
Redis缓存NoSQL
下面是一些关于Redis比较好的文章,因为篇幅较大,我就将其折叠起来了。不太喜欢分不同的笔记去记载,除非真的很多很多。所以本文不仅要对Redis做简单的介绍,还要分别介绍Redis中的五种结构,并会贴上一些示例代码,因为篇幅比较大,所以示例代码都是折叠起来的,有需要看代码的请自行点开,还请谅解。这里只附上了不分示例代码。



redis.conf配置详细解析https://www.cnblogs.com/kreo/p/4423362.html
项目首页,下方是各种语言支持列表:
http://code.google.com/p/redis/
作者在wiki中给出了一个非常好的例子,以使我们可以快速上手,地址:
http://code.google.com/p/redis/wiki/TwitterAlikeExample
同时作者推荐的另一个教程,地址:
http://labs.alcacoop.it/doku.php?id=articles:redis_land
一个redis爱好者创建的相关问题讨论网站:
http://www.rediscookbook.org/
为什么使用 Redis及其产品定位
http://www.infoq.com/cn/articles/tq-why-choose-redis
Redis内存使用优化与存储
http://www.infoq.com/cn/articles/tq-redis-memory-usage-optimization-storage
https://www.linuxidc.com/Linux/2011-02/32700.htm
本地缓存,当前进程的内存,把数据存起来,下次直接使用,可以提升效率。
1、容量有限,window下面,32位一个进程最多2G或者3G,64位最多也就4G
2、多服务器直接需要缓存共享,需要分布式缓存,远程服务器内存管理数据,提供读写接口,效率高。
分布式缓存:
1、Memcached,最早流行的
2、Redis(NoSQL)现在的主流方案
为什么现在都升级到Redis(NoSQL)去了?
NoSQL:
非关系型数据库,Not Only SQL
web1.0时代,服务端提供数据,客户端看,只能看新闻
web2.0时代,客户端可以向服务端互动了,现在能评论了
数据的关系负责:
好友关系(张三有100个好友,映射表,其实这个映射表就荣誉了,关系型数据库开始累赘了)
再就是数据库读取和写入压力,硬盘的速度满足不了,尤其是一些大数据量,所以产生了NoSQL。
特点:基于内存(MongoDB是基于文档的),没有严格的数据格式,不是一行数据的列必须一样。封堵的类型,满足web2.0的需求。
Redis和MongoDB都是NoSQL,应该在什么场景去选择呢?数据量比较大,用MongoDB,否则其他的一切需求,用Redis就可以解决。
Redis:REmote DIctionary Server,远程点点服务器,基于内存管理(数据存在内存),实现了五种数据结构(String、HashTable、Set、ZSet、List去分别对应各种具体需求),单线程模型应用程序(单进程单线程),对外提供插入-查询-固化-集群功能。
Redis----SQLServer
Redis-Cli---SQLClient
Redis支持N多个命令,相当于SQL语句
ServerStack(1小时6000次请求)----ADO.NET
StackExchange,免费的,其实更像是ORM,封装了连接+命令。
https://github.com/dmajkic/redis/downloads 下载地址
管理员模式打开控制台(配置成自己的路径)
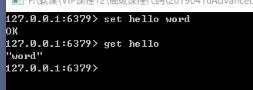
可以打开redis-cli.exe尝试使用,
输入:set key value
结果:OK
输入:get key
结果:value
Redis安装与启动,以及可视化管理工具,请参考:https://blog.csdn.net/lihua5419/article/details/80661684
用cli,可以简单的对Redis数据新增和获取
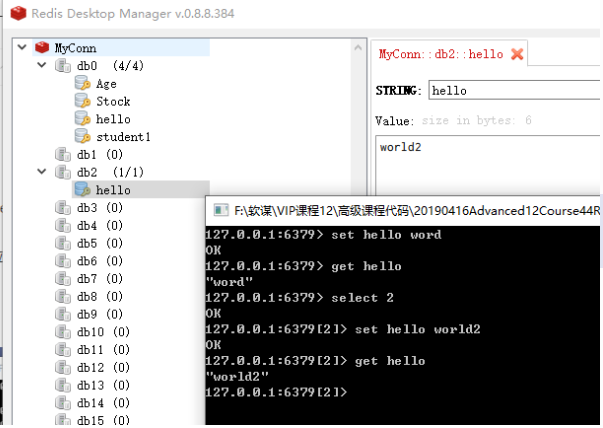
基于内存管理,速度快,不能当做数据库。Redis还有个固化数据的功能,VitualMemory,把一些不经常访问是会存在硬盘。可以哦诶之的,down掉会丢失数据snapshot可以保存到硬盘。AOF,数据辩护记录日志,很少用。Redis毕竟不是数据库,只能用来提升性能,不能作为数据的最终依据。
多线程模型:
.NET应用都是多线程模型,尤其是网站,可以更好的发挥硬件的能力,但是也有线冲突的问题和调度成本。
单线程模型:
Node.js是单线程,整个进程只有一个线程,线程就是执行流,性能低?实际上并非如此。一次网络请求操作----正则解析请求----加减乘除+数据库操作(发命令--等结果),读文件(发命令---等结果)+调用接口(发命令----等结果),单线程都是事件驱动,发起命令就做下一件事,这个线程是完全不做等待的,一直在计算。
多进程,多进程提供集群;单线程多进程的模式来提供集群服务。,B 查询还有没有--有---1更新
单线程最大的好处就是原子性操作,就是要么都成功,要么都失败,不会出现中间状态,Redis中的每个命令都是原子性的(因为单线程),不用考虑并发。
C#程序中,要使用Redis,首先要Nuget包安装一些程序集。下面是一些初始化的工作,写法一般都是固定的,我就折叠起来了。
/// <summary> /// redis配置文件信息 /// 也可以放到配置文件去 /// </summary> public sealed class RedisConfigInfo { /// <summary> /// 可写的Redis链接地址 /// format:ip1,ip2 /// /// 默认6379端口 /// </summary> public string WriteServerList = "127.0.0.1:6379"; /// <summary> /// 可读的Redis链接地址 /// format:ip1,ip2 /// </summary> public string ReadServerList = "127.0.0.1:6379"; /// <summary> /// 最大写链接数 /// </summary> public int MaxWritePoolSize = 60; /// <summary> /// 最大读链接数 /// </summary> public int MaxReadPoolSize = 60; /// <summary> /// 本地缓存到期时间,单位:秒 /// </summary> public int LocalCacheTime = 180; /// <summary> /// 自动重启 /// </summary> public bool AutoStart = true; /// <summary> /// 是否记录日志,该设置仅用于排查redis运行时出现的问题, /// 如redis工作正常,请关闭该项 /// </summary> public bool RecordeLog = false; } /// <summary> /// Redis管理中心 /// </summary> public class RedisManager { /// <summary> /// redis配置文件信息 /// </summary> private static RedisConfigInfo RedisConfigInfo = new RedisConfigInfo(); /// <summary> /// Redis客户端池化管理 /// </summary> private static PooledRedisClientManager prcManager; /// <summary> /// 静态构造方法,初始化链接池管理对象 /// </summary> static RedisManager() { CreateManager(); } /// <summary> /// 创建链接池管理对象 /// </summary> private static void CreateManager() { string[] WriteServerConStr = RedisConfigInfo.WriteServerList.Split(','); string[] ReadServerConStr = RedisConfigInfo.ReadServerList.Split(','); prcManager = new PooledRedisClientManager(ReadServerConStr, WriteServerConStr, new RedisClientManagerConfig { MaxWritePoolSize = RedisConfigInfo.MaxWritePoolSize, MaxReadPoolSize = RedisConfigInfo.MaxReadPoolSize, AutoStart = RedisConfigInfo.AutoStart, }); } /// <summary> /// 客户端缓存操作对象 /// </summary> public static IRedisClient GetClient() { return prcManager.GetClient(); } } /// <summary> /// RedisBase类,是redis操作的基类,继承自IDisposable接口,主要用于释放内存 /// </summary> public abstract class RedisBase : IDisposable { public IRedisClient iClient { get; private set; } /// <summary> /// 构造时完成链接的打开 /// </summary> public RedisBase() { iClient = RedisManager.GetClient(); } //public static IRedisClient iClient { get; private set; } //static RedisBase() //{ // iClient = RedisManager.GetClient(); //} private bool _disposed = false; protected virtual void Dispose(bool disposing) { if (!this._disposed) { if (disposing) { iClient.Dispose(); iClient = null; } } this._disposed = true; } public void Dispose() { Dispose(true); GC.SuppressFinalize(this); } public void Transcation() { using (IRedisTransaction irt = this.iClient.CreateTransaction()) { try { irt.QueueCommand(r => r.Set("key", 20)); irt.QueueCommand(r => r.Increment("key", 1)); irt.Commit(); // 提交事务 } catch (Exception ex) { irt.Rollback(); throw ex; } } } /// <summary> /// 清除全部数据 请小心 /// </summary> public virtual void FlushAll() { iClient.FlushAll(); } /// <summary> /// 保存数据DB文件到硬盘 /// </summary> public void Save() { iClient.Save();//阻塞式save } /// <summary> /// 异步保存数据DB文件到硬盘 /// </summary> public void SaveAsync() { iClient.SaveAsync();//异步save } }
Redis中的五大结构
1、String:
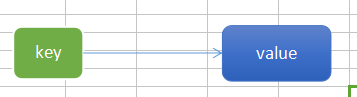
key-value,缓存,支持过期,value不超过512M。Redis单线程的特性,比如SetAll、AppendToValue、GetAndSetValue、IncrementValue、IncrementValueBy,这些命令,看上去是组合命令,实际上是具体的命令,是一个原则性的操作,不用考虑并发,不可能出现中间状态,可以应对一些并发情况。
现在有个场景,就是超卖的问题,超卖,顾名思义,就是订单数超过商品。
数据库:秒杀的时候,10件商品,100个人想买,假定大家一瞬间都来了,A 查询还有没有--有---1更新;C 查询还有没有--有---1更新;可能会卖出12 12甚至20件商品;微服务也有超卖的问题,异步队列。Redis原子性操作--保证一个数值只出现一次--防止一个商品卖给多个人
Redis是单线程的,程序有怎么多线程操作Redis呢?打开多个链接,去提交任务,对程序而言,Redis是并发。所以用上了Redis,一方面保证绝对不会超卖,另一方面没有效率影响,数据库是可以为成功的人并发的,还有撤单的时候增加库存,可以继续秒杀,,限制秒杀的库存是放在redis,不是数据库,不会造成数据的不一致性,Redis能够拦截无效的请求,如果没有这一层,所有的请求压力都到数据库。
超卖的代码示例:
/// <summary> /// key-value 键值对:value可以是序列化的数据 /// </summary> public class RedisStringService : RedisBase { #region 赋值 /// <summary> /// 设置key的value /// </summary> public bool Set<T>(string key, T value) { return base.iClient.Set<T>(key, value); } /// <summary> /// 设置key的value并设置过期时间 /// </summary> public bool Set<T>(string key, T value, DateTime dt) { return base.iClient.Set<T>(key, value, dt); } /// <summary> /// 设置key的value并设置过期时间 /// </summary> public bool Set<T>(string key, T value, TimeSpan sp) { return base.iClient.Set<T>(key, value, sp); } /// <summary> /// 设置多个key/value /// </summary> public void Set(Dictionary<string, string> dic) { base.iClient.SetAll(dic); } #endregion #region 追加 /// <summary> /// 在原有key的value值之后追加value,没有就新增一项 /// </summary> public long Append(string key, string value) { return base.iClient.AppendToValue(key, value); } #endregion #region 获取值 /// <summary> /// 获取key的value值 /// </summary> public string Get(string key) { return base.iClient.GetValue(key); } /// <summary> /// 获取多个key的value值 /// </summary> public List<string> Get(List<string> keys) { return base.iClient.GetValues(keys); } /// <summary> /// 获取多个key的value值 /// </summary> public List<T> Get<T>(List<string> keys) { return base.iClient.GetValues<T>(keys); } #endregion #region 获取旧值赋上新值 /// <summary> /// 获取旧值赋上新值 /// </summary> public string GetAndSetValue(string key, string value) { return base.iClient.GetAndSetValue(key, value); } #endregion #region 辅助方法 /// <summary> /// 获取值的长度 /// </summary> public long GetLength(string key) { return base.iClient.GetStringCount(key); } /// <summary> /// 自增1,返回自增后的值 /// </summary> public long Incr(string key) { return base.iClient.IncrementValue(key); } /// <summary> /// 自增count,返回自增后的值 /// </summary> public long IncrBy(string key, int count) { return base.iClient.IncrementValueBy(key, count); } /// <summary> /// 自减1,返回自减后的值 /// </summary> public long Decr(string key) { return base.iClient.DecrementValue(key); } /// <summary> /// 自减count ,返回自减后的值 /// </summary> /// <param name="key"></param> /// <param name="count"></param> /// <returns></returns> public long DecrBy(string key, int count) { return base.iClient.DecrementValueBy(key, count); } #endregion }
public class OversellTest { private static bool IsGoOn = true;//秒杀活动是否结束 public static void Show() { using (RedisStringService service = new RedisStringService()) { service.Set<int>("Stock", 10);//是库存 } for (int i = 0; i < 5000; i++) { int k = i; Task.Run(() =>//每个线程就是一个用户请求 { using (RedisStringService service = new RedisStringService()) { if (IsGoOn) { long index = service.Decr("Stock");//-1并且返回 if (index >= 0) { Console.WriteLine($"{k.ToString("000")}秒杀成功,秒杀商品索引为{index}"); //可以分队列,去数据库操作 } else { if (IsGoOn) { IsGoOn = false; } Console.WriteLine($"{k.ToString("000")}秒杀失败,秒杀商品索引为{index}"); } } else { Console.WriteLine($"{k.ToString("000")}秒杀停止......"); } } }); } Console.Read(); } } public class OversellField { private static bool IsGoOn = true;//秒杀活动是否结束 private static int Stock = 0; public static void Show() { Stock = 10; for (int i = 0; i < 5000; i++) { int k = i; Task.Run(() =>//每个线程就是一个用户请求 { if (IsGoOn) { long index = Stock;//-1并且返回 去数据库查一下当前的库存 Thread.Sleep(100); if (index >= 1) { Stock = Stock - 1;//更新库存 Console.WriteLine($"{k.ToString("000")}秒杀成功,秒杀商品索引为{index}"); //可以分队列,去数据库操作 } else { if (IsGoOn) { IsGoOn = false; } Console.WriteLine($"{k.ToString("000")}秒杀失败,秒杀商品索引为{index}"); } } else { Console.WriteLine($"{k.ToString("000")}秒杀停止......"); } }); } Console.Read(); } }
2、Hash
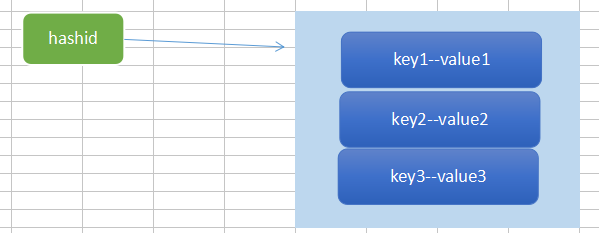
key-dictionary
1、节约空间(zipmap的紧密摆放的存储模式)
2、更新/访问方便(hashid+key)
3、Hash数据结构很想关系型数据库的一张表的一行数据。但是其实字段是可以随意定制的,没有严格约束。
缓存一个用户的信息,用String类型可以吗?也可以,因为String类型,key-value,先序列化,然后再反序列化,然后存储:
using (RedisStringService service = new RedisStringService()) { //service.Set<string>($"userinfo_{user.Id}", Newtonsoft.Json.JsonConvert.SerializeObject(user)); service.Set<UserInfo>($"userinfo_{user.Id}", user); var userCacheList = service.Get<UserInfo>(new List<string>() { $"userinfo_{user.Id}" }); var userCache = userCacheList.FirstOrDefault(); //string sResult = service.Get($"userinfo_{user.Id}"); //var userCache = Newtonsoft.Json.JsonConvert.DeserializeObject<UserInfo>(sResult); userCache.Account = "Admin"; service.Set<UserInfo>($"userinfo_{user.Id}", userCache); }
如果修改需求,就是查询---反序列化---修改---序列化---存储。这样真的太麻烦了。
现在有了Hash类型。
using (RedisHashService service = new RedisHashService()) { service.SetEntryInHash("student", "id", "bingle1"); service.SetEntryInHash("student", "name", "bingle2"); service.SetEntryInHash("student", "remark", "bingle3"); var keys = service.GetHashKeys("student"); var values = service.GetHashValues("student"); var keyValues = service.GetAllEntriesFromHash("student"); Console.WriteLine(service.GetValueFromHash("student", "id")); service.SetEntryInHashIfNotExists("student", "name", "bingle"); service.SetEntryInHashIfNotExists("student", "description", "bingle"); Console.WriteLine(service.GetValueFromHash("student", "name")); Console.WriteLine(service.GetValueFromHash("student", "description")); service.RemoveEntryFromHash("student", "description"); Console.WriteLine(service.GetValueFromHash("student", "description")); }
Hash---》Hashid---UserInfo
多个key,String类型的value,最小是512byte,即使只保存一个1,也要占用512byte的空间。而hash是一种zipmap存储,数据紧密排列,可以节约空间(配置zip两个属性,只要都满足就可以用zipmap存储)。
Hash的有点:
1、节约空间
2、更新方便
如果实体类型是带ID的,可以直接实体存储和读取。
using (RedisHashService service = new RedisHashService()) { service.FlushAll(); //反射遍历做一下 service.SetEntryInHash($"userinfo_{user.Id}", "Account", user.Account); service.SetEntryInHash($"userinfo_{user.Id}", "Name", user.Name); service.SetEntryInHash($"userinfo_{user.Id}", "Address", user.Address); service.SetEntryInHash($"userinfo_{user.Id}", "Email", user.Email); service.SetEntryInHash($"userinfo_{user.Id}", "Password", user.Password); service.SetEntryInHash($"userinfo_{user.Id}", "Account", "Admin"); service.StoreAsHash<UserInfo>(user);//含ID才可以的 var result = service.GetFromHash<UserInfo>(user.Id); }
3、Set
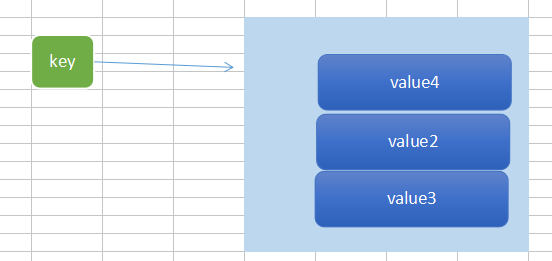
using (RedisSetService service = new RedisSetService()) { service.FlushAll();//清理全部数据 service.Add("advanced", "111"); service.Add("advanced", "112"); service.Add("advanced", "114"); service.Add("advanced", "114"); service.Add("advanced", "115"); service.Add("advanced", "115"); service.Add("advanced", "113"); var result = service.GetAllItemsFromSet("advanced"); var random = service.GetRandomItemFromSet("advanced");//随机获取 service.GetCount("advanced");//独立的ip数 service.RemoveItemFromSet("advanced", "114"); { service.Add("begin", "111"); service.Add("begin", "112"); service.Add("begin", "115"); service.Add("end", "111"); service.Add("end", "114"); service.Add("end", "113"); var result1 = service.GetIntersectFromSets("begin", "end"); var result2 = service.GetDifferencesFromSet("begin", "end"); var result3 = service.GetUnionFromSets("begin", "end"); //共同好友 共同关注 } }
好友管理,共同好友,可能认识
去重:IP统计去重;添加好友申请;投票限制;点赞。
4、ZSet:是一个有序集合,去重
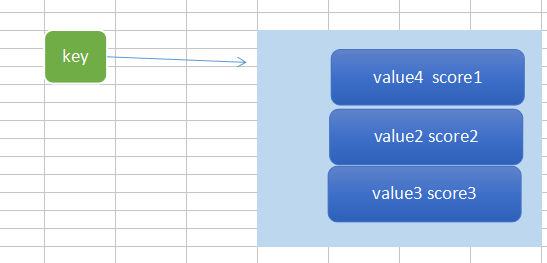
using (RedisZSetService service = new RedisZSetService()) { service.FlushAll();//清理全部数据 service.Add("advanced", "1"); service.Add("advanced", "2"); service.Add("advanced", "5"); service.Add("advanced", "4"); service.Add("advanced", "7"); service.Add("advanced", "5"); service.Add("advanced", "9"); var result1 = service.GetAll("advanced"); var result2 = service.GetAllDesc("advanced"); service.AddItemToSortedSet("Sort", "bingle1", 123234); service.AddItemToSortedSet("Sort", "bingle2", 123); service.AddItemToSortedSet("Sort", "bingle3", 45); service.AddItemToSortedSet("Sort", "bingle4", 7567); service.AddItemToSortedSet("Sort", "bingle5", 9879); service.AddRangeToSortedSet("Sort", new List<string>() { "123", "花生", "加菲猫" }, 3232); var result3 = service.GetAllWithScoresFromSortedSet("Sort"); //交叉并 }

最后一个参数,是自己设定的,设定value的分数的。
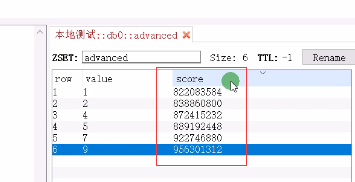
实时排行榜:刷个礼物。
维度很多,平台/房间/主播/日/周/年/月
A对B刷个礼物,影响很多。
没Redis之前,刷个礼物值记录流水,不影响排行,凌晨24点跑任务更新。
实时排行榜,Redis-IncrementItemInSortedSet,刷礼物增加Redis分数,就可以试试获取最新的排行,多个维度就是多个ZSet,刷礼物的时候保存数据库并更新Redis。
5、List
生产者消费者:
using (RedisListService service = new RedisListService()) { service.Add("test", "这是一个学生Add1"); service.Add("test", "这是一个学生Add2"); service.Add("test", "这是一个学生Add3"); service.LPush("test", "这是一个学生LPush1"); service.LPush("test", "这是一个学生LPush2"); service.LPush("test", "这是一个学生LPush3"); service.LPush("test", "这是一个学生LPush4"); service.LPush("test", "这是一个学生LPush5"); service.LPush("test", "这是一个学生LPush6"); service.RPush("test", "这是一个学生RPush1"); service.RPush("test", "这是一个学生RPush2"); service.RPush("test", "这是一个学生RPush3"); service.RPush("test", "这是一个学生RPush4"); service.RPush("test", "这是一个学生RPush5"); service.RPush("test", "这是一个学生RPush6"); List<string> stringList = new List<string>(); for (int i = 0; i < 10; i++) { stringList.Add(string.Format($"放入任务{i}")); } service.Add("task", stringList); Console.WriteLine(service.Count("test")); Console.WriteLine(service.Count("task")); var list = service.Get("test"); list = service.Get("task", 2, 4); Action act = new Action(() => { while (true) { Console.WriteLine("************请输入数据**************"); string testTask = Console.ReadLine(); service.LPush("test", testTask); } }); act.EndInvoke(act.BeginInvoke(null, null)); }
生产者消费者(队列)一个数据,只能被一个对象消费,一个程序写入,一个程序即时读取消费,还可以多个程序读取消费,按照时间顺序,数据失败了还可以放回去下次重试,这种东西在项目中有什么价值呢?和那些MQ差不多,就是队列。
异步队列:
优点:
1、可以控制并发数量
2、以前要求立马处理完,现在可以在一个时段完成
3、失败还能重试
4、流量削峰,降低高峰期的压力
5、高可用
6、可扩展
缺点:
1、不能理解处理
2、事务的一致性问题。
发布订阅,发布一个数据,全部的订阅者都能收到。观察者,一个数据源,多个接受者,只要订阅了就可以收到的,能被多个数据源共享。观察者模式:微信订阅号---群聊天----数据同步
MSMQ---RabbitMQ---ZeroMQ----RocketMQ---RedisList
分布式缓存,多个服务器都可以访问到,多个生产者,多个消费者,任何产品只被消费一次。
using (RedisListService service = new RedisListService()) { service.Add("test", "这是一个学生Add1"); service.Add("test", "这是一个学生Add2"); service.Add("test", "这是一个学生Add3"); service.LPush("test", "这是一个学生LPush1"); service.LPush("test", "这是一个学生LPush2"); service.LPush("test", "这是一个学生LPush3"); service.LPush("test", "这是一个学生LPush4"); service.LPush("test", "这是一个学生LPush5"); service.LPush("test", "这是一个学生LPush6"); service.RPush("test", "这是一个学生RPush1"); service.RPush("test", "这是一个学生RPush2"); service.RPush("test", "这是一个学生RPush3"); service.RPush("test", "这是一个学生RPush4"); service.RPush("test", "这是一个学生RPush5"); service.RPush("test", "这是一个学生RPush6"); List<string> stringList = new List<string>(); for (int i = 0; i < 10; i++) { stringList.Add(string.Format($"放入任务{i}")); } service.Add("task", stringList); Console.WriteLine(service.Count("test")); Console.WriteLine(service.Count("task")); var list = service.Get("test"); list = service.Get("task", 2, 4); //Action act = new Action(() => //{ // while (true) // { // Console.WriteLine("************请输入数据**************"); // string testTask = Console.ReadLine(); // service.LPush("test", testTask); // Console.ReadLine(); // } //}); //act.EndInvoke(act.BeginInvoke(null, null)); while (true) { Console.WriteLine("************请输入数据**************"); string testTask = Console.ReadLine(); service.LPush("test", testTask); } }
public class ServiceStackProcessor { public static void Show() { string path = AppDomain.CurrentDomain.BaseDirectory; string tag = path.Split('/', '\\').Last(s => !string.IsNullOrEmpty(s)); Console.WriteLine($"这里是 {tag} 启动了。。"); using (RedisListService service = new RedisListService()) { Action act = new Action(() => { while (true) { var result = service.BlockingPopItemFromLists(new string[] { "test", "task" }, TimeSpan.FromHours(3)); Thread.Sleep(100); Console.WriteLine($"这里是 {tag} 队列获取的消息 {result.Id} {result.Item}"); } }); act.EndInvoke(act.BeginInvoke(null, null)); } } }
ask项目,问答,一天的问题都是几万,表里面是几千万数据,首页要战士最新的问题,Ajax动态定时获取刷新,还有前20也是很多人访问的。
每次写入数据库的时候,把ID_标题写到RedisList,后面搞个TrimList,只要最近200个,用户刷新页面的时候就不需要去数据库了,直接Redis。
还有一种就是水平分表,第一次的时候不管分页,只拿数据,存数据的时候可以保存id+表全名。
主要解决数据量大,变化的数据分页问题。二八原则,80%的访问集中在20%的数据,List里面只用保存大概的量就够了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架