

作业①
1)
– 要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
– 输出信息:
|
2020排名 |
2019排名 |
全部层次 |
学校类型 |
总分 |
|
1 |
2 |
前2% |
中国人民大学 |
1069.0 |
|
2...... |
|
|
|
|
代码如下:
import urllib.request import re #获取 url = 'https://www.shanghairanking.cn/rankings/bcsr/2020/0812 ' req = urllib.request.Request(url) response = urllib.request.urlopen(req) html = response.read().decode('utf-8') #print(html) #tdList = re.findall(r'<td[^>]*>(.*?)</td>',html, re.I | re.M) #print(tdList) #爬取总的信息 detail_data = re.findall(r'class="rk-table"(.*?)</table>', html, re.S)[0] #匹配学校名称 tdList1 = re.findall(r'class="name-cn"[^>]*>(.*?)</a>',html, re.I | re.M) #匹配2020学校排名 tdList2 = re.findall(r'div class="ranking"(.*?) </div>',detail_data,re.S) tdList2=''.join(tdList2) tdList2 = re.findall(r"\d+\.?\d*", tdList2) data1 = [] for i in range(0,len(tdList2)): if i % 3 == 2: data1.append(tdList2[i]) #print(detail_data) #匹配学科层次 tdList3 = re.findall(r'前\d+%',detail_data,re.S) data2 = [] for i in range(0,len(tdList3)): if i >6 : data2.append(tdList3[i]) #学科总分 tdList4 = re.findall(r'\d+\.\d+',detail_data,re.S) #print(tdList4) #print(data1) #按格式输出 print("{:^10}\t{:^8}\t{:^10}\t{:^20}".format("排名","全部层次","学校名称","总分")) for i in range(0,len(data1)): print("{:^10}\t{:^10}\t{:^10}\t{:^20}".format(data1[i],data2[i],tdList1[i],tdList4[i]))
运行结果如下:
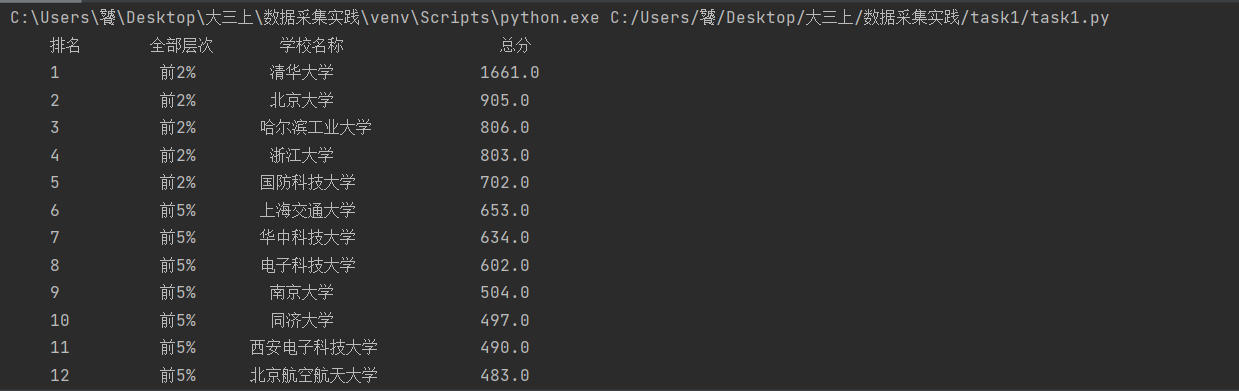
码云地址:作业1/task1.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
2)、心得体会
分析网页,体会urllib库和re匹配的使用方法,在爬取网页的时候,总分一开始匹配很久都没有找到,问了舍友,直接使用\d+.\d+来匹配,对这些方法的体会加深,也算是爬虫初入门。
作业②
1)
– 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
– 输出信息:
|
序号 |
城市 |
AQI |
PM2.5 |
SO2 |
No2 |
Co |
首要污染物 |
|
1 |
北京 |
55 |
6 |
5 |
1.0 |
225 |
— |
代码如下:
import requests from bs4 import BeautifulSoup #获取 def getHTMLText(url, loginheaders): try: r = requests.get(url, headers=loginheaders, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" #url与header url = 'https://datacenter.mee.gov.cn/aqiweb2/' loginheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36', } #获取数据 data = getHTMLText(url,loginheaders) s = BeautifulSoup(data,"html.parser") l = s.select('tbody[id="legend_01_table"] tr') #序号 num = 1 #输出 print("{:^10}\t{:^10}\t{:^6}\t{:^10}\t{:^10}\t{:^10}\t{:^6}\t{:^6}\t{:^6}\t{:^6}".format("序号","city","AQI","PM2.5","PM10","SO2","NO2","CO","O3","main_pollution")) for i in l : city = i.select('td')[0].text AQI = i.select('td')[1].text PM2 = i.select('td')[2].text PM10 = i.select('td')[3].text SO2 = i.select('td')[4].text NO2 = i.select('td')[5].text CO = i.select('td')[6].text O3 = i.select('td')[7].text main_pollution = i.select('td')[8].text.strip() print("{:^8}\t{:^8}\t{:^6}\t{:^10}\t{:^10}\t{:^10}\t{:^6}\t{:^6}\t{:^6}\t{:^6}".format(num,city,AQI,PM2,PM10,SO2,NO2,CO,O3,main_pollution)) num += 1
运行结果如下:
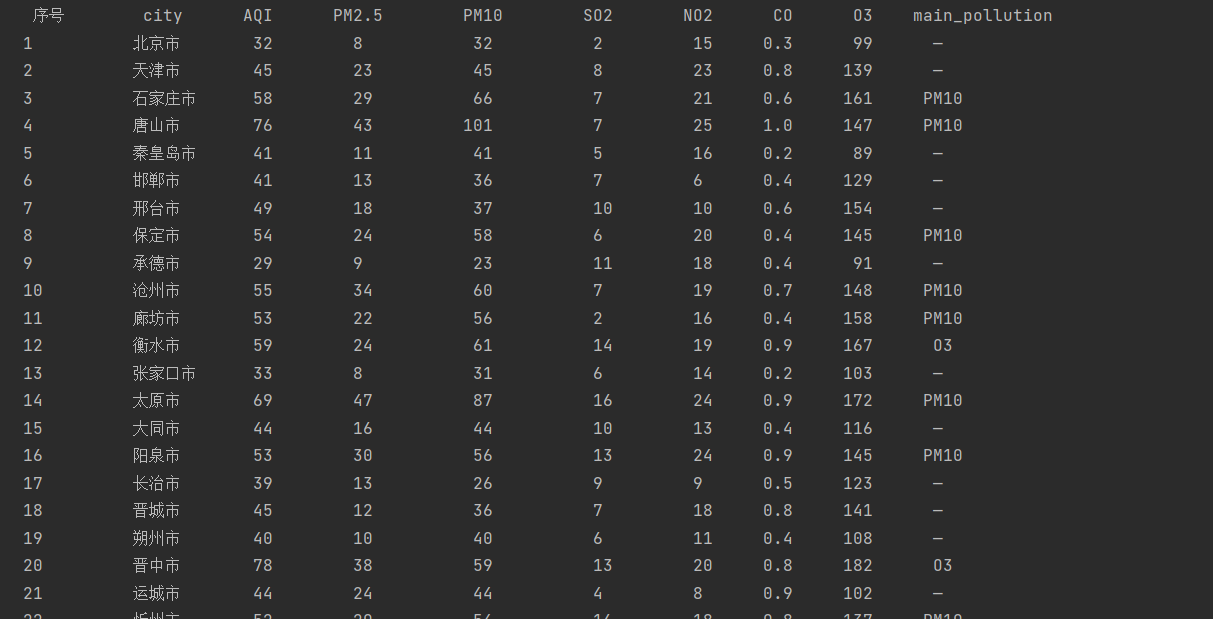
码云地址:作业1/task2.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
2)、心得体会
感觉beautifulsoup和requests更加方便
作业③
1)、
– 要求:使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/)爬取该网站下的所有图片
– 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
代码如下:
import requests import re #获取 def getHTMLText(url, loginheaders): try: r = requests.get(url, headers=loginheaders, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" #url与header url = 'http://news.fzu.edu.cn/' loginheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36', } data = getHTMLText(url,loginheaders) tdlist1 = re.findall(r'src=".*.jpg', data) #print(tdlist1) #去掉前面的src,最后与网页组成图片的正确路径 data1 = [] for i in range(len(tdlist1)): flag = 'http://news.fzu.edu.cn'+tdlist1[i][5:] # print(flag) res = requests.get(flag) with open("picture/{}.jpg".format(i), "wb") as f: f.write(res.content) print("成功下载") #print(data1)
码云地址:作业1/task3.py · 刘洋/2019数据采集与融合 - 码云 - 开源中国 (gitee.com)
运行结果如下:
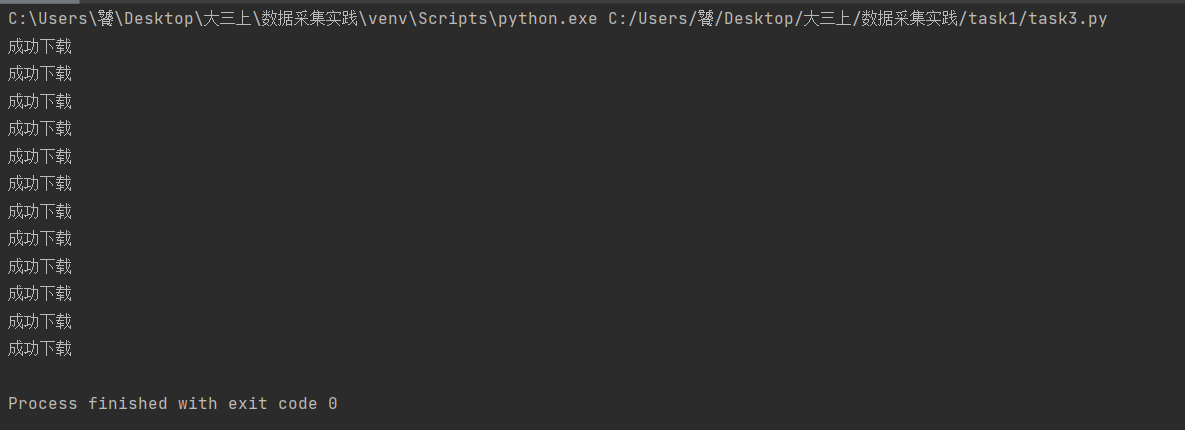
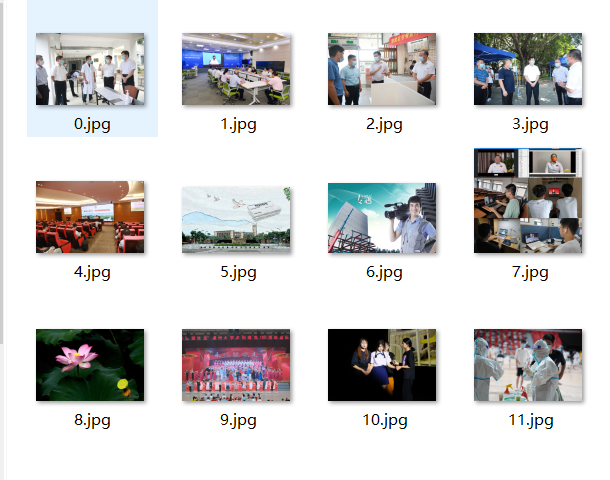
2)、心得体会
图片的路径需要加上本身的网页组成,要将匹配到的字符串去掉前面的src,在第一次写的时候不知道为什么同样的网址拒绝访问,然后重启之后又允许访问了。
