Spark 学习(五)广播变量和累加器
一,概述
二,广播变量broadcast variable
2.1 定义广播变量的原因
2.2 图解广播变量
2.3 定义广播变量
2.4 还原广播变量
2.5 定义注意事项
三,累加器
3.1 为什么要将一个变量定义为一个累加器
3.2 图解累加器
3.3 定义累加器
3.4 还原累加器
3.5 定义注意事项
正文
一,概述
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变(broadcast variable)和累加器(accumulator)
二,广播变量broadcast variable
2.1 定义广播变量的原因
广播变量用来高效分发较大的对象。向所有工作节点发送一个 较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发 送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起 来都很顺手。
2.2 图解广播变量
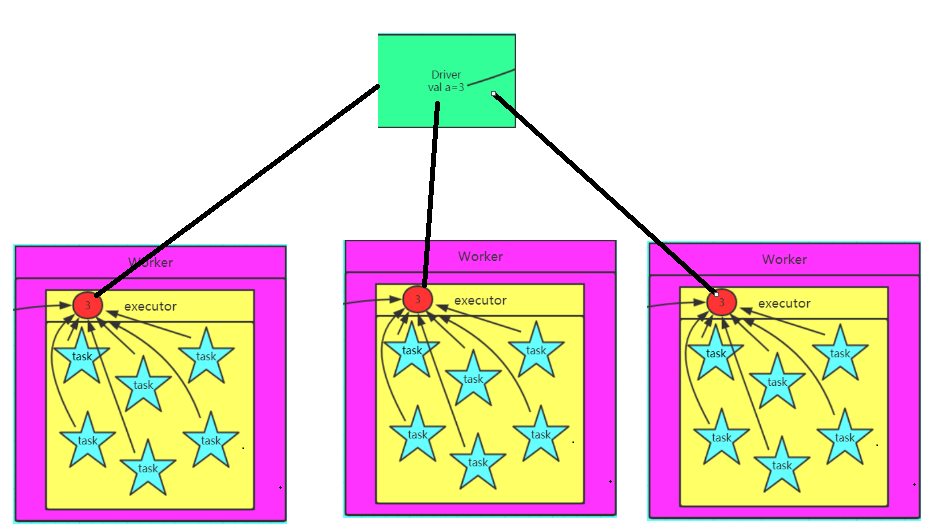
2.3 定义广播变量
val a = 3
val broadcast = sc.broadcast(a)
2.4 还原广播变量
val c = broadcast.value
2.5 定义注意事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
6、变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
2.6 广播变量应用实例
实例描述:有一些访问数据,需要根据访问的IP获取对于IP的访问地址,同时求出每个访问地址的数量。因为每一个IP段会对应一个区域地址。也就是映射关系。我们就可以通过IP还对应这些访问地址。
工具类:
package cn.edu360.sparkThree import scala.io.{BufferedSource, Source} object MyUtils { // 解析IP段对应的省份,将这些省份隐式到IP段 def readRules(path: String): Array[(Long, Long, String)]={ val bf: BufferedSource = Source.fromFile(path) val lines: Iterator[String] = bf.getLines() val rules: Array[(Long, Long, String)] = lines.map(line => { val fields: Array[String] = line.split("[|]") val startNum: Long = fields(2).toLong val endNum: Long = fields(3).toLong val privince: String = fields(6) (startNum, endNum, privince) }).toArray rules } // 将IP地址转换成长整形 def ipToLong(ip: String)={ val fragments: Array[String] = ip.split("[.]") var ipNum = 0L for(i <- 0 until fragments.length){ ipNum = fragments(i).toLong | ipNum << 8L } ipNum } // 利用二分法的形式返回IP地址对应的IP段 def binarySearch(lines: Array[(Long, Long, String)], ip: Long ): Int={ var low = 0 var high = lines.length - 1 while (low <= high){ val middle = (low + high) / 2 if((ip >= lines(middle)._1) && (ip <=lines(middle)._2)){ return middle } if(ip < lines(middle)._1){ high = middle - 1 }else{ low = middle + 1 } } -1 } }
利用Spark程序解析IP:
package cn.edu360.sparkThree import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object IpLocationOne { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("IpManage").setMaster("local[4]") val sc = new SparkContext(conf) // 获取IP映射库,同时将其解析 val rules: Array[(Long, Long, String)] = MyUtils.readRules("C:\\Users\\Administrator\\Desktop\\java\\spark4\\课件与代码\\ip\\ip.txt") // 将IP映射规则广播到每一个Worker的executer val broudcastRef: Broadcast[Array[(Long, Long, String)]] = sc.broadcast(rules) // 获取访问日志 val lines: RDD[String] = sc.textFile("hdfs://hd1:9000/ip/log/") // 定义一个解析访问日志的函数 val func =(line: String) =>{ val fields: Array[String] = line.split("[|]") val ip: String = fields(1) val ipNum: Long = MyUtils.ipToLong(ip) val rulesInExecutor: Array[(Long, Long, String)] = broudcastRef.value var province = "未知" val index: Int = MyUtils.binarySearch(rulesInExecutor, ipNum) if(index != -1){ province = rulesInExecutor(index)._3 } (province, 1) } // 解析数据 val provinceOne: RDD[(String, Int)] = lines.map(func) // 聚合数据 val reduced: RDD[(String, Int)] = provinceOne.reduceByKey(_+_) val result: Array[(String, Int)] = reduced.collect() print(result.toBuffer) } }
三,累加器
3.1 什么是累加器
累加器是通过交替的操作可以增加的变量,并且可以运行在并行的情况下。可以用来实现一个计数器(和 MapReduce中的一样)或者求和。Spark天然支持数字类型的累加器,开发人员可以添加新类型的支持。
3.2 累加器的作用
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
3.3 图解累加器
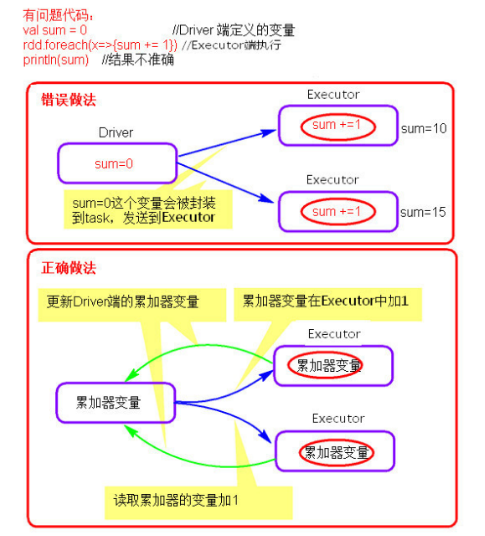
3.4 定义累加器
val a = sc.accumulator(0)
3.5 还原累加器
val b = a.value
3.6 定义注意事项
1、累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的
