Python Rabbitmq的解析
关于python的queue介绍
关于python的队列,内置的有两种,一种是线程queue,另一种是进程queue,但是这两种queue都是只能在同一个进程下的线程间或者父进程与子进程之间进行队列通讯,并不能进行程序与程序之间的信息交换,这时候我们就需要一个中间件,来实现程序之间的通讯。
RabbitMQ
MQ并不是python内置的模块,而是一个需要你额外安装(ubunto可直接apt-get其余请自行百度。)的程序,安装完毕后可通过python中内置的pika模块来调用MQ发送或接收队列请求。接下来我们就看几种python调用MQ的模式(作者自定义中文形象的模式名称)与方法。
具体流程如下图所示:
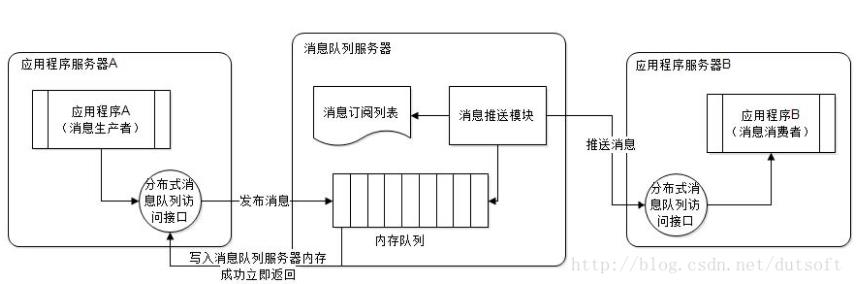
一、轮询的消费模式:
即将消息循环发送给不同的消费者,如:消息1,3,5发送给消费者1;消息2,4,6发送给消费者2
发送端:
import pika ''' 轮询的消费模式:即多个客户端同时连接同一个队列,这里面的数据就是以轮询发方式消费数据的 ''' credentials = pika.PlainCredentials('wallace', 'wallace123') #rabbitmq队列创建的用户名,告诉服务器是这个用户要使用队列 connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.174.130',credentials=credentials)) #连接上队列服务器 credentials凭证 channel = connection.channel() #建立了rabbit 协议的通道 # 声明queue channel.queue_declare(queue='hello') #参数是声明的队列名 channel.basic_publish(exchange='', #交换机在广播模式中会用到 routing_key='hello', #指定要向那个队列发送数据 body='Hello wallace!') #要向队列发送哪些数据 print(" [x] Sent 'Hello wallace!'") connection.close() #这里发送完关闭队列
接收端:
import pika import time credentials = pika.PlainCredentials('wallace', 'wallace123') #申明那个用户连接上队列服务器的 connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.174.130',credentials=credentials)) channel = connection.channel() #建立连接通道 channel.queue_declare(queue='hello') #申明queue def callback(ch, method, properties, body): #定义回调函数 print("received msg...start processing....",body) time.sleep(5) print(" [x] msg process done....",body) channel.basic_consume(callback, #接收完毕后执行的函数 queue='hello', #申明向那个队列取数据 no_ack=True) #自动应答,false是手动应答 print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() #开始接收数据
二,队列消息持久化
消息持久化,将消息写入硬盘中。 RabbitMQ不允许你重新定义一个已经存在、但属性不同的queue。需要申明一个持久化的消息队列即在申明队列时:durable=True,同时标记消息为持久化的 - 要通过设置 delivery_mode 属性为 2来实现。
消息持久化的注意点:
标记消息为持久化并不能完全保证消息不会丢失,尽管已经告诉RabbitMQ将消息保存到磁盘,但RabbitMQ接收到的消息在还没有保存的时候,仍然有一个短暂的时间窗口。RabbitMQ不会对每个消息都执行同步 --- 可能只是保存到缓存cache还没有写入到磁盘中。因此这个持久化保证并不是很强,但这比我们简单的任务queue要好很多,如果想要很强的持久化保证,可以使用 publisher confirms。
发送端:
import pika import time ''' 队列持久化:当rabbitMQ意外宕机时,可能会有持久化保存队列的需求(队列中的消息不消失) ''' credentials = pika.PlainCredentials('wallace', 'wallace123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.174.128',credentials=credentials)) channel = connection.channel() # 声明queue channel.queue_declare(queue='task_queue',durable=True) #durable耐久的持久的。持久化队列 import sys message = ' '.join(sys.argv[1:]) or "Hello World! %s" % time.time() channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, # make message persistent让队列里的消息持久化 ) ) print(" [x] Sent %r" % message) connection.close()
安全接收
import pika, time credentials = pika.PlainCredentials('wallace', 'wallace123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.174.128',credentials=credentials)) channel = connection.channel() def callback(ch, method, properties, body): print(" [x] Received %r" % body) time.sleep(20) print(" [x] Done") print("method.delivery_tag", method.delivery_tag) ch.basic_ack(delivery_tag=method.delivery_tag) #ackownledgement channel.basic_consume(callback,queue='task_queue',) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
消息订阅发布
exchange:交换机。生产者不是将消息发送给队列,而是将消息发送给交换机,由交换机决定将消息发送给哪个队列。所以exchange必须准确知道消息是要送到哪个队列,还是要被丢弃。因此要在exchange中给exchange定义规则,所有的规则都是在exchange的类型中定义的。
exchange有4个类型:direct, topic, headers ,fanout
之前,我们并没有讲过exchange,但是我们仍然可以将消息发送到队列中。这是因为我们用的是默认exchange.也就是说之前写的:exchange='',空字符串表示默认的exchange。
2.1 fanout形式
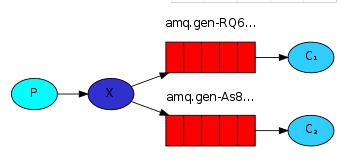
import pika import sys ''' 将消息发送到交换机,交换机根据那个客户端订阅了服务端,进行消息分发 生产者将消息发送给所有消费者,如果某个消费者没有收到当前消息,就再也收不到了 ''' credentials = pika.PlainCredentials('wallace', 'wallace123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.174.128',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='logs',exchange_type='fanout') #广播类型设置类型外fanout,创建一个fanout广播类型的交换机,不需要指定队列 message = ' '.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange='logs', #设置广播类型时需要加上这个设置交换机 routing_key='', #在fanout类型中,绑定关键字routing_key必须忽略,写空即可 body=message) print(" [x] Sent %r" % message) connection.close()
广播接收
import pika credentials = pika.PlainCredentials('wallace', 'wallace123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.174.128',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='logs', exchange_type='fanout') result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_name = result.method.queue channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name,no_ack=True) channel.start_consuming()
direct形式
direct:关键字类型。功能:交换机根据生产者消息中含有的不同的关键字将消息发送给不同的队列,消费者根据不同的关键字从不同的队列取消息
生产者:不用创建对列
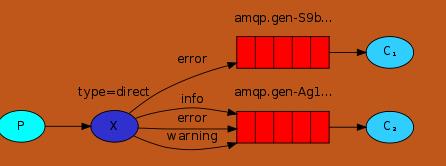
import pika import sys ''' direct关键字类型。功能:交换机根据生产者消息中含有的不同的关键字将消息发送给不同的队列, 消费者根据不同的关键字从不同的队列取消息,即将消息进行分组,给在该组的队列发送数据 ''' credentials = pika.PlainCredentials('wallace', 'wallace123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.174.128',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='direct_logs',exchange_type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info' #严重程度,级别 #severity这里只能为一个字符串,这里为‘info’表明本生产者只将下面的message发送到info队列中,消费者也只能从info队列中接收info消息 message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='direct_logs', routing_key=severity, #关键字不能为空 body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
direct接收
import pika import sys credentials = pika.PlainCredentials('wallace', 'wallace123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.174.128',credentials=credentials)) channel = connection.channel() channel.exchange_declare(exchange='direct_logs',exchange_type='direct') result = channel.queue_declare(exclusive=True) #创建随机队列,当消费者与rabbitmq断开连接时,这个队列将自动删除。 queue_name = result.method.queue #分配随机队列的名字。 severities = sys.argv[1:] or ['info','err']#可以接收绑定关键字info或err的消息,列表中也可以只有一个 if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange='direct_logs',queue=queue_name, routing_key=severity) #该消费者绑定的关键字。 print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) #消费者接收消息后,不给rabbimq回执确认。 channel.start_consuming() #循环等待消息接收。
精准rabbitmq
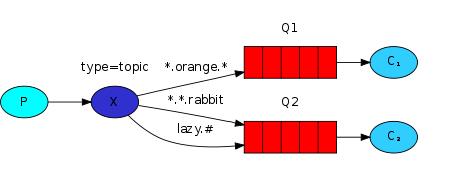
import pika import sys ''' 发送到一个 topics交换机的消息,它的 routing_key不能是任意的 -- 它的routing_key必须是一个用小数点分割的单词列表。 这个字符可以是任何单词,但是通常是一些指定意义的字符。比如:“stock.usd.nyse","nyse.vmw","quick.orange.rabbit". 这里可以是你想要路由键的任意字符。最高限制为255字节。 生产者与消费者的routing_key必须在同一个表单中。 Topic交换的背后的逻辑类似直接交换(direct) -- 包含特定关键字的消息将会分发到所有匹配的关键字队列中。然后有两个重要的特殊情况: 绑定键值: > * (星) 可代替一个单词 > # (井) 可代替0个或多个单词 ''' import pika import sys username = 'wt' #指定远程rabbitmq的用户名密码 pwd = '111111' user_pwd = pika.PlainCredentials(username, pwd) s_conn = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.240', credentials=user_pwd))#创建连接 channel = s_conn.channel() #在连接上创建一个频道 channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 创建模糊匹配类型的exchange。。 routing_key = '[warn].kern'#这里关键字必须为点号隔开的单词,以便于消费者进行匹配。引申:这里可以做一个判断,判断产生的日志是什么级别,然后产生对应的routing_key,使程序可以发送多种级别的日志 message = 'Hello World!' channel.basic_publish(exchange='topic_logs',#将交换机、关键字、消息进行绑定 routing_key=routing_key, # 绑定关键字,将队列变成[warn]日志的专属队列 body=message) print(" [x] Sent %r:%r" % (routing_key, message)) s_conn.close()
topic接收
import pika import sys username = 'wt'#指定远程rabbitmq的用户名密码 pwd = '111111' user_pwd = pika.PlainCredentials(username, pwd) s_conn = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.240', credentials=user_pwd))#创建连接 channel = s_conn.channel()#在连接上创建一个频道 channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 声明exchange的类型为模糊匹配。 result = channel.queue_declare(exclusive=True) # 创建随机一个队列当消费者退出的时候,该队列被删除。 queue_name = result.method.queue # 创建一个随机队列名字。 binding_keys = ['[warn]', 'info.*']#绑定键。‘#’匹配所有字符,‘*’匹配一个单词。这里列表中可以为一个或多个条件,能通过列表中字符匹配到的消息,消费者都可以取到 if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys:#通过循环绑定多个“交换机-队列-关键字”,只要消费者在rabbitmq中能匹配到与关键字相应的队列,就从那个队列里取消息 channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True)#不给rabbitmq发送确认 channel.start_consuming()#循环接收消息
牛逼的远程RPC
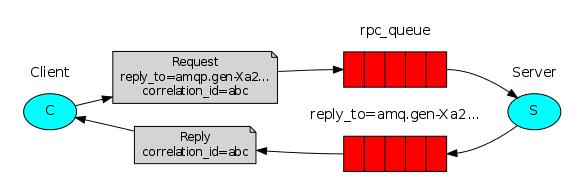
import pika import time ''' 前面的例子都有个共同点,就是发送端发送消息出去后没有结果返回。如果只是单纯发送消息,当然没有问题了, 但是在实际中,常常会需要接收端将收到的消息进行处理之后,返回给发送端。 处理方法描述:发送端在发送信息前,产生一个接收消息的临时队列,该队列用来接收返回的结果。其实在这里接收端、 发送端的概念已经比较模糊了,因为发送端也同样要接收消息,接收端同样也要发送消息,所以这里笔者使用另外的示例来演示这一过程。 ''' credentials = pika.PlainCredentials('alex', 'alex123') connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.14.52',credentials=credentials)) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n - 1) + fib(n - 2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) #定义需要返回的数据 ch.basic_publish(exchange='', routing_key=props.reply_to, properties=pika.BasicProperties(correlation_id= \ props.correlation_id), #correlation_id : 用来关联RPC的请求与应答。 body=str(response)) #将请求后得到的数据返回 ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) #接收到队列里的请求后执行on_request channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming()
rpc接收
import uuid import pika class FibonacciRpcClient(object): def __init__(self): credentials = pika.PlainCredentials('alex', 'alex123') self.connection = pika.BlockingConnection(pika.ConnectionParameters( '192.168.14.52', credentials=credentials)) channel = self.connection.channel() self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True,#准备接受命令结果 queue=self.callback_queue) def on_response(self, ch, method, props, body): """"callback方法""" if self.corr_id == props.correlation_id: self.response = body def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) #唯一标识符 self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id, ), body=str(n)) count = 0 while self.response is None: self.connection.process_data_events() #检查队列里有没有新消息,但不会阻塞 count +=1 print("check...",count) return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(5) print(" [.] Got %r" % response)
