windows 10环境下搭建基于Hadoop的Eclipse开发环境
1.1 Hadoop环境配置
本文用于指导hadoop在windows10环境下单机版的使用,软件版本选择:
l Windows10家庭版
l JDK 1.8.0_171-b11
l hadoop-2.7.3
1.1.1 Hadoop简要介绍
Hadoop 是Apache基金会下一个开源的分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心,为用户提供了系统底层细节透明的分布式基础架构。
1.1.2准备工作
从官网下载Hadoop二进制版本,然后解压到:D:\Study\codeproject\hadoop-2.7.3。
Java是Hadoop依赖的运行环境,读者可以在Oracle官网获取最新版的Java版本,由于只是运行不是开发,所以也可以只下载JRE。安装完成后配置安装完成后,配置JAVA_HOME和JRE_HOME环境变量。执行如下命令表示JDK安装成功:
C:\Users\45014>java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
右键单击我的电脑 –>属性 –>高级环境变量配置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME,接着编辑环境变量path,将hadoop的bin目录加入到后面
1.1.2 修改Hadoop配置
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/data/temp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/data/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!-- 这个参数设置为1,因为是单机版hadoop -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/datanode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/datanode</value>
</property>
</configuration>
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的yarn-site.xml文件:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
1.1.3 启动Hadoop
(1)进入D:\Study\codeproject\hadoop-2.7.3\bin目录,格式化hdfs,在cmd中运行命令 hdfs namenode -format
(2)运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动以下进程。
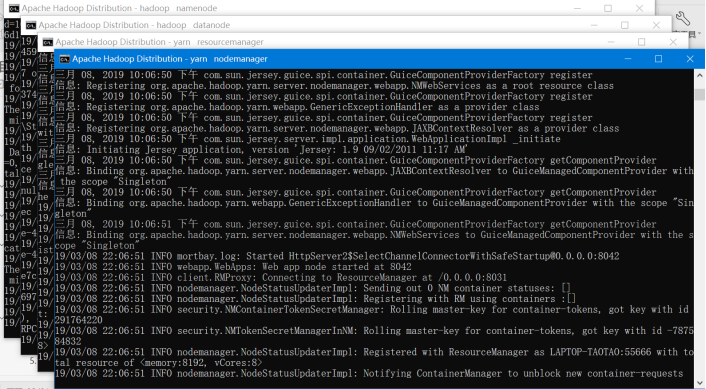
1.1.4 访问Hadoop管理界面
启动成功后,进入资源管理GUI:http://localhost:8088/

节点管理GUI:http://localhost:50070/;
1.2 Eclipse操作Hadoop环境配置
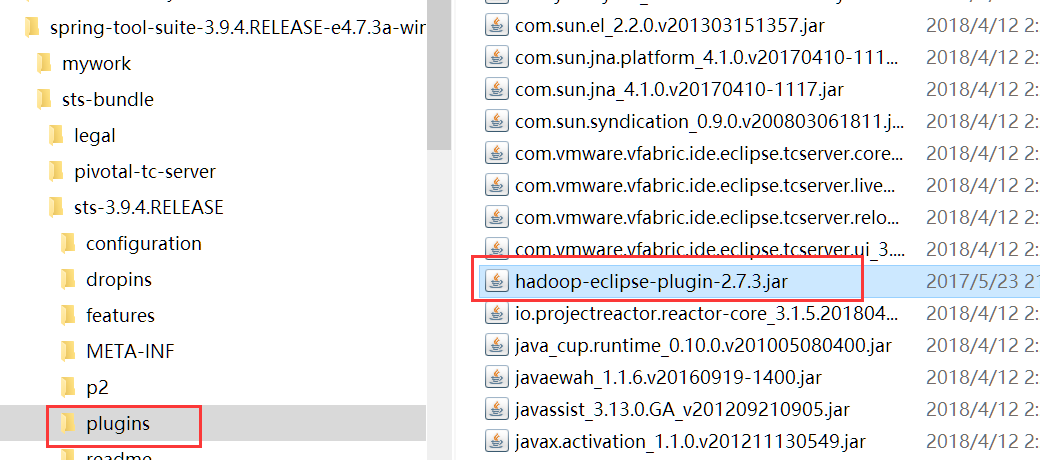
1.在eclipse上安装Hadoop插件
把下载好的hadoop-eclipse-plugin-2.7.1.jar文件拷贝到eclipse安装目录中的plugins文件夹内(注意版本选择,否则可能导致不可用)。如下图:
2.继续配置hadoop编译环境(方便配置,确保已经启动了 Hadoop)
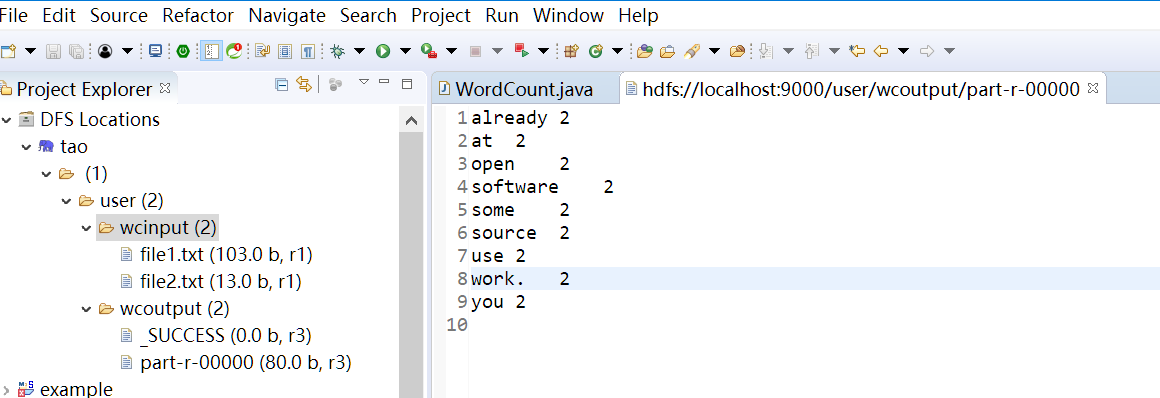
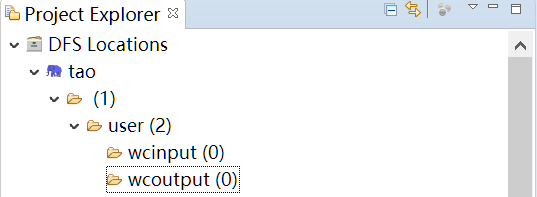
启动 Eclipse 后就可以在左侧的Project Explorer中看到DFS Locations。
3.插件的配置
第一步:选择 Window 菜单下的 Preference。
此时会弹出一个窗体,点击选择 Hadoop Map/Reduce 选项,选择 Hadoop 的安装目录(例如:/home/hadoop/hadoop)。
第二步:切换 Map/Reduce 开发视图
选择Window 菜单下选择 Open Perspective -> Other,弹出一个窗体,从中选择Map/Reduce 选项即可进行切换。
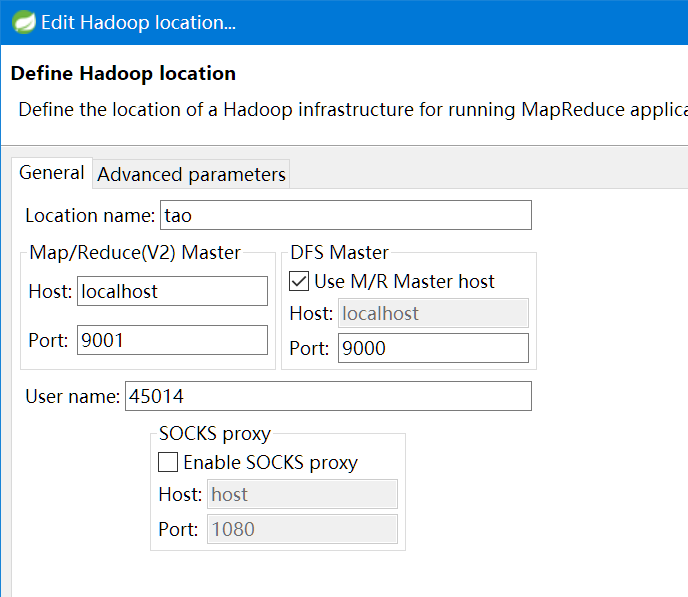
第三步:建立与 Hadoop 集群的连接
点击Eclipse软件右下角的Map/Reduce Locations 面板,在面板中单击右键,选择New Hadoop Location。
在弹出来的General选项面板中,General的设置要与 Hadoop 的配置一致。一般两个 Host值是一样的,如果是伪分布式,填写 localhost 即可,这里使用的是Hadoop伪分布,设置fs.defaultFS为 hdfs://localhost:9000,则 DFS Master 的 Port 改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
1.3 上传文件到HDFS
HDFS是Hadoop体系中数据存储管理的基础。 HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。
1.运行cmd窗口,执行“hdfs namenode -format”;
根据你core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了。
1.创建输入目录
C:\Users\45014>hadoop fs -mkdir hdfs://localhost:9000/user/
C:\Users\45014>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput
2.上传数据到目录
C:\Users\45014>hadoop fs -put D:\file1.txt hdfs://localhost:9000/user/wcinput
C:\Users\45014>hadoop fs -put D:\file2.txt hdfs://localhost:9000/user/wcinput
3.查看文件
C:\Users\45014>hadoop fs -ls hdfs://localhost:9000/user/wcinput
Found 2 items
-rw-r--r-- 1 45014 supergroup 52 2019-03-08 22:48 hdfs://localhost:9000/user/wcinput/file1.txt
-rw-r--r-- 1 45014 supergroup 13 2019-03-08 22:48 hdfs://localhost:9000/user/wcinput/file2.txt
在esclipse界面的DFS Locations右键点击refresh,如下图:

1.4 Map/Reduce的hello world
MapReduce是Google的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
下面代码来自网络,一起参考学习。
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; @SuppressWarnings("unused") public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> // 为什么这里k1要用Object、Text、IntWritable等,而不是java的string啊、int啊类型, //当然,你可以用其他的,这样用的好处是,因为它里面实现了序列化和反序列化。 // 可以让在节点间传输和通信效率更高。这就为什么hadoop本身的机制类型的诞生。 // 这个Mapper类是一个泛型类型,它有四个形参类型,分别指定map函数的输入键、输入值、输出键、输出值的类型。 //hadoop没有直接使用Java内嵌的类型,而是自己开发了一套可以优化网络序列化传输的基本类型。 // 这些类型都在org.apache.hadoop.io包中。 // 比如这个例子中的Object类型,适用于字段需要使用多种类型的时候,Text类型相当于Java中的String类型, //IntWritable类型相当于Java中的Integer类型 { // 定义两个变量或者说是定义两个对象,叫法都可以 private final static IntWritable one = new IntWritable(1);// 这个1表示每个单词出现一次,map的输出value就是1. // 因为,v1是单词出现次数,直接对one赋值为1 private Text word = new Text(); public void map(Object key, Text value, Context context) // context它是mapper的一个内部类,简单的说顶级接口是为了在map或是reduce任务中跟踪task的状态,很自然的MapContext就是记录了map执行的上下文,在mapper类中,这个context可以存储一些job // conf的信息,比如job运行时参数等, // 我们可以在map函数中处理这个信息,这也是Hadoop中参数传递中一个很经典的例子,同时context作为了map和reduce执行中各个函数的一个桥梁,这个设计和Java // web中的session对象、application对象很相似 // 简单的说context对象保存了作业运行的上下文信息,比如:作业配置信息、InputSplit信息、任务ID等 // 我们这里最直观的就是主要用到context的write方法。 // 说白了,context起到的是连接map和reduce的桥梁。起到上下文的作用! throws IOException, InterruptedException { // The tokenizer uses the default delimiter set, which is " \t\n\r": the space // character, the tab character, the newline character, the carriage-return // character StringTokenizer itr = new StringTokenizer(value.toString());// 将Text类型的value转化成字符串类型 while (itr.hasMoreTokens()) { // 实际上就是java.util.StringTokenizer.hasMoreTokens() // hasMoreTokens() 方法是用来测试是否有此标记生成器的字符串可用更多的标记。 word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 我们这里最直观的就是主要用到context的write方法。 // 说白了,context起到的是连接map和reduce的桥梁。起到上下文的作用! int sum = 0; for (IntWritable val : values) {// 叫做增强的for循环,也叫for星型循环 sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration();// 程序里,只需写这么一句话,就会加载到hadoop的配置文件了 // Configuration类代表作业的配置,该类会加载mapred-site.xml、hdfs-site.xml、core-site.xml等配置文件。 // 删除已经存在的输出目录 Path mypath = new Path("hdfs://localhost:9000/user/wcoutput");// 输出路径 FileSystem hdfs = mypath.getFileSystem(conf);// 程序里,只需写这么一句话,就可以获取到文件系统了。 // 如果文件系统中存在这个输出路径,则删除掉,保证输出目录不能提前存在。 if (hdfs.isDirectory(mypath)) { hdfs.delete(mypath, true); } // job对象指定了作业执行规范,可以用它来控制整个作业的运行。 Job job = Job.getInstance();// new Job(conf, "word count"); job.setJarByClass(WordCount.class);// 我们在hadoop集群上运行作业的时候,要把代码打包成一个jar文件,然后把这个文件 // 传到集群上,然后通过命令来执行这个作业,但是命令中不必指定JAR文件的名称,在这条命令中通过job对象的setJarByClass()中传递一个主类就行, //hadoop会通过这个主类来查找包含它的JAR文件。 job.setMapperClass(TokenizerMapper.class); // job.setReducerClass(IntSumReducer.class); job.setCombinerClass(IntSumReducer.class);// Combiner最终不能影响reduce输出的结果 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 一般情况下mapper和reducer的输出的数据类型是一样的,所以我们用上面两条命令就行,如果不一样,我们就可以用下面两条命令单独指定mapper的输出key、value的数据类型 // job.setMapOutputKeyClass(Text.class); // job.setMapOutputValueClass(IntWritable.class); // hadoop默认的是TextInputFormat和TextOutputFormat,所以说我们这里可以不用配置。 // job.setInputFormatClass(TextInputFormat.class); // job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/user/wcinput/file1.txt"));// FileInputFormat.addInputPath()指定的这个路径可以是单个文件、一个目录或符合特定文件模式的一系列文件。 // 从方法名称可以看出,可以通过多次调用这个方法来实现多路径的输入。 FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/wcoutput"));// 只能有一个输出路径,该路径指定的就是reduce函数输出文件的写入目录。 // 特别注意:输出目录不能提前存在,否则hadoop会报错并拒绝执行作业,这样做的目的是防止数据丢失,因为长时间运行的作业如果结果被意外覆盖掉,那肯定不是我们想要的 System.exit(job.waitForCompletion(true) ? 0 : 1); // 使用job.waitForCompletion()提交作业并等待执行完成,该方法返回一个boolean值,表示执行成功或者失败,这个布尔值被转换成程序退出代码0或1,该布尔参数还是一个详细标识,所以作业会把进度写到控制台。 // waitForCompletion()提交作业后,每秒会轮询作业的进度,如果发现和上次报告后有改变,就把进度报告到控制台,作业完成后,如果成功就显示作业计数器,如果失败则把导致作业失败的错误输出到控制台 } }