
scrapy 爬虫踩过的坑(I)
问题1:正则表达式没问题,但是爬虫进不了item方法
分析:
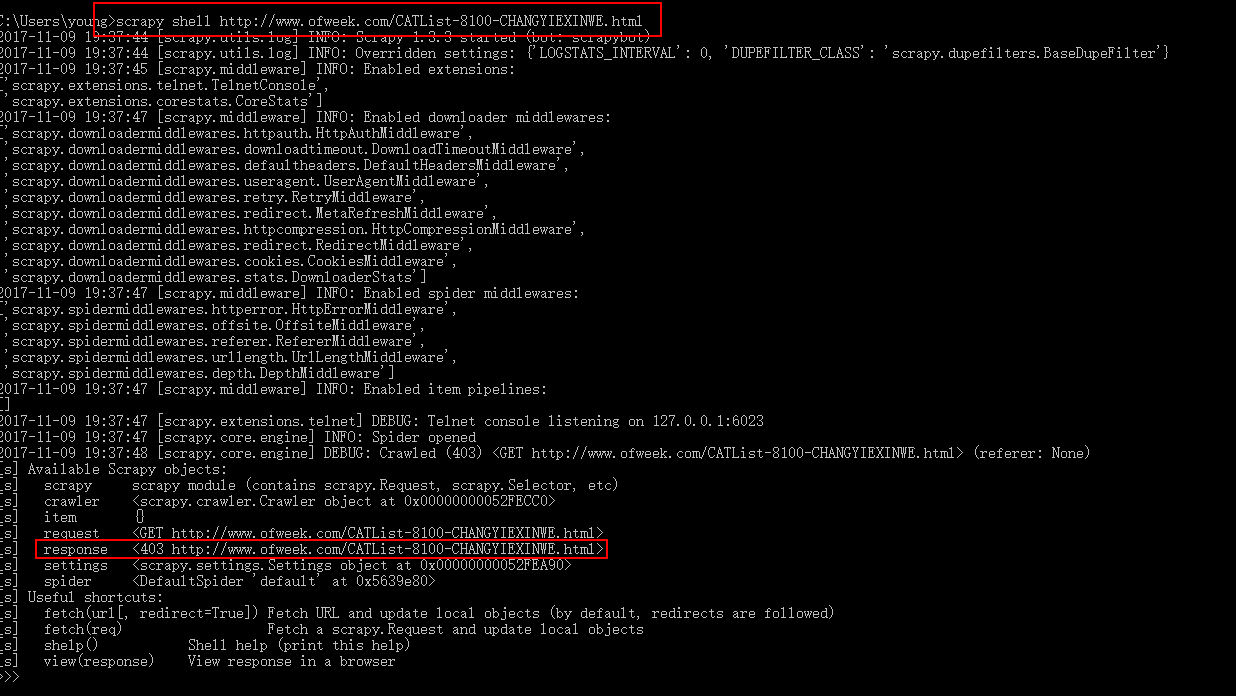
1. 可能是下载不到list 页面的内容。可以用 scrapy shell url 进行测试
2. 可能是allowed_domains 不允许

3. list 页面里的链接不符合正则表达式 或者说list 页面里根本就没有相关的链接
解决方案
针对第一种:有可能是所爬取的网站有反爬虫机制,比如禁掉你的ip(多数是通过ip的)
解决方案:可以更换动态更换 user_agent,或者使用ip池,更换ip网上有不少免费的IP代理,但是不是很稳定
2: 因为详情页的链接很可能并不是和list 页面在同一个domain 下,所以在不清楚domain 时,建议将allowed_domain 制空
3. 查看response 的text值,看看是否根本就不包含相关的url。有时你说看到的url 可能并不是list 页面中的链接,服务器上可能进行了处理
