
Python爬虫实战三之爬取嗅事百科段子
一、前言
俗话说,上班时间是公司的,下班了时间才是自己的。搞点事情,写个爬虫程序,每天定期爬取点段子,看着自己爬的段子,也是一种乐趣。

二、Python爬取嗅事百科段子
1.确定爬取的目标网页
首先我们要明确目标,本次爬取的是糗事百科文字模块的段子。
(糗事百科)->分析目标(策略:url格式(范围)、数据格式、网页编码)->编写代码->执行爬虫
2.分析爬取的目标网页
段子链接:https://www.qiushibaike.com/text/
访问链接可以看到如下的页面,一个红框代表一个段子内容,也就是对应html源码的一个div浮层。页面布局采用分页的方式,每页显示25条,总共13页。点击页码或者"下一页"会跳转到相应页面。Chrome浏览器F12可以看到,每页内容都是同步加载的,而且请求次数较多,显然不能采用直接模拟请求的方式,这里采用的爬取策略是Python Selenium,每获取和解析完一页的段子,点击 "下一页" 跳转到对应页码页继续解析,直至解析并记录所有的段子。
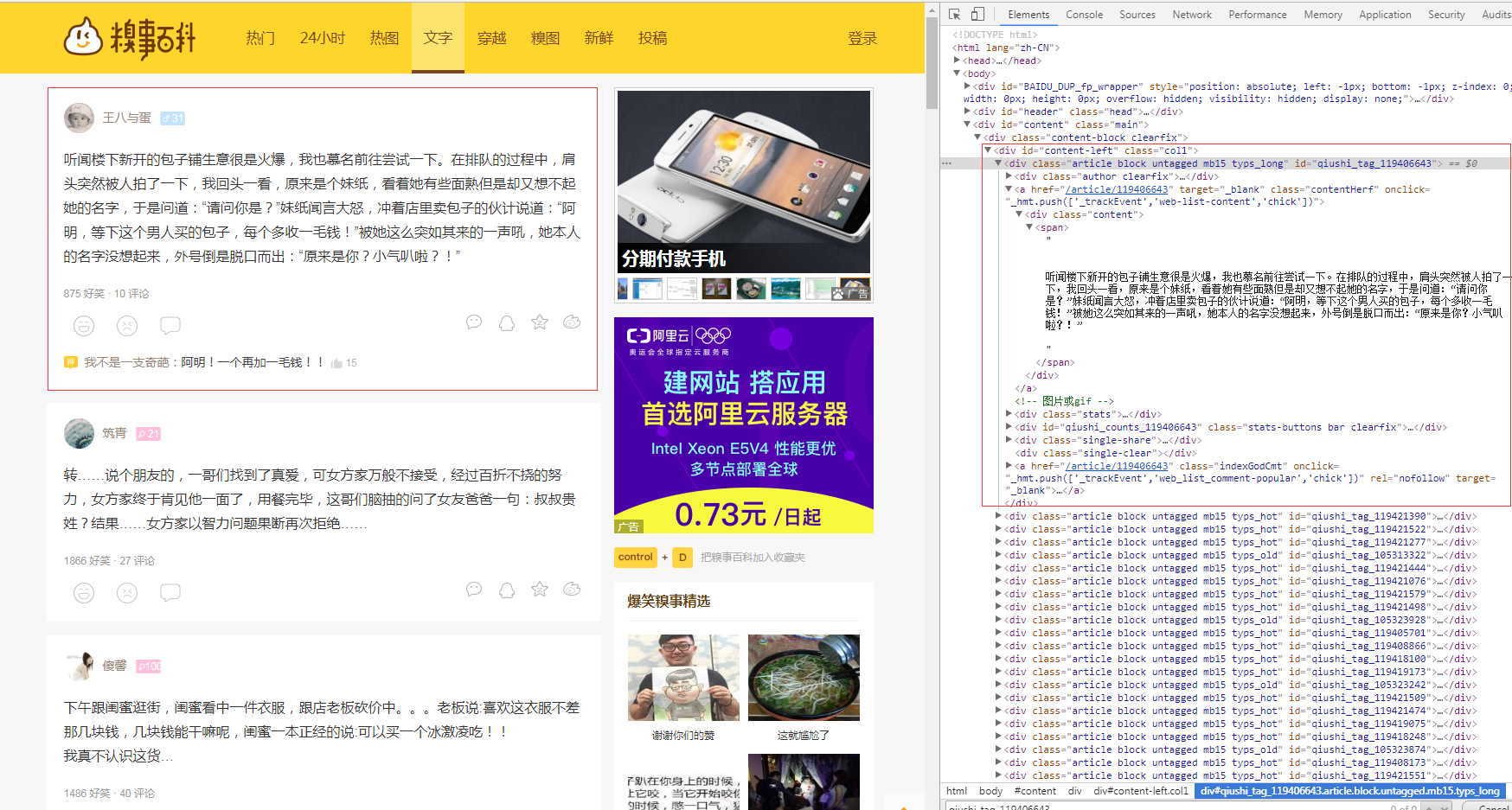
Chrome F12查看Network模块,看到请求密密麻麻的,下载各种document、script js脚本、stylesheet样式,图片jpeg、png等。
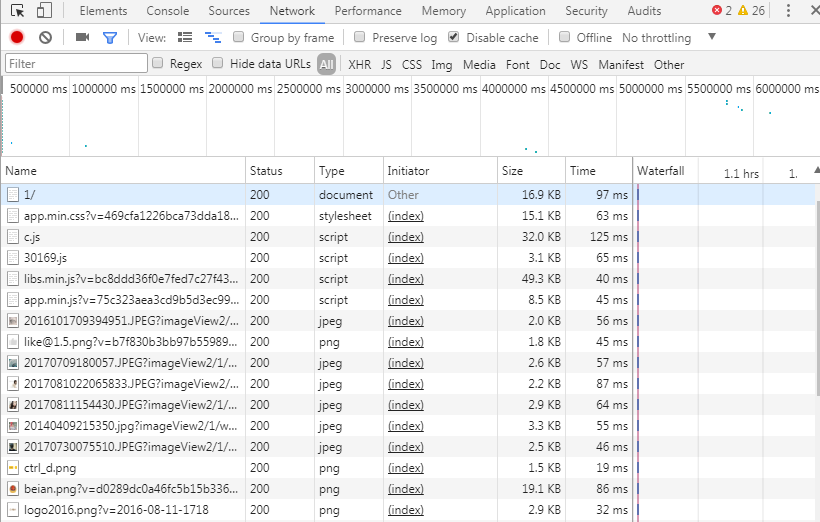
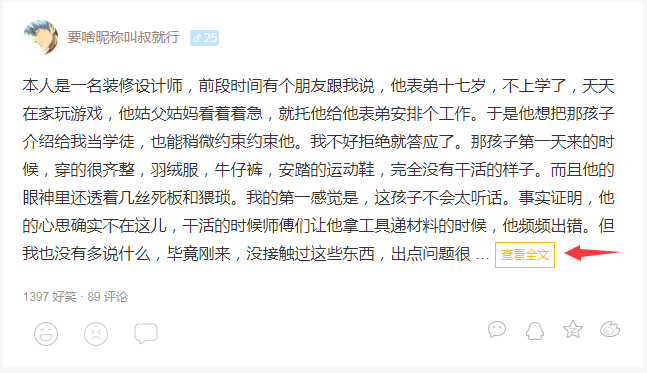
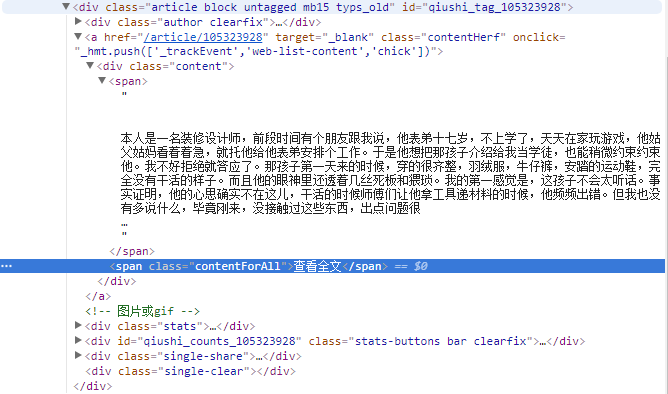
有个情况需要注意,当一个段子内容字数太多,会被截断,出现省略号“...”和"查看全文"的跳转链接,为了获取完整的段子信息,需要增加多一个步骤,请求段子的链接,再截取里面的全部内容。
3.编写代码
下载网页内容,我使用python requests第三方库,发起GET请求方式。


1 def do_get_request(self, url, headers=None, timeout=3, is_return_text=True, num_retries=2): 2 if url is None: 3 return None 4 print('Downloading:', url) 5 if headers is None: # 默认请求头 6 headers = { 7 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'} 8 response = None 9 try: 10 response = requests.get(url, headers=headers, timeout=timeout) 11 12 response.raise_for_status() # a 4XX client error or 5XX server error response,raise requests.exceptions.HTTPError 13 if response.status_code == requests.codes.ok: 14 if is_return_text: 15 html = response.text 16 else: 17 html = response.json() 18 else: 19 html = None 20 except requests.Timeout as err: 21 print('Downloading Timeout:', err.args) 22 html = None 23 except requests.HTTPError as err: 24 print('Downloading HTTP Error,msg:{0}'.format(err.args)) 25 html = None 26 if num_retries > 0: 27 if 500 <= response.status_code < 600: 28 return self.do_get_request(url, headers=headers, num_retries=num_retries - 1) # 服务器错误,导致请求失败,默认重试2次 29 except requests.ConnectionError as err: 30 print('Downloading Connection Error:', err.args) 31 html = None 32 33 return html
解析网页内容,我使用python lxml第三方库和python的re标准库,在解析之前,使用lxml的lxml的Cleaner清理器,把多余的空行、注释,脚本和样式等清楚,再通过re.sub(pattern, string, flags)替换一些标签和字符串<br>和\n空行符,这样才能保证lxml.html.
_Element的text属性能够获取完整的段子内容(如果段子中有<br>,text属性只会取<br>前部分的文字)。cssselect.CSSSelector()通过CSS选择器#content-left获取其下所有的div,再使用e.find()和e.findall()的xpath定位方式分别获取段子的投票数、评论数、
链接地址和内容文本。
1 def duanzi_scrapter(html_doc, page_num=1): 2 html_after_cleaner = cleaner.clean_html(html_doc) 3 # 去除段子内容中的<br> 4 pattern = re.compile('<br>|\n') 5 html_after_cleaner = re.sub(pattern, '', html_after_cleaner) 6 document = etree.fromstring(html_after_cleaner, parser) 7 print('正在解析第%s页段子...' % str(page_num)) 8 try: 9 sel = cssselect.CSSSelector('#content-left > div') 10 for e in sel(document): 11 12 try: 13 # a content 获取段子信息 14 a = e.find('.//a[@class="contentHerf"]') 15 a_href = a.attrib['href'] # 格式/article/105323928 16 spans = e.findall('.//a[@class="contentHerf"]/div/span') 17 if len(spans) > 1: # 出现“查看全文” 18 urls.add_new_url(a_href) # 保存段子链接 19 else: 20 duanzi_info = {} 21 duanzi_info['dz_url'] = 'https://www.qiushibaike.com' + a_href # 段子链接地址 22 duanzi_info['dzContent'] = spans[0].text # 段子内容 23 24 # div stats 25 spans = e.findall('.//div[@class="stats"]/span') 26 for span in spans: 27 i = span.find('.//i') 28 if span.get('class') == 'stats-vote': 29 duanzi_info['vote_num'] = i.text # 投票数 30 elif span.get('class') == 'stats-comments': # 评论数 31 duanzi_info['comment_num'] = i.text 32 collect_data(duanzi_info) 33 34 except Exception as err: 35 print('提取段子异常,进入下一循环') 36 continue 37 print('解析第%s页段子结束' % str(page_num)) 38 next_page(page_num + 1) # 进入下一页 39 except TimeoutException as err: 40 print('解析网页出错:', err.args) 41 return next_page(page_num + 1) # 捕获异常,直接进入下一页
下载并解析因字数过长截断而无法获取完整段子内容的段子链接页面,获取段子的投票数、评论数、链接地址和内容文本。
模拟单击“下一页”按钮,跳转到下一页。
1 def next_page(page_num_input): 2 # print('当前是第%d页' % (page_num_input)) # 首页下标为0,依次累加 3 if page_num_input > 1: # 超出最大页码,直接返回 4 print('超过最大页码,返回') 5 return 6 try: 7 # 定位并单击"下一页",跳转到下一页 8 submit = wait.until( 9 EC.element_to_be_clickable((By.XPATH, '//*[@id="content-left"]/ul/li/a/span[@class="next"]')) 10 ) 11 submit.click() 12 time.sleep(5) # 注意:等待页面加载完成 13 # 定位当前页码 14 # current = wait.until( 15 # EC.presence_of_element_located((By.XPATH, '//*[@id="content-left"]/ul/li/span[@class="current"]')) 16 # ) 17 # print('当前页码是%s' % current.text) # 打印当前页码 18 19 html = browser.page_source 20 duanzi_scrapter(html, page_num_input) # 解析段子 21 except TimeoutException as err: 22 print('翻页出错:', err.args)
保存段子信息到Excel文件
1 from openpyxl import Workbook 2 3 4 class excelManager: 5 def __init__(self, excel_name): 6 self.workBook = Workbook() 7 self.workSheet = self.workBook.create_sheet('duanzi') 8 self.workSheet.append(['投票数', '评论数', '链接地址', '段子内容']) 9 self.excelName = excel_name 10 11 def write_to_excel(self, content): 12 try: 13 for row in content: 14 self.workSheet.append([row['vote_num'], row['comment_num'], row['dz_url'], row['dzContent']]) 15 self.workBook.save(self.excelName) # 保存段子信息到Excel文件 16 except Exception as arr: 17 print('write to excel error', arr.args) 18 19 def close_excel(self): 20 self.workBook.close()
4.执行爬虫
爬虫跑起来了,一页一页地去爬取段子信息,并保存到集合中,最后通过get_duanzi_info()方法获取段子的投票数、评论数,链接地址和内容并保存到Excel文件中。
爬虫程序运行截图:

Excel文件截图:

三、Python爬取嗅事百科段子总结
糗事百科页面加载没有采用ajax的异步方式,选择使用Python Selenium方式是比较合理的。一页一页地往下排,爬完一页再下一页,直至爬完最大的页数。这次页面解析全部采用Python lxml方式,解析性能方面lxml较BeautifulSoup高,可是感觉使用没有像BeautifulSoup简单易用,还有通过xpath定位元素的时候花了很多时间,也暴露出自己对xpath定位方式不太熟悉,后期需要多花点时间。爬取效率方面,这里采用的是单进程的方式,后期版本想采用多线程的方式,在加快爬取效率的同时,会多学习些网站防爬虫的知识,包括浏览器代理,HTTP请求头,同一域名访问时间间隔等。
四、后语
最后要庆祝下,毕竟成功把糗事百科的段子爬取下来了。本次能够成功爬取段子,Selenium PhantomJS,lxml和requests功不可没,通过本次实战,我对lxml的html元素定位和lxml API有更加深入的理解,后续会更加深入学习。期待下次实战。

