

作业①
1)要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.we ather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位)
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
单线程爬取代码如下:
1 import urllib.request
2
3 def imageSpider(start_url):
4 #获取
5 r = requests.get(start_url)
6 r.raise_for_status()
7 r.encoding = r.apparent_encoding
8 html = r.text
9 # 正则爬取正常的图片,不爬取类似小图标之类的图片
10 pics = re.findall(r'img class="lunboimgages" src="(.*?jpg)"', html)
11 for i in range(0,len(pics)):
12 print(pics[i])
13 download(pics[i])
14 #保存图片
15 def download(url):
16 global count
17 global flag
18 try:
19 count=count+1
20 if(url[len(url)-4]=="."):
21 ext=url[len(url)-4:]
22 else:
23 ext=""
24 req=urllib.request.Request(url,headers=headers)
25 data=urllib.request.urlopen(req,timeout=100)
26 data=data.read()
27 fobj=open(r"images/"+str(count)+ext,"wb")
28 fobj.write(data)
29 fobj.close()
30 print("downloaded"+str(count)+ext)
31 except Exception as err:
32 print(err)
33
34 import re
35 import requests
36 url = 'http://p.weather.com.cn/zrds/index.shtml'
37 r = requests.get(url)
38 r.raise_for_status()
39 r.encoding = r.apparent_encoding
40 data = r.text
41 #匹配获取对应图片网页的链接
42 urls = re.findall(r'http://p.weather.com.cn/\d\d\d\d/\d\d\/\d\d\d\d\d\d\d.shtml',data)
43 urls_2 =[]
44 #爬取的链接会有两个指向同一个地方,创建新的urls_2保存不一样的链接
45 for i in range(0,len(urls),2):
46 urls_2.append(urls[i])
47 #print(urls_2)
48
49 headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
50 count=0
51
52 for i in range(1,len(urls)):
53 start_url = urls_2[i]
54 imageSpider(start_url)
55 if count == 120:
56 break
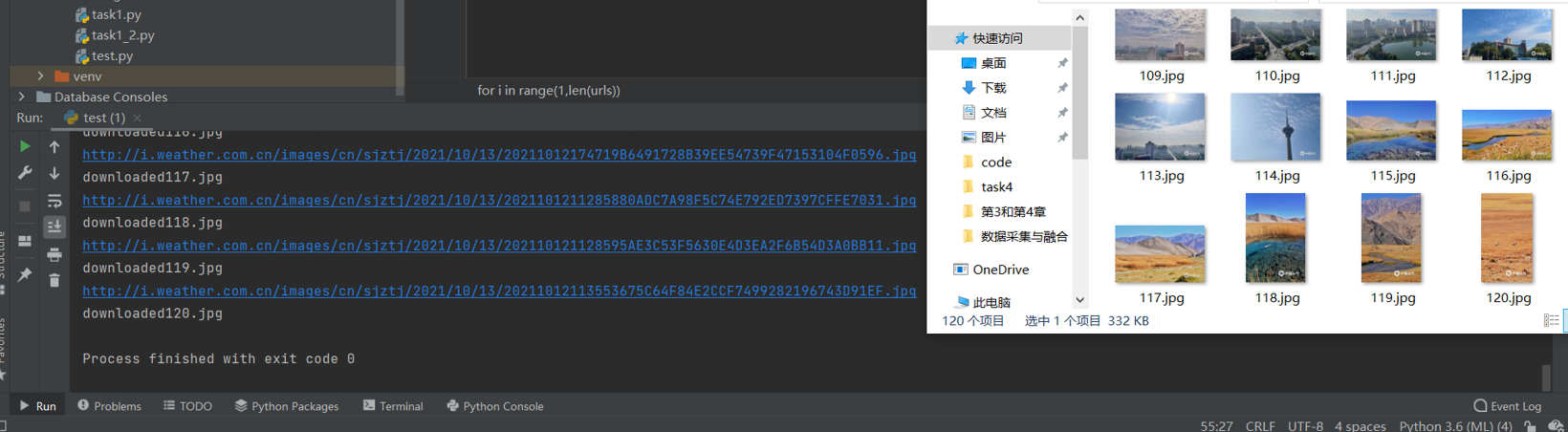
运行结果如下:
多线程代码如下:
1 import urllib.request
2 import threading
3
4 def imageSpider(start_url):
5 global count
6 r = requests.get(start_url)
7 r.raise_for_status()
8 r.encoding = r.apparent_encoding
9 html = r.text
10 #正则爬取正常的图片,不爬取类似小图标之类的图片
11 pics = re.findall(r'img class="lunboimgages" src="(.*?jpg)"', html)
12 for i in range(0,len(pics)):
13 print(pics[i])
14 count = count + 1
15 T = threading.Thread(target=download, args=(pics[i], count))
16 T.setDaemon(False)
17 T.start()
18 threads.append(T)
19 #保存图片
20 def download(url,count):
21 try:
22
23 if(url[len(url)-4]=="."):
24 ext=url[len(url)-4:]
25 else:
26 ext=""
27 req=urllib.request.Request(url,headers=headers)
28 data=urllib.request.urlopen(req,timeout=100)
29 data=data.read()
30 fobj=open(r"images1/"+str(count)+ext,"wb")
31 fobj.write(data)
32 fobj.close()
33 print("downloaded"+str(count)+ext)
34 except Exception as err:
35 print(err)
36
37 import re
38 import requests
39 url = 'http://p.weather.com.cn/zrds/index.shtml'
40 r = requests.get(url)
41 r.raise_for_status()
42 r.encoding = r.apparent_encoding
43 data = r.text
44
45 #匹配获取对应图片网页的链接
46 urls = re.findall(r'http://p.weather.com.cn/\d\d\d\d/\d\d\/\d\d\d\d\d\d\d.shtml',data)
47 urls_2 =[]
48 #爬取的链接会有两个指向同一个地方,创建新的urls_2保存不一样的链接
49 for i in range(0,len(urls),2):
50 urls_2.append(urls[i])
51
52 headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
53 count=0
54 threads=[]
55 for i in range(1,len(urls)):
56 start_url = urls_2[i]
57 imageSpider(start_url)
58 for t in threads:
59 t.join()
60 if count == 120:
61 break
62 print("The End")
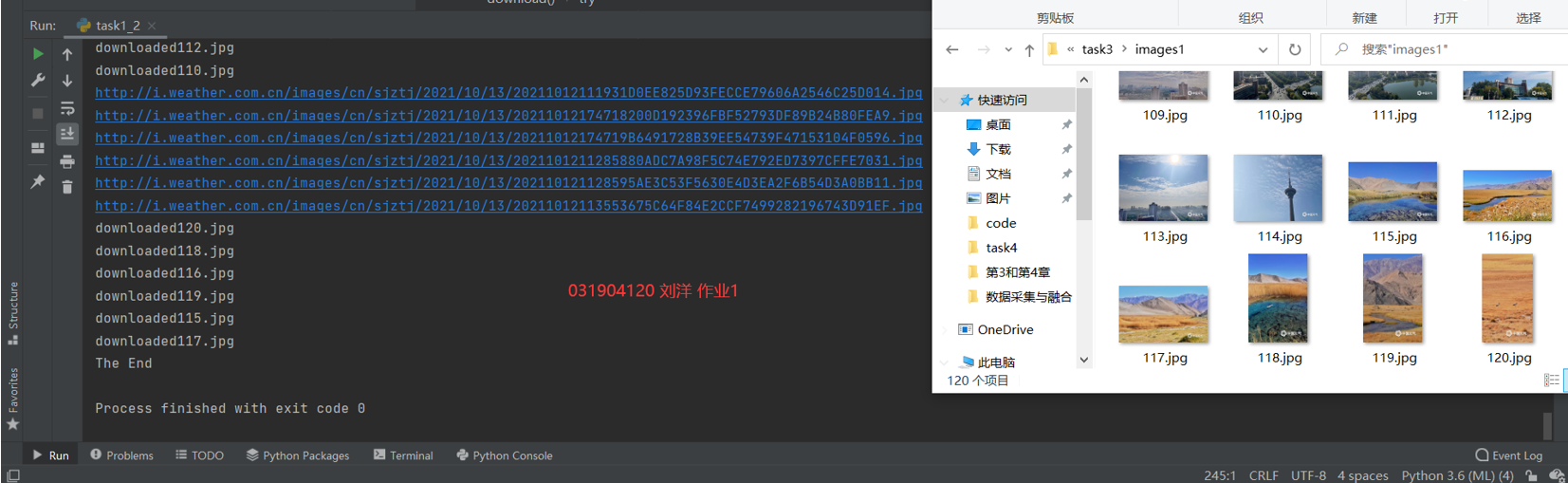
运行结果如下:
心得体会:通过此实验,我进一步了解熟悉了正则匹配、网页的跳转翻页等操作,同时锻炼了我对多线程的理解和使用,。
单线程:作业3/task1.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
多线程:作业3/task1_2.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
作业②
1)作业要求:使用scrapy框架复现作业①。
2)输出信息:同作业①
代码如下:
weather_spiders:
1 import scrapy
2
3 from weather.items import WeatherItem
4
5
6 class WeatherSpidersSpider(scrapy.Spider):
7 name = 'weather_spiders'
8 #allowed_domains = ['http://p.weather.com.cn/zrds/index.shtml']
9 start_urls = ['http://p.weather.com.cn/zrds/index.shtml']
10
11 def parse(self, response):
12 urls = response.xpath('//div[@class="tu"]/a/@href').extract()
13 for url in urls:
14 yield scrapy.Request(url=url, callback=self.imgs_parse)
15
16 def imgs_parse(self, response):
17 item = WeatherItem()
18 #获取对应图片的链接
19 item["pic_url"] = response.xpath('/html/body/div[3]/div[1]/div[1]/div[2]/div/ul/li/a/img/@src').extract()
20 yield item
pipelines:
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 import os 9 import re 10 import urllib 11 12 from scrapy.exceptions import DropItem 13 from scrapy.pipelines.images import ImagesPipeline 14 import scrapy 15 from itemadapter import ItemAdapter 16 17 18 class WeatherPipeline(ImagesPipeline): 19 def get_media_requests(self, item, info): 20 for i in range(len(item['pic_url'])): 21 yield scrapy.Request(url=item['pic_url'][i]) 22 23 def item_completed(self, results, item, info): 24 # 是一个元组,第一个元素是布尔值表示是否成功 25 if not results[0][0]: 26 raise DropItem('下载失败') 27 return item
items:
1 # Define here the models for your scraped items
2 #
3 # See documentation in:
4 # https://docs.scrapy.org/en/latest/topics/items.html
5
6 import scrapy
7
8
9 class WeatherItem(scrapy.Item):
10 # define the fields for your item here like:
11 # name = scrapy.Field()
12 pic_url = scrapy.Field()
settings:
1 BOT_NAME = 'weather'
2
3 SPIDER_MODULES = ['weather.spiders']
4 NEWSPIDER_MODULE = 'weather.spiders'
5 ROBOTSTXT_OBEY = False
6 DEFAULT_REQUEST_HEADERS = {
7 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
8 'Accept-Language': 'en',
9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36',
10 }
11 ITEM_PIPELINES = {
12 'weather.pipelines.WeatherPipeline': 300,
13 }
14 IMAGES_STORE = './image'
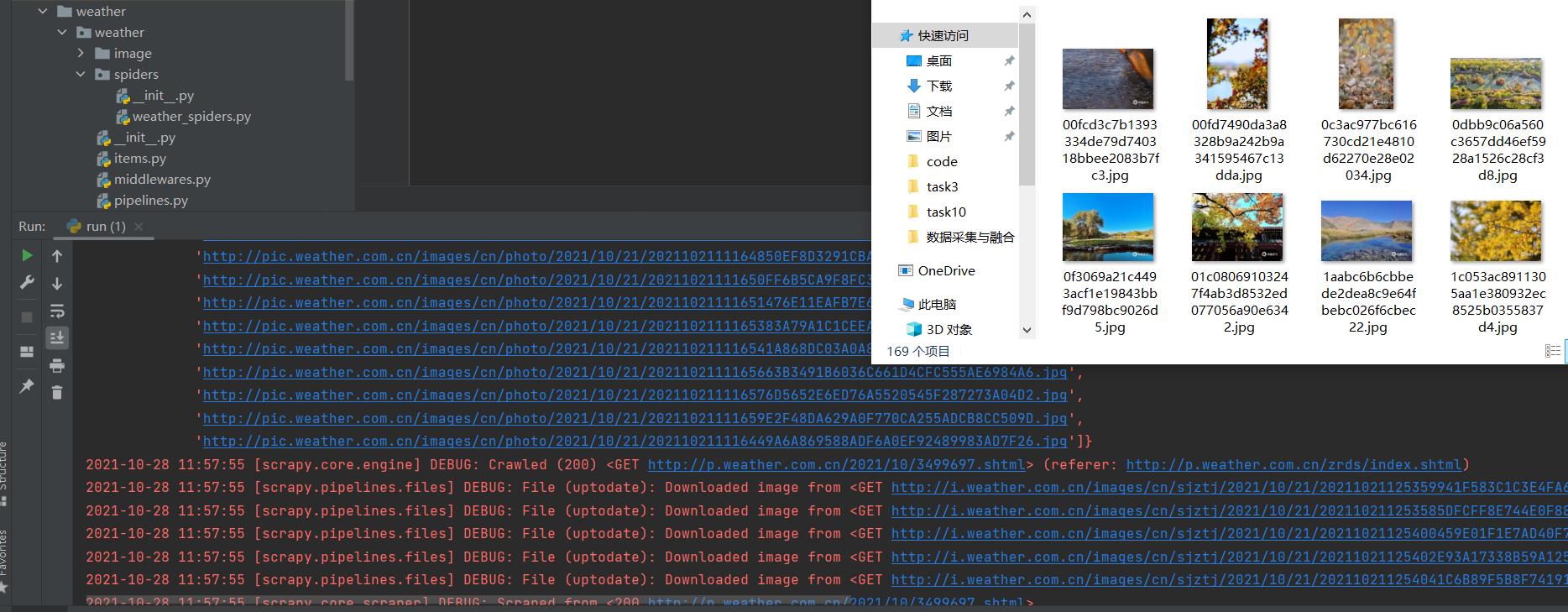
运行结果如下:
心得体会:通过此次实验,我对scrapy的使用有了进一步了解。
码云地址:作业3/weather/weather · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
作业③
1要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在 imgs路径下。
2)候选网站: https://movie.douban.com/top250
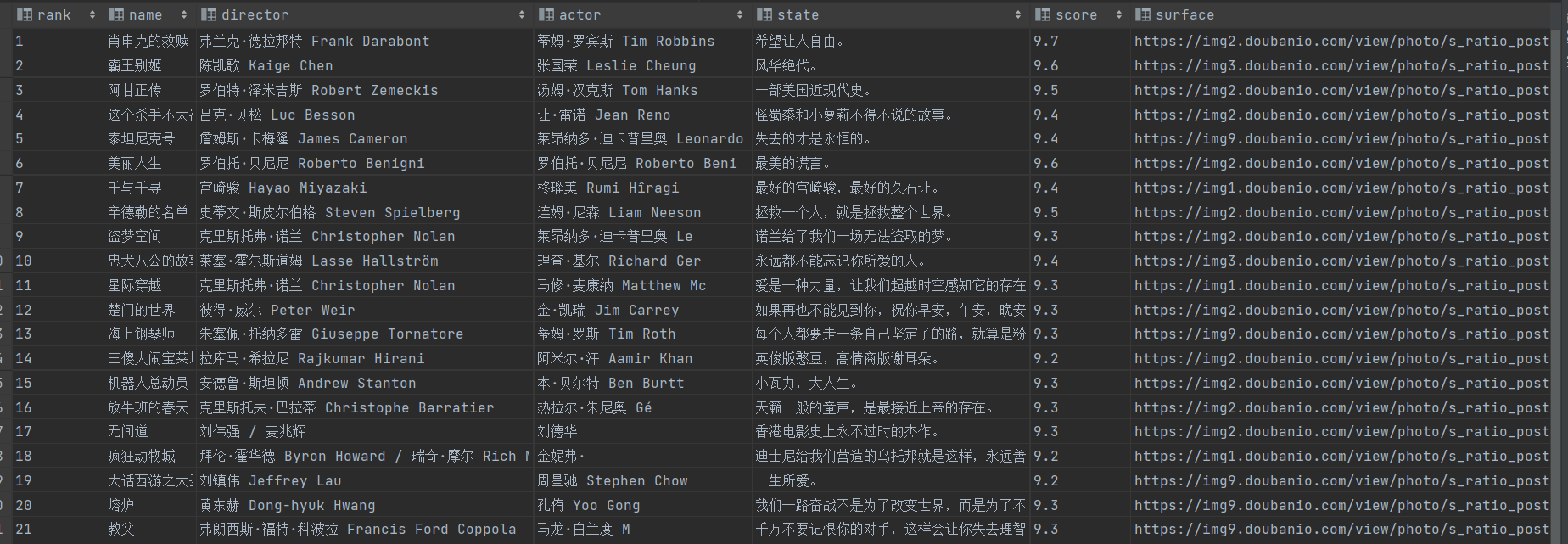
3)输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2.... |
代码如下:
dou_spiders:
1 import re
2 import scrapy
3 from task3.dou.dou.items import DouItem
4
5
6 class DouSpidersSpider(scrapy.Spider):
7 name = 'dou_spiders'
8 allowed_domains = ['movie.douban.com']
9 start_urls = ['https://movie.douban.com/top250']
10
11 def parse(self, response):
12 item = DouItem()
13 title = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()').extract() # 多个span标签
14 movieInfo = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]').extract()
15 star = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()').extract()
16 quote = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()').extract()
17 pic = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[1]/a/img/@src').extract()
18 directors = []
19 actors = []
20 #将movieinfo中的导演与演员分开存储
21 for list in movieInfo:
22 list = list.replace("\n", "")
23 director = re.findall(r'导演: (.*?)\xa0', list)
24 directors.append(director)
25 actor = re.findall(r'主演: (.*?)[\./]', list)
26 actors.append(actor)
27 item['movieinfo'] = movieInfo
28 item['title'] = title
29 item['director'] =directors
30 item['actor'] = actors
31 item['star'] = star
32 item['quote'] = quote
33 item['pic'] =pic
34 yield item
items:
1 # Define here the models for your scraped items
2 #
3 # See documentation in:
4 # https://docs.scrapy.org/en/latest/topics/items.html
5
6 import scrapy
7
8
9 class DouItem(scrapy.Item):
10 # define the fields for your item here like:
11 # name = scrapy.Field()
12 title = scrapy.Field() # 电影名字
13 director = scrapy.Field() # 导演
14 movieinfo = scrapy.Field()#电影信息(包括了演员与导演)
15 actor = scrapy.Field()#演员
16 star = scrapy.Field()#分数
17 quote = scrapy.Field()#简介
18 pic = scrapy.Field()#电影封面
pipelines:
1 import os
2 import urllib
3 # Define your item pipelines here
4 #
5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting
6 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
7 # useful for handling different item types with a single interface
8 import sqlite3
9 from urllib.request import Request
10
11 class movieDB:
12 def openDB(self):
13 self.con = sqlite3.connect("movie.db") # 连接数据库,没有的话会注定创建一个
14 self.cursor = self.con.cursor() # 设置一个游标
15 try:
16 self.cursor.execute("create table movies(rank varchar(10),name varchar(10),director varchar(10),actor varchar(10),state varchar(20),score varchar(10),surface varchar(50))")
17 # 创建电影表
18 except:
19 self.cursor.execute("delete from movies")
20
21 def closeDB(self):
22 self.con.commit() # 自杀
23 self.con.close() # 关闭数据库
24
25 def insert(self,Rank,Name,Director,Actor,State,Score,Surface):
26 try:
27 self.cursor.execute("insert into movies(rank,name,director,actor,state,score,surface) values (?,?,?,?,?,?,?)", (Rank, Name, Director, Actor, State, Score, Surface))
28 # 插入数据
29 except Exception as err:
30 print(err)
31
32
33
34
35 class DouPipeline(object):
36 def process_item(self, item, spider):
37 # movieinfo = item["movieinfo"]
38 title = item["title"]
39 director = item["director"]
40 actor = item["actor"]
41 star = item["star"]
42 quote = item["quote"]
43 pic = item["pic"]
44 print(title)
45 #print用于打印测试
46 # print(movieinfo)
47 # print(pic)
48 # print(quote)
49 # print(star)
50 # print(director)
51 # print(actor)
52 os.mkdir("./img/")
53 moviedb = movieDB() # 创建数据库对象
54 moviedb.openDB() # 打开数据库
55 for i in range(len(title)):
56 print(str(i + 1) + "\t" + title[i] + "\t" + director[i][0] + "\t" + actor[i][0] + "\t" + quote[i] + "\t" +star[i] + "\t\t" + pic[i])
57 moviedb.insert(i + 1, title[i], director[i][0], actor[i][0], quote[i], star[i], pic[i])
58 urllib.request.urlretrieve(pic[i], "./img/" + title[i] + ".jpg")
59 print("成功存入数据库")
60 moviedb.closeDB() # 关闭数据库
运行结果如下:
心得体会:加深了对Xpath与scrapy的理解,对数据库的使用更加理解
