BUAA-面向对象设计与构造-第一单元总结
作者:杨恩源 20373559
第一次作业
UML类图
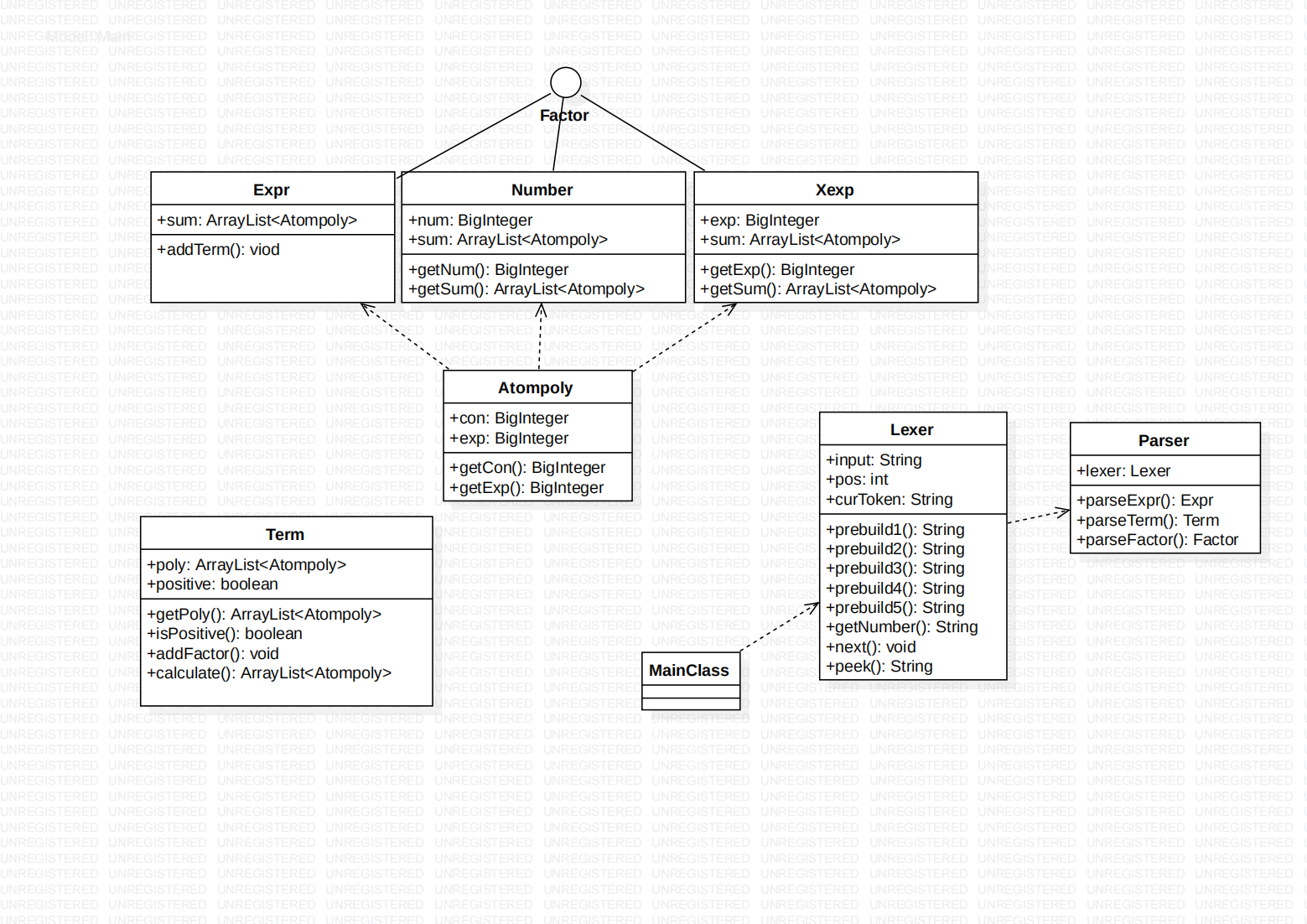
采取递归下降法架构,Atompoly类用于描述多项式的单项,便于最后加和输出;因子采用Factor接口表示,解析后相乘为Term类,再进行加减运算即为表达式(Expr类)。
复杂度分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getNumber() | 2 | 1 | 3 | 3 |
| Lexer.next() | 3 | 2 | 3 | 4 |
| Lexer.peek() | 0 | 1 | 1 | 1 |
| Lexer.prebuild1(String) | 3 | 1 | 3 | 3 |
| Lexer.prebuild2(String) | 22 | 1 | 9 | 11 |
| Lexer.prebuild3(String) | 15 | 1 | 15 | 15 |
| Lexer.prebuild4(String) | 7 | 1 | 6 | 6 |
| Lexer.prebuild5(String) | 5 | 1 | 4 | 4 |
| MainClass.main(String[]) | 78 | 1 | 36 | 36 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.parseExpr() | 8 | 1 | 6 | 6 |
| Parser.parseFactor() | 7 | 3 | 5 | 5 |
| Parser.parseTerm(boolean) | 1 | 1 | 2 | 2 |
| expr.Atompoly.Atompoly(BigInteger, BigInteger) | 0 | 1 | 1 | 1 |
| expr.Atompoly.getCon() | 0 | 1 | 1 | 1 |
| expr.Atompoly.getExp() | 0 | 1 | 1 | 1 |
| expr.Atompoly.setCon(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Atompoly.setExp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Expr.Expr() | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Term) | 4 | 1 | 3 | 3 |
| expr.Expr.getSum() | 0 | 1 | 1 | 1 |
| expr.Number.Number(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Number.getNum() | 0 | 1 | 1 | 1 |
| expr.Number.getSum() | 0 | 1 | 1 | 1 |
| expr.Poly.Poly() | 0 | 1 | 1 | 1 |
| expr.Term.Term(boolean) | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Factor) | 6 | 1 | 5 | 5 |
| expr.Term.calculate(Factor) | 12 | 1 | 8 | 8 |
| expr.Term.getPoly() | 0 | 1 | 1 | 1 |
| expr.Term.isPositive() | 0 | 1 | 1 | 1 |
| expr.Xexp.Xexp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Xexp.getExp() | 0 | 1 | 1 | 1 |
| expr.Xexp.getSum() | 0 | 1 | 1 | 1 |
设计架构
模仿了第一次上机练习中递归下降的思路,先对字符串进行预处理,化简为标准形式,再进行解析处理,在MainClass类中输出。
优点
确定了较为完备的递归下降思路, 避免了后续迭代进行重构的问题;利用arraylist结构存储,最后统一加和输出,有利于对长度进行优化。
缺点
由于第一次作业完成的较为仓促,未能在优化、未来迭代方面全盘考虑,导致架构有些混乱、对规范因子理解不到位、预处理过于繁杂等问题。优化方面没有全面考虑表达式符号问题,导致强测未能满分。
互测体验
第一次互测之前,在强测中拿到了不错的成绩,因此互测中其他同学未能hack我的代码,同时我也没有hack到其他同学。这里体现了对其他同学代码研究不够深刻的问题。
第二次作业
UML类图
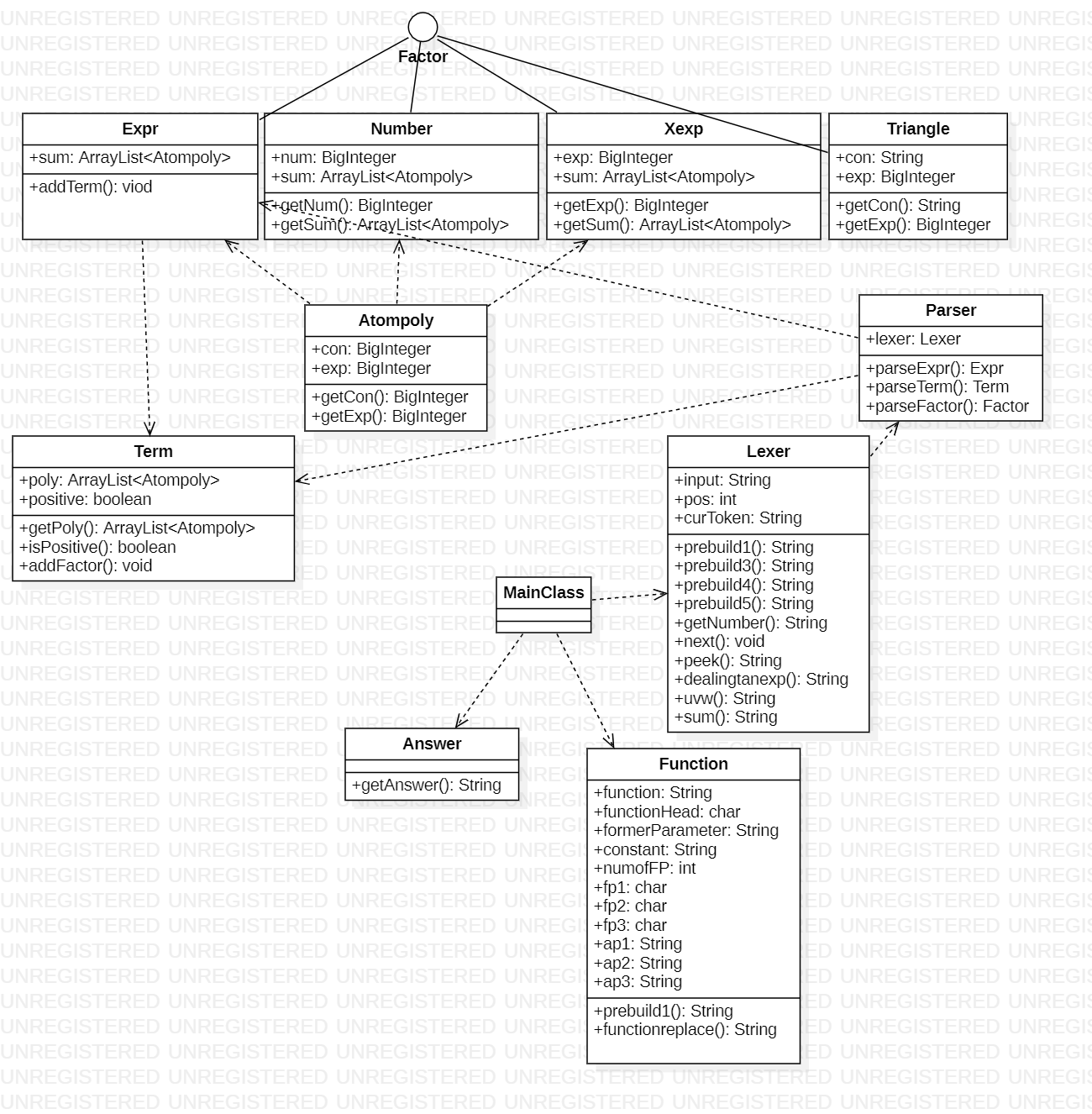
复杂度分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Answer.getAnswer(HashMap<HashMap<String, BigInteger>, BigInteger>) | 112 | 1 | 25 | 26 |
| Function.Function(String) | 3 | 1 | 4 | 4 |
| Function.functionreplace(String) | 109 | 7 | 40 | 42 |
| Function.prebuild1(String) | 3 | 1 | 3 | 3 |
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.dealingtanexp(String) | 22 | 7 | 8 | 10 |
| Lexer.getNumber() | 2 | 1 | 3 | 3 |
| Lexer.getTriangle() | 6 | 1 | 3 | 5 |
| Lexer.next() | 4 | 2 | 4 | 5 |
| Lexer.peek() | 0 | 1 | 1 | 1 |
| Lexer.prebuild1(String) | 3 | 1 | 3 | 3 |
| Lexer.prebuild2(String) | 31 | 1 | 16 | 18 |
| Lexer.prebuild3(String) | 15 | 1 | 15 | 15 |
| Lexer.prebuild4(String) | 7 | 1 | 6 | 6 |
| Lexer.prebuild5(String) | 5 | 1 | 4 | 4 |
| Lexer.prebuild6(String) | 7 | 1 | 7 | 7 |
| Lexer.prebuild7(String) | 5 | 1 | 4 | 4 |
| Lexer.sum(String) | 58 | 7 | 13 | 15 |
| Lexer.uvw(String) | 9 | 1 | 8 | 8 |
| MainClass.main(String[]) | 6 | 1 | 7 | 7 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.parseExpr() | 8 | 1 | 6 | 6 |
| Parser.parseFactor() | 9 | 4 | 7 | 7 |
| Parser.parseTerm(boolean) | 1 | 1 | 2 | 2 |
| expr.Atompoly.Atompoly(BigInteger, BigInteger) | 0 | 1 | 1 | 1 |
| expr.Atompoly.getCon() | 0 | 1 | 1 | 1 |
| expr.Atompoly.getExp() | 0 | 1 | 1 | 1 |
| expr.Atompoly.setCon(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Atompoly.setExp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Expr.Expr() | 0 | 1 | 1 | 1 |
| expr.Expr.Expr(HashMap<HashMap<String, BigInteger>, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Term) | 26 | 1 | 10 | 10 |
| expr.Expr.getExp() | 0 | 1 | 1 | 1 |
| expr.Expr.getPoly() | 0 | 1 | 1 | 1 |
| expr.Expr.setExp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Number.Number(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Number.getNum() | 0 | 1 | 1 | 1 |
| expr.Poly.Poly() | 0 | 1 | 1 | 1 |
| expr.Term.Term(boolean) | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Factor) | 120 | 1 | 30 | 30 |
| expr.Term.getPoly() | 0 | 1 | 1 | 1 |
| expr.Term.isPositive() | 0 | 1 | 1 | 1 |
| expr.Triangle.Triangle(String, BigInteger) | 0 | 1 | 1 | 1 |
| expr.Triangle.getCon() | 0 | 1 | 1 | 1 |
| expr.Triangle.getExp() | 0 | 1 | 1 | 1 |
| expr.Xexp.Xexp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Xexp.getExp() | 0 | 1 | 1 | 1 |
设计架构
相比第一次作业,进行了部分重构和较大的架构优化;多项式改用hashmap进行存储,达到了即时求和的效果;将新增的三角函数纳入factor接口,作为因子之一参与运算。
优点
-
将输出分离开,单独作为一个类使用,减少了代码风格上的不妥和架构上的混乱
-
优化了atomploy的存储和运算,架构更加清晰
-
完成了括号嵌套功能,降低了下一次迭代的工作量
缺点
-
未能将sum和自定义纳入运算中,而是先预处理代入,不仅过于繁杂,不符合高内聚低耦合原则,还导致了hack阶段出锅和下一次迭代的重构的麻烦
互测体验
bug分析
-
由于代码中Term结构乘法模块中指数相加部分写错,导致强测出现WA,互测也被他人hack,应注意检查代码逻辑,多做测试。
-
修复仅需变动一行代码的位置,侧面印证了此bug产生的不应该
-
-
当三角函数指数为0时,输出会出错,主要是Answer类输出优化逻辑出错,未做好充分测试的结果,修改对应函数if函数条件后成功修复。
hack体验
这次互测利用三角函数指数的特殊情况成功hack他人,以后做测试时应多考虑边界条件和极端情况。
第三次作业
UML类图

复杂度分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| MainClass.deletespace(String) | 3 | 1 | 3 | 3 |
| MainClass.main(String[]) | 1 | 1 | 2 | 2 |
| expr.Atompoly.Atompoly(BigInteger, BigInteger) | 0 | 1 | 1 | 1 |
| expr.Atompoly.getCon() | 0 | 1 | 1 | 1 |
| expr.Atompoly.getExp() | 0 | 1 | 1 | 1 |
| expr.Atompoly.setCon(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Atompoly.setExp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Expr.Expr() | 0 | 1 | 1 | 1 |
| expr.Expr.Expr(HashMap<HashMap<String, BigInteger>, BigInteger>) | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Term) | 26 | 1 | 10 | 10 |
| expr.Expr.getExp() | 0 | 1 | 1 | 1 |
| expr.Expr.getPoly() | 0 | 1 | 1 | 1 |
| expr.Expr.setExp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Expr.toString() | 112 | 1 | 25 | 26 |
| expr.Function.Function(String) | 3 | 1 | 4 | 4 |
| expr.Function.addAps(int, Expr) | 2 | 1 | 2 | 2 |
| expr.Function.calculation() | 24 | 1 | 17 | 17 |
| expr.Function.getFunctionHead() | 0 | 1 | 1 | 1 |
| expr.Function.getNumofFP() | 0 | 1 | 1 | 1 |
| expr.Number.Number(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Number.getNum() | 0 | 1 | 1 | 1 |
| expr.Poly.Poly() | 0 | 1 | 1 | 1 |
| expr.Sum.Sum(BigInteger, BigInteger, String) | 4 | 1 | 4 | 4 |
| expr.Sum.getExpr() | 0 | 1 | 1 | 1 |
| expr.Term.Term(boolean) | 0 | 1 | 1 | 1 |
| expr.Term.addEmptyFactor(Factor) | 40 | 1 | 13 | 13 |
| expr.Term.addFactor(Factor) | 71 | 1 | 18 | 18 |
| expr.Term.getPoly() | 0 | 1 | 1 | 1 |
| expr.Term.isPositive() | 0 | 1 | 1 | 1 |
| expr.Triangle.Triangle(char, Expr, BigInteger) | 3 | 1 | 3 | 3 |
| expr.Triangle.getCon() | 0 | 1 | 1 | 1 |
| expr.Triangle.getExp() | 0 | 1 | 1 | 1 |
| expr.Triangle.isNum(String) | 1 | 1 | 1 | 2 |
| expr.Xexp.Xexp(BigInteger) | 0 | 1 | 1 | 1 |
| expr.Xexp.getExp() | 0 | 1 | 1 | 1 |
| main.Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| main.Lexer.dealingtanexp(String) | 22 | 7 | 8 | 10 |
| main.Lexer.getNumber() | 2 | 1 | 3 | 3 |
| main.Lexer.getPos() | 0 | 1 | 1 | 1 |
| main.Lexer.next() | 5 | 2 | 6 | 7 |
| main.Lexer.nextexpr() | 7 | 5 | 3 | 5 |
| main.Lexer.peek() | 0 | 1 | 1 | 1 |
| main.Lexer.prebuild1(String) | 3 | 1 | 3 | 3 |
| main.Lexer.prebuild2(String) | 31 | 1 | 16 | 18 |
| main.Lexer.prebuild3(String) | 15 | 1 | 15 | 15 |
| main.Lexer.prebuild4(String) | 7 | 1 | 6 | 6 |
| main.Lexer.prebuild5(String) | 5 | 1 | 4 | 4 |
| main.Lexer.prebuild6(String) | 7 | 1 | 7 | 7 |
| main.Lexer.prebuild7(String) | 5 | 1 | 4 | 4 |
| main.Lexer.sum(String) | 58 | 7 | 13 | 15 |
| main.Lexer.uvw(String) | 9 | 1 | 8 | 8 |
| main.Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| main.Parser.getFunctions() | 0 | 1 | 1 | 1 |
| main.Parser.parseExpr() | 8 | 1 | 6 | 6 |
| main.Parser.parseFactor() | 33 | 8 | 17 | 17 |
| main.Parser.parseFactorExpr() | 4 | 1 | 4 | 4 |
| main.Parser.parseFactorSum() | 6 | 1 | 5 | 5 |
| main.Parser.parseFactorTriangle() | 4 | 1 | 4 | 4 |
| main.Parser.parseFactorXexp() | 4 | 1 | 4 | 4 |
| main.Parser.parseTerm(boolean) | 3 | 1 | 4 | 4 |
| main.Parser.setFunctions(ArrayList<Function>) | 0 | 1 | 1 | 1 |
设计架构
第三次作业做的改动相对较少,主要是将sum和function纳入factor接口组成的parser运算体系中。同时也进一步优化了代码架构,调整代码风格的同时极大简化了之前繁杂的预处理。
优点
-
递归下降的思路较为清晰,架构优化后降低了类之间的耦合度
缺点
-
由于代码迭代中忘记及时注释掉废弃的方法,导致Sum模块新方法未能充分测试,在强测中出锅。
-
对解析过程思考不够完善,导致自定义函数部分出现纰漏,强测WA,互测也被hack
互测体验
bug分析
-
和很多同学一样未考虑Sum函数中s,t的值超出int的情况,修改Sum类后修复。
-
自定义函数部分出错,主要是factorparse()方法中Function类进出栈顺序错误问题,调换代码顺序即可解决,这种bug在编写过程中稍微推演即可发现,下回应注意。
hack体验
这次利用了普遍性的bug,hack到了几位同学,但是对其他bug测试研究不充分,这是值得反思的,并且应在下一次作业中改进。
测试方法
总结与体会
架构设计
三次作业中,我感受到架构设计是十分重要的。良好的架构能省去相当多的重构/打补丁时间,而对架构的清晰认识能够减少代码出锅的可能性。第一单元的作业由于参考了上机练习的架构,在这方面并没有耗费太多时间,不过之后的任务未必就如此幸运了。
心得感受
