软工实践寒假作业(2/2)
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》并提问、WordCount编程 |
| 其他参考文献 | 无 |
1.阅读《构建之法》并提问
1.1阅读并提问
1.在阅读《构建之法》3.1 个人能力的衡量与发展 中的
初级软件工程师如何成长呢?我认为有下面几种成长
......
3.对通用的软件设计思想和软件工程思想的理解。这一方面就比较虚,什么是好的软件设计思想?什么是好的软件工程思想?一个工程师开了博客,转发了很多别人的文章,这算有思想么?另一个工程师坚持做任何设计都要画UML图,这算有思想么?
我有一个问题:学习了软件设计思想和软件工程思想的知识之后,显然并不是任何时候都要死板的按照所学的知识进行开发设计,软件思想的运用边界在哪里?何时该使用,何时不该使用?
我在网络上搜索开发者何时会使用UML图,有些基本不用,有些认为在有正规流程规范的公司工作才会使用,有些甚至不知道UML,软件思想似乎在实际开发中的适用范围似乎和模糊。
思考:同样是UML,我在学习完UML之后恨不得每做一个项目都画类图,这样显然不太对。个人认为编程需要软件思想的指导,但是不能死板地用所学的理论框住自己。但是对这一部分的理解还是有限,这个问题似乎有点大,我依旧无法清晰地知道自己在什么时候应该按理论要求开发,何时不要。
2.在阅读《构建之法》3.2 软件工程师的职业发展 中的
21世纪以来,中国大陆每年招收六百万大学生,其中的百分之十是在学习各种IT相关的专业(计算机科学与技术、计算机工程、计算机软件、软件工程、管理信息系统等)。扣除读研究生(最终大部分也会走上工作岗位)、出国等分流,同时考虑到培训机构给就业市场贡献的大量劳动力,每年大致有四十万到六十万左右的“职业软件工程师”进入工作岗位。
我有一个问题:科班出身的软件工程师和非科班出身的有哪些区别?如何在就业市场就业压力如此大的情况下发挥科班出身的优势?
前段时间看到一档综艺节目,里面有个工作室的程序员都不是科班出身的,原来有在工地搬砖的,有当护士的,有当电话客服的,让我感受到了这个行业的竞争之激烈。知乎上的一个回答指出,两者之间的差距在于非科班缺少根基,他们会去学习那些更有“价值”的东西,而忽略了基础。
思考:我认为知乎的这个回答是很有道理的,要提升自己的竞争力,基础知识就是拉开差距的重要点,这是优势也是今后学习应该顾及的点。
3.在阅读《构建之法》10.1 典型用户和典型场景 中的
阿超:所谓“Person-a”,就是典型用户,吴石头/石头他爹就是我们系统的两个典型用户。我们的确需要了解我们软件系统的用户(不是公司的商业客户),那么,什么是典型用户?在产品开发的过程中,我们经常需要描述一组典型的用户。以前大家通常是以一些抽象的名词来表示用户,如“家用电脑初学者”、“经验丰富的系统管理员”,现在我们建议用一个“典型用户”来代表。典型用户不再是一个抽象的概念,而应该是一个活生生的人物。典型用户一般有哪些特性?一个典型用户往往描述了一组用户的典型技巧、能力、需要、想法、工作习惯和工作环境。
我有一个问题:如何确定软件系统的典型用户?
查阅网络资料,确定典型用户需要先收集用户数据,找到不同用户之间不同的行为,确定行为变量,最后用行为变量来找到典型用户。
思考:感觉网络上的这种方法先收集用户数据依旧讲的和模糊,收集哪些用户数据呢?这种方法感觉会有很多的不确定性。
4.在阅读《构建之法》6.1.2 敏捷流程概述 中的
冲刺期间,每天要开一个每日例会,团队成员大多站着开会,所以又称每日立会。大家依次报告:
我昨天做了啥
我今天要做啥
我碰到了哪些问题
每日立会强迫每个人向同伴报告进度,迫使大家把问题摆在明面上。
我有一个问题:如果团队成员在每日例会中迫于压力、碍于面子对自己的实际情况撒了谎,可能会打乱整个流程,该如何处理?
思考:老拖延症了。这种情况应该很考验Scrum Master ,需要Scrum Master协调好团队,搞好整个团队的氛围,营造一种大家都能实话实说,有问题大家一起解决的环境。其实这个问题可以扩展成:如果敏捷开发过程中出现意外,流程被打乱该如何处理?我觉得敏捷开发计划的周期比较短,应该不会造成很严重的后果。
5.在阅读《构建之法》16.1.2 迷思之二:大家都喜欢创新 中的
如果使用QWERTY键盘,那么只有10%的英语单词能在手指不离开键盘中列的情况下敲出来。但是如果使用Dvorak键盘布局,你可以在键盘中列打出60%的常用单词!这样会减轻手指和相关肌肉的负担,减少劳损,同时加快打字速度。......但是,长期以来,人们已经习惯了QWERTY键盘,所谓先入为主。
我有一个问题:当前中国人最离不开的软件微信,是否正在成为中国的“QWERTY键盘”?这样的软件存在是否会打击行业创新的积极性呢?
思考:我觉得微信不是中国的“QWERTY键盘”,至少现在不是,毕竟微信有痛点,也不是不思进取。微信确实给聊天软件的创新带来了巨大的阻碍,垄断行业让创新很难被注意,但是有意义的创意被行业注意只是时间问题,不思进取,被行业淘汰也是时间问题。
1.2附加题
RSA算法在软件开发中是常用的一种加密算法,它的命名是由三个提出者Ron Rivest、Adi Shamir、Leonard Adleman的姓氏首字母组成的。
Rivest在阅读一篇新论文后,对文章中前所未有的思路兴奋不已,将其中的思想忘我地对Adleman讲解,Adleman却并没有太感冒。于是Rivest找到隔壁的Shamir拉来做同盟,开始他们的探索之旅。尽管 Adleman 不情愿参与其中,他们还是会把结果拿给 Adleman,Adleman 的角色就是逐个击破这些方案,找出各种漏洞,给那两个头脑发热的人泼点冷水,免得他们走弯路。最后论文发表时,按照惯例,Rivest 应该按姓氏字母序将三人的名字署在论文上,也就是 Adleman、Rivest、Shamir,但 Adleman 总觉得自己贡献微乎其微,不过是泼泼冷水,不至于还要署个名,便要求 Rivest 拿掉自己的名字。在 Rivest 的坚持下,他最终要求至少把Adleman的名字放到最后。也正因为如此,RSA 叫做 RSA没有被叫做 ARS。虽然 Adleman 一开始认为这注定是他诸多论文中最不起眼的一篇,RSA 走红后他还是调侃说,越来越觉得 ARS 更顺口了。http://localhost-8080.com/2013/12/history-of-rsa/
Adleman的谦让很有风度,非常潇洒。我们应该看到这种行为对团队成员的启发,做好自己的事,不邀功,不抢别人的功劳。此外,我认为Adleman的角色在这三个人中,并不是可有可无,对成员进行鞭策纠正是很重要的工作。
2.WordCount编程
2.1Github项目地址
项目地址:TarsSE/PersonalProject-Java
2.2PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 180 | 240 |
| • Estimate | • 估计这个任务需要多少时间 | 180 | 240 |
| Development | 开发 | 1380 | 1800 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 240 |
| • Design Spec | • 生成设计文档 | 60 | 120 |
| • Design Review | • 设计复审 | 60 | 90 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| • Design | • 具体设计 | 120 | 90 |
| • Coding | • 具体编码 | 600 | 780 |
| • Code Review | • 代码复审 | 120 | 120 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 240 | 300 |
| • Test Repor | • 测试报告 | 60 | 60 |
| • Size Measurement | • 计算工作量 | 60 | 60 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 120 | 180 |
| 合计 | 1800 | 2340 |
2.3解题思路描述
思考过程:
1.第一次看整个程序的需求,脑子乱乱的,要求不多但是组织的有点乱,一下子看不过来,就决定先将程序分解成多个类,各自处理一些功能,最后再整合起来
2.按照对文件处理粒度先分为三个类分别处理字符,单词,行,因为从一整行内容中将单词分离感觉比较复杂,将这些类处理的基本单位定为字符,单词按照一个一个字符组成,行按照一个一个字符组成
3.处理字符的类主要用于判断ASCII码
4.处理单词的类要实现单词构建,单词校验,单词总数统计,各单词频数统计,以及按照频率和字典序排序单词的功能
5.处理行的类要实现行构建,有效行判断的功能
6.因为将程序分为多个功能,为了保证每个部分都可靠,减少后期返工的麻烦,单元测试部分打算每完成一个功能就测试一个功能,最后再测试整合后的程序
7.各个分离的功能都实现后写main函数和构造接口都是很自然的,会涉及文件的处理
8.最后对程序进行性能测试和优化,优化后再完整的进行一次单元测试
找资料过程:
1.《构建之法》
2.要求中提供的资料
3.百度/Google
2.4代码规范制定链接
代码规范地址:Tars的Java代码规范
2.5设计与实现过程
1.在一开始就把程序分出了多个类,分别处理字符、单词和行,三个要求的接口都封装到WordCountCore类下,此外使用一个类保存一些全局常量,方便修改一些需要经常用到的量,以及WordCount类包含main函数,共6个类
2.处理字符的类AsciiCharCounter主要用于判断字符类型
public boolean isAsciiChar(int inputChar) {
boolean result = false;
if (inputChar < 128) {
result = true;
}
return result;
}
函数通过字符编码判断是否为ASCII字符
-
统计文件字符数
将读入字符使用isAsciiChar判断,若为ASCII字符则字符数加一。
3.处理单词的类WordProcessor我认为主要的难点在于如何将单词从文件中通过一个一个读取字符,将可能符合要求的单词提取出来
StringBuilder possibleWord;
public boolean buildPossibleWord(char scanChar,boolean isEndOfFile) {
isPossibleWordAvailable = false;
if (!isEndOfFile) {
if (isLetterChar(scanChar) || isDigitChar(scanChar)) {
if (!isInPossibleWord) {
isInPossibleWord = true;
possibleWord = new StringBuilder(INIT_WORD_MAX_LENGTH);
}
possibleWord.append(scanChar);
} else {
if (isInPossibleWord) {
isInPossibleWord = false;
isPossibleWordAvailable = true;
}
}
}else {
isPossibleWordAvailable = isInPossibleWord;
}
return isPossibleWordAvailable;
}

函数在读取到字母数字以外的字符或读取到文件末尾时,之前读取到的字符就有可能组成全部是字母和数字的字符串,从而提取出文件中独立的字符数字串,进而进行进一步的合法单词判断。
-
统计单词数
将分离到的可能是单词的字符串使用isLegalWord函数进行判断
isLegalWord函数对合法单词的判断过程为
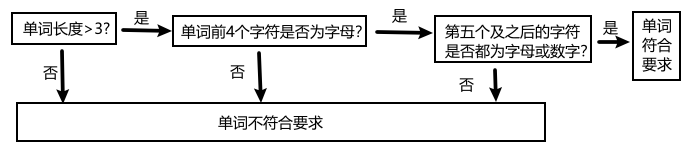
读取到合法单词就将合法单词数加一
-
统计各单词出现次数
private Map<String,Integer> wordSumMap = new HashMap<>(); public boolean individualWordSumUp(String legalWord) { boolean isCounted = false; legalWord = legalWord.toLowerCase(); if (wordSumMap.containsKey(legalWord)) { wordSumMap.replace(legalWord,wordSumMap.get(legalWord) + 1); isCounted = true; }else { wordSumMap.put(legalWord,1); } return isCounted; }使用individualWordSumUp函数对各个单词频数进行统计,统计过程为:
1.将单词都转换为小写,忽略大小写的影响,同时也符合输出时使用小写的要求
2.在存有单词和频数对的Map中查找要统计的单词是否之前出现过
3.若单词之前已统计,则将对应的频数加一,否则构建新的单词频数对添加到Map中,频数设为1
-
输出频率最高的10个单词及频数
要统计词频最高的十个单词,需要对单词-频数对进行排序,使用Java自带库将Map转换为List再使用List接口的sort方法对List排序
其中sort方法需要提供自定义的比较器Comparator,对照作业要求,比较器先比较单词频率,再比较字典序,字典序的比较使用String类的compareTo方法
private final Comparator<Map.Entry<String,Integer> > wordComparator = new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> stringIntegerEntry, Map.Entry<String, Integer> t1) {//s<t1返回正 int result = t1.getValue() - stringIntegerEntry.getValue(); if (result ==0 ) { result = stringIntegerEntry.getKey().compareTo(t1.getKey()); } return result; } }; public List<Map.Entry<String,Integer> > getSortedWordCountList() { List<Map.Entry<String,Integer> > wordList = new ArrayList<>(wordSumMap.entrySet()); wordList.sort(wordComparator); return wordList; }
4.处理行的类重点和处理单词的类相似,如何把行内容从文件中提取出来
提取行内容的方法与提取单词的方法相似,只是把分隔符换为'\n',对行内的内容不做要求,换汤不换药,这里不再赘述。
-
文件有效行数的判断
public boolean isEffectiveLine(){ return (lineContent.toString().trim().length() != 0); }因为Java8没有isBlank函数,因此使用了一种曲线救国的方法,删去空白符,再根据字符串长度判断是否为有效行。从后面的性能测试来看,这种方法还是会消耗比较多的时间,不够直接。
5.接口封装
程序功能分解的比较细,计算模块的接口就是上述类方法的组合
-
统计字符数
1.将字符从文件中读入
2.使用AsciiCharCounter对字符统计判断
-
统计单词数
1.将字符从文件中读入
2.使用WordProcesser的buildPossibleWord方法对单词进行构建,若构成了可能合法的单词,使用WordProcesser的allWordSumUp进行验证和统计。
-
统计最多的10个单词及其词频
1.将字符从文件中读入
2.使用WordProcesser的buildPossibleWord方法对单词进行构建,若构成了可能合法的单词,并且经过验证是合法单词,使用WordPricessor的individualWordSumUp对各单词分别进行统计
3.最后使用WordCount的getSortedWordCountList方法获取排序后的单词-频数对构成的List,再对List进行修剪,最多保存10对。
6.WordCount实现
WordCount进一步对各个功能进行了整合,使用上述各种类方法,主函数执行时能够只读一遍文件完成对字符的统计,单词的构建校验和统计,各单词的词频统计以及排序,行的构建以及有效行的判断和统计。
2.6性能改进
性能测试方面使用一个8.17MB 包含8500k+字符的文件进行测试
优化前,使用JProfiler进行测试发现整个程序中InputStreamReader的read和StringBuffer的append方法耗费了较多时间,于是上网找资料进行优化:
1.使用InputStreamReader构造BufferedReader,用BufferedReader的read方法替换InputStreamReader的read方法,BufferedReader带有缓冲区可以将一定大小的文件内容读入内存,不必频繁地进行系统调用,读取硬盘,减少IO时间
2.经过网络搜索,发现对字符串的拼接有三种方式:String的concat,StringBuffer的append,StringBuilder的append,其中StringBuilder的append效率最高,StringBuilder的append次之,String的concat效率最低,看别人对这三种方法的测试,StringBuilder的append和StringBuilder的append差距并不大,将StringBuilder的append换为StringBuilder的append之后,性能是有所提高的。
3.在代码复审时发现了一个遗留问题,在实现各单词频数统计时使用的Map是TreeMap,TreeMap是基于红黑树实现的,查找和插入的时间复杂度为O(log n),而使用HashMap时间复杂度为O(1),在频繁插入的情况下,HashMap会快得多,统计各单词词频使用的Map功能基本上都是基于查找和插入实现的,因此将TreeMap换为HashMap,进一步提高效率。
性能优化后的调用数及执行时间:
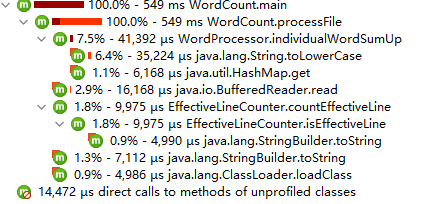
在性能优化方面大概用了3个小时,包括学***rofiler的使用,以及各种优化方法的学习
2.7单元测试
2.7.1单元测试覆盖率
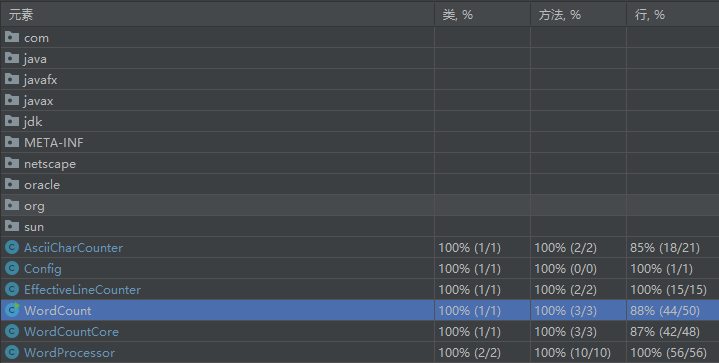
2.7.2测试函数
单元测试大量使用到文件,将测试数据保存在文件中,这样的好处在于:1)一个测试数据文件可供多个测试函数使用,提高利用率;2)不必在测试类中保存测试数据,在重复使用到测试数据时,不用大量复制数据,让代码更干净
例如以下对核心模块的部分测试代码,一个文件可供多个测试函数使用,在其他测试类中也可使用,测试类中没有保存测试数据,整体比较整洁
class WordCountCoreTest {
WordCountCore wordCountCore = new WordCountCore();
File testFile1 = new File("testText\\test1.txt");
@Test
void countChar() {
int characterNum = wordCountCore.countChar(testFile1);
int actual = 237;
assertEquals(characterNum,actual);
}
@Test
void countWord1() {
int wordNum = wordCountCore.countWord(testFile1);
int actual = 25;
assertEquals(wordNum,actual);
}
}
测试数据的构造,先按照比较正常的数据测试保证基本功能的正确实现,再到比较诡异的测试数据,测试在极端情况下程序的执行,构造测试数据,需要足够了解自己写的代码,照顾到方方面面。这一点证明开发人员要负责自己所写代码的单元测试是合理科学的
2.7.3如何优化覆盖率
利用工具,比如使用IDEA测试,已覆盖的代码在左侧行数条上会被绿色覆盖,未测试到的为红色,根据非测试到的代码构造相应的测试数据就可以提高覆盖率。当然,单元测试覆盖率不能说明软件质量,依旧需要构建合适的测试数据进行进一步测试。
2.8异常处理说明
程序对文件不存在进行了异常处理,这种异常出现在用户传入的文件路径不存在时。
单元测试样例:
String notExistFilePath = "testText\\test1";//不存在的文件路径
@Test
void main4() {
WordCount.main(new String[]{notExistFilePath,"output.txt"});
}
此外还有UnsupportedEncodingException和IOException。UnsupportedEncodingException在传入的编码字符串错误时抛出,在程序中只有源代码被修改,代码里的编码字符串错误时才会出现,一般很少出现。IOException在读写异常时出现。
2.9心路历程及收获
2.9.1心路历程
- 一开始看到编程作业的要求感觉会是一个很复杂的系统,再看截止日期,心里就想,好日子到头了。很庆幸一开始就决定把任务分解成好多个小的部分,其实助教在作业要求里面也是在拼命暗示分解,最后实现的时候目标就比较明确,而且做完之后感觉也没那么复杂。
- 刚开始要分解是没错,但是我在实际的分解中依旧纠结,该怎么分,这样分对吗,依旧不是很有头绪。
- 在这次作业中实践了单元测试,感觉测试能给人成就感。做完一个部分,测试一下,这只有问题,改一改,再测一遍,通过,唔,我真的很不错。
2.9.2收获
- 更加熟练Git和GitHub的使用。以前使用GitHub进行团队开发是真的小白,每次提交都会有很多冲突,大家都是用GitHub Desktop手动处理冲突,现在进一步深入使用学会了.gitignore的使用,每次commit也越来越熟练了。
- 学会使用用工具性能测试进行性能测试。在这次作业中,我初步学习了JProfiler的使用,能够根据测试结果有针对的对效率低的代码进行优化,摒弃了以前想到哪里可以优化就优化到哪里的盲目行为。
- 单元测试是个好东西。原来测试是有章法的,以前对程序的测试也是盲目的,一般都是整个项目完成之后才会开始测试,这个时候测试通常都很头疼:项目已经有了一定规模,很难照顾到方方面面;找到bug却很难定位,改要改一大堆。现在把单元测试分散到开发过程中,问题好解决了,而且有工具辅助,让测试可视化,成就感满满。通过这次作业,还亲自体会了测试覆盖率不等于代码正确率的血一般的教训。
- 重拾Java。这次选Java进行开发,对Java一些基础的运用都有所涉及,自己也通过网络搜索等方式对一些生疏了的知识进行了复习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号