
Tapdata 开源项目基础教程:功能特性及实操演示

自开源以来,Tapdata 吸引了越来越多开发者的关注。随着更多新鲜力量涌入社区,在和社区成员讨论共创的过程中,我们也意识到在基础文档之外,一个更“直观”、更具“互动性”的实践示范教程的重要性和必要性。为了辅助开发者更好地理解技术文档,真正实现快速上手、深度参与,即刻开启实时数据新体验,我们同步启动了 Tapdata 功能特性及操作演示系列教程。
以下,为本教程的第一弹内容——零基础快速上手实践,细致分享了从源码编译和启动服务到如何新建数据源,再到如何做数据源之间的数据同步的启动部署及常见功能演示,主要任务包括:
- MongoDB => MySQL 的实时同步任务,包括自动建表与实时数据同步
- MongoDB => MySQL + 自定义函数 + 自动模型推演 + 建表的任务,可以按照自定义函数的逻辑自动推断表模型
- MySQL=> PG + DDL 同步的任务,可以自动同步数据, 也可以自动同步表模型变更
一、项目简介
什么是 Tapdata?

Tapdata 开源路线图
Tapdata 开源项目的定位是一个实时数据服务平台,目前已上线的 1.0 版本核心覆盖实时数据同步、实时数据开发、Fluent ETL 等场景,具备全量和增量复制、异构数据库间的同步与转换,表级同步以及任务监控等能力。其工作机制主要包含以下四个环节的功能特性:
- 基于 CDC 的无侵入数据源实时采集
- 异构数据模型自动推断与转换
- 数据处理,流式计算,缓存存储一体架构
- 一键将模型发布为数据服务的闭环能力

Tapdata 开源工作机制
如上图所示,最左侧是包括数据库、数仓以及应用文件等在内的各种数据源。通过 Tapdata 主打的基于 CDC 的无侵入数据实时采集模块,能够将来自这些数据源的数据实时抓取过来;再经过一个异构数据模型的自动推断和转换,成为计算流中标准数据的一部分;继而经过一些数据处理、流式计算,配合项目自带的缓存存储,将数据按开发者的需求完成转换;最后通过数据发布能力,以 API 的形式呈现,或是直接按需传入数据目标,例如数据库、应用,或是 Web 服务等,从而达到更快获取所需数据的目的。
和传统解决方案的对比
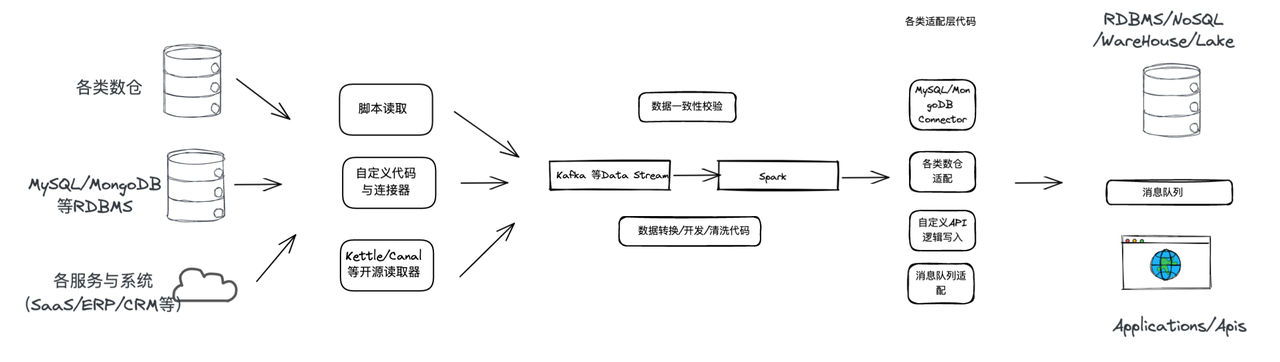
常见的传统解决方案
同样的场景下,传统解决方案比较常见的方式是通过脚本轮询读取、自定义代码连接器,或是 Kettle/Canal/OGG 一类的开源适配器等方式,对来自于各类数据源的数据进行读取;再通过 Kafka/MQ 这样的消息队列,或是 Spark/Flink 这样的计算引擎等方式进行数据的流转转换、开发清洗,进行数据的流转转换、开发清洗;最终通过自己写一些 API 接口逻辑将数据发送到目标终端。
这类方案的整个链路从原始读取到消息队列,再到写 Stream 逻辑,再到计算层,再到输入层,存在一个非常大且非常明显的缺陷,就是链路长、非实时、成本高、难维护。

Tapdata 解决方案
而 Tapdata 要做的,就是与之相对的一种快速、实时、简单、易用的方案——将中间的全部过程任务,交由我们来完成,这也是 Tapdata 的开源设计理念。
二、使用说明
如何从源码构建并启动完整的 Tapdata 服务?
从0开始构建和部署 Tapdata 开源版本,需要完成三个步骤:
- 环境准备: Linux + Docker(当前版本仅支持 Linux 和 Docker 环境,基于非 Docker 的和非 Linux 的环境正在适配中,很快会和大家见面)
- 下载源码: git clone git@github.com:tapdata/tapdata.git && cd tapdata
- 通过一个命令,一键编译所有组件并启动服务: bash build/quick-dev.sh
另附代码结构解析及启动说明:
- 代码库主要组成部分(目录)
- assets:用于存储我们的图片、logo 等静态资源
- build:主要用于存放我们用来打包、编译或测试的脚本,不是框架的主要组成部分
- connectors common:数据源的通用对象以及类的定义
- plugin-kit:供开发者使用,如果开发者想在框架上开发一个自己的数据源,就可以用到这里的一些 API 方法
- tapshell:目前 Tapdata 的开源项目没有暴露 UI 界面,整个系统的交互使用都是通过 tapshell 来运行的,是一个基于 Python 的交互式命令行工具
- bin:我们后续会在这里放一些类似于启动/停止的脚本
- connectors:目前 Tapdata 支持的数据源都在这里:
- 开源数据库 Apache Doris
- 测试用数据库 Dummy
- ES/Kafka/MySQL/PG/OceanBase/RabbitMQ/RocketMQ……
- dist:每次打包时的成品目录
- engine:引擎,做计算时的一个主要仓库,可以用来做数据的读取、转换,以及聚合计算
- manager:管理端,开发者的任务管理、日志上报、监控等信息都是通过这个组件来完成的。我们也是通过 manager 来完成任务的持久化(engine 本身仅运行任务,不做持久化)
- README:一个中文版,一个英文版
- 编译说明:先把 plugin-kit 和 connectors common 编译完(编译出我们基本依赖的对象),再完成 engine 引擎编译,继续完成 manager 编译后,整个服务就可以跑起来了。最后通过 build 里的 DockerFile 打包成一个 All-in-One 的镜像,我们最终运行的是这个镜像。在运行之后,我们还需要把 connectors 下面的所有数据源注册到系统中去。
- 数据源注册:如果想要注册一个新的数据源,可以通过 accesstoken 来完成
如何动态注册数据源?
以 MongoDB 为例,具体演示如何动态地注册一个数据源,让系统具备插件式数据集成的能力:
- 动态注册一个开发完成的数据源插件
- 列出系统当前支持的数据源:show connectors
- 注册 MongoDB 数据源插件
- 列出系统当前支持的数据源: show connectors
- 新建一个 MongoDB 数据源
DataSource("mongodb", $name).uri($uri).save() - 校验并保存数据源
- 新建所需的全部数据源, 校验并保存数据源
DataSource("mysql", $name).host($host).port($port).username($username).password($password).db($db).save()
DataSource("postgresql", $name).host($host).port($port).username($username).password($password).db($db).schema($schema).save()
- 检查数据源配置, 检查表加载情况
三、功能示例及任务操作演示
提前准备的库(已确认可连通):
- MongoDB: 4.2,包含一张表:car
- MySQL: 8.0.22,空库
- PG: 12.6,空库
构建并运行一个 MongoDB => MySQL 的简单同步任务
*任务说明:这个同步任务不包含任何复杂处理,要求是将 car 表从 MongoDB 同步至 MySQL。
- 新建表同步任务并运行
p = Pipeline('mongo=>mysql')
p.readFrom(mongodb.car).writeTo(mysql.car)
p.start()
- 查看任务运行状况:show jobs
- 监听实时状态:monitor job mongo=>mysql
- 查看运行日志:logs job mongo=>mysql
- 在源与目标查看数据情况
- 做一个变更,查看数据是否同步
任务完成情况:数据的增删改都可以实时同步过来,延迟一般在几百毫秒以内。
构建并运行一个 MongoDB => MySQL 的带 UDF 的同步任务
*任务说明:从 MongoDB 到 MySQL 的带 UDF(User Defined Function)的数据同步,仍然是数据同步,但做了一些字段变换。
-
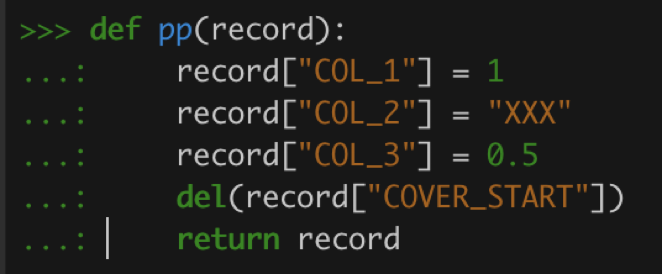
定义 UDF(User Defined Function):加一些字段,删除一个已存在的数据
![]()
-
新建表同步任务,增加 UDF 节点并运行
p = Pipeline('mongo=>mysql_with_udf')
p.readFrom(mongodb.car).processor(pp).writeTo(mysql.car_with_udf)
p.start()
*补充说明:与上一个任务的不同之处在于,这里在读写之间增加了一个处理器(processor),对 record 做了一些变换的同时,按照 UDF 定义增减了字段,变换了类型。
- 监听实时状态:monitor job mongo=>mysql
- 查看运行日志:logs job mongo=>mysql
- 查看建表情况
*任务完成情况:亮点在于,不仅完成了数据同步,还完成了表结构的自动创建。在同步过程中,能够自动建出处理完之后的表结构,无需像其他同步工具一样手动建表,使用更方便。
构建并运行一个 MySQ => PG 的支持 DDL 同步任务
*任务说明:从 MySQL 到 PG 的 DDL 同步,对象是第一个任务中用到的 car 表。
视频片段⑤
-
新建表同步任务,配置支持 DDL 并运行
p = Pipeline('mysql=>pg_with_ddl')
p.readFrom(mysql.car_ddl, ddl=True).writeTo(pg.car_ddl)
p.start()
*补充说明:DDL 任务是默认不开启的,如果想要同步 DDL,可以通过执行 ddl=True 打开。 -
监听实时状态:monitor job mongo=>mysql
-
查看运行日志:logs job mongo=>mysql
-
查看建表情况
-
源端进行多次 DDL,查看目标是否同步:
- 源字段类型调整
- 源字段重命名
- 新增 / 删除字段
*任务完成情况:实现实时同步,延迟一般也会在几百毫秒以内。
至此,我们的整个系统中就同时有如上三个任务在跑,我们可以随时:
- 通过 logs job + 任务名来查看任务运行状况;
- 通过 monitor job + 任务名来查看该任务的运行指标信息,包括 input/output/update 的数据量等;
- 通过show/use 来查看表信息、表结构
👉🏻GitHub 项目链接:https://www.github.com/tapdata/tapdata
如果您对我们的项目感兴趣,欢迎给 Tapdata 【Star+Fork+Watch】三连击

以上,就是本次教程的核心内容回顾。还有更多有关 Tapdata 开源项目的问题亟待解答?已经顺利度过“自学上手期”,想要观看更多基础之上的细节操作?欢迎扫码添加 Tapdata 小姐姐(微信号:Tapdata2022),加入 Tapdata 社区群进行进一步交流讨论。
我们期待与您共创一个优秀的开源项目以及一个开放成熟的开源社区,见证实时数据的更多可能,下一期教程内容,或许就源自您提出的问题!
🎁 更多进群彩蛋
在 Tapdata 社区群,开源项目核心成员将为大家线上答疑,帮助开发者们快速理清困惑。
与此同时,作为 Tapdata 社区活跃用户,你还可以:
- 获得 Tapdata 开源 Issue、需求的特殊优先级
- 第一时间收获社区最新资讯(包括但不限于开发计划、核心技术、业务场景等)
- 参与活动、领取开源体验官新手任务、获得商务双肩包、潮牌 T 恤等更多好礼
- 有机会受邀加入 Tapdata Committer Program,成为正式的 Tapdata Committer
- 有机会直接参与并影响 Tapdata 的未来走向

 浙公网安备 33010602011771号
浙公网安备 33010602011771号