
MYSQL IN 一定走索引吗?
摘要
IN 一定走索引吗?那当然了,不走索引还能全部扫描吗?好像之前有看到过什么Exist,IN走不走索引的讨论。首先说明:IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描。
我就在我本地找一找张之前随便建的表,来看一下:

CREATE TABLE `products` ( `id` INT(10) NOT NULL AUTO_INCREMENT, `created_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, `updated_at` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, `code` VARCHAR(255) NOT NULL DEFAULT '' COLLATE 'utf8mb4_general_ci', `price` INT(10) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) USING BTREE ) COLLATE='utf8mb4_general_ci' ENGINE=InnoDB AUTO_INCREMENT=47 ;
然后插入一些数据,从上面的建表语句,可以看到,我已经插入了46条数据。
EXPLAN 分析执行的SQL语句,当然也可以使用工具提供的快捷键,这里,我使用的是HeidiSQL 这款工具
场景1:当IN中的取值只有一个主键时
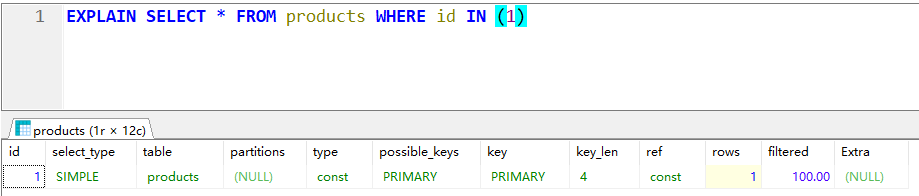
我们只需要注意一个最重要的type 的信息很明显的提现是否用到索引:
type结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
对上面的解释:
all:全表扫描
index:另一种形式的全表扫描,只不过他的扫描方式是按照索引的顺序
range:有范围的索引扫描,相对于index的全表扫描,他有范围限制,因此要优于index
ref: 查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
const:通常情况下,如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。至于如何转化以及何时转化,这个取决于优化器
一般来说,得保证查询至少达到range级别,最好能达到ref,type出现index和all时,表示走的是全表扫描没有走索引,效率低下,这时需要对sql进行调优。
当extra出现Using filesor或Using temproary时,表示无法使用索引,必须尽快做优化。
possible_keys:sql所用到的索引
key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
rows: 显示MySQL认为它执行查询时必须检查的行数。
场景2:扩大IN中的取值范围

此时仍然走了索引,但是效率降低了
场景3:继续扩大IN的取值范围

发现此时已经没有走索引了,而是全表扫描,type 的值为ALL ,并且我共插入了46条数据,这里检查的rows 就是46,也恰巧证明了是全表扫描
场景4:表中存在多个索引
在一张表中,仅有千万级别的数据,现在我有一个SQL语句,我该增加的索引都增加了,但是执行速度很慢,我们经过分析执行的SQL语句得到如下:

是因为,在查询的时候,使用的索引错误了,也可以强制其走指定的索引:
select * from table force index(idx_start_date) where ....
总结
根据实际的情况,需要控制IN查询的范围。原因有以下几点
1. IN 的条件过多,会导致索引失效,走索引扫描
2. IN 的条件过多,返回的数据会很多,可能会导致应用堆内内存溢出。
所以必须要控制好IN的查询个数


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架