
Hive 学习(三) Hive的DDL操作
正文
一,库操作
1.1 语句结构
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] //关于数据块的描述 [LOCATION hdfs_path] //指定数据库在HDFS上的存储位置 [WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性 默认地址:/user/hive/warehouse/db_name.db/table_name/partition_name/…
1.2 创建数据库
create database db_order; 库建好后,在hdfs中会生成一个库目录: hdfs://hdp20-01:9000/user/hive/warehouse/db_order.db
二,表操作
2.1 语法结构
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
2.2 基本建表语句
下面是常见的建表实例:
use db_order; create table t_order(id string,create_time string,amount float,uid string); 表建好后,会在所属的库目录中生成一个表目录 /user/hive/warehouse/db_order.db/t_order 只是,这样建表的话,hive会认为表数据文件中的字段分隔符为 ^A 正确的建表语句为: create table t_order(id string,create_time string,amount float,uid string) row format delimited fields terminated by ','; 这样就指定了,我们的表数据文件中的字段分隔符为 ","
2.3 删除表
drop table t_order; 删除表的效果是: hive会从元数据库中清除关于这个表的信息; hive还会从hdfs中删除这个表的表目录;
2.4 内部表和外部表
内部表(MANAGED_TABLE):表目录按照hive的规范来部署,位于hive的仓库目录/user/hive/warehouse中:如下实例:
create table t_order(id string,create_time string,amount float,uid string) row format delimited fields terminated by ',';
外部表(EXTERNAL_TABLE):表目录由建表用户自己指定,如下实例,比内部表多个 external,和location关键字
create external table t_access(ip string,url string,access_time string) row format delimited fields terminated by ',' location '/access/log'; # 注意这里的路径是hdfs的文件路径
外部表和内部表的特性差别:
1、内部表的目录在hive的仓库目录中 VS 外部表的目录由用户指定
2、drop一个内部表时:hive会清除相关元数据,并删除表数据目录
3、drop一个外部表时:hive只会清除相关元数据;
一个hive的数据仓库,最底层的表,一定是来自于外部系统,为了不影响外部系统的工作逻辑,在hive中可建external表来映射这些外部系统产生的数据目录;然后,后续的ETL操作,产生的各种表建议用内部表。
2.5 分区表
分区表的实质是:在表目录中为数据文件创建分区子目录,以便于在查询时,MR程序可以针对分区子目录中的数据进行处理,缩减读取数据的范围。比如,网站每天产生的浏览记录,浏览记录应该建一个表来存放,但是,有时候,我们可能只需要对某一天的浏览记录进行分析。这时,就可以将这个表建为分区表,每天的数据导入其中的一个分区;当然,每日的分区目录,应该有一个目录名(分区字段)。
创建分区表:
create table t_pv_log(id int,ip string,create_time string) partitioned by(day string) # 指明分区字段 row format delimited fields terminated by ',';
下面是一个实例:

数据导入到分区表:
load data local inpath '/root/hiveData/t_pv_log1.txt' intable t_pv_log partition (day='20190101') load data local inpath '/root/hiveData/t_pv_log2.txt' intable t_pv_log partition (day='20190102')
数据导入后,如下在HDFS中的文件目录:
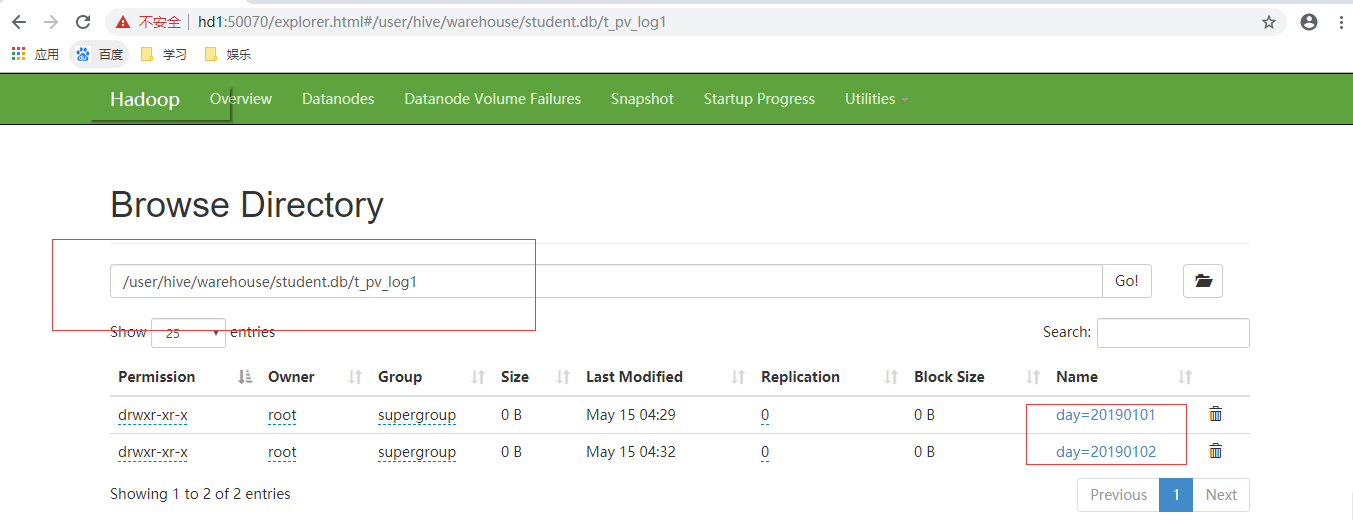
关于多分区表:有时可能会遇到多个分区,如下:
create table t_partition(id int,name string,age int) partitioned by(department string,sex string,howold int) row format delimited fields terminated by ',';
数据导入:
load data local inpath '/root/p1.dat' into table t_partition partition(department='xiangsheng',sex='male',howold=20);
2.6 CTAS建表语法
可以通过已存在表来建表:
1、create table t_user_2 like t_user; 新建的t_user_2表结构定义与源表t_user一致,但是没有数据 2、在建表的同时插入数据 create table t_access_user as select ip,url from t_access; t_access_user会根据select查询的字段来建表,同时将查询的结果插入新表中
三,数据导入和导出
3.1 将文件导入hive的表
方式1:导入数据的一种方式:
手动用hdfs命令,将文件放入表目录;
hadoop fs -put -f '/root/hiveData/user.txt' '/user/hive/warehouse/school/student/'
方式2:在hive的交互式shell中用hive命令来导入本地数据到表目录
hive>load data local inpath '/root/order.data.2' into table t_order;
方式3:用hive命令导入hdfs中的数据文件到表目录
hive>load data inpath '/access.log.2017-08-06.log' into table t_access partition(dt='20170806');
注意:导本地文件和导HDFS文件的区别:
本地文件导入表:复制
hdfs文件导入表:移动
3.2 将hive表中的数据导出到指定的路径文件
1、将hive表中的数据导入HDFS的文件
insert overwrite directory '/root/access-data' row format delimited fields terminated by ',' select * from t_access;
2、将hive表中的数据导入本地磁盘文件
insert overwrite local directory '/root/access-data' row format delimited fields terminated by ',' select * from t_access limit 100000;
3.3 hive的文件格式
HIVE支持很多种文件格式: SEQUENCE FILE | TEXT FILE | PARQUET FILE | RC FILE
create table t_pq(movie string,rate int) stored as textfile;
create table t_pq(movie string,rate int) stored as sequencefile;
create table t_pq(movie string,rate int) stored as parquetfile;
演示:
1、先建一个存储文本文件的表
create table t_access_text(ip string,url string,access_time string) row format delimited fields terminated by ',' stored as textfile;
导入文本数据到表中:
load data local inpath '/root/access-data/000000_0' into table t_access_text;
2、建一个存储sequence file文件的表:
create table t_access_seq(ip string,url string,access_time string) stored as sequencefile;
从文本表中查询数据插入sequencefile表中,生成数据文件就是sequencefile格式的了:
insert into t_access_seq select * from t_access_text;
3、建一个存储parquet file文件的表:
create table t_access_parq(ip string,url string,access_time string) stored as parquetfile;
四,修改表定义
仅修改Hive元数据,不会触动表中的数据,用户需要确定实际的数据布局符合元数据的定义。修改表ALTER TABLE table_name RENAME TO new_table_name示例:
alter table t_1 rename to t_x;
修改分区名: alter table t_partition partition(department='xiangsheng',sex='male',howold=20) rename to partition(department='1',sex='1',howold=20);
添加分区 alter table t_partition add partition (department='2',sex='0',howold=40);
删除分区 alter table t_partition drop partition (department='2',sex='2',howold=24); 修改表的文件格式定义: ALTER TABLE table_name [PARTITION partitionSpec] SET FILEFORMAT file_format 实例: alter table t_partition partition(department='2',sex='0',howold=40 ) set fileformat sequencefile; 修改列名定义: ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENTcol_comment] [FIRST|(AFTER column_name)]
实例: alter table t_user change price jiage float first; 增加/替换列: ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type[COMMENT col_comment], ...) 示例:
alter table t_user add columns (sex string,addr string); alter table t_user replace columns (id string,age int,price float);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号