python脚本处理下载的b站学习视频
作为常年在b站学习的我,一直以来看到有兴趣的视频,从来都是点赞收藏下载三连,但是苦于我那小钢炮iphone se屏幕大小有限,看起视频实在费劲,决定一定要找个下载电脑上下载b站视频的方法,以前用过硕鼠,可惜速度不行,批量解析也会出些问题,就没用了,后来也用过一些其他小工具,效果都不咋样,今天真是发现神器了,还支持迅雷下载,速度6M多美妙,真是美滋滋😄
下面重磅教程来袭:
一、找到视频的播放地址,如“七周成为数据分析师”,此视频地址为:https://www.bilibili.com/video/av46196018
二、修改原地址为:https://www.kanbilibili.com/video/av46196018,即在“bilibili”前加“kan”,搜索该地址
三、在新的网页如下位置点击获取地址
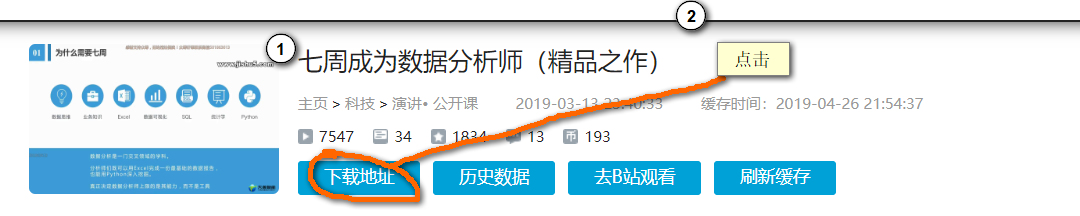
四、选择视频清晰度,然后加载出所有视频列表
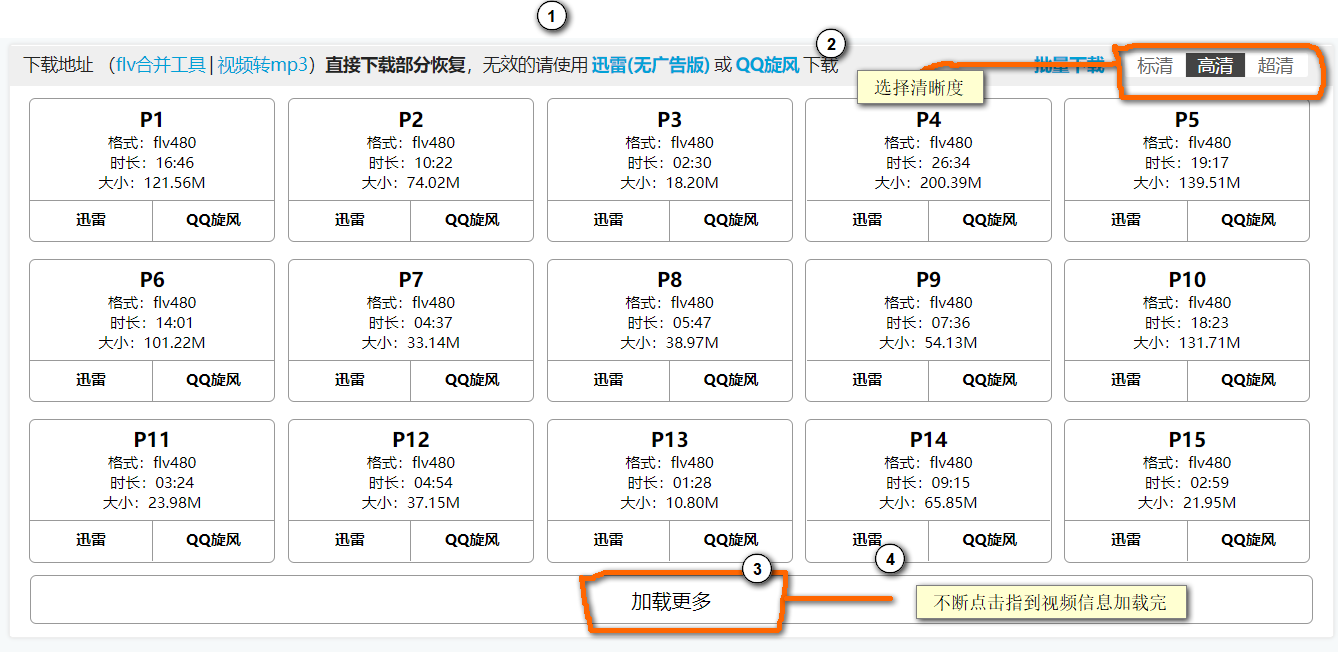
五、在选项栏中选择批量下载,拿到下载地址

六、使用迅雷下载
据说迅雷极速版更好用?
链接:https://pan.baidu.com/s/1TxMi0z-HMBTiglqycAvAbQ
提取码:aihf
downloading......
downloading......
downloading......
待下载完成,发现视频标题都变成数字了,而不是原来含有视频信息的标题!
分析可知,尽管都是数字,但它们都是有规律的,这些数字从小到大排列正好是原来的标题顺序,所有解决办法就是拿到原来的标题列表,将其和下载到的标题小到大顺序排列的列表进行一一组合,最终得到的每一个组合就包含下载的数字标题名字和含视频信息的标题名字,那么我们将其一一重命名即可,具体操作如下:
七、利用开发者工具,定位到视频列表,获取列表css元素
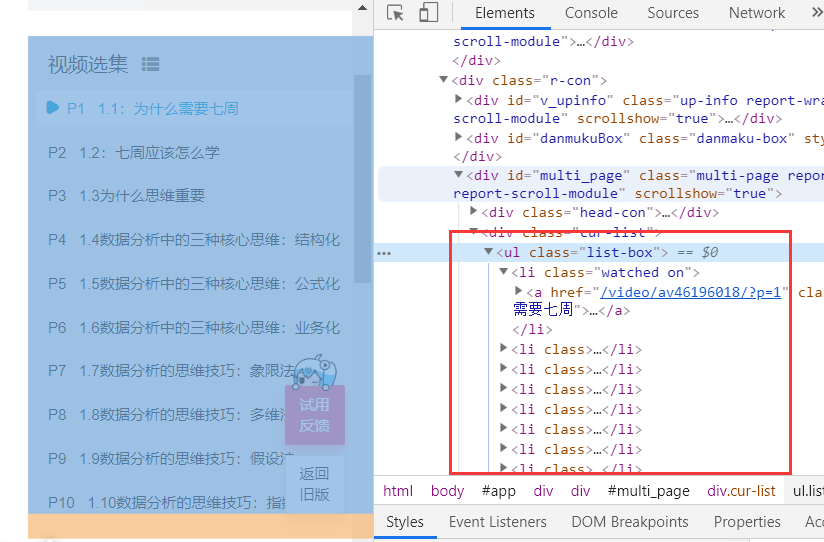
八、根据该列表的html+css信息,在console控制台获取含视频信息的标题名字列表

复制内容到python项目下7week.txt文档
九、可见含视频信息的标题名字列表仍有多余信息,如“P11.1:为什么需要七周” 变为 “1:为什么需要七周”更好,编写formatter.py脚本,对7week.txt每行内容替换字符串。
formatter.py:
# -*- coding:utf-8 -*- # Author: Tarantiner # @Time :2019/4/26 20:26 import re with open('7week.txt', 'r+', encoding='utf-8')as f: name_lis = [] for index, line in enumerate(f.readlines()): name = re.sub('P\d+\.\d+ ?', '%s' % (index+1), line) name_lis.append(name) f.seek(0) f.truncate() for name in name_lis: f.write(name)
十、进行重命名工作,获取下载目录所有文件,os.listdir()是列表形式,并且测试发现os.listdir()得到的列表中的文件名顺序正好是真正的视频顺序,就不用我对它进行重新排序了,接下来用zip函数打包下载的文件名列表和7week.txt文件中真正文件名列表,然后逐一重命名文件就好了。
renamer.py:
# -*- coding:utf-8 -*- # Author: Tarantiner # @Time :2019/4/26 20:54 import os file_path = 'F:/迅雷下载/b站7周成为数据分析师/' os.chdir(file_path) files = os.listdir() names = open('C:/Users/Chen/Desktop/rename_files/seven_week/7week.txt', 'r', encoding='utf-8').readlines() file_lis = list(zip(files, names)) # [('old_name', 'new_name'), ( , ) ...] for file in file_lis: os.rename(file[0], file[1].strip() + '.flv')
项目结构:
最终还是有个别文件格式不正确,手动重命名一下就好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号