

4.2 re模块及其方法
re模块使python语言拥有全部的正则表达式功能,本节主要介绍Python中re模块常用的3种函数使用方法。
4.2.1 search()函数
re模块的search()函数匹配并提取第一个符合规律的内容,返回一个正则表达式对象。search()函数的语法如下:
re.match(pattern,string,flags=0)
其中:
⑴pattern为匹配的正则表达式。
⑵string为要匹配的字符串。
⑶flags为标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等。
例如:
import re a = 'one1two2three3' infos = re.search('\d+',a) print(infos) #search方法返回的是正则表达式对象
程序运行结果如下图所示。
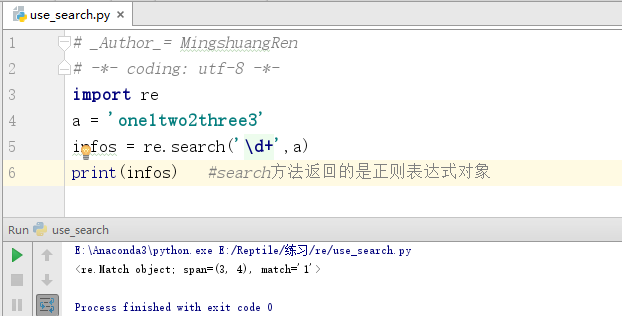
可以看出,search()函数返回的是正则表达式对象,通过正则表达式匹配到了“1”这个字符串,可以通过下面的代码返回匹配到的字符串:
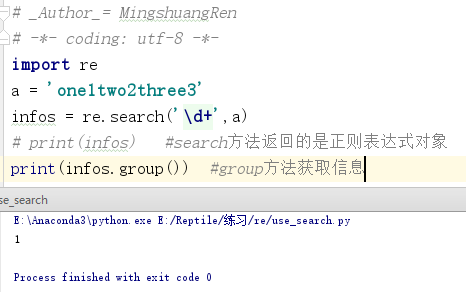
import re a = 'one1two2three3' infos = re.search('\d+',a) print(infos.group()) #group方法获取信息
程序运行结果如图所示。
4.2.2 sub()函数
re模块提供了sub()函数用于替换字符串中的匹配项,sub()函数的语法如下:
re.sub(pattern,repl,string,count=0,flags=0)
其中:
⑴pattern为匹配的正则表达式。
⑵repl为替换的字符串。
⑶string为要被查找替换的原始字符串。
⑷count为模式匹配后替换的最大次数,默认0表示替换所有的匹配。
⑸flags为标志位,用于控制正则表达式的匹配方式,如是否区分大小写,多行匹配等。
例如,一个电话号码123-4567-1234,通过sub()函数把中间的"-"去除掉,可以通过如下代码实现:
import re phone = '123-4567-1234' new_phone = re.sub('\D','',phone) print(new_phone) #sub()方法用于替换
程序运行结果如下图所示。

sub()函数的用途类似于字符串中的replace()函数,但sub()函数更加灵活,可以通过正则表达式来匹配需要替换的字符串,而replace却是不能做到的。在爬虫实战中,sub()函数的使用也是极少的,因为爬虫所需的是爬取数据,而不是替换数据。
4.2.3 findall()函数
findall()函数匹配所有符合规律的内容,并以列表的形式返回结果。例如,前面的‘one1two2three3’,通过search()函数只能匹配到第一个符合规律的结果,而通过findall()函数可以返回字符串所有的数字。
import re a = 'one1two2three3' infos = re.findall('\d+',a) print(infos)
程序运行结果如下图所示。
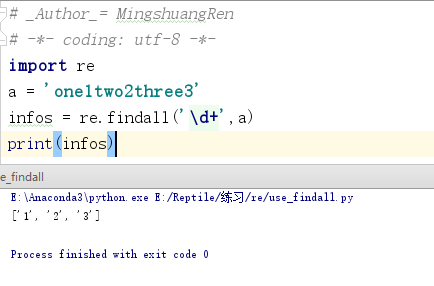
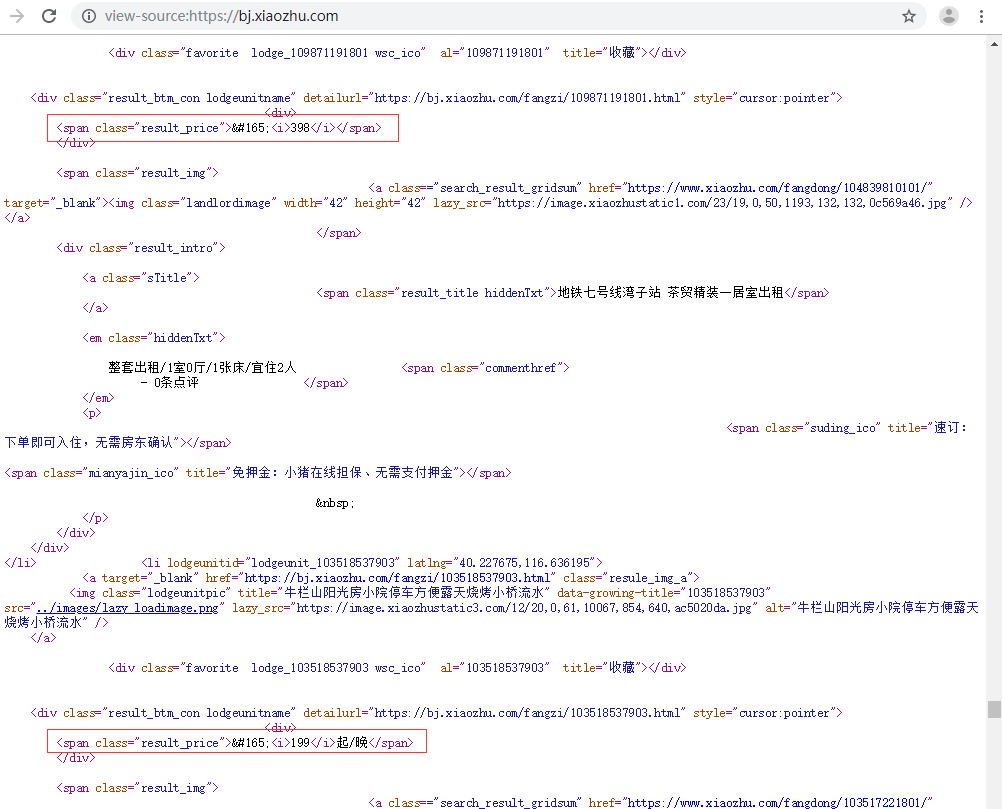
在爬虫实战中,findall()的使用频率最多,下面以第3章爬取北京地区短租房的价格为例(http://bj.xiaozhu.com/),看一下通过正则表达式如何提取所需要的信息,通过观察网页源码可以看出,短租房的价格都是在<span class="result_price">¥<i>398</i></span>这个标签中,如下图所示。
这时就可以通过构建正则表达式和findall()函数来获取房租价格:
import re import requests res = requests.get('http://bj.xiaozhu.com/') princes = re.findall('<span class="result_price">¥<i>(.*?)</i></span>',res.text) for price in princes: print(price)
程序运行结果如下图所示。

不难看出,通过正则表达式的方法爬取数据,比之前的方法代码更少也更简单,那是因为少了解析数据这一步,通过requests库请求返回的HTML文件就是字符串的类型,代码可以直接通过正则表达式来提取数据。
4.2.4 re模块修饰符
re模块中包含一些可选标志修饰符来控制匹配的模式,如表所示。
| 修饰符 | 描述 |
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w,\W,\b,\B |
| re.X | 该标志通过给予更灵活的格式,以便将正则表达式写得更易理解 |
在爬虫中,re.S是最常用的修饰符,它能够换行匹配。在这里举一个简单的例子,例子如提取<div>指数</div>中的文字,可以通过以下代码实现:
import re a = '<div>指数</div>' word = re.findall('<div>(.*?)</div>',a) print(word)
程序运行结果如下:
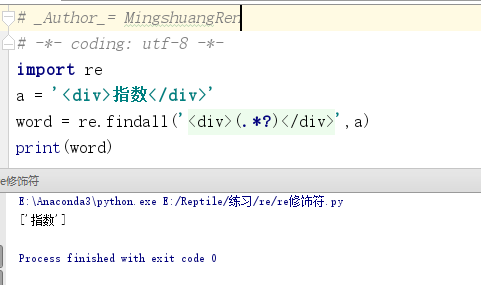
但如果字符串是下面这样的:
a = '''<div>指数 </div>'''
通过上面的代码则匹配不到div标签中的文字信息,如下图所示。
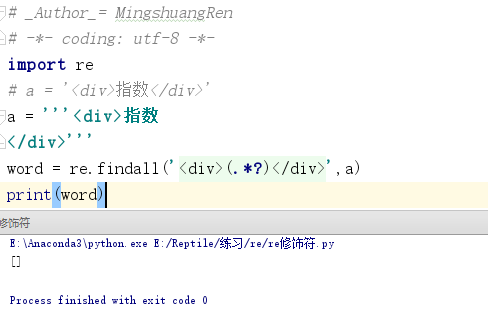
这是因为findall()函数是逐行匹配的,当第1行没有匹配到数据时,就会从第2行开始重新匹配,这样就没法匹配到div标签中的文字信息,这时便可通过re.S来进行跨行匹配。
import re a = '''<div>指数 </div>''' word = re.findall('<div>(.*?)</div>',a,re.S) #re.S用于跨行匹配 print(word)
程序运行结果如图所示。
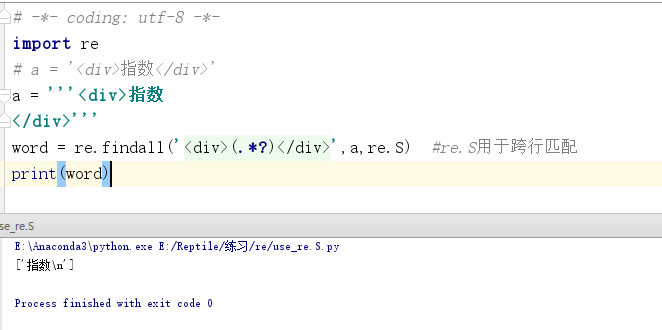
从结果中可以看出,跨行匹配的结果会有一个换行符,这种数据需要清洗才能存入数据库,可以通过第1章中的strip()方法去除换行符。
import re a = '''<div>指数 </div>''' word = re.findall('<div>(.*?)</div>',a,re.S) #re.S用于跨行匹配 print(word[0].strip()) #strip()方法去除换行符
程序运行结果如下:
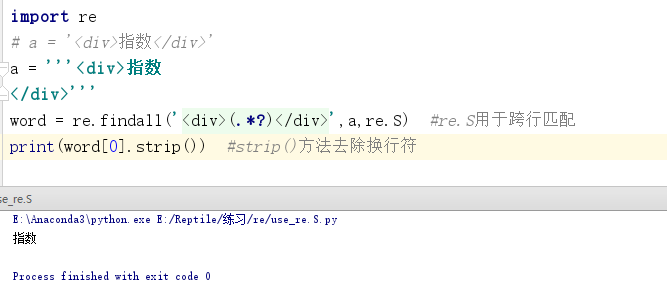

 浙公网安备 33010602011771号
浙公网安备 33010602011771号