图的邻接矩阵和邻接表的比较(转)
图的存储结构主要分两种,一种是邻接矩阵,一种是邻接表。
1.邻接矩阵
图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:
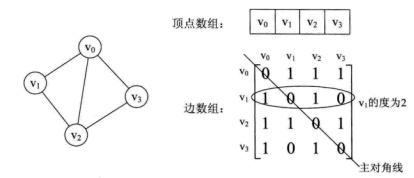
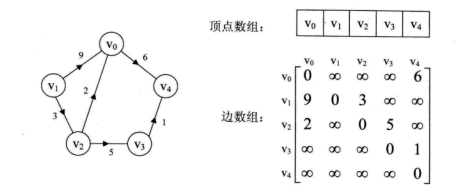
看一个实例,下图左就是一个无向图。
从上面可以看出,无向图的边数组是一个对称矩阵。所谓对称矩阵就是n阶矩阵的元满足aij = aji。即从矩阵的左上角到右下角的主对角线为轴,右上角的元和左下角相对应的元全都是相等的。
从上面可以看出,无向图的边数组是一个对称矩阵。所谓对称矩阵就是n阶矩阵的元满足aij = aji。即从矩阵的左上角到右下角的主对角线为轴,右上角的元和左下角相对应的元全都是相等的。
从这个矩阵中,很容易知道图中的信息。
(1)要判断任意两顶点是否有边无边就很容易了;
(2)要知道某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行或(第i列)的元素之和;
(3)求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点;
而有向图讲究入度和出度,顶点vi的入度为1,正好是第i列各数之和。顶点vi的出度为2,即第i行的各数之和。
若图G是网图,有n个顶点,则邻接矩阵是一个n*n的方阵,定义为:
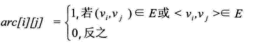
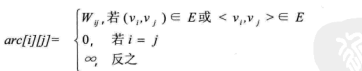
1.2 邻接表
邻接矩阵是不错的一种图存储结构,但是,对于边数相对顶点较少的图,这种结构存在对存储空间的极大浪费。因此,找到一种数组与链表相结合的存储方法称为邻接表。
邻接表的处理方法是这样的:
(1)图中顶点用一个一维数组存储,当然,顶点也可以用单链表来存储,不过,数组可以较容易的读取顶点的信息,更加方便。
(2)图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,所以,用单链表存储,无向图称为顶点vi的边表,有向图则称为顶点vi作为弧尾的出边表。
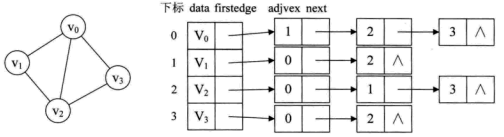
例如,下图就是一个无向图的邻接表的结构。
从图中可以看出,顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。
对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可。如下图所示。
3.两者区别
对于一个具有n个顶点e条边的无向图
它的邻接表表示有n个顶点表结点2e个边表结点
对于一个具有n个顶点e条边的有向图
它的邻接表表示有n个顶点表结点e个边表结点
如果图中边的数目远远小于n2称作稀疏图,这是用邻接表表示比用邻接矩阵表示节省空间;
如果图中边的数目接近于n2,对于无向图接近于n*(n-1)称作稠密图,考虑到邻接表中要附加链域,采用邻接矩阵表示法为宜。
转自:https://blog.csdn.net/curry___/article/details/81742727

 浙公网安备 33010602011771号
浙公网安备 33010602011771号