

基于windows10的Flume+kafka+storm的集成学习笔记
这个周末基于windows10单机版学习Flume+kafka+storm的简单集成,目的是加深对应基本概念的认识。这里不具体介绍flume,kafka,storm的原理,只对基本概念只做简单说明。
1.1 准备阶段
操作系统:windows 10家庭版
在官方网站下载下载编译后的软件,本人学习对应的软件版本如下:
apache-flume-1.9.0-bin
apache-storm-1.0.5
kafka_2.11-1.1.1
zookeeper-3.4.10
1.2 学习目标
(1) 使用Flume基于spooling directory和netcat采集日志数据,作为Kafka的Producer;
(2) 使用Kafka的客户端输入日志作为Kafka的Producer;
(3) 使用storm消费Kafka的日志,读取的日志数据保存到文件系统。
如下图:
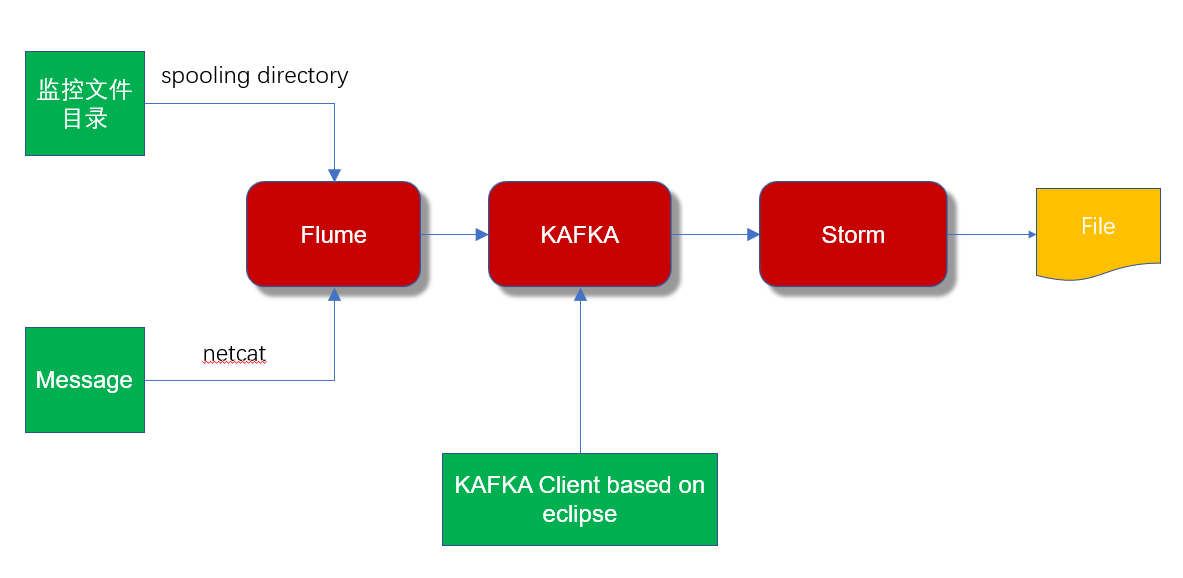
1.3 Flume
1.3.1 基本概念
Flume是一个分布式、可靠、高可用的海量日志采集、聚合、传输的系统。核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,Flume再删除自己缓存的数据。
基本概念:
Source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
Channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
Sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、Hbase、solr、自定义。
Flume运行机制:
Flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据输入的source,一个是数据输出的sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方,例如HDFS等。注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
1.3.1 演示例子
下面的例子以spooling directory source和netcat source为例子进行学习。
步骤一:下载官网flume1.9
将软件解压到本地D:\Study\codeproject\apache-flume-1.9.0-bin
步骤二:在conf目录下复制flume-env.ps1.template改为flume-env.ps1
步骤三:检查安装是否成功:
D:\Study\codeproject\apache-flume-1.9.0-bin\bin>flume-ng.cmd version
Sourcing environment configuration script D:\Study\codeproject\apache-flume-1.9.0-bin\conf\flume-env.ps1
class: org.apache.flume.tools.VersionInfo
arguments:
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
备注:不清楚为啥在windows10下一直报如下错误:
Sourcing environment configuration script D:\Study\codeproject\apache-flume-1.9.0-bin\conf\flume-env.ps1
Test-Path : 路径中具有非法字符。
所在位置 F:\kafka\apache-flume-1.8.0-bin\bin\flume-ng.ps1:106 字符: 56
+ ... ? { "$_" -ne "" -and (Test-Path $_ )} |
+ ~~~~~~~~~~~~
+ CategoryInfo : InvalidArgument: (F:\kafka\apache-flume-1.8.0-bin\":String) [Test-Path],ArgumentException
+ FullyQualifiedErrorId : ItemExistsArgumentError,Microsoft.PowerShell.Commands.TestPathCommand
后将GetHadoopHome、GetHbaseHome、GetHiveHome相关的脚本全部注释掉,就可以了。
步骤四:在conf目录下新增kafka_sink.conf配置文件,内容如下:
# example.conf: A single-node Flume configuration
#命名Agent a1的组件
a1.sources = r1 r2
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 12345
a1.sources.r2.type = spooldir
a1.sources.r2.spoolDir = D:/test
a1.sources.r2.fileHeader = true
#描述Sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = flume
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
#描述内存Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#为Channle绑定Source和Sink
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sinks.k1.channel = c1
由于KAFKA还没有配置好,这里先不启动Flume,等kafka部署好后启动。
1.4 Kafka
1.4.1 基本概念
Kafka是一个分布式数据流平台,可以运行在单台服务器上,也可以在多台服务器上部署形成集群。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
基本概念:
Message(消息):传递的数据对象,主要由四部分构成:offset(偏移量)、key、value、timestamp(插入时间); 其中offset和timestamp在kafka集群中产生,key/value在producer发送数据的时候产生
Broker(代理者):Kafka集群中的机器/服务被成为broker, 是一个物理概念。
Topic(主题):维护Kafka上的消息类型被称为Topic,是一个逻辑概念。
Partition(分区):具体维护Kafka上的消息数据的最小单位,一个Topic可以包含多个分区;Partition特性:ordered & immutable。(在数据的产生和消费过程中,不需要关注数据具体存储的Partition在那个Broker上,只需要指定Topic即可,由Kafka负责将数据和对应的Partition关联上)
Producer(生产者):负责将数据发送到Kafka对应Topic的进程
Consumer(消费者):负责从对应Topic获取数据的进程
Consumer Group(消费者组):每个consumer都属于一个特定的group组,一个group组可以包含多个consumer,但一个组中只会有一个consumer消费数据。
1.4.2 演示例子
第一步:下载对应的软件(依赖zookeeper)
kafka_2.11-1.1.1(目录:D:\Study\codeproject\kafka_2.11-1.1.1)
zookeeper-3.4.10(目录:D:\Study\codeproject\zookeeper-3.4.10)
第二步:运行Zookeeper
这里zookeeper采用单机安装,非常简单,在执行启动脚本之前,有几个基本的配置项需要配置一下,Zookeeper 的配置文件在 conf 目录下,这个目录下有 zoo_sample.cfg 和 log4j.properties,需要将 zoo_sample.cfg 改名为 zoo.cfg,因为 Zookeeper 在启动时会找这个文件作为默认配置文件。
修改zoo.cfg配置:
dataDir=D:/Study/codeproject/zookeeper-3.4.10/data
dataDir就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
执行启动命令:
D:\Study\codeproject\zookeeper-3.4.10\bin>zkServer.cmd
第三步:运行Kafka
修改kafka配置:
D:\Study\codeproject\kafka_2.11-1.1.1\config>server.properties 修改该文件的配置(数据存储的位置)
log.dirs=D:/Study/codeproject/kafka_2.11-1.1.1/data
启动kafka,这里注意一下是否正常运行了,如果日志报错则将日志文件夹删除后再让其自动重新生成。
D:\Study\codeproject\kafka_2.11-1.1.1>.\bin\windows\kafka-server-start.bat .\config\server.properties
第四步:创建一个名字为flume的Topic
D:\Study\codeproject\kafka_2.11-1.1.1\bin\windows>kafka-console-consumer.bat --zookeeper localhost:2181 --topic flume
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
第五步:打开这个Topic的一个Consumer
新打开一个窗口,创建一个KAFKA消费者
D:\Study\codeproject\kafka_2.11-1.1.1\bin\windows>kafka-console-consumer.bat --zookeeper localhost:2181 --topic flume
第六步:启动Flume:
启动刚才配置好的Flume :
D:\Study\codeproject\apache-flume-1.9.0-bin\bin>flume-ng agent --conf ../conf --conf-file ../conf/kafka_sink.conf --name a1 -property flume.root.logger=INFO,console
D:\Study\codeproject\apache-flume-1.9.0-bin\bin>powershell.exe -NoProfile -InputFormat none -ExecutionPolicy unrestricted -File D:\Study\codeproject\apache-flume-1.9.0-bin\bin\flume-ng.ps1 agent --conf ../conf --conf-file ../conf/kafka_sink.conf --name a1 -property flume.root.logger=INFO,console
Sourcing environment configuration script ../conf\flume-env.ps1
Running FLUME agent :
class: org.apache.flume.node.Application
arguments: -n a1 -f "D:\Study\codeproject\apache-flume-1.9.0-bin\conf\kafka_sink.conf"
说明:其中--conf指定配置文件路径,--conf-file指定配置文件,--name指定配置文件里的要启动agent名字(一个配置文件里可以有多个agent的定义),-Dflume.root.logger指定Flume运行时输出的日志的级别和地方。
这样flume就连接到kafka了。
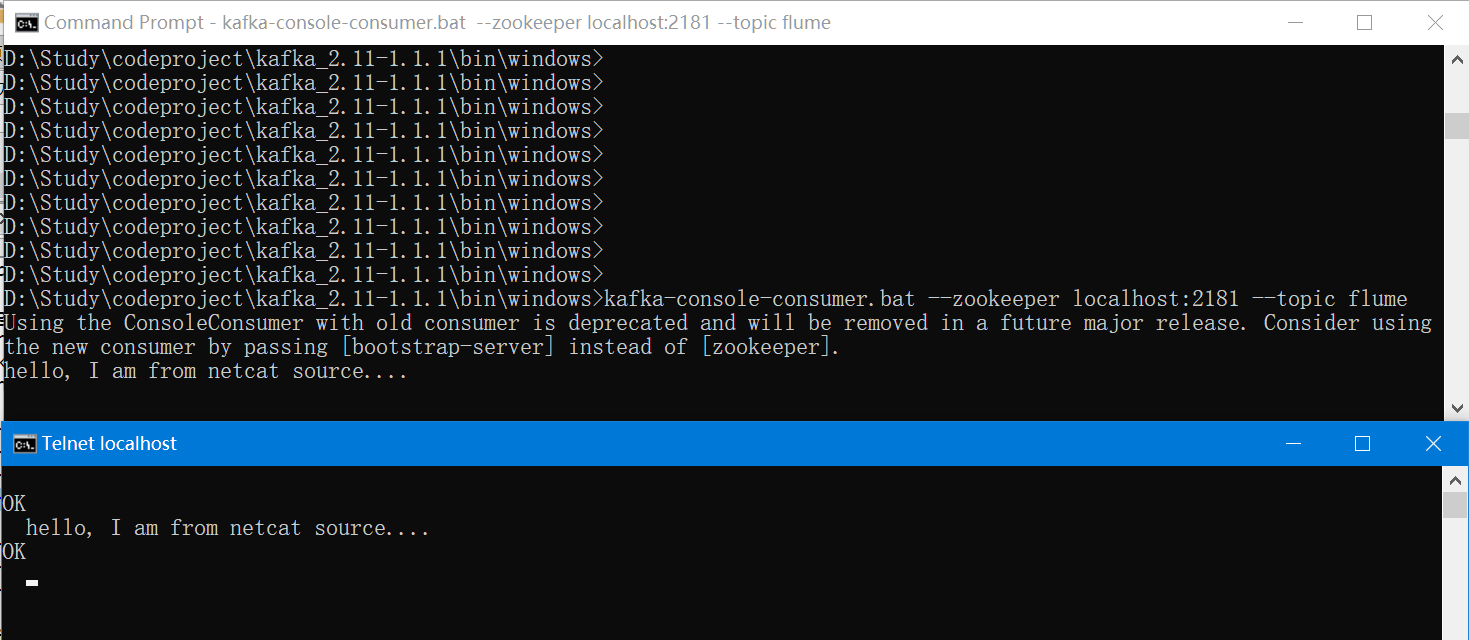
第六步:验证Flume是否与kafka正常连接,使用telnet(netcat)
新建一个窗口,telnet localhost 12345
输入:hello, I am from netcat source....
检查kafka的消费者端口是否正常输出,如下图:
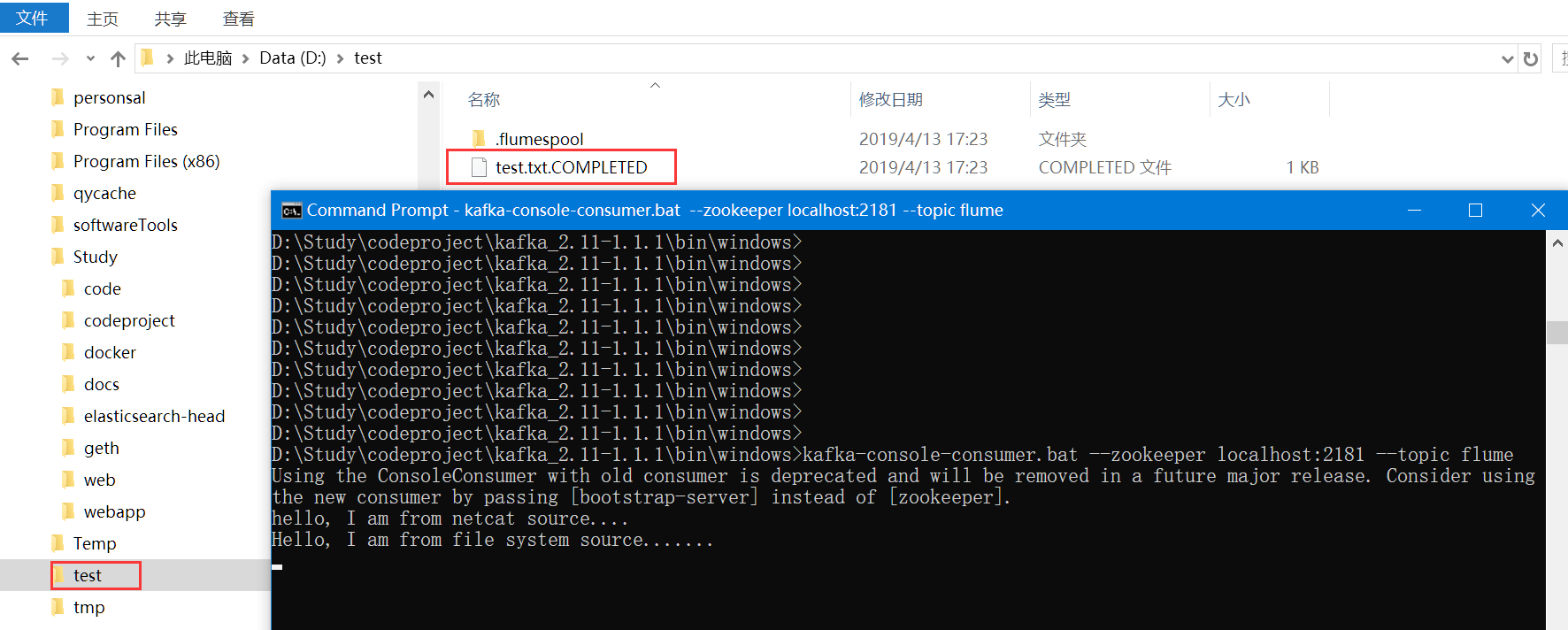
第七步:验证spooling directory接入Flume是否可以被KAFKA消费
在D:\Test目录下放入一个文件test文本文件,内容为:
Hello, I am from file system source.......
观看文件处理结果(文件被增加了COMPLETLED,同时文件内容呈现在KAFKA消费者的界面上):
1.4.3 使用Elicpse开一个简单的生产者,查看KAFKA消费者的输出
* @author 45014
*
*/
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
{
private static Producer<Integer, String> producer;
private final Properties props = new Properties();
{
// 定义连接的broker list
props.put("metadata.broker.list", "localhost:9092");
// 定义序列化类 Java中对象传输之前要序列化
props.put("serializer.class", "kafka.serializer.StringEncoder");
producer = new Producer<Integer, String>(new ProducerConfig(props));
}
{
for (int x = 0; x < 200; x = x + 1) //发送200次消息
{
KDataProducer sp = new KDataProducer();
// 定义topic
String topic = "flume";
// 定义要发送给topic的消息
String messageStr = "I am from Kafka Client based on elcipse...";
List<KeyedMessage<Integer, String>> datalist = new ArrayList<KeyedMessage<Integer, String>>();
// 构建消息对象
KeyedMessage<Integer, String> data = new KeyedMessage<Integer, String>(topic, messageStr);
datalist.add(data);
// 推送消息到broker
producer.send(data);
producer.close();
try
{
Thread.sleep(6000);
}
catch(Exception e)
{
e.printStackTrace();
}
}
}
}
输出结果如下:

1.5 Storm
1.5.1 基本概念
Storm是一个分布式实时流式计算平台,支持水平扩展,通过追加机器就能提供并发数进而提高处理能力;同时具备自动容错机制,能自动处理进程、机器、网络等异常。它可以很方便地对流式数据进行实时处理和分析,能运用在实时分析、在线数据挖掘、持续计算以及分布式 RPC 等场景下。Storm 的实时性可以使得数据从收集到处理展示在秒级别内完成,从而为业务方决策提供实时的数据支持。
Nimbus和Supervisor之间的所有协调工作都是通过Zookeeper集群完成。另外,Nimbus进程和Supervisor进程都是快速失败(fail-fast)和无状态的。所有的状态要么在zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死Nimbus和Supervisor进程, 然后再重启它们,就好像什么都没有发生过。这个设计使得Storm异常的稳定。
Nimbus:即Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
Supervisor:即Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker,一个Supervisor节点中包含多个Worker进程。
Worker:工作进程,每个工作进程中都有多个Task。
Task:任务,在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。每个任务都与一个执行线程相对应。
Topology:计算拓扑,Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的的拓扑结构。
Stream:数据流(Streams)是 Storm 中最核心的抽象概念。一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
Spout:数据源(Spout)是拓扑中数据流的来源。一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;相对应的,不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout可以发送多个数据流。
Bolt:拓扑中所有的数据处理均是由 Bolt 完成的。通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能,Bolt 几乎能够完成任何一种数据处理需求。一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
Stream grouping:为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
Topology是我们开发程序主要的用的组件。Topology则是使用Spout获取数据,Bolt来进行计算。总的来说就是一个Topology由一个或者多个的Spout和Bolt组成。
1.5.1 演示例子
步骤一:下载官网apache-storm-1.0.5
解压到本地D:\Study\codeproject\apache-storm-1.0.5
步骤二:修改storm.yaml的配置
storm.local.dir: "D:\\Study\\codeproject\\apache-storm-1.0.5\\data"
步骤三:启动storm服务,分别
D:\Study\codeproject\apache-storm-1.0.5\bin>storm nimbus
D:\Study\codeproject\apache-storm-1.0.5\bin>storm supervisor
D:\Study\codeproject\apache-storm-1.0.5\bin>storm ui
登录管理页面查看:http://localhost:8080/index.html
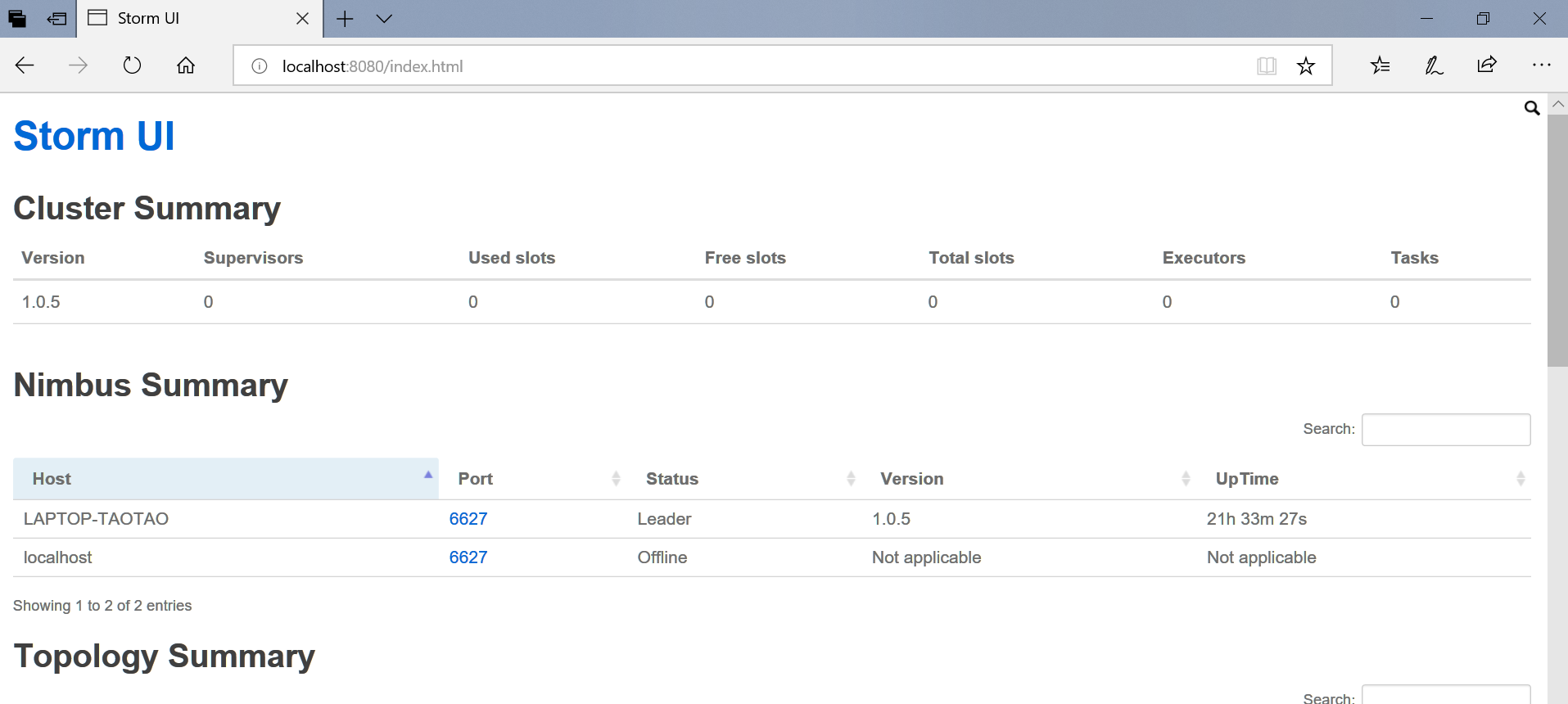
Topology Summary展现提交到集群中的Topology
拓扑运行模式支持:本地模式和分布式模式,下面分别进行学习:
1、本地模式
本地模式是我们用来本地开发调试的,不需要部署到storm集群就能运行,运行java的main函数就可以了。
步骤一:将如下代码去掉注释,然后执行KafkaTopology的main函数:
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("WordCount1", config, builder.createTopology());
步骤二:执行KafkaTopology的main函数
为演示storm获取flume/kafka的数据,需要进行如下操作:
(1)在Flume的telnet 端口输入:
hello, I am from netcat source....
(2)在test文件夹下面新建一个test.txt文件
文件内容为:Hello, I am from file system source.......
(3)执行KDataProducer的main函数,进行kafka prducer生产数据:
步骤三:查看D:盘生成的文件:word-92e0042c-8a74-4343-80c6-f13c1c29c168,内容如下:

内容正好是输入的信息,验证结果OK。。。
2、集群模式
步骤一:修改demo代码:
需要将本地模式的代码注释掉,然后如下代码去掉注释。
StormSubmitter.submitTopology("storm----kafka--test5", config, builder.createTopology());
步骤二:
由于是依赖编译,maven工程中需要添加如下脚本:
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<!--在这里自己写MainClass -->
<mainClass>testdemo.KafkaTopology</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
步骤三:执行编译命令(对应目录为eclipse工程对应的目录):
D:\softwareTools\spring-tool-suite-3.9.4.RELEASE-e4.7.3a-win32-x86_64\mywork\testdemo> mvn clean assembly:assembly
编译成功后结果显示如下:

步骤四:查看生成的jar(注意是包含依赖,否则执行会失败)
步骤五:将上述包复制到storm的bin对应目录下:

步骤六:然后在storm集群中可以执行如下命令:
D:\Study\codeproject\apache-storm-1.0.5\bin>storm jar ./testdemo-0.0.1-SNAPSHOT-jar-with-dependencies.jar testdemo.KafkaTopology KafkaTopology
storm jar ./testdemo-0.0.1-SNAPSHOT-jar-with-dependencies.jar testdemo.KafkaTopology KafkaTopology
注意:KafkaTopology为执行类的入口。
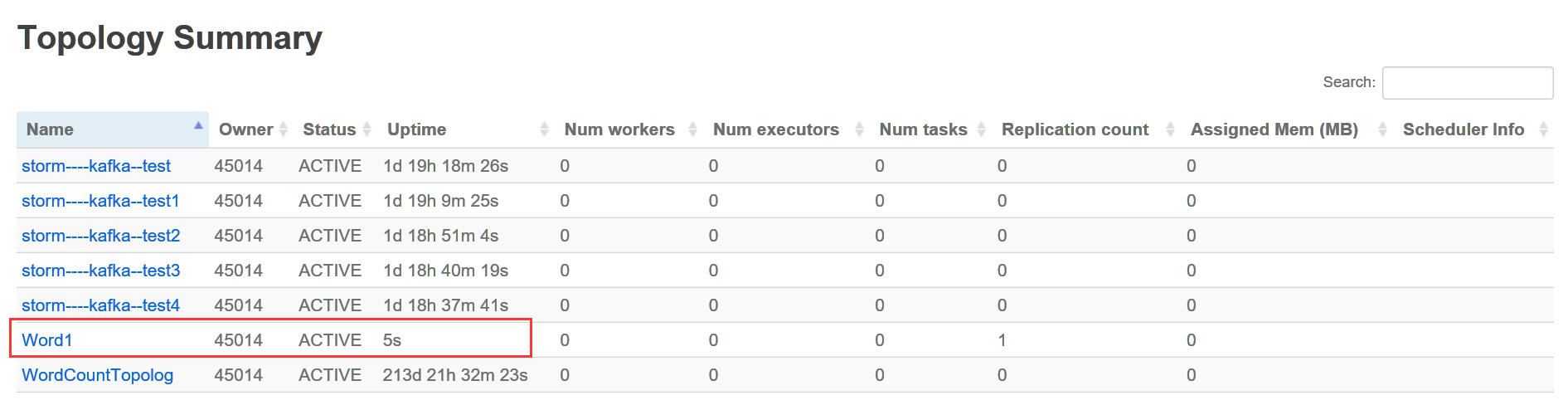
打开storm的管理页面,我们就可以看到提交的Topology,Topology名字对应代码中:
// 集群模式
StormSubmitter.submitTopology("Word1", config, builder.createTopology());
1.5.2 对应简单代码
package testdemo; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org.apache.storm.spout.SchemeAsMultiScheme; import org.apache.storm.topology.TopologyBuilder; import org.apache.storm.tuple.Fields; import org.apache.storm.topology.TopologyBuilder; import java.util.Map; import org.apache.storm.kafka.BrokerHosts; import org.apache.storm.kafka.KafkaSpout; import org.apache.storm.kafka.SpoutConfig; import org.apache.storm.kafka.ZkHosts; /** * @author 45014 * */ public class KafkaTopology { public KafkaTopology() { } public void run() { // 指定zk的地址 BrokerHosts brokerHosts = new ZkHosts("localhost:2181"); TopologyBuilder builder = new TopologyBuilder(); // zookeeper链接地址 BrokerHosts hosts = new ZkHosts("localhost:2181"); // KafkaSpout需要一个config,参数代表的意义1:zookeeper链接,2:消费kafka的topic,3,4:记录消费offset的zookeeper地址 // 集群的/test/consume下面 SpoutConfig sconfig = new SpoutConfig(hosts, "flume", "/test", "consume"); // 消费的时候忽略offset从头开始消费,这里可以注释掉,因为消费的offset在zookeeper中可以找到 sconfig.ignoreZkOffsets = true; // sconfig.scheme = new SchemeAsMultiScheme( new StringScheme() ); builder.setSpout("kafkaspout", new KafkaSpout(sconfig), 1); builder.setBolt("myWritebolt1", new MyWritebolt(), 1).shuffleGrouping("kafkaspout"); Config config = new Config(); config.setNumWorkers(1); try { // 集群模式 //StormSubmitter.submitTopology("Word1", config, builder.createTopology()); // 本地模式 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("Word1", config, builder.createTopology()); } catch (Exception e) { e.printStackTrace(); } } public static void main(String[] args) { new KafkaTopology().run(); } }
/** * */ package testdemo; import java.io.FileWriter; import java.io.IOException; import java.util.Map; import java.util.UUID; import org.apache.storm.task.OutputCollector; import org.apache.storm.task.TopologyContext; import org.apache.storm.topology.OutputFieldsDeclarer; import org.apache.storm.topology.base.BaseRichBolt; import org.apache.storm.tuple.Tuple; import java.util.UUID; /** * @author 45014 * */ public class MyWritebolt extends BaseRichBolt { private static final long serialVersionUID = 1L; OutputCollector collector = null; FileWriter writer = null; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; try { writer = new FileWriter("D:/" + "word-" + UUID.randomUUID().toString()); } catch (IOException e) { e.printStackTrace(); } } public void execute(Tuple input) { try { //得到的内容是byte数组,所以需要转换 String out = new String((byte[])input.getValue(0)); System.out.println(out); writer.write(out); writer.write("\n"); writer.flush(); } catch (IOException e) { e.printStackTrace(); } // collector.ack(input); } public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
关键依赖:
<dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.0.5</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.9.2</artifactId> <version>0.8.2.2</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka</artifactId> <!-- version>0.9.6</version--> <version>1.1.3</version> </dependency> </dependencies>
-------结束-----------

