
Tensorflow2.0使用Resnet18进行数据训练
在今年的3月7号,谷歌在 Tensorflow Developer Summit 2019 大会上发布 TensorFlow 2.0 Alpha
版,随后又发布了Beta版本。
Resnet18结构
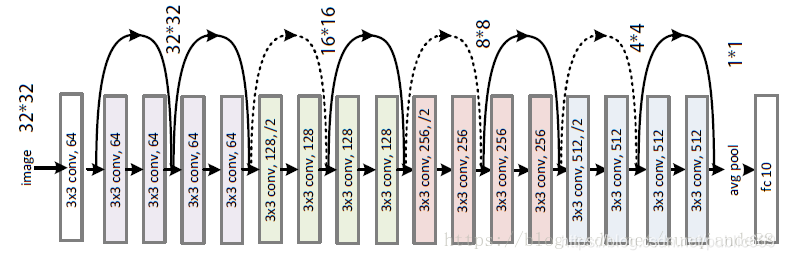
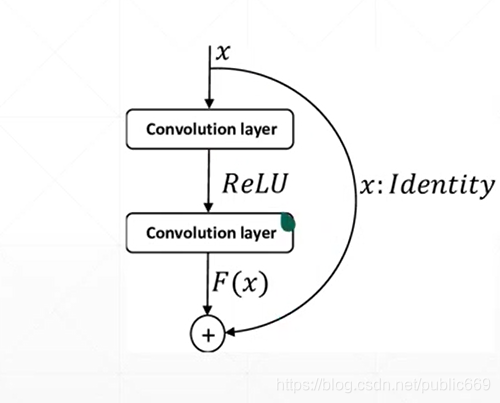
Tensorflow搭建Resnet18
导入第三方库
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,Sequential
搭建BasicBlock
class BasicBlock(layers.Layer):
def __init__(self,filter_num,stride=1):
super(BasicBlock, self).__init__()
self.conv1=layers.Conv2D(filter_num,(3,3),strides=stride,padding='same')
self.bn1=layers.BatchNormalization()
self.relu=layers.Activation('relu')
self.conv2=layers.Conv2D(filter_num,(3,3),strides=1,padding='same')
self.bn2 = layers.BatchNormalization()
if stride!=1:
self.downsample=Sequential()
self.downsample.add(layers.Conv2D(filter_num,(1,1),strides=stride))
else:
self.downsample=lambda x:x
def call(self,input,training=None):
out=self.conv1(input)
out=self.bn1(out)
out=self.relu(out)
out=self.conv2(out)
out=self.bn2(out)
identity=self.downsample(input)
output=layers.add([out,identity])
output=tf.nn.relu(output)
return output
搭建ResNet
class ResNet(keras.Model):
def __init__(self,layer_dims,num_classes=10):
super(ResNet, self).__init__()
# 预处理层
self.stem=Sequential([
layers.Conv2D(64,(3,3),strides=(1,1)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPool2D(pool_size=(2,2),strides=(1,1),padding='same')
])
# resblock
self.layer1=self.build_resblock(64,layer_dims[0])
self.layer2 = self.build_resblock(128, layer_dims[1],stride=2)
self.layer3 = self.build_resblock(256, layer_dims[2], stride=2)
self.layer4 = self.build_resblock(512, layer_dims[3], stride=2)
# there are [b,512,h,w]
# 自适应
self.avgpool=layers.GlobalAveragePooling2D()
self.fc=layers.Dense(num_classes)
def call(self,input,training=None):
x=self.stem(input)
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
x=self.layer4(x)
# [b,c]
x=self.avgpool(x)
x=self.fc(x)
return x
def build_resblock(self,filter_num,blocks,stride=1):
res_blocks= Sequential()
# may down sample
res_blocks.add(BasicBlock(filter_num,stride))
# just down sample one time
for pre in range(1,blocks):
res_blocks.add(BasicBlock(filter_num,stride=1))
return res_blocks
def resnet18():
return ResNet([2,2,2,2])
训练数据
为了数据获取方便,这里使用的是CIFAR10的数据,可以在代码中直接使用keras.datasets.cifar10.load_data()方法获取,非常的方便
训练代码如下:
import os
import tensorflow as tf
from Resnet import resnet18
from tensorflow.keras import datasets,layers,optimizers,Sequential,metrics
os.environ["TF_CPP_MIN_LOG_LEVEL"]='2'
tf.random.set_seed(2345)
def preprocess(x,y):
x=2*tf.cast(x,dtype=tf.float32)/255.-1
y=tf.cast(y,dtype=tf.int32)
return x,y
(x_train,y_train),(x_test,y_test)=datasets.cifar10.load_data()
y_train=tf.squeeze(y_train,axis=1)
y_test=tf.squeeze(y_test,axis=1)
# print(x_train.shape,y_train.shape,x_test.shape,y_test.shape)
train_data=tf.data.Dataset.from_tensor_slices((x_train,y_train))
train_data=train_data.shuffle(1000).map(preprocess).batch(64)
test_data=tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_data=test_data.map(preprocess).batch(64)
sample=next(iter(train_data))
print('sample:',sample[0].shape,sample[1].shape,
tf.reduce_min(sample[0]),tf.reduce_max(sample[0]))
def main():
model=resnet18()
model.build(input_shape=(None,32,32,3))
model.summary()
optimizer=optimizers.Adam(lr=1e-3)
for epoch in range(50):
for step,(x,y) in enumerate(train_data):
with tf.GradientTape() as tape:
logits=model(x)
y_onehot=tf.one_hot(y,depth=10)
loss=tf.losses.categorical_crossentropy(y_onehot,logits,from_logits=True)
loss=tf.reduce_mean(loss)
grads=tape.gradient(loss,model.trainable_variables)
optimizer.apply_gradients(zip(grads,model.trainable_variables))
if step%100==0:
print(epoch,step,'loss',float(loss))
total_num=0
total_correct=0
for x,y in test_data:
logits=model(x)
prob=tf.nn.softmax(logits,axis=1)
pred=tf.argmax(prob,axis=1)
pred=tf.cast(pred,dtype=tf.int32)
correct=tf.cast(tf.equal(pred,y),dtype=tf.int32)
correct=tf.reduce_sum(correct)
total_num+=x.shape[0]
total_correct+=int(correct)
acc=total_correct/total_num
print(epoch,'acc:',acc)
if __name__ == '__main__':
main()
训练数据
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential (Sequential) multiple 2048
_________________________________________________________________
sequential_1 (Sequential) multiple 148736
_________________________________________________________________
sequential_2 (Sequential) multiple 526976
_________________________________________________________________
sequential_4 (Sequential) multiple 2102528
_________________________________________________________________
sequential_6 (Sequential) multiple 8399360
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 5130
=================================================================
Total params: 11,184,778
Trainable params: 11,176,970
Non-trainable params: 7,808
_________________________________________________________________
0 0 loss 2.2936558723449707
0 100 loss 1.855604887008667
0 200 loss 1.9335857629776
0 300 loss 1.508711576461792
0 400 loss 1.5679863691329956
0 500 loss 1.5649926662445068
0 600 loss 1.147849202156067
0 700 loss 1.3818628787994385
0 acc: 0.5424
1 0 loss 1.3022596836090088
1 100 loss 1.4624202251434326
1 200 loss 1.3188159465789795
1 300 loss 1.1521495580673218
1 400 loss 0.9550357460975647
1 500 loss 1.2304189205169678
1 600 loss 0.7009983062744141
1 700 loss 0.8488335609436035
1 acc: 0.644
2 0 loss 0.9625152945518494
2 100 loss 1.174363374710083
2 200 loss 1.1750390529632568
2 300 loss 0.7221378087997437
2 400 loss 0.7162064909934998
2 500 loss 0.926654040813446
2 600 loss 0.6159981489181519
2 700 loss 0.6437114477157593
2 acc: 0.6905
3 0 loss 0.7495195865631104
3 100 loss 0.9840961694717407
3 200 loss 0.9429250955581665
3 300 loss 0.5575872659683228
3 400 loss 0.5735365152359009
3 500 loss 0.7843905687332153
3 600 loss 0.6125107407569885
3 700 loss 0.6241222620010376
3 acc: 0.6933
4 0 loss 0.7694090604782104
4 100 loss 0.5488263368606567
4 200 loss 0.9142876863479614
4 300 loss 0.4908181428909302
4 400 loss 0.5889899730682373
4 500 loss 0.7341771125793457
4 600 loss 0.4880038797855377
4 700 loss 0.5088012218475342
4 acc: 0.7241
5 0 loss 0.5378311276435852
5 100 loss 0.5630106925964355
5 200 loss 0.8578733205795288
5 300 loss 0.3617972433567047
5 400 loss 0.29359108209609985
5 500 loss 0.5915042757987976
5 600 loss 0.3684327006340027
5 700 loss 0.40654802322387695
5 acc: 0.7005
6 0 loss 0.5005596280097961
6 100 loss 0.40528279542922974
6 200 loss 0.4127967953681946
6 300 loss 0.4062516987323761
6 400 loss 0.40751856565475464
6 500 loss 0.45849910378456116
6 600 loss 0.4571283459663391
6 700 loss 0.32558882236480713
6 acc: 0.7119
可以看到使用ResNet18网络结构,参数量是非常大的,有 11,184,778,所以训练起来的话,很耗时间,这里笔者没有训练完,有兴趣的同学,可以训练一下

