
Tensorflow2.0实战之Auto-Encoder
autoencoder可以用于数据压缩、降维,预训练神经网络,生成数据等等
Auto-Encoder架构
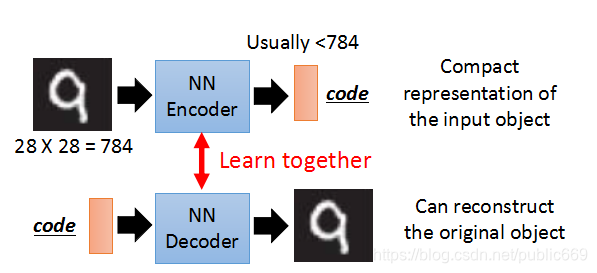
需要完成的工作
需要完成Encoder和Decoder的训练
例如,Mnist的一张图片大小为784维,将图片放到Encoder中进行压缩,编码code使得维度小于784维度,之后可以将code放进Decoder中进行重建,可以产生同之前相似的图片。
Encoder和Decoder需要一起进行训练。
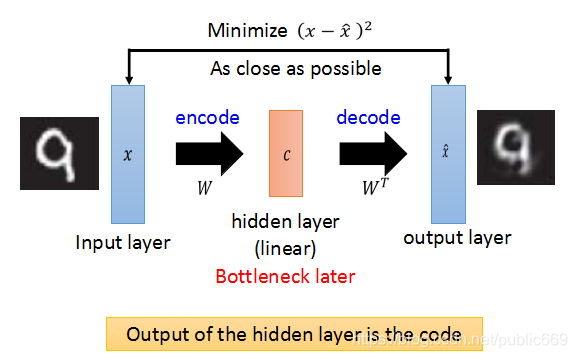
输入同样是一张图片,通过选择W,找到数据的主特征向量,压缩图片得到code,然后使用W的转置,恢复图片。
我们知道,PCA对数据的降维是线性的(linear),恢复数据会有一定程度的失真。上面通过PCA恢复的图片也是比较模糊的。
所以,我们也可以把PCA理解成为一个线性的autoencoder,W就是encode的作用,w的转置就是decode的作用,最后的目的是decode的结果和原始图片越接近越好。
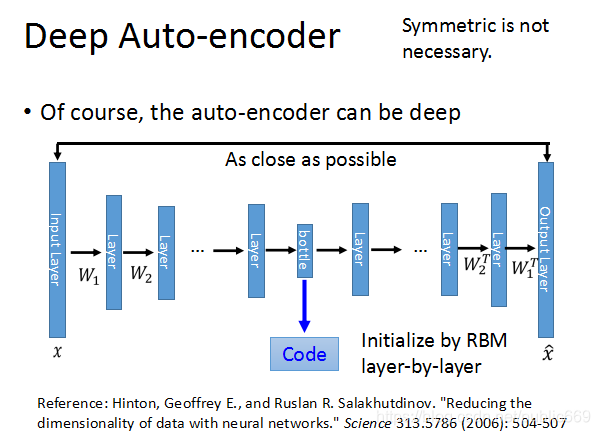
现在来看真正意义上的Deep Auto-encoder的结构。通常encoder每层对应的W和decoder每层对应的W不需要对称(转置)
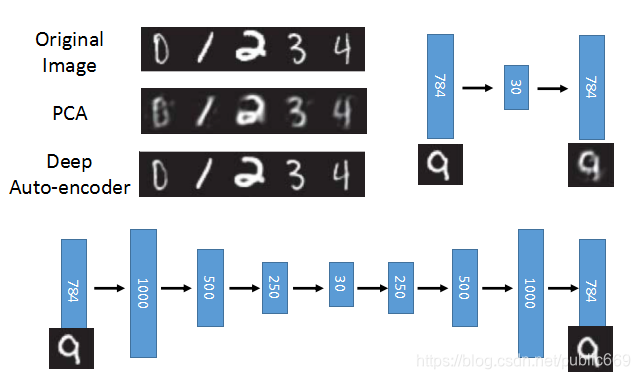
从上面可以看出,Auto-encoder产生的图片,比PCA还原的图片更加接近真实图片。
接下来我们就来实现这样的一个Auto-Encoder
实现
导入必要的第三方库,以及前期的处理
import os
import numpy as np
from PIL import Image
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import Sequential,layers
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
assert tf.__version__.startswith('2.')
定义一个保存图片的方法,以便于将我们新生成的图片保存起来,为我们后面我们查看图片的效果带来持久化的数据
def save_images(imgs,name):
new_im=Image.new('L',(280,280))
index=0
for i in range(0,280,28):
for j in range(0,280,28):
im=imgs[index]
im=Image.fromarray(im,mode='L')
new_im.paste(im,(i,j))
index+=1
new_im.save(name)
这部分为数据集的加载和图片重建的预处理过程;我们这里将高的维度降为20,这个参数可以随意,读者也可以将其降为10也是可以的。同时这里我们不再使用label了
h_dim=20
batchsz=512
lr=1e-3
(x_train,y_train),(x_test,y_test)=keras.datasets.fashion_mnist.load_data()
x_train,x_test=x_train.astype(np.float32)/255.,x_test.astype(np.float32)/255.
train_data=tf.data.Dataset.from_tensor_slices(x_train)
train_data=train_data.shuffle(batchsz*5).batch(batchsz)
test_data=tf.data.Dataset.from_tensor_slices(x_test)
test_data=test_data.batch(batchsz)
接下来我们创建模型
这里我们使用keras的接口,再建立模型的时,我们需要继承Keras下的Model
我们先将网络结构搭建出来,这里有两个部分,一个是init的初始化方法;另一个是call前向传播的方法
class AE(keras.Model):
def __init__(self):
super(AE, self).__init__()
pass
def call(self,inputs,training=None):
pass
编写好上述后,我们完成init和call中的方法。
首先编写Encoder,这里Encoder将编辑为高维度、抽象的向量
self.encoder=Sequential([
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(128,activation=tf.nn.relu),
layers.Dense(h_dim)
])
我们再编写Decoders的方法,可以看到同Encoder是相反的过程
self.decoder=Sequential([
layers.Dense(128,activation=tf.nn.relu),
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(784)
])
完成了init的方法后,我们再来写call中的方法了,
首先使用encoder将输入的高维度图片置为低维的,然后再使用decoder还原,
笔者这里由于上述设置的h_dim为10,同时使用的是FashionMNIST数据集(维度是784),所以encoder将[b,784]-->[b,10],
decoder将[b,10]-->[b,784]
def call(self, inputs, training=None):
# encoder-->decoder [b,784]-->[b,10]
h=self.encoder(inputs)
# [b,10]-->[b,784]
x_hat=self.decoder(h)
return x_hat
接下来我们可以建立model,再看看model是怎样的
model=AE()
model.build(input_shape=(None,784))
model.summary()
Model: "ae"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) multiple 236436
_________________________________________________________________
sequential_1 (Sequential) multiple 237200
=================================================================
Total params: 473,636
Trainable params: 473,636
Non-trainable params: 0
_________________________________________________________________
定义优化器
这里我们就使用Adam优化器,读者也可以使用SGD,这个无所谓。、
optimizer=tf.optimizers.Adam(lr=lr)
训练
for epoch in range(200):
for step,x in enumerate(train_data):
x=tf.reshape(x,[-1,784])
with tf.GradientTape() as tape:
x_rec_logits =model(x)
rec_loss =tf.losses.binary_crossentropy(x,x_rec_logits,from_logits=True)
rec_loss =tf.reduce_mean(rec_loss)
grads=tape.gradient(rec_loss,model.trainable_variables)
optimizer.apply_gradients(zip(grads,model.trainable_variables))
if step%100==0:
print(epoch,step,float(rec_loss))
验证
这里需要注意一下,image是一个文件夹,再训练前,我们需要在代码所在路径下手动添加
x=next(iter(test_data))
logits=model(tf.reshape(x,[-1,784])) # trans [0,1]
x_hat=tf.sigmoid(logits)
x_hat=tf.reshape(x_hat,[-1,28,28])
x_concat=tf.concat([x,x_hat],axis=0)
x_concat=x_concat.numpy()*255
x_concat=x_concat.astype(np.uint8)
save_images(x_concat,'image/epoch_%d.png'%epoch)
结果展示:






建议大家动手实践实践,共同进步。
笔者水平有限,如有表述不准确的地方还请谅解,有错误的地方欢迎大家批评指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号