写,哪些可以写成全局函数,哪些可以写成类的成员函数。)
//list迭代器的操作符重载
template<class T,class Ref,class Ptr>
struct _list_iterator
{
......
reference operator*() const {return (*node).data;}
pointer operator->() const {return &(operator*());}
self& operator++() {node = (link_type)((*node).next);return *this;}
self operator++(int) {self tmp=*this; ++*this; return tmp;}
}
模板
类模板

函数模板

用T前面用class或者typename都可以,class是老式的写法。
成员模板(目前用不到,先放掉)
特化
既然能对多种类型的数据进行泛化处理,那么当某种类型需要更好的写法,也就可以对它进行特化。
三种语法写法:
例一:

例二:

黄色部分其实就是template<>,特化的另一种写法而已。
例三:

偏特化 Partial Specialization

第十一讲
分配器
operator new() 和 malloc()
归结都是使用malloc函数。
operator new()函数

malloc分配的内存就如上右图所示,你所要求的大小是size,而malloc分配内存的时候会搭配上下这些东西。这些细节会在内存管理中讲解。你要的size内存越大,上下分配的其他部分占比就越小;你要的越小,附加(overhead)的比例越大。
内存上下的两块红色部分被称为cookie,本质是一个指针,用于记录这块内存的大小,但容器中每个元素的大小都是一样的,所以可以不需要这部分,G2.9就从这方面去优化。
VC++6.0对分配器的使用

不同的编译器对于分配器的使用有所不同,上图是VC6STL对于分配器的使用。他们默认使用的分配器都是紫色字体allocator,它是个模板,下图就是allocator的实现。

allocator的实现调用allocate,allocate中调用_Allocate, _Allocate中调用operator new(),前面提到operator new()中使用的是malloc,所以一层一层调用下来最终是调用malloc。另外allocator还有一个deallocate函数是用于回收内存的。
VC++的分配器没有任何独特设计,就只是调用C的malloc分配内存,这就会消耗很多很多额外空间(overhead),接口设计也不太好直接用,上面灰框allocate< int>()就表示通过分配器建立一个临时对象。
Builder Compiler5.0对分配器的使用


和vc没什么区别,没有任何特殊设计,还是原来缺陷,浪费很多overhead。
但bc allocator第二参数有默认值,建立分配器临时对象会比较简单。
GNU Compiler Collection对分配器的使用
GC2.9对分配器的使用

都一样,最终使用的都是malloc和free,会造成很多额外的开销。
注释中告诉你,它们的容器用的都是别的分配器。
实际使用的分配器就是下图alloc。

为了尽量减少cookie浪费的内存,G2.9设计了十六条链表,每一条链表负责某一特定大小的区块,第1条链表负责8个字节大小的区域,第8条链表负责7*8=56字节的区域,第16条链表负责16 * 8 =128bit。容器的元素大小会自动调节到稍大的链表中,比如容器中有50个容器,就自动到第八条链表56bit的区域,就可以有效减少cookie。假设有100w个元素,那么能剩下800w字节。

GC4.9对分配器的使用


从以上两张图可以看出来,到了GC4.9又回到了之前调用malloc和free的分配器,会浪费很多内存。
不过在G4.9的标准库里有很多扩充的allocators,而其中pool alloc就是G2.9的alloc。
8是每条链表的空间大小;128是链表的最大空间;128/8是链表的数量,由此可以看出和刚刚G2.9的设计一模一样。


这个图是不同容器之间的关联性。以缩排的形式表达“基生与衍生层”的关系。这里的衍生不是“继承”,而是复合。
意思就是set、map……里面有一个红黑树做支撑;heap、priority_queue里面有一个vector。

第十三讲
深度探索list
容器list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号