阿里重磅开源Qwen2-VL:超越人类的视觉理解能力,从医学影像到手写识别,这款开源多模态大模型究竟有多强?(附本地化部署教程)
阿里重磅开源Qwen2-VL:超越人类的视觉理解能力,从医学影像到手写识别,这款开源多模态大模型究竟有多强?(附本地化部署教程)

模型介绍
最近呢,阿里巴巴开源了Qwen2-VL,在多模态大模型展现了在实际应用中的巨大潜力,尤其是在处理跨模态数据方面表现出众。以下是该模型的几大应用亮点:
-
智能客服新范式:Qwen2-VL可应用于视频客服场景,实时分析用户展示的产品图像或条形码,并给出相关商品信息,大幅提升人机交互体验。
-
赋能医疗、安防等行业:该模型能处理复杂的图像视频输入,支持医学影像分析、智能监控等任务,有望在多个领域实现技术变革。
-
面向全球的智能助理:Qwen2-VL支持多语言的视觉语言交互,可实现跨语言的图文互译、视频摘要等功能,在跨国企业服务中大有可为。
-
连接现实世界的强大工具:通过调用API、访问外部数据等能力,该模型可以获取航班、天气、物流等实时信息,为各行业提供强大的数字化工具。
-
提升内容生产力:Qwen2-VL可根据视觉输入自动生成文案、设计元素,助力内容创作者提高生产效率,在广告营销等领域潜力巨大。
Qwen2-VL代表了视觉语言大模型技术的最新发展方向,其在多模态理解、生成、交互等方面的突出表现,标志着人工智能走向成熟应用的新里程碑。随着算法迭代和产业探索的不断深入,Qwen2-VL有望成长为引领未来智慧社会的关键科技力量。
Qwen2-VL-72B在线预览链接
- Qwen2-VL-72B 在线预览:https://huggingface.co/spaces/Qwen/Qwen2-VL
- 模型官网介绍:https://qwenlm.github.io/zh/blog/qwen2-vl/
本地化部署
这里使用autodl 机器学习平台,官网地址:https://www.autodl.com/market/list
直接到算力市场,选择按量计费,地区随便选择一个,这里使用4090显卡。
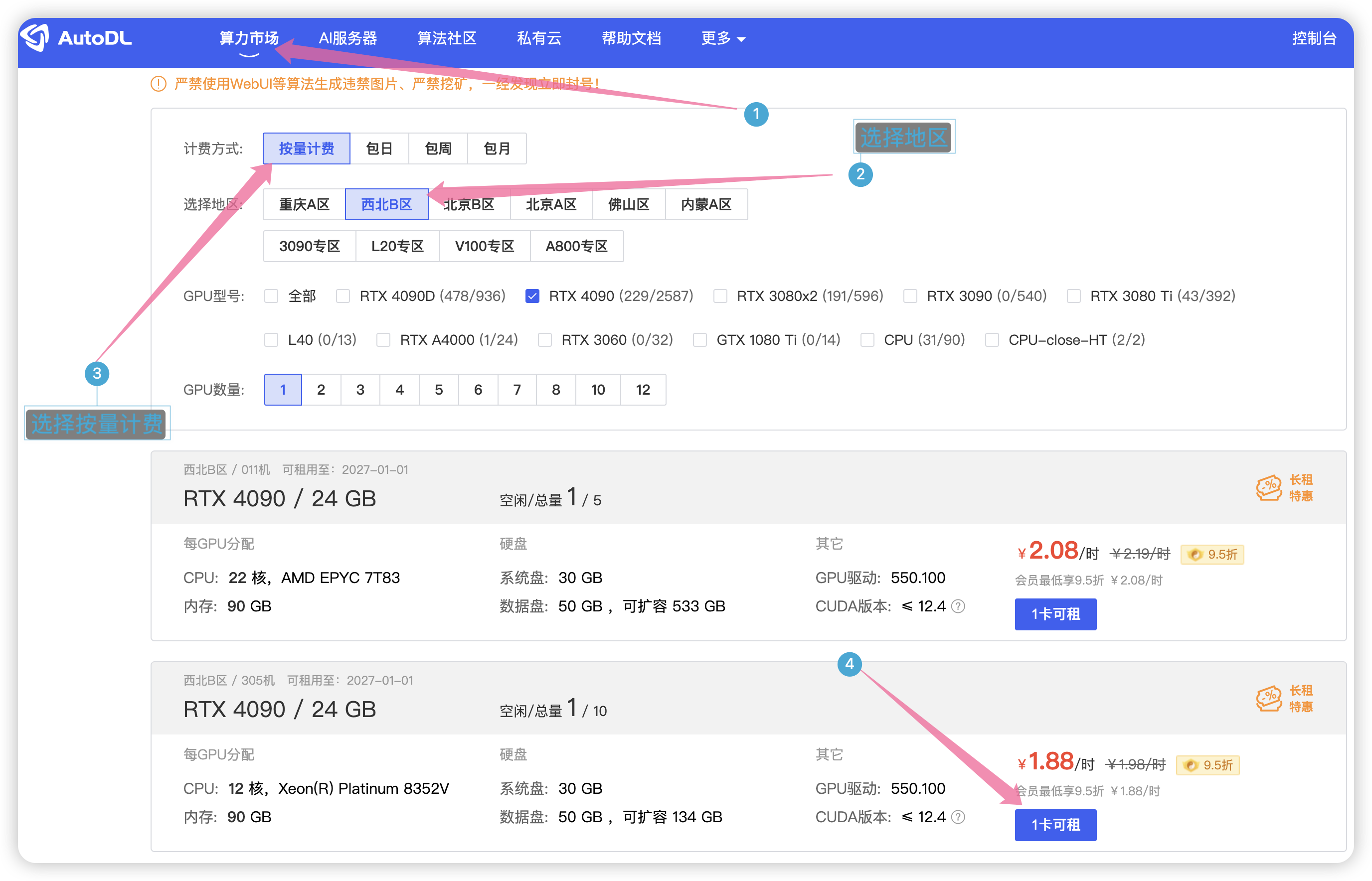
如图选择PyTorch 版本,最后点击创建。
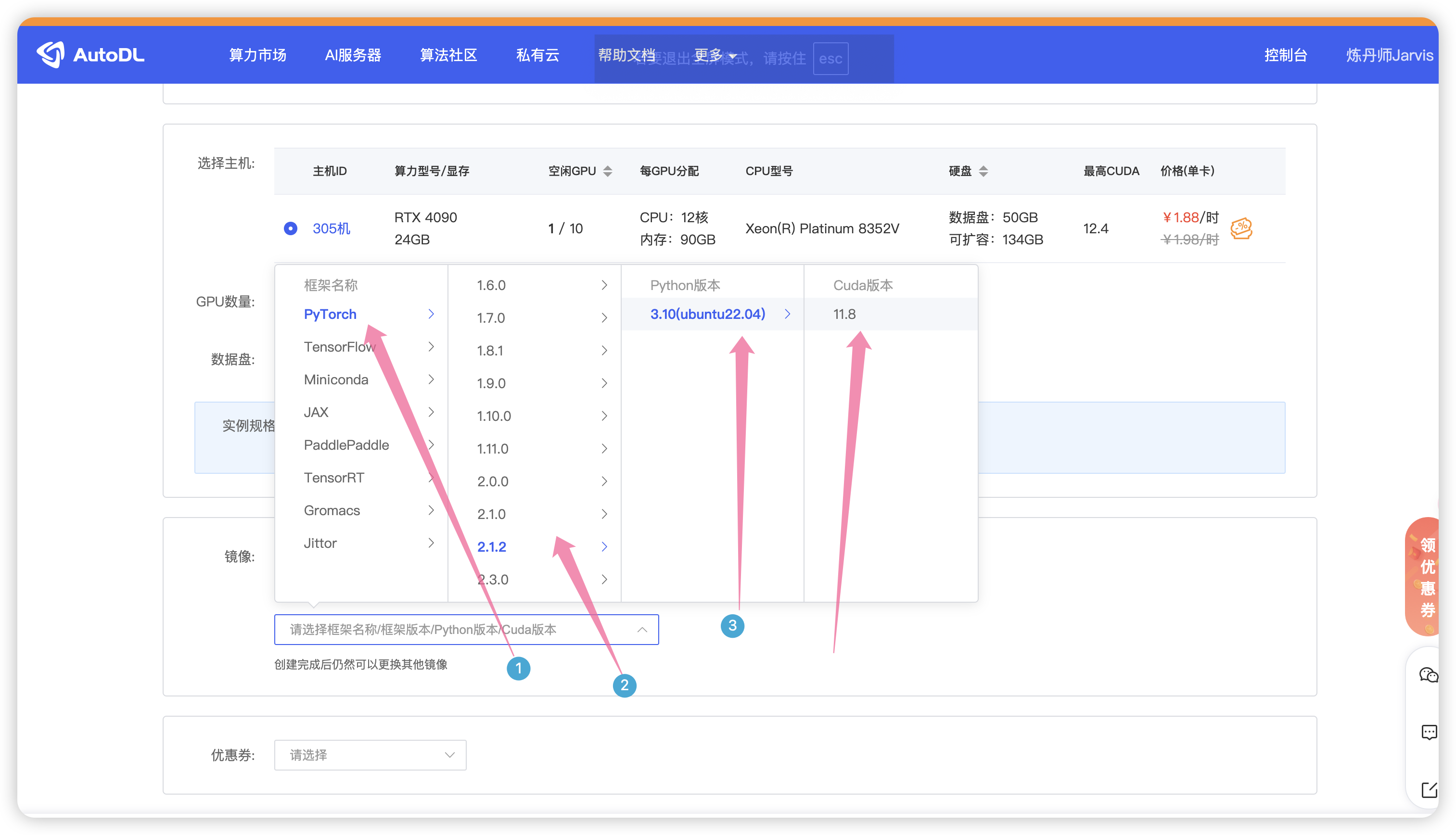
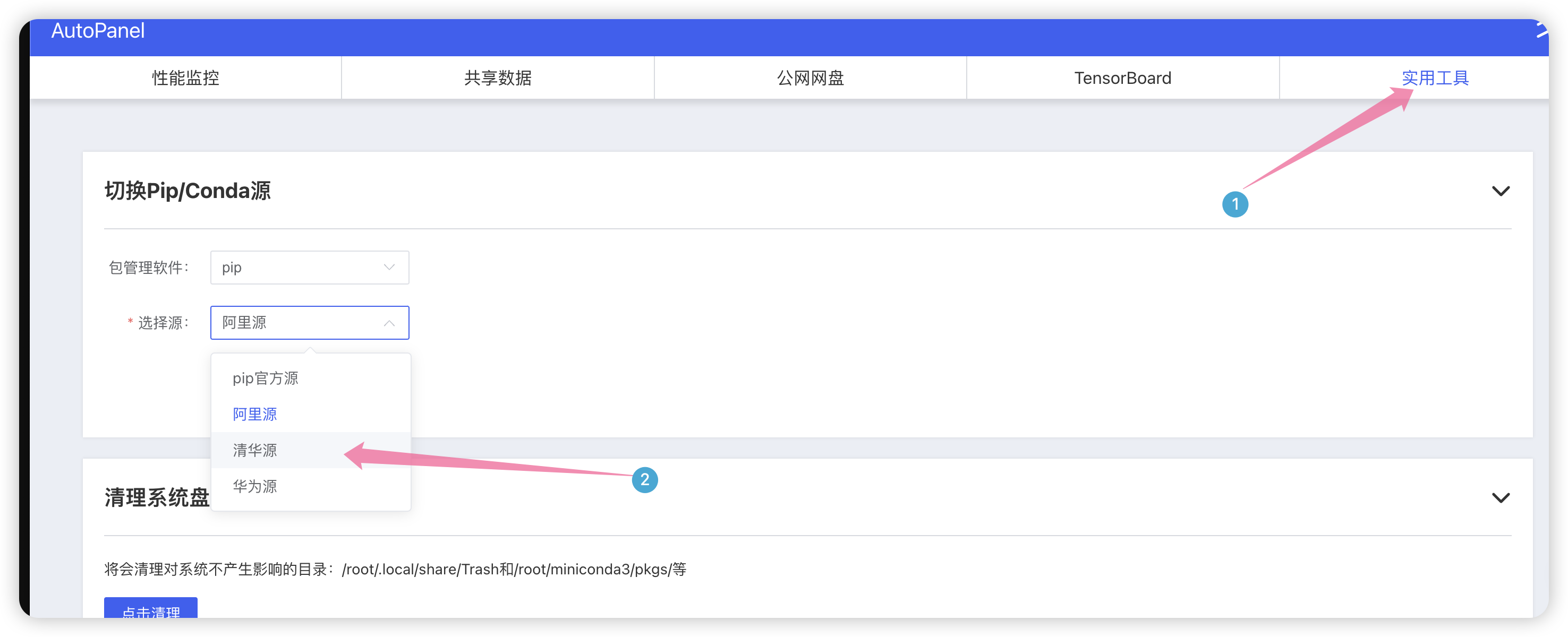
创建好以后就来到了控制台,点击AutoPanel 面板,设置默认为清华源。

点击选择清华源,因为清华源下载依赖包比较快。
接着回到控制台,点击进入JupyterLab。

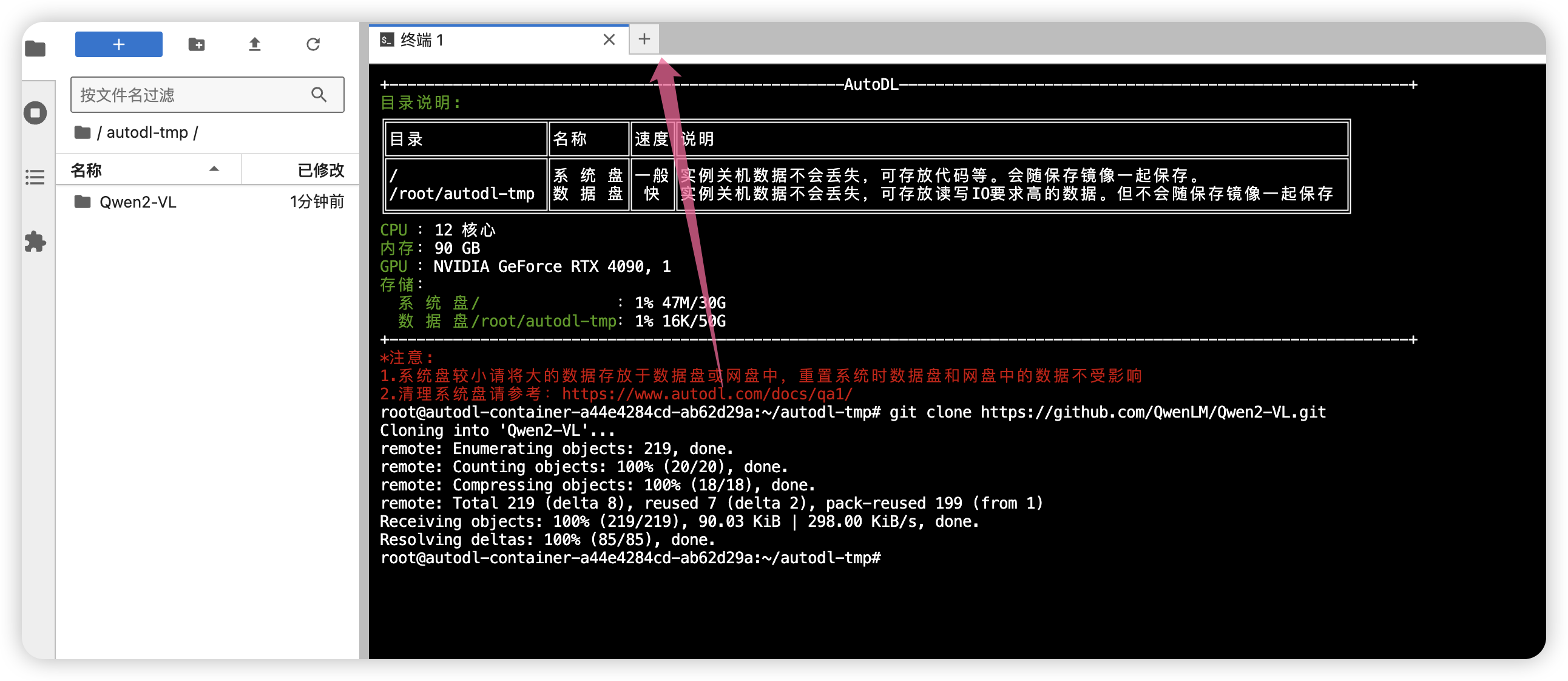
进入到autodl-tmp 目录下,然后打开终端。
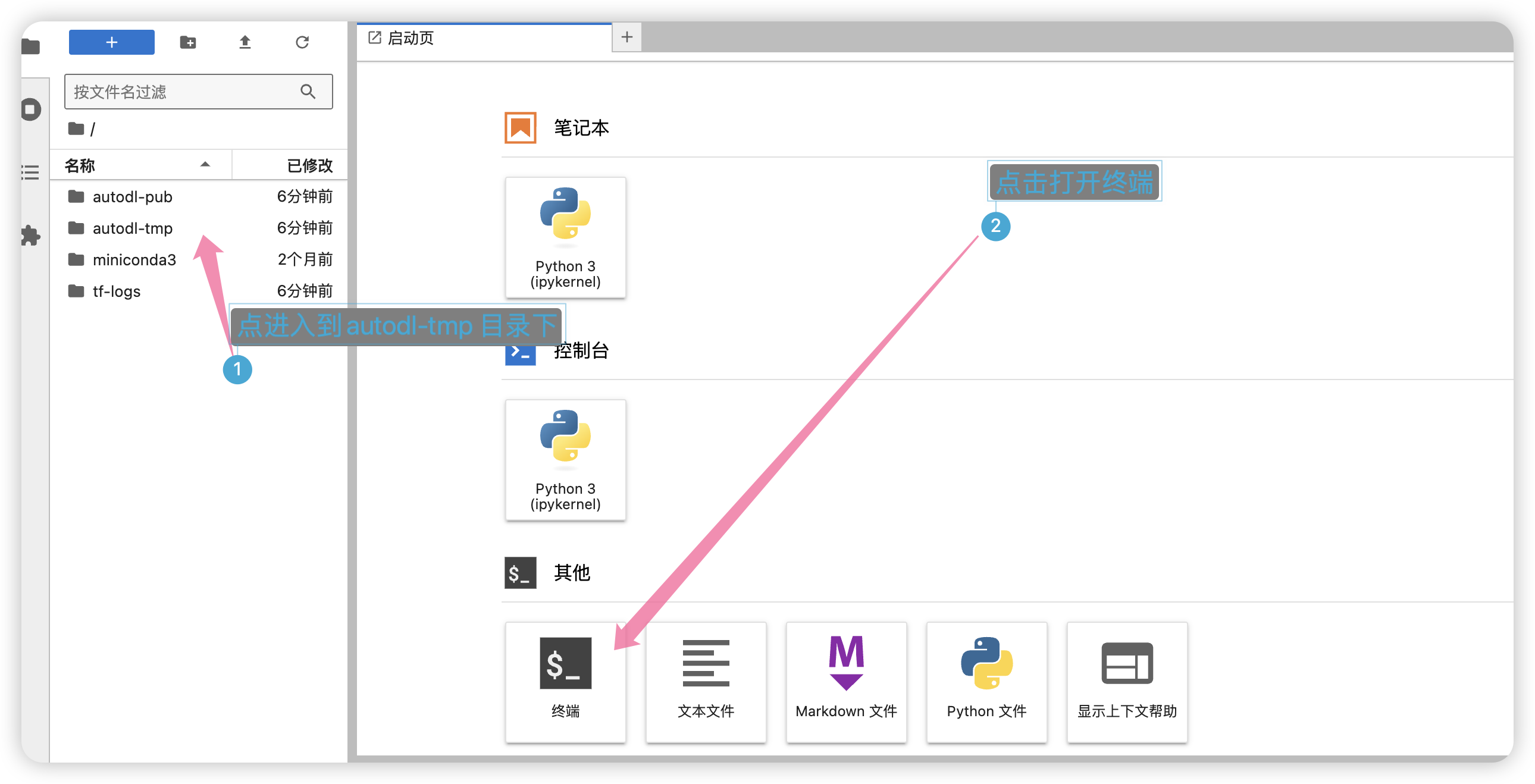
然后克隆项目,输入如下命令:
git clone https://github.com/QwenLM/Qwen2-VL.git
继续打开一个笔记本,下载模型。
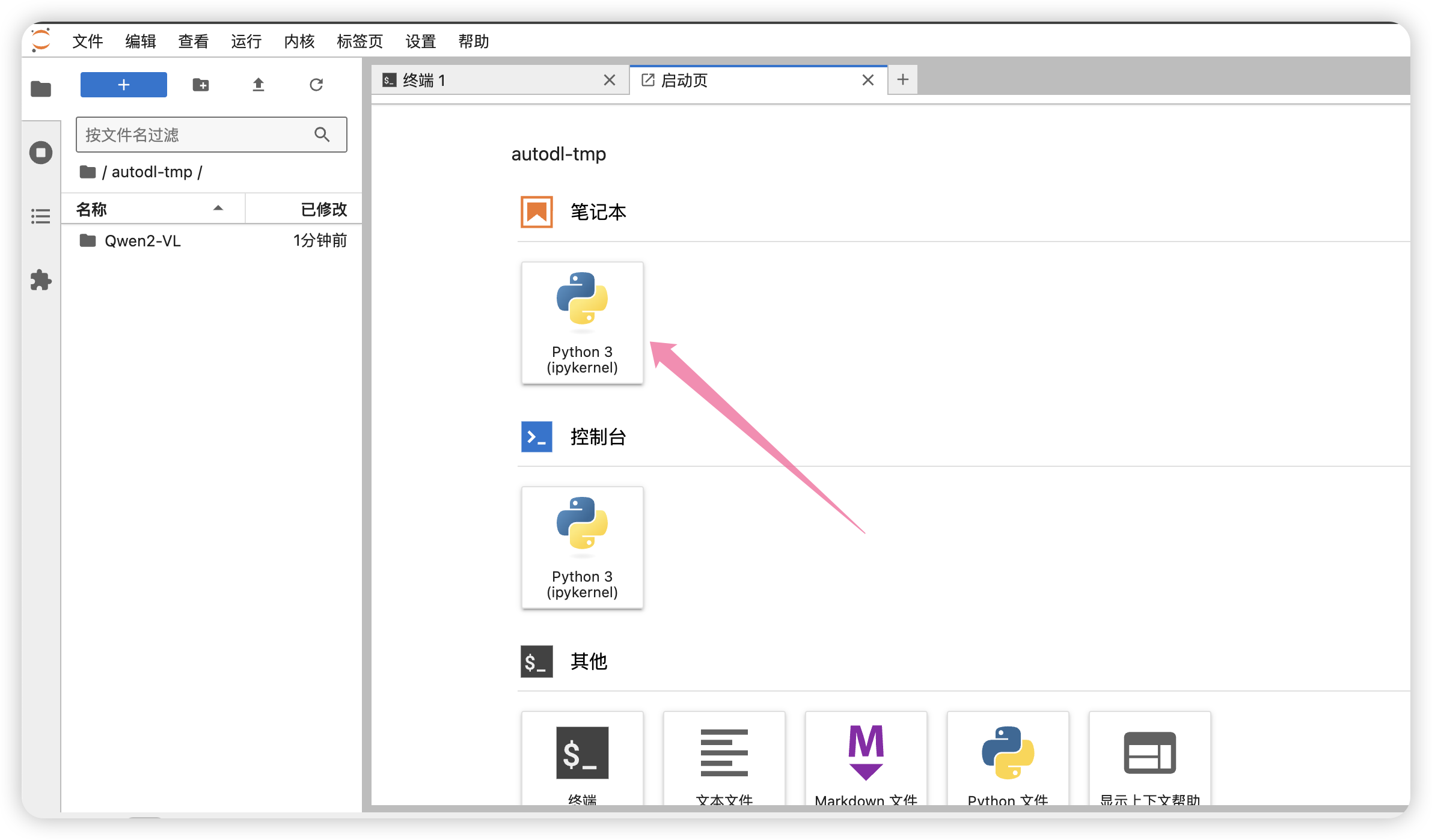
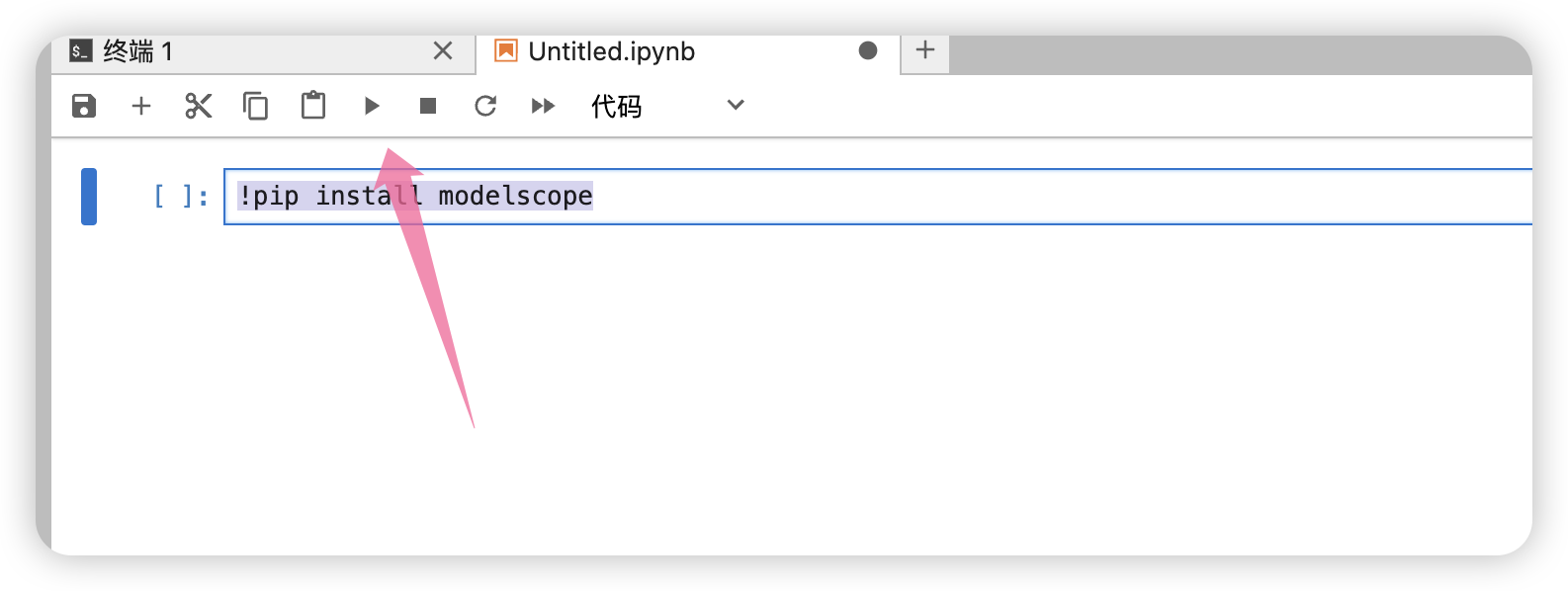
键入如下代码后运行:
!pip install modelscope
继续键入如下代码下载模型:
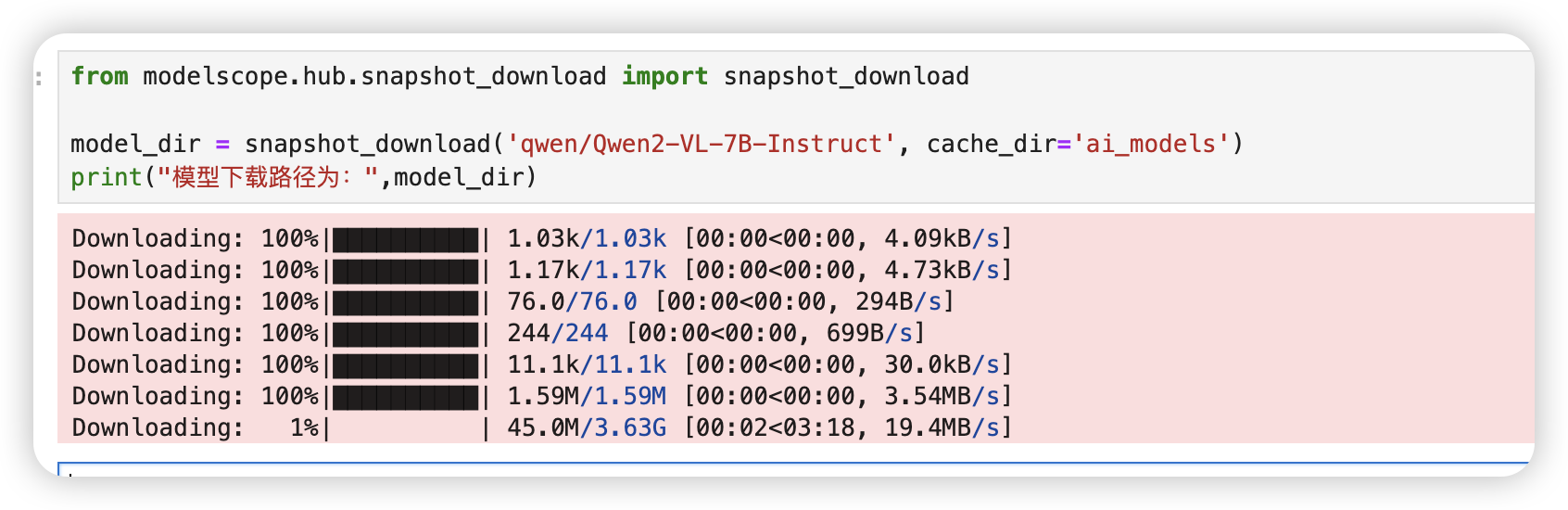
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-VL-7B-Instruct', cache_dir='ai_models')
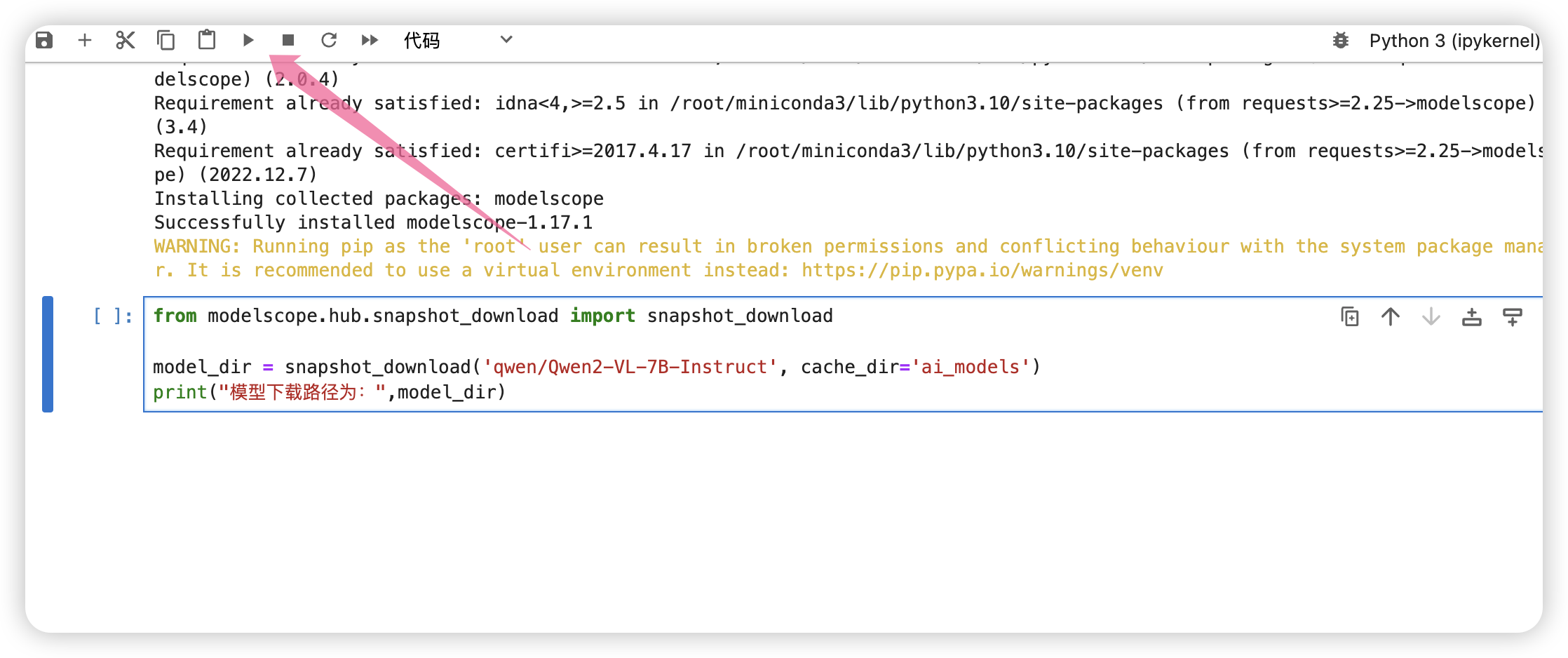
出现进度条说明模型开始下载了。
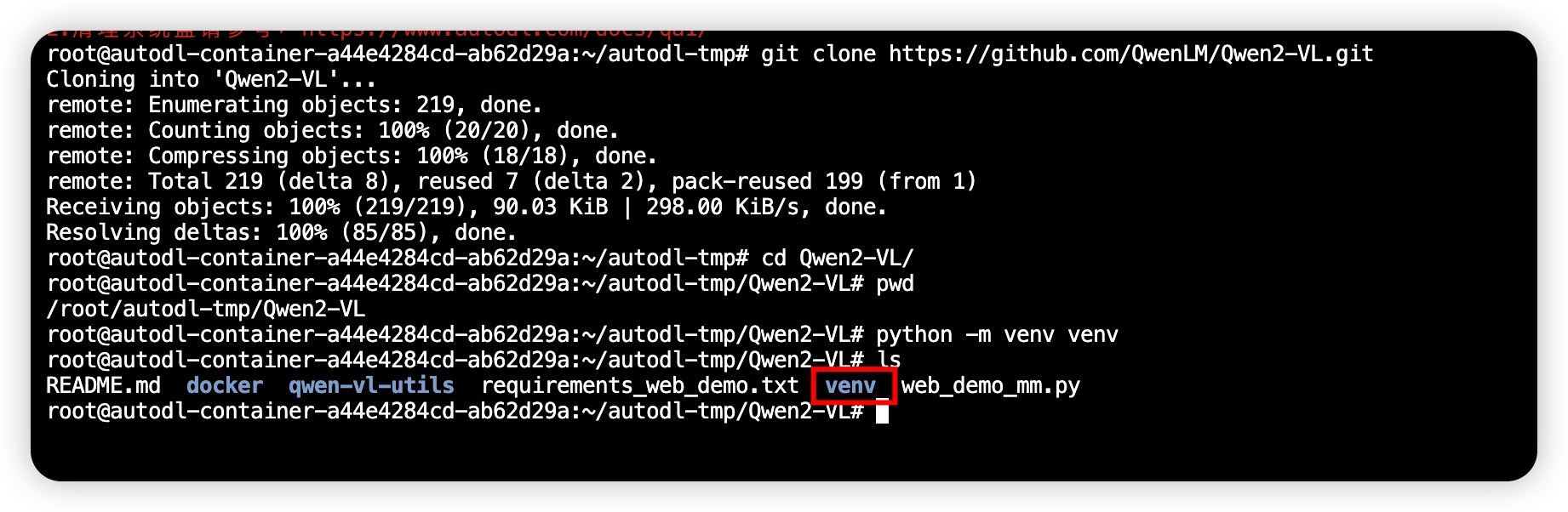
然后回到终端,进入Qwen2-VL 目录。
cd Qwen2-VL/
创建虚拟环境
# 创建一个名为venv 的虚拟环境。
python -m venv venv
接着激活虚拟环境。
source ./venv/bin/activate
安装依赖
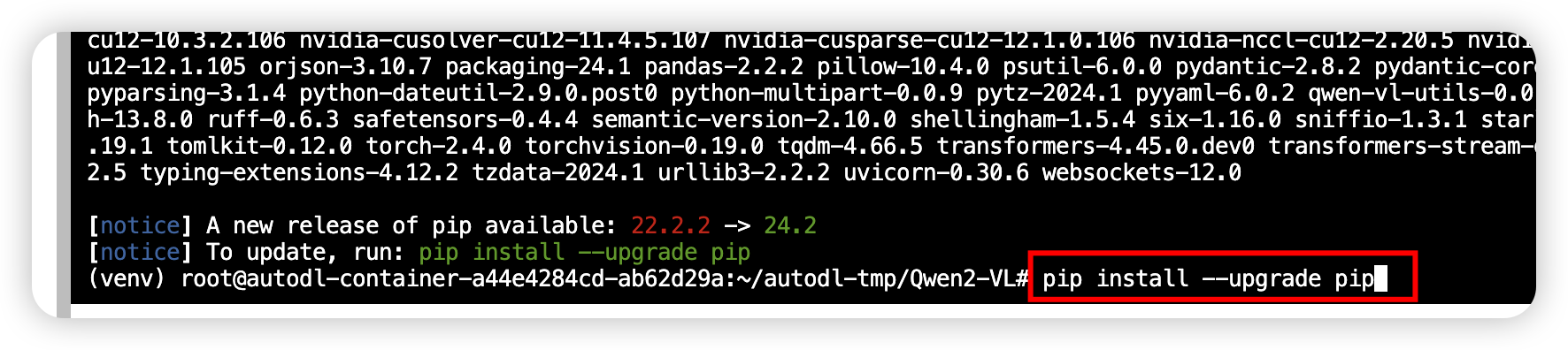
pip install -r requirements_web_demo.txt
安装好依赖以后,我们更新pip
pip install --upgrade pip
VsCode 远程连接
回到控制台,复制ssh配置。

打开Vsocode,远程连接。
粘贴登录信息
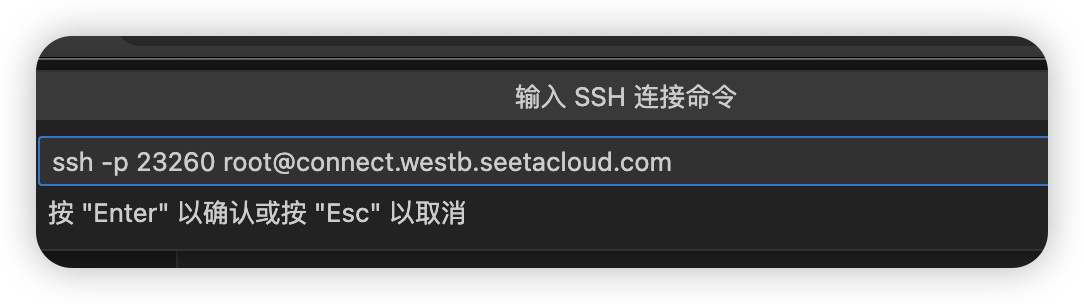
选择第一个默认配置。

选择第一个链接。
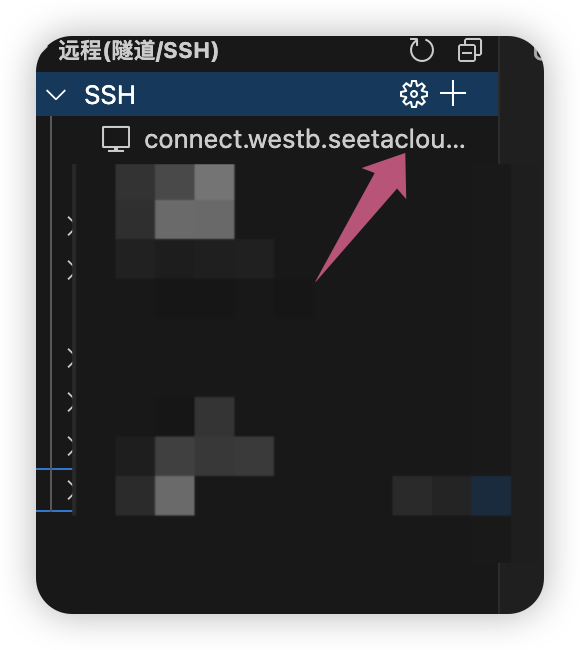
复制密码

粘贴密码

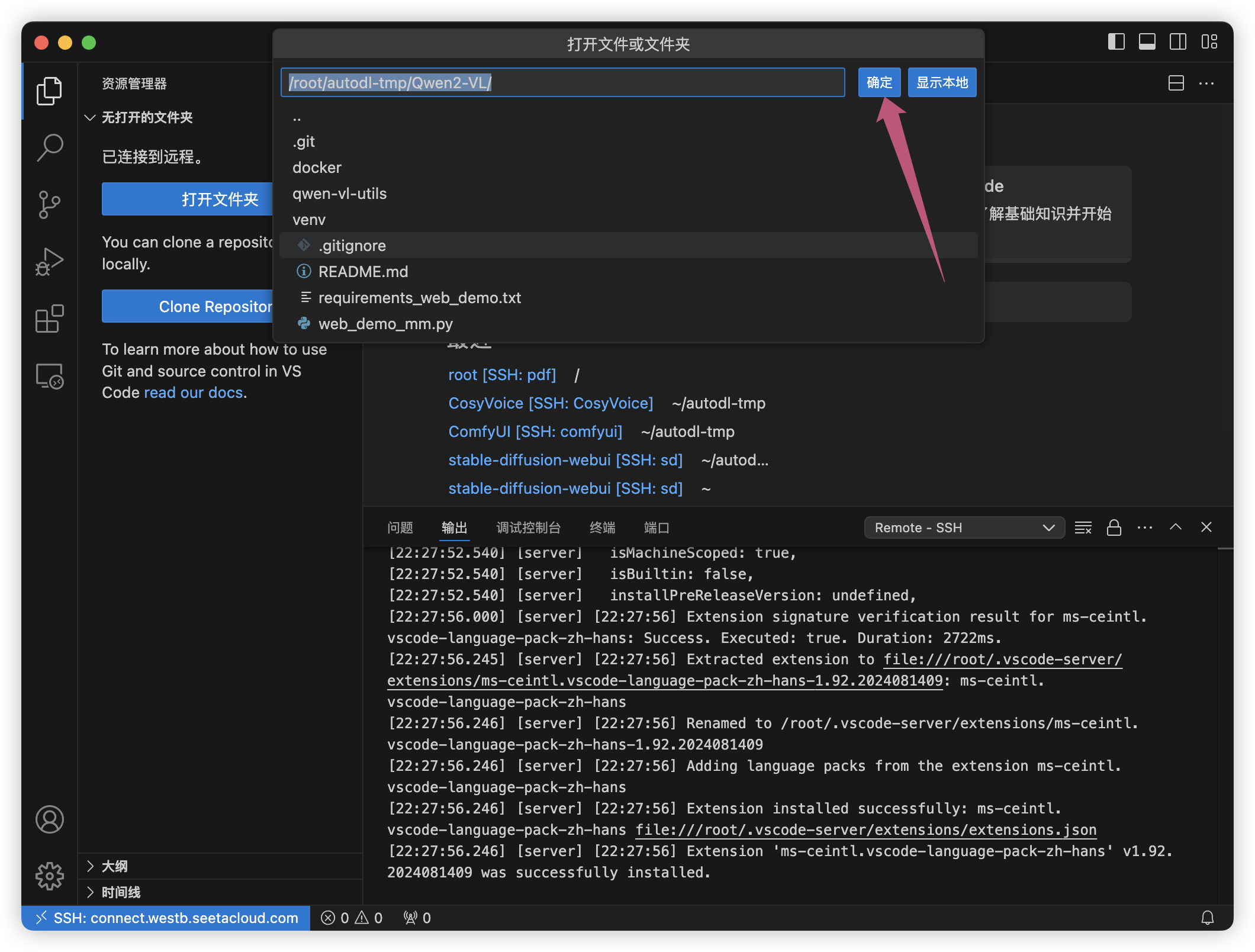
接着打开文件夹,选择/root/autodl-tmp/Qwen2-VL/
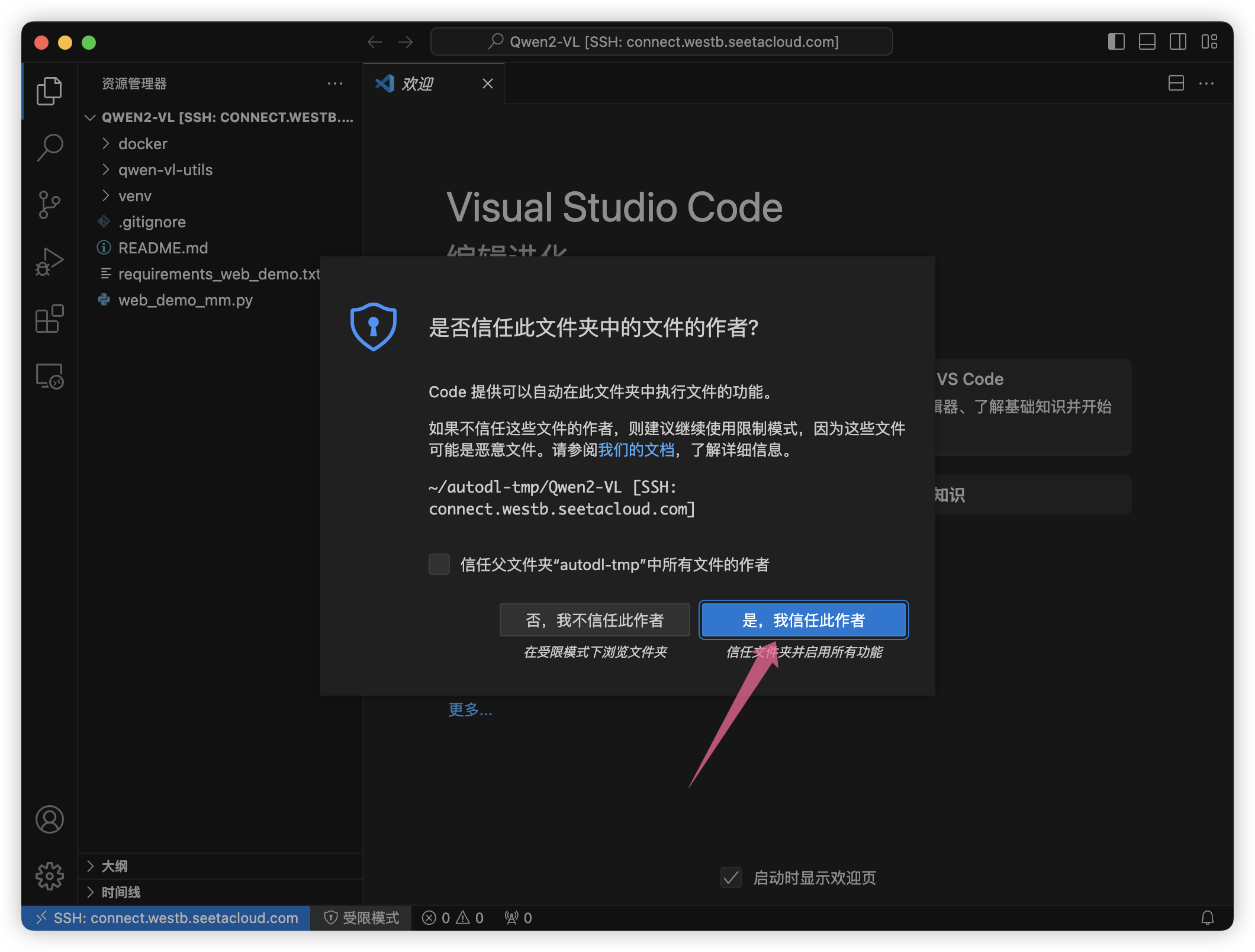
选择信任
点击打开终端
接着激活虚拟环境。
source ./venv/bin/activate
接着回到笔记本模型哪里,复制下载的模型路径。
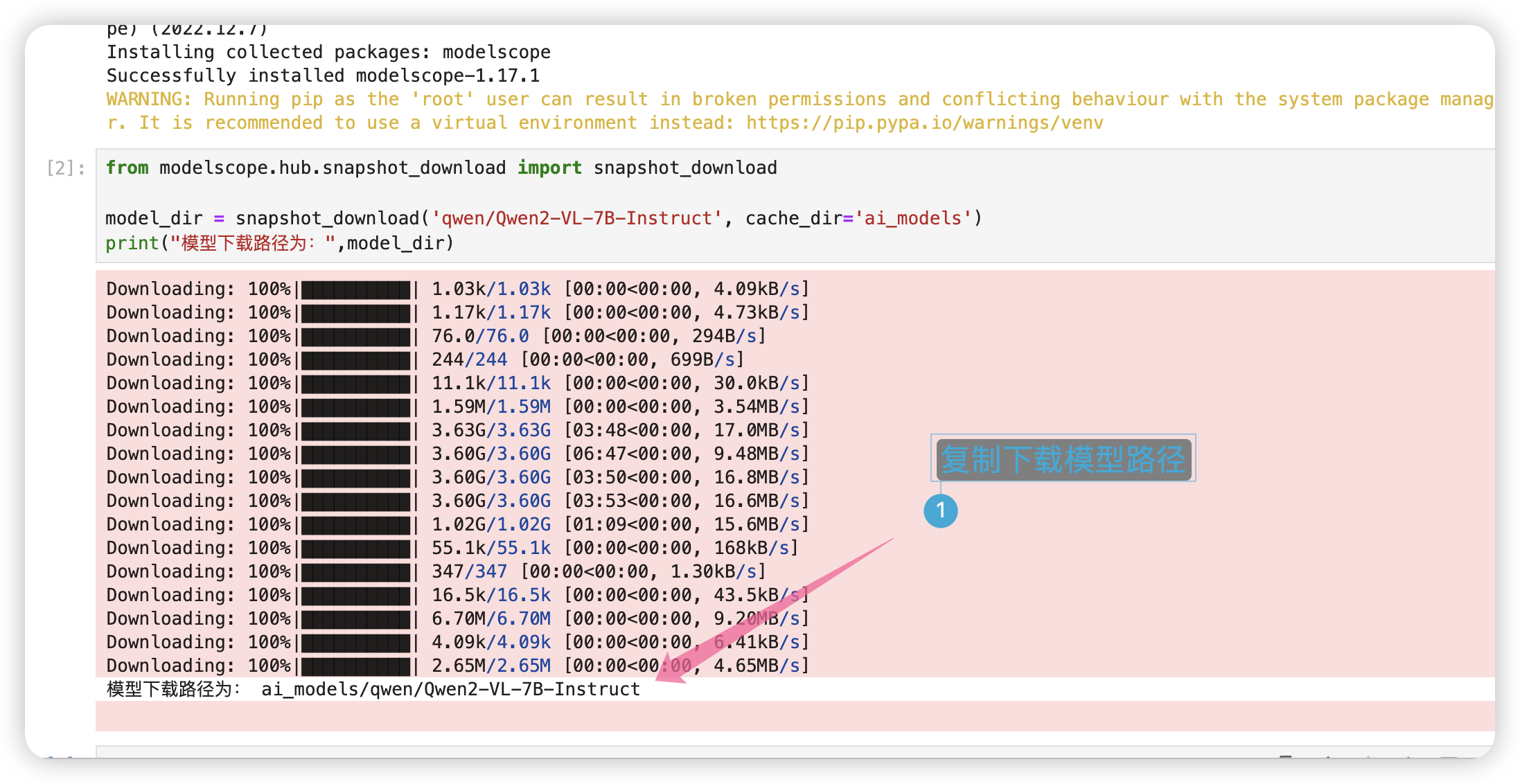
回到VsCode ,编辑web_demo_mm.py,设置模型的路径为如下:

最后,见证奇迹的时候到了,运行我们的Python代码。
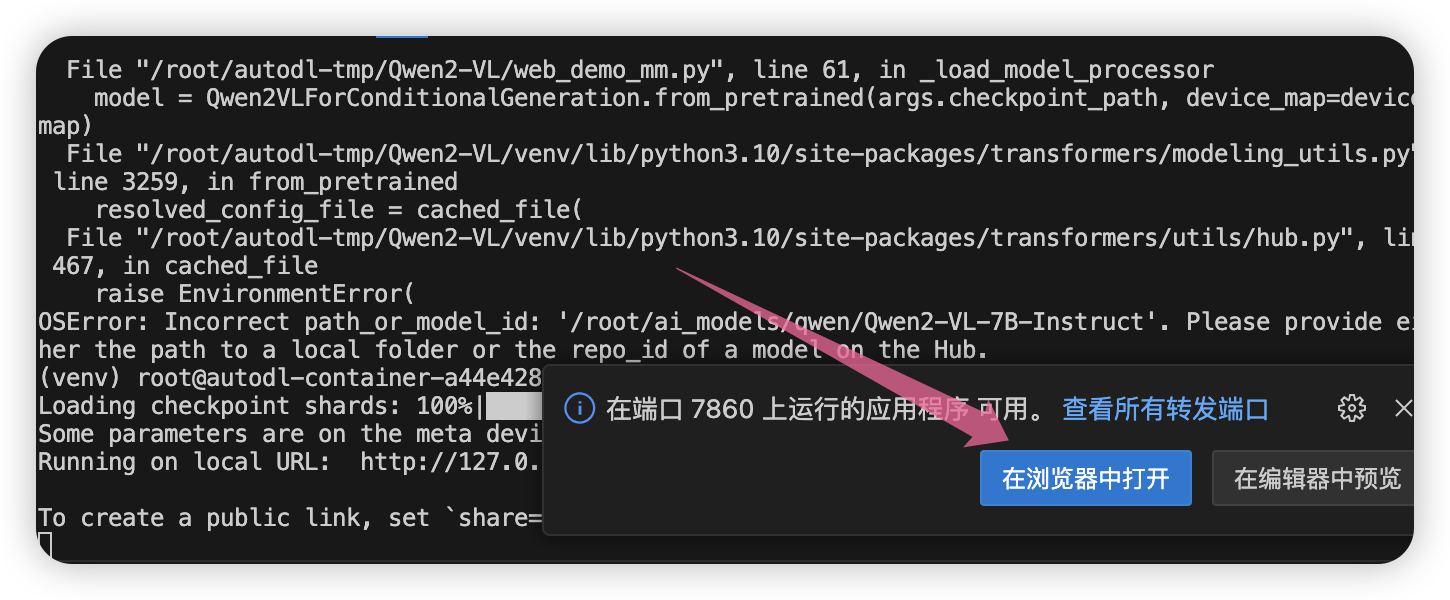
python web_demo_mm.py
选择在浏览器打开。
接着,就可以快乐的玩耍了。
我们来试着让它帮我们识别发票。
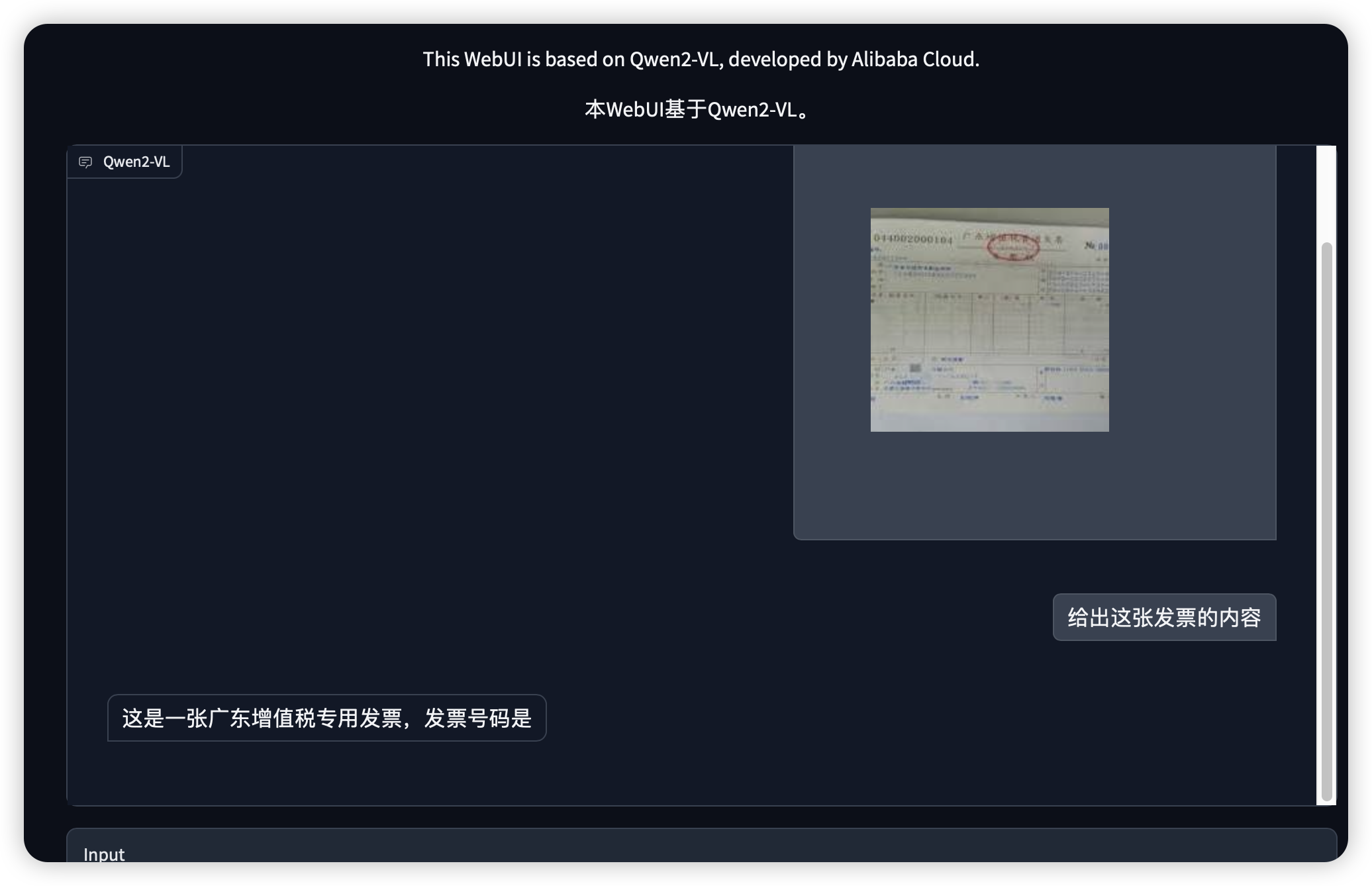
Tips
在视频总结会遇到一些错误,我们可以按以下步骤解决这个问题:
-
安装系统级依赖:
首先,我们需要安装一些必要的系统库,这些库是 PyAV 所需要的。打开终端,运行以下命令:sudo apt-get update sudo apt-get install -y libavformat-dev libavcodec-dev libavdevice-dev libavutil-dev libswscale-dev libswresample-dev libavfilter-dev -
安装 PyAV:
现在我们可以安装 PyAV 了。在终端中运行:pip install av -
更新 torchvision:
确保 torchvision 是最新版本:pip install --upgrade torchvision -
检查其他依赖:
更新所有其他必要的包:pip install --upgrade -r requirements.txt(假设您的项目目录中有 requirements.txt 文件)
-
如果您使用的是虚拟环境(venv),请确保在执行上述命令前已激活该环境。
-
重新运行您的脚本,看看问题是否解决。
如果在执行这些步骤后仍然遇到问题,可能需要检查一下您的 CUDA 版本(如果您在使用 GPU)是否与您的 PyTorch 和 torchvision 版本兼容。
总结
想象一下,如果有了Qwen2-VL的加持,我们去医院检查就不用再发愁看不懂片子了,系统会自动帮你分析;逛淘宝时只要给客服发个包包的图,它就能告诉你详细信息,购物体验直接起飞!
而且啊,Qwen2-VL还是个"外语小达人",能听懂多国语言,帮你翻译文字、总结视频要点,出国旅行、做跨国生意完全不用愁。
还有还有,这位小助手简直是内容创作者的福音!输入一张图,它就能帮你自动生成文案、设计素材,以后做广告、写稿件效率直接翻倍!
想不到吧,原来人工智能已经这么厉害了!阿里这次开源Qwen2-VL,让我们普通用户也能享受到顶尖AI技术的便利,是不是瞬间感觉未来触手可及了呢?
科技始终来源于人性,Qwen2-VL的出现,让机器真正成为了我们生活中贴心的助手和朋友。相信在不久的将来,类似的AI应用将遍地开花,让我们拭目以待吧!
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号