
爬虫实战-微博评论爬取
简介
最近在做NLP方面的研究,以前一直在做CV方面。最近由于chatgpt,所以对NLP就非常感兴趣。索性就开始研究起来了。
其实我们都知道,无论是CV方向还是NLP方向的模型实现,都是离不开数据的。哪怕是再先进的代码,都是需要数据支撑的。但是我们的数据都来自哪里呢。无非就两个方面,一方面是来自于公开的数据集,或者就是个人收集。那么个人收集数据的方法,最常用的页就是爬虫了。通过爬虫采集数据是非常非常方便的。那么接下来我就来介绍一下如何使用爬虫来采集微博上的评论数据。
下面是我采集的数据,具体如下:
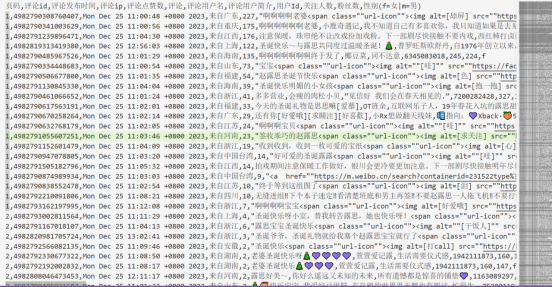
可以看到基本上就是两类,一类是关于评论数据方面的,这里包括评论id,评论的时间,评论的ip地址,另外一类就是发布评论的作者信息,这里包括了评论者的username,个人简介,粉丝数量、关注的人,以及性别等等。
代码使用
那么我们应该怎么使用这个代码呢:
我们主要分为两步,一步是修改代码中的cookie的值,另外一方面就是找到你需要爬取的微博的id,然后运行代码就可以了。
代码中的cookie位置如下,我们在此处就可以进行修改了
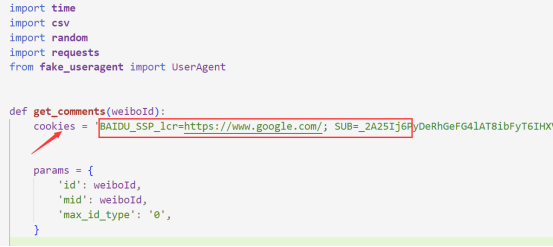
那么我们应该怎么找到自己的cookie信息呢。
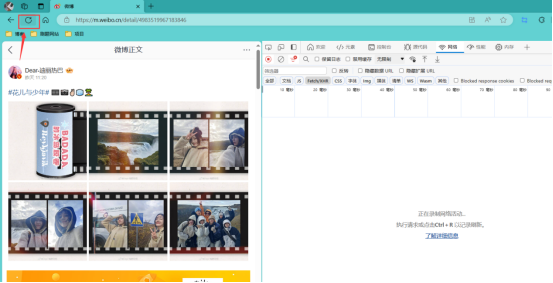
我们首先打开浏览器,然后输入微博,然后进入微博页面,随便点一个微博就可以了,此时我们按F12,如下所示
接下来的话,我们刷新页面即可,此时有一大波数据来袭
然后我们如下所示,点击一个文件,然后就可以看到cookie值了。具体如下所示:
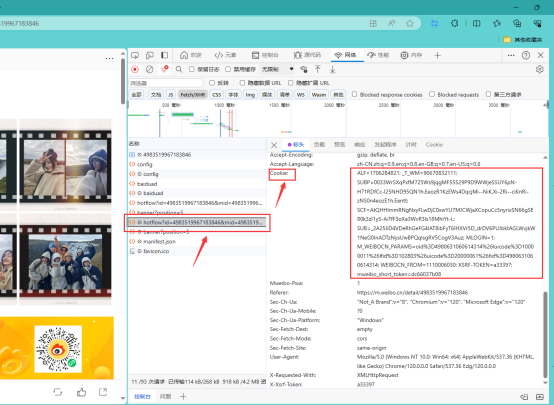
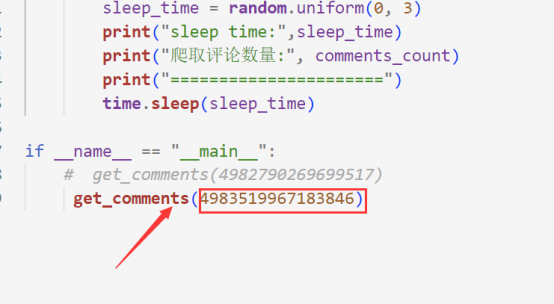
另外一步就是,获取到对应微博的id,获取方式如下所示。我们复制就可以了

然后粘贴到代码中就就可以了
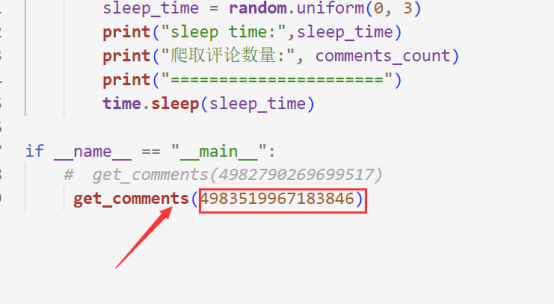
上述步骤都完成以后,我们就可以运行了。
具体的操作,请看如下视频:
【爬虫实战】- 爬取微博评论


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用