基于Token-bucket(令牌桶)的hashlimit;iptables限制syn_ack并发个数,并记录日志;
http://superuser.com/questions/769174/limit-incoming-connections-using-iptables-per-ip
|
I need to limit access to some port per IP. Let's say 5 connections per minute - not more. I've seen iptables recent, connlimit and limit, but all of them are not fitting exactly what I need. Suppose you have a client trying to connect every second. In my scenario I need to allow 5 packetseach minute. recent: If some IP tries to connect every 1 second, --hitcount 5 will memorize this IP and keep it in the list until no packets comes within --second 60 time. So, it will limit the client permanently in my scenario. limit: This one limits as I wish with --limit 5/min, but for all IPs - no way to specify this per IP. connlimit: Limits number of simultaneous connections, not per some time. In fact, I need a mixture of limit + recent. Who knows how to do it? |
|||||||||
|
|
Use the hashlimit match extension: Debug version: |
|||||||||||||||||||||
|


|
To limit the number of connections is to use that will reject connections above 5 from one source IP. If you want to protect from a DDoS attack use
|
|||||||||
|
|
Finally managed to do it with recent: --update will restart the timer again on each receiving packet, but --rcheck will only check it. After 60 seconds the structure is deleted and a new timer is started again. This is how I got it (I was not looking into sources - too lazy) |
|||
http://www.oschina.net/question/12_3612
[转]使用iptables应对SYN攻击、CC攻击、ACK攻击
三次握手的过程及相关概念
TCP/IP协议使用三次握手来建立连接,过程如下:
1、第一次握手,客户端发送数据包syn到服务器,并进入SYN_SEND状态,等待回复
2、第二次握手,服务器发送数据报syn/ack,给客户机,并进入SYN_RECV状态,等待回复
3、第三次握手,客户端发送数据包ACK给客户机,发送完成后,客户端和服务器进入ESTABLISHED状态,链接建立完成
三次握手协议中,服务器维护一个等待队列,收到一个syn包就在队列中建立一个条目,并分配一定的资源。对应的每一个条目表示已经收到一个syn请 求,并已经回复syn/ack,服务器上对应的连接已经进入SYN_RECV状态,等待客户端响应,收到客户端的响应包以后,该连接进入 ESTABLISHED状态,队列中对应的条目被删除。
backlog参数:设定等待队列的最大数目。对应内核参数:net.ipv4.tcp_max_syn_backlog = 1024
syn-ack重传次数:服务器发送syn/ack包,如果没有收到客户端的相应,就会重传syn/ack,超过一定时间之后会进行第二次重传,超过设定 次数以后将该条目从队列中删除。每次重传的间隔时间并不确定。对应的内核参数:net.ipv4.tcp_synack_retries = 5
syn重传次数:概念和syn/ack重传次数类似,对应的内核参数:net.ipv4.tcp_syn_retries = 5
等待存活时间:指等待队列的条目存活时间,即从服务器收到syn包到确认这个包无效的最长时间,该时间是所有重传包请求的最长等待时间
什么是SYN 攻击
syn攻击属于DDOS攻击中的一种,利用TCP/IP的缺陷进行网络攻击,可以使用很小的资源取得十分显著的效果。其基本原理如下:
服务器收到客户端的syn包,之后进入SYN_RECV状态,服务器的等待队列中增加一个条目,服务器未收到客户端的确认包,进行重传,一直到超时之后, 该条目从未链接队列中删除。客户端不断地发送syn包,而不响应来自服务器的syn/ack,等待队列的条目迅速增长,最后服务器的等待队列达到最大数 目,之后就不能再接受新的连接,一直到链接超时才从队列中删除对应的条目。配合ip地址欺骗技术,该方法可以取得十分良好的效果,基本上在攻击期间,服务 器将不能给正常的用户提供服务。这个攻击办法利用了TCP/IP协议的缺陷,攻击的目标不止于服务器,任何网络设备,只要开启了网络服务器,都可能会受到 这种攻击,导致处理器资源被大量占用,内存被用完,大量队列等待处理,针对网络设备的攻击往往会导致整个网络瘫痪。
如何减小SYN攻击的影响
1、修改等待数:
2、启用syncookies:
启用syncookies可以大幅减小syn攻击带来的影响,但是却引入了新的安全缺陷
syncookie基本原理是:仔细处理连接的初始序列号而不是随机选择一个序列号。一旦server接收到SYN报文,将关键信息仔细编码并作为 state存储在SYN队列中。这种经过编码的信息是用一个秘钥进行加密hash,形成SYN-ACK报文中的序列号并发送给client。在合法握手的 第三个报文中,即从client返回给server的ACK报文中,在acknowledgment number字段中包含该序列号(加1). 这样,open双向连接所必须的所有信息又返回给server,而server在三次握手完成之前不必维护state。syn-cookies解决了 SYN的基本问题,但是随之带来一个新的问题,就是服务器需要对收到的ACK报文进行计算,提高了三次握手需要的系统资源。一种新的攻击方式随之而来,即 ACK攻击,发送大量的ACK数据报,导致服务器忙于计算最终导致服务器停止相应。Linux上的实际应用中,只有等待数被占满的时候才会启用 syncookies的方式(syncookies摘自网文)
3、修改重试次数
4、使用iptables限制单个地址的并发连接数量:
5、使用iptables限制单个c类子网的并发链接数量:
6、限制单位时间内的连接数:
#iptables -t filter -A INPUT -p tcp --dport 80 -m --state --state NEW -m recent --update --seconds 60 --hitcount 30 --name access -j DROP
或者使用如下两条策略
#iptables -t filter -A INPUT -p tcp --dport 80 -m --state --syn -m recent --set
#iptables -t filter -A INPUT -p tcp --dport 80 -m --state --syn -m recent --update --seconds 60 --hitcount 30 -j DROP
7、为了取得更好的效果,需要修改/etc/modprobe.conf
8、限制单个地址最大连接数:
应对 ACK攻击
ACK 攻击是针对syn-cookies而发产生的,通过发送大量的ACK数据报,使目标服务器忙于计算,达到拒绝服务的目的,使用iptables对发起 ACK攻击的地址进行限制
#iptables -I INPUT -p tcp --dport 80 -m connlimit --connlimit-above 50 -j DROP 限制并发连接数不大于50
#iptables -t filter -A INPUT -p tcp --dport 80 --tcp-flags FIN,SYN,RST,ACK ACK -m connlimit --connlimit-above 10 --connlimit-mask 32 -j REJECT 限制并发ACK不大于50
#iptables -t filter -A INPUT -p tcp --dport 80 --tcp-flags FIN,SYN,RST,ACK ACK -m recent --set --name drop
#iptables -t filter -A INPUT -p tcp --dport 80 --tcp-flags FIN,SYN,RST,ACK ACK -m recent --update --seconds 60 --hitcount 30 -j DROP 一分钟内大于30次的连接全部丢弃
应对CC攻击
普通的CC攻击特点是所有的连接都是正常的完整的连接,这样的连接一般的防火墙是很难预防的。但是既然是网络攻击必然也具有网络攻击的共同特点,也 就是每一个攻击源都会发起尽量多的连接,因此我们仍然可以使用限制单个地址并发链接数量的办法来实现对CC攻击的抵御。具体命令同上
webcc,想必之下似乎更加难以预防,但是由于所有的访问都是由相同的一个或几个网站中转而来,这些访问请求的http_reffer都会带有这 些中转站的地址。我们只要在web服务器上设置http_reffer过滤即可大幅减小webcc攻击的影响,具体的设置这里就略过不表了
附:如何为RHEL5增加connlimit模块
#wget ftp://ftp.netfilter.org/pub/iptables/iptables-1.4.0.tar.bz2
#
bunzip2 iptables-1.4.0.tar.bz2
#
tar xvf iptables-1.4.0.tar
#
bunzip2 patch-o-matic-ng-20080214.tar.bz2
# tar xf patch-o-matic-ng-20080214.tar
#
cd patch-o-matic-ng-20080214
下载connlimit模块
# export IPTABLES_DIR=/root/iptables-1.4.0
# ./runme --download
Successfully downloaded external patch geoip
Successfully downloaded external patch condition
Successfully downloaded external patch IPMARK
Successfully downloaded external patch ROUTE
Successfully downloaded external patch connlimit
Successfully downloaded external patch ipp2p
Successfully downloaded external patch time
./patchlets/ipv4options exists and is not external
./patchlets/TARPIT exists and is not external
Failed to get http://www.intra2net.com/de/produkte/opensource/ipt_account//index, skipping..
Successfully downloaded external patch pknock
Loading patchlet definitions........................ done
Excellent! Source trees are ready for compilation.
把connlimit应用到内核
Loading patchlet definitions........................ done
Welcome to Patch-o-matic ($Revision: 6736 $)!
Kernel:
2.6.18, /usr/src/kernels/2.6.18-8.el5-i686/
Iptables: 1.4.0, /root/iptables-1.4.0/
Each patch is a new feature: many have minimal impact, some do not.
Almost every one has bugs, so don't apply what you don't need!
-------------------------------------------------------
Already applied:
Testing connlimit... not applied
The connlimit patch:
Author: Gerd Knorr <kraxel@bytesex.org>
Status: ItWorksForMe[tm]
This adds an iptables match which allows you to restrict the
number of parallel TCP connections to a server per client IP address
(or address block).
Examples:
# allow 2 telnet connections per client host
iptables -p tcp --syn --dport 23 -m connlimit --connlimit-above 2 -j REJECT
# you can also match the other way around:
iptables -p tcp --syn --dport 23 -m connlimit ! --connlimit-above 2 -j ACCEPT
# limit the nr of parallel http requests to 16 per class C sized
# network (24 bit netmask)
iptables -p tcp --syn --dport 80 -m connlimit --connlimit-above 16 \
--connlimit-mask 24 -j REJECT
-----------------------------------------------------------------
Do you want to apply this patch [N/y/t/f/a/r/b/w/q/?] y
Excellent! Source trees are ready for compilation.
内核编译
scripts/kconfig/conf -o arch/i386/Kconfig
*
* Linux Kernel Configuration
*
*
* Code maturity level options
*
Prompt for development and/or incomplete code/drivers (EXPERIMENTAL) [Y/n/?] y
*
* General setup
………………………………………………………………………………………………………………………………………………………..
ARP tables support (IP_NF_ARPTABLES) [M/n/?] m
ARP packet filtering (IP_NF_ARPFILTER) [M/n/?] m
ARP payload mangling (IP_NF_ARP_MANGLE) [M/n/?] m
Connections/IP limit match support (IP_NF_MATCH_CONNLIMIT) [N/m/?] (NEW) m
提示加入了connlimit的选项,问使用哪一种模式,编译进内核还是模块,输入“m”,编译为模块
CRC32 functions (CRC32) [Y/?] y
CRC32c (Castagnoli, et al) Cyclic Redundancy-Check (LIBCRC32C) [Y/?] y
#
# configuration written to .config
#
编译模块
scripts/kconfig/conf -s arch/i386/Kconfig
CHK
include/linux/version.h
CHK
include/linux/utsrelease.h
HOSTCC
scripts/genksyms/genksyms.o
HOSTCC
scripts/genksyms/lex.o
HOSTCC
scripts/genksyms/parse.o
HOSTLD
scripts/genksyms/genksyms
CC
scripts/mod/empty.o
MKELF
scripts/mod/elfconfig.h
HOSTCC
scripts/mod/file2alias.o
HOSTCC
scripts/mod/modpost.o
HOSTCC
scripts/mod/sumversion.o
HOSTLD
scripts/mod/modpost
net/ipv4/netfilter/Makefile.bak
备份原来的文件
LD
net/ipv4/netfilter/built-in.o
CC [M]
net/ipv4/netfilter/ipt_connlimit.o
Building modules, stage 2.
MODPOST
CC
net/ipv4/netfilter/ipt_connlimit.mod.o
LD [M]
net/ipv4/netfilter/ipt_connlimit.ko
#
cp net/ipv4/netfilter/ipt_connlimit.ko /lib/modules/2.6.18-8.el5/kernel/net/ipv4/netfilter/
# chmod 744 /lib/modules/2.6.18-8.el5/kernel/net/ipv4/netfilter/ipt_connlimit.ko
# depmod -a
[root@localhost 2.6.18-8.el5-i686]# modprobe ipt_connlimit
# lsmod |grep conn
ip_conntrack_netbios_ns
6977
0
ipt_connlimit
7680
6
ip_conntrack
53153
3 ip_conntrack_netbios_ns,xt_state,ipt_connlimit
nfnetlink
10713
1 ip_conntrack
x_tables
17349
8 ipt_recent,xt_state,ipt_REJECT,ipt_connlimit,ip_tables,ip6t_REJECT,xt_tcpudp,ip6_tables
好了,模块安装完毕。可以使用connlimit策略了
######################################################################
http://moper.me/some-useful-iptables-rules.html
一些有用的iptables规则
iptables -I INPUT -p tcp –dport 80 -m connlimit –connlimit-above 30 -j REJECT
允许单个IP的最大连接数为 30
iptables -t filter -A INPUT -p tcp –dport 80 –tcp-flags FIN,SYN,RST,ACK SYN -m connlimit –connlimit-above 10 –connlimit-mask 32 -j REJECT
iptables限制单个地址的并发连接数量
iptables -t filter -A INPUT -p tcp –dport 80 –tcp-flags FIN,SYN,RST,ACK SYN -m connlimit –connlimit-above 10 –connlimit-mask 24 -j REJECT
使用iptables限制单个c类子网的并发链接数量
iptables -A INPUT -s 192.168.0.8|192.168.0.0/24 -p tcp –dport 22 -j ACCEPT
只允许某IP或某网段的机器进行SSH连接
iptables -A FORWARD -p TCP ! –syn -m state –state NEW -j DROP
丢弃坏的TCP包
iptables -A FORWARD -f -m limit –limit 100/s –limit-burst 100 -j ACCEPT
处理IP碎片数量,防止攻击,允许每秒100个
iptables -A FORWARD -p icmp -m limit –limit 1/s –limit-burst 10 -j ACCEPT
设置ICMP包过滤,允许每秒1个包,限制触发条件是10个包
iptables -A FORWARD -m state –state INVALID -j DROP
iptables -A INPUT -m state –state INVALID -j DROP
iptables -A OUTPUT -m state –state INVALID -j DROP
禁止非法连接
iptables -N syn-flood
iptables -A INPUT -p tcp –syn -j syn-flood
iptables -A syn-flood -p tcp -m limit –limit 3/s –limit-burst 6 -j RETURN
iptables -A syn-flood -j REJECT
防止SYN攻击 轻量
iptables -A INPUT -p tcp –syn –dport 22 -j ACCEPT
iptables -A OUTPUT -p tcp –syn –dport 22 -j ACCEPT
允许访问22端口
iptables -A INPUT -p tcp –syn –dport 80 -j ACCEPT
iptables -A OUTPUT -p tcp –syn –dport 80 -j ACCEPT
允许访问80端口
iptables -A INPUT -j REJECT
iptables -A FORWARD -j REJECT
禁止其他未允许的规则访问(注意:如果22端口未加入允许规则,SSH链接会直接断开。)
最近在研究一个话题,就是iptables 怎么利用hashlimit 和limit 结合限速使有效的带宽最大用户使用
测试环境:MTU=1492
eth1 (内网口) eth0(公网出口)
着先,明白hashlimit 各参数的意义
-m
hashlimit
--hashlimit-name
--hashlimit
--hashlimit-burst
--hashlimit-mode
srcip (每个源地址IP为一个匹配项)
dstip (每个目的地址IP为一个匹配项)
srcport (每个源端口为一个匹配项)
dstport (每个目的端口为一个匹配项)
--hashlimit-htable-expire
FORWARD default DROP
本实验只针对FORWARD eth1
首先自定义BASE链,放过NEW,ESTABLISHED,RELATED,并使用hashlimit 进行第一次限速
script:

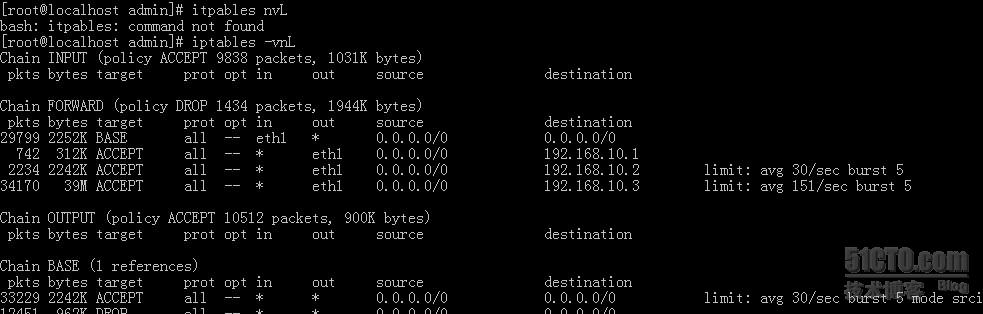
然后分别在FORWARD 用三个ip 进行测试
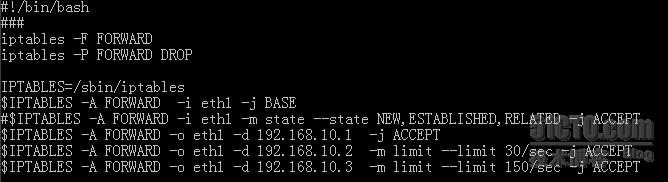
测试流理详细图
针对192.168.10.1 解释
测试下载速度AVG 100/Kbps
由于forward 链中对192.168.10.1 没有什么出任何限速,故限速体现在hashlimit
针对192.168.10.2 解释
测试下载速度AVG 28/Kbps
由于forward 链中对192.168.10.2 做出了limit 30/sec的限速,故限速体现在limit
针对192.168.10.3解释
测试下载速度为AVG 100Kbps
它的速度限制来出hashlimit
结论:当hashlimit 同时存在时,以最小的为准
hashlimit 比limit 更精确(请查阅相关资料)
经测试: hashlimit 对-i eth1 state 状态包限速和实际速度大约存在三倍关系
hashlimit 下载速度AVG
10/sec 27/Kbps
20/sec 60/Kbps
30/sec 100/Kbps
40/sec 125/Kbps
本文出自 “小杨” 博客,请务必保留此出处http://fabian.blog.51cto.com/2541639/548053
http://blog.tankywoo.com/2015/03/18/iptables-hashlimit-module.html
iptables的hashlimit模块
某机器有一条防DNS攻击的规则:
iptables -t raw -I dns_limit -m string --algo bm --icase \
--hex-string "|${hex_domain}|" \
-m hashlimit \
--hashlimit-name DNS \
--hashlimit-mode srcip \
--hashlimit-above 1/second \
--hashlimit-burst 1 \
--hashlimit-htable-max 1000000 \
--hashlimit-htable-expire 180000 \
--hashlimit-htable-gcinterval 30000 \
--hashlimit-srcmask 28 \
-m comment --comment "${domain}" -j DROP
当时机器上测试dig查询, 发现某个域名被完全封禁了, 而不是预想中的限速.
查看iptables的规则链dns_limit, 发现这个域名有两条这样的规则, 删除一条后则和预想一致, 实现了限速.
先说下最主要的, hashlimit 模块的核心是令牌桶算法(Token Bucket), 这个模块的作用是匹配, 限速是根据匹配结果以及target操作而实现的功能. 当时了解到这个后, 问题就迎刃而解了.
几个参数:
--hashlimit-name: 定义这条hashlimit规则的名称, 所有的条目(entry)都存放在/proc/net/ipt_hashlimit/{hashlimit-name}里--hashlimit-mode: 限制的类型,可以是源地址/源端口/目标地址/目标端口--hashlimit-srcmask: 当mode设置为srcip时, 配置相应的掩码表示一个网段--hashlimit-above: mount/quantum, 允许进来的包速率(令牌恢复速率)--hashlimit-burst: 允许突发的个数(其实就是令牌桶最大容量)--hashlimit-htable-max: hash的最大条目数--hashlimit-htable-expire: hash规则失效时间, 单位毫秒(milliseconds)--hashlimit-htable-gcinterval: 垃圾回收器回收的间隔时间, 单位毫秒
上面是man手册比较正式的解释.
关于 expire 和 gcinterval, 如果在这个时间内没有再次触发规则, 则时间逐渐减为0, 进而负数, 但是并不会从hash中删除, 直到垃圾回收器执行后, 才会删除.
gcinterval 一般设置会比 expire 小, 这个值应配合 expire 选取合适值, 太小会导致频繁占用资源, 太大会导致封禁条目达到失效时间后还需要等待很久才会被删除.
失效时间到达后未被删除, 还是会被封禁.
查看 /proc/net/ipt_hashlimit/DNS 文件:
$ cat /proc/net/ipt_hashlimit/DNS
180 X.X.X.X:0->0.0.0.0:0 32000 32000 32000
这里第一个字段是expire倒计时时间(单位是秒), 比如这里设置180000毫秒, 即180s, 如果180s内没有再次触发这个规则, 则会一直减到0 (见上面关于expire解释); 如果触发则再次变为180.
第二个字段是 srcip:port->dstip:port, 这里mode只设置了srcip
第三个字段是当前剩余的令牌数
第四个字段是令牌桶最大容量, 是一个定值
第五个字段是一次触发使用的令牌数, 也是令牌产生速率, 也是一个定值
一秒(second)有32000个令牌(TODO 这里没有找到相关说明, 源码也没翻到... 猜测应该是每jiffy(毫秒) 32个令牌), 如果限制是 1req/sec, 则令牌产生速率是 32000/1 = 32000, 如果是 2req/sec, 则第五个字段就是 32000/2 = 16000.
而最大的令牌数就是 令牌产生速率 * {hashlimit-burst}, 比如 2req/sec, burst是5, 则第四个字段就是32000/2*5 = 80000
第三个字段每触发一次规则, 都会减去 令牌产生速率 * 1个令牌, 并以这个速率恢复. 如果长时间没有触发, 会一直处于和最大令牌数一样的值.
关于hashlimit的匹配结果: 当查询包进来时, 如果令牌足够, 则会减去一次令牌数, 接着恢复, 且接着去下一条规则; 如果在剩余的令牌不足以减去一次查询的令牌, 则匹配这条hashlimit规则, target是DROP时, 则丢弃这个包.
模拟DNS攻击, 查看第三个字段的值, 发现两条规则时, 就是减少两次令牌, 因为一次会减少32000个令牌, 两次减少64000个, 而令牌桶的最大数目是32000, 也就是说这是一个永远无法完成的操作, 当然也就会造成一种完全封禁的情况.
实验测试中, 比如把速率改为 2seq/sec, burst改为3, 一遍dig一遍抓包并查看/proc/net/ipt_hashlimit/DNS文件, 可以看到当令牌不够时, 匹配这个域名后的包确实丢掉了.
简单小结下: 开头的这个规则, 主要就是 hashlimit-above 和 hashlimit-burst 这两个参数的设置. 首先匹配上域名, 然后hashlimit会新建一个entry, 用令牌桶管理包速. hashlimit-above 决定了一秒允许多少个包经过, 相应也就是令牌产生的速率, hashlimit-burst决定令牌桶的最大容量, 如果查询包超过这个限制(令牌桶剩余令牌不够), 则匹配上这条规则, DROP掉包, 否则包继续进入下一条规则查看是否匹配.
http://blog.serverbuddies.com/using-hashlimit-in-iptables/
Using hashlimit in iptables
This rule limits one connection to the SSH port from one IP address per minute.
hashlimit match options
--hashlimit-upto max average match rate
[Packets per second unless followed by
/sec /minute /hour /day postfixes]
–hashlimit-above min average match rate
–hashlimit-mode mode is a comma-separated list of
dstip,srcip,dstport,srcport (or none)
–hashlimit-srcmask source address grouping prefix length
–hashlimit-dstmask destination address grouping prefix length
–hashlimit-name name for /proc/net/ipt_hashlimit
–hashlimit-burst number to match in a burst, default 5
–hashlimit-htable-size number of hashtable buckets
–hashlimit-htable-max number of hashtable entries
–hashlimit-htable-gcinterval interval between garbage collection runs
–hashlimit-htable-expire after which time are idle entries expired?
http://m.ctocio.com.cn/os/120/12145620_2_m.shtml
iptables中用hashlimit来限速
博客
第一条的作用是,为所有访问本机22端口的不同IP建立一个匹配项,匹配项对应的令牌桶容量为10,令牌产生速率为5个每秒。放行通过匹配的数据包。
第二条的作用是,丢弃所有其它访问本机22端口的数据包。
通过这两条命令,我们就实现了限制其它机器对本机22端口(ssh服务)频繁访问的功能.
再来我们看一个复杂点的限速。假设我们现在在一台NAT网关上,想限制内部网某个网段 192.168.1.2/24对外的访问频率。(这个的主要作用是限制内部中毒主机对外的flood攻击)
那我们可以这么做:
| iptables -N DEFLOOD iptables -A FORWARD -s 192.168.1.2/24 -m state --state NEW -j DEFLOOD iptables -A DEFLOOD -m hashlimit --hashlimit-name deflood --hashlimit 10/sec --hashlimit-burst 10 --hashlimit-mode srcip -j ACCEPT iptables -P DEFLOOD -j DROP |
第一条命令建立了一个自定义的处理链
第二条命令,所有来自192.168.1.2/24网段,并且打算新建网络连接的数据包,都进入DEFLOOD链处理
第三条命令,在DEFLOOD链中,为每个IP建立一个匹配项,对应令牌桶容量为10,产生速率为10个每秒。放行通过匹配的数据包。
第四条命令,在DEFLOOD链中丢弃所有其它的数据包
当然,hashlimit还有一些其他的参数,比如
| --hashlimit-htable-expire --hashlimit-htable-size --hashlimit-htable-max |
具体可以man iptables
以上我们介绍了hashlimit模块的原理和使用。希望能对大家有所帮助
这几天正在捣鼓防火墙,用到了hashlimit模块。Google了一圈发现相关的文档无论英文还
是中文都很少,
所以我就把自己的折腾的心得记录下来吧。
hashlimit是iptables的一个匹配模块,用它结合iptables的其它命令可以实现限速的功能
。(注意,单独hashlimit模块
是无法限速的)。
不过首先必须明确,hashlimit本身只是一个“匹配”模块。我们知道,iptables的基本原
理是“匹配--处理”,hashlimit在
这个工作过程中只能起到匹配的作用,它本身是无法对网络数据包进行任何处理的。我看到
网上有些hashlimit的例子里面说只
用一条包含hashlimit匹配规则的iptables语句就可以实现限速,那是错误的。
实际上,利用hashlimit来限速需要包括两个步骤。
1.对符合hashlimit匹配规则包放行
2.丢弃/拒绝未放行的包
下面是一个简单的例子:
iptables -A INPUT -p tcp --dport 22 -m hashlimit --hashlimit-name ssh
--hashlimit 5/sec --hashlimit-burst 10 --hashlimit-mode srcip
--hashlimit-htable-expire 90000 -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j DROP
然后,我们来着重讲讲hashlimit模块具体是如何工作的。hashlimit的匹配是基于令牌桶
(Token bucket)模型的。令牌桶是一种网络通讯中常见的缓冲区工作原理,它有两个重要
的参数,令牌桶容量n和令牌产生速率s。我们可以把令牌当成是门票,而令牌桶则是负责制
作和发放门票的管理员,它手里最多有n张令牌。一开始,管理员开始手里有n张令牌。每当
一个数据包到达后,管理员就看看手里是否还有可用的令牌。如果有,就把令牌发给这个数
据包,hashlimit就告诉iptables,这个数据包被匹配了。而当管理员把手上所有的令牌都
发完了,再来的数据包就拿不到令牌了。这时,hashlimit模块就告诉iptables,这个数据
包不能被匹配。
除了发放令牌之外,只要令牌桶中的令牌数量少于n,它就会以速率s来产生新的令牌,直到
令牌数量到达n为止。
通过令牌桶机制,即可以有效的控制单位时间内通过(匹配)的数据包数量,又可以容许短
时间内突发的大量数据包的通过(只要数据包数量不超过令牌桶n)。
hashlimit模块提供了两个参数--hashlimit和--hashlimit-burst,分别对应于令牌产生速
率和令牌桶容量。
除了令牌桶模型外,hashlimit匹配的另外一个重要概念是匹配项。在hashlimit中,每个匹
配项拥有一个单独的令牌桶,执行独立的匹配计算。通过hashlimit的--hashlimit-mode参
数,你可以指定四种匹配项及其组合,即:srcip(每个源地址IP为一个匹配项),dstip(
每个目的地址IP为一个匹配项),srcport(每个源端口为一个匹配项),dstport(每个目
的端口为一个匹配项)
除了前面介绍的三个参数外,hashlimit还有一个必须要用的参数,即--hashlimit-name。
hashlimit会在/proc/net/ipt_hashlimit目录中,为每个调用了hashlimit模块的iptables
命令建立一个文件,其中保存着各匹配项的信息。--hashlimit-name参数即用来指定该文件
的文件名。
好了,以上我们已经介绍了hashlimit的工作原理和相应的参数,下面我们来看几个例子。
首先是前面的那个例子:
iptables -A INPUT -p tcp --dport 22 -m hashlimit --hashlimit-name ssh
--hashlimit 5/sec --hashlimit-burst 10 --hashlimit-mode -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j DROP
在了解了hashlimit各参数的含义之后,我们现在就可以知道这两条iptables命令的作用。
第一条的作用是,为所有访问本机22端口的不同IP建立一个匹配项,匹配项对应的令牌桶容
量为10,令牌产生速率为5个每秒。放行通过匹配的数据包。
第二条的作用是,丢弃所有其它访问本机22端口的数据包。
通过这两条命令,我们就实现了限制其它机器对本机22端口(ssh服务)频繁访问的功能,
再来我们看一个复杂点的限速。假设我们现在在一台NAT网关上,想限制内部网某个网段
192.168.1.2/24对外的访问频率。(这个的主要作用是限制内部中毒主机对外的flood攻击
)
那我们可以这么做:
iptables -N DEFLOOD
iptables -A FORWARD -s 192.168.1.2/24 -m state --state NEW -j DEFLOOD
iptables -A DEFLOOD -m hashlimit --hashlimit-name deflood --hashlimit 10/sec
--hashlimit-burst 10 --hashlimit-mode srcip -j ACCEPT
iptables -P DEFLOOD -j DROP
第一条命令建立了一个自定义的处理链
第二条命令,所有来自192.168.1.2/24网段,并且打算新建网络连接的数据包,都进入
DEFLOOD链处理
第三条命令,在DEFLOOD链中,为每个IP建立一个匹配项,对应令牌桶容量为10,产生速率为
10个每秒。放行通过匹配的数据包。
第四条命令,在DEFLOOD链中丢弃所有其它的数据包
以上我们介绍了hashlimit模块的原理和使用。希望能对大家有所帮助:)
用iptables的limit或hashlimit模块,目标是ACCEPT。当你设置300/s时,它大约每3ms发出一个令牌,获得令牌的包可以发出去,没有获得令牌的包只能等待下一个令牌到来,这样不会造成一些包丢失,更不会造成所谓“断线”的。
limit匹配:限制匹配数据包的频率或速率,看清楚了,它是用来限制匹配的数据包的频率和速率的. 这里“limit”这个词经常给别人“限制”的误解,其实准确说,应该是“按一定速率去匹配”
至于“限制”还是“放行”是后面 -j 动作来实现的
limit 仅仅是个 match 模块,他的功能是匹配,匹配方式是按一定速率
以下2条是对icmp的burst限制
iptables -A INPUT -p icmp -m limit --limit 1/sec --limit-burst 10 -j ACCEPT
iptables -A INPUT -p icmp -j DROP
第一条ipables的意思是限制ping包每一秒钟一个,10个后重新开始.
同时可以限制IP碎片,每秒钟只允许100个碎片,用来防止DoS攻击.
iptables -A INPUT -f -m limit --limit 100/sec --limit-burst 100 -j ACCEPT
iptables limit 参数备忘
? 限制特定封包传入速度
? 限制特定端口口连入频率
? iptables Log 记录参数备忘
? 自定 Chain 使用备忘
? 防治 SYN-Flood 碎片攻击
限制 ping (echo-request) 传入的速度
限制前, 可正常每 0.2 秒 ping 一次
ping your.linux.ip -i 0.2
限制每秒只接受一个 icmp echo-request 封包
iptables -A INPUT -p icmp --icmp-type echo-request -m limit --limit 1/s --limit-burst 1 -j ACCEPT
iptables -A INPUT -p icmp --icmp-type echo-request -j DROP
--limit 1/s 表示每秒一次; 1/m 则为每分钟一次
--limit-burst 表示允许触发 limit 限制的最大次数 (预设 5)
再以每 0.2 秒 ping 一次, 得到的响应是每秒一次
ping your.linux.ip -i 0.2
限制 ssh 连入频率
建立自订 Chain, 限制 tcp 联机每分钟一次, 超过者触发 Log 记录 (记录在 /var/log/messages)
iptables -N ratelimit
iptables -A ratelimit -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -A ratelimit -p tcp --syn -m limit --limit 1/m --limit-burst 1 -j ACCEPT
iptables -A ratelimit -p tcp -j LOG --log-level "NOTICE" --log-prefix "[RATELIMIT]"
iptables -A ratelimit -p tcp -j DROP
引用自订 Chain, 限制 ssh (tcp port 22) 连入频率
iptables -A INPUT -p tcp --dport 22 -s 192.168.0.0/16 -j ACCEPT (特定 IP 来源不受限制)
iptables -A INPUT -p tcp --dport 22 -j ratelimit
参考数据: Mike's Blog - How to limit attack attempts in Linux
sshd_config 设定备忘:
? LoginGraceTime 30 密码输入时限为 30 秒
? MaxAuthTries 2 最多只能输入 3 次密码
同理可证
iptables -N pinglimit
iptables -A pinglimit -m limit --limit 1/s --limit-burst 1 -j ACCEPT
iptables -A pinglimit -j DROP
iptables -A INPUT -p icmp --icmp-type echo-request -j pinglimit
亦可达到每秒只接受一个 echo-request 封包
补充: 清除自订 Chain
iptables -L -n --line-number
iptables -D INPUT n
iptables -F ratelimit
iptables -X ratelimit
防治 SYN-Flood 碎片攻击
iptables -N syn-flood
iptables -A syn-flood -m limit --limit 50/s --limit-burst 10 -j RETURN
iptables -A syn-flood -j DROP
iptables -I INPUT -j syn-flood
模拟攻击
wget http://www.xfocus.net/tools/200102/naptha-1.1.tgz
wget ftp://rpmfind.net/linux/freshrpms/redhat/7.0/libnet/libnet-1.0.1b-1.src.rpm
tar -zxf naptha-1.1.tgz
rpmbuild --recompile libnet-1.0.1b-1.src.rpm
cp -r /var/tmp/libnet-buildroot/usr/* /usr/local/
cd naptha-1.1
make
./synsend your.linux.host.ip 80 local.host.eth0.ip 0.1
若成功抵挡, 不久后会出现 Can't send packet!: Operation not permitted 的讯息
iprange a.b.c.d-a.b.c.d 表示这一段地址还是分别表示每一个包含的地址?
例 iptables -A -m iprange --src-range 172.16.1.10-172.16.16.1 -m limit --limit 300/second -j ACCEPT
表示172.16.1.10-172.16.16.1这段地址每秒一共匹配300个数据包
还是表示172.16.1.10-172.16.16.1地址中的每一个ip 分别匹配300个数据包?-------iprange a.b.c.d-a.b.c.d 表示这一段地址还是分别表示每一个包含的地址?
例 iptables -A -m iprange --src-range 172.16.1.10-172.16.16.1 -m limit --limit 300/second -j ACCEPT
表示172.16.1.10-172.16.16.1这段地址每秒一共匹配300个数据包
还是表示172.16.1.10-172.16.16.1地址中的每一个ip 分别匹配300个数据包?
limit
This module must be explicitly specified with `-m limit' or `--match limit'. It is used to restrict the rate of matches, such as for suppressing log messages. It will only match a given number of times per second (by default 3 matches per hour, with a burst of 5). It takes two optional arguments:
--limit
followed by a number; specifies the maximum average number of matches to allow per second. The number can specify units explicitly, using `/second', `/minute', `/hour' or `/day', or parts of them (so `5/second' is the same as `5/s').
--limit-burst
followed by a number, indicating the maximum burst before the above limit kicks in.
This match can often be used with the LOG target to do rate-limited logging. To understand how it works, let's look at the following rule, which logs packets with the default limit parameters:
# iptables -A FORWARD -m limit -j LOG
The first time this rule is reached, the packet will be logged; in fact, since the default burst is 5, the first five packets will be logged. After this, it will be twenty minutes before a packet will be logged from this rule, regardless of how many packets reach it. Also, every twenty minutes which passes without matching a packet, one of the burst will be regained; if no packets hit the rule for 100 minutes, the burst will be fully recharged; back where we started.
iptables -t filter -A INPUT -p icmp --icmp-type echo-request -m limit --limit 6/minute --limit-burst 6 -j LOG --log-prefix="filter INPUT:"
列:
#!/bin/bash
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -N syn-flood
iptables -A INPUT -i eth0 -p tcp -m state --state NEW -j syn-flood
iptables -A syn-flood -m limit --limit 1/s --limit-burst 4 -j RETURN
iptables -A INPUT -i eth0 -p tcp ! --syn -m state --state NEW -j DROP
iptables -A INPUT -i eth0 -p tcp -d 0/0 --dport 80 -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --dport 22 -j ACCEPT
iptables -A INPUT -f -m limit --limit 100/s --limit-burst 100 -j ACCEPT
iptables -A INPUT -p icmp -m limit --limit 1/s --limit-burst 3 -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --dport 21 -j ACCEPT
iptables -A INPUT -i eth0 -p tcp --dport 20 -j ACCEPT
iptables -A INPUT -i eth0 -j DROP
流量控制
tc qdisc del dev eth0 root 2>/dev/null
##定义上传总带宽(用tc语法,这里用的是htb过滤器)
##define root and default rule
tc qdisc add dev eth0 root handle 10: htb default 70
##define uplink max rate
tc class add dev eth0 parent 10: classid 10:1 htb rate 64kbps ceil 64kbps
##对不同的业务进行分类,定义不同的数据流量
##define second leaf
#tc class add dev eth0 parent 10:1 classid 10:10 htb rate 2kbps ceil 4kbps prio 2
#tc class add dev eth0 parent 10:1 classid 10:20 htb rate 2kbps ceil 4kbps prio 2
#tc class add dev eth0 parent 10:1 classid 10:30 htb rate 32kbps ceil 40kbps prio 3
tc class add dev eth0 parent 10:1 classid 10:40 htb rate 3kbps ceil 13kbps prio 0
tc class add dev eth0 parent 10:1 classid 10:50 htb rate 1kbps ceil 11kbps prio 1
tc class add dev eth0 parent 10:1 classid 10:60 htb rate 1kbps ceil 11kbps prio 1
tc class add dev eth0 parent 10:1 classid 10:70 htb rate 2kbps ceil 5kbps prio 1
##定义不同数据传输业务的优先级别和优化数据传输方法
##define rule for second leaf
#tc qdisc add dev eth0 parent 10:10 handle 101: pfifo
#tc qdisc add dev eth0 parent 10:20 handle 102: pfifo
#tc qdisc add dev eth0 parent 10:30 handle 103: pfifo
#tc qdisc add dev eth0 parent 10:40 handle 104: pfifo
#tc qdisc add dev eth0 parent 10:50 handle 105: pfifo
#tc qdisc add dev eth0 parent 10:60 handle 106: pfifo
#tc qdisc add dev eth0 parent 10:70 handle 107: pfifo
##tc qdisc add dev eth0 parent 10:10 handle 101: sfq perturb 10
##tc qdisc add dev eth0 parent 10:20 handle 102: sfq perturb 10
##tc qdisc add dev eth0 parent 10:30 handle 103: sfq perturb 10
tc qdisc add dev eth0 parent 10:40 handle 104: sfq perturb 5
tc qdisc add dev eth0 parent 10:50 handle 105: sfq perturb 10
tc qdisc add dev eth0 parent 10:60 handle 106: sfq perturb 10
tc qdisc add dev eth0 parent 10:70 handle 107: sfq perturb 10
##为netfilter链中的mangle链打标记做好准备(做句柄标示)
##define fw for ipfilter
#tc filter add dev eth0 parent 10: protocol ip prio 100 handle 10 fw classid 10:10
#tc filter add dev eth0 parent 10: protocol ip prio 100 handle 20 fw classid 10:20
#tc filter add dev eth0 parent 10: protocol ip prio 100 handle 30 fw classid 10:30
tc filter add dev eth0 parent 10: protocol ip prio 100 handle 40 fw classid 10:40
tc filter add dev eth0 parent 10: protocol ip prio 100 handle 50 fw classid 10:50
tc filter add dev eth0 parent 10: protocol ip prio 100 handle 60 fw classid 10:60
tc filter add dev eth0 parent 10: protocol ip prio 100 handle 70 fw classid 10:70
###################################################################################
##下载端口配置(方法同上传配置,只是在速率定义上有调整)
echo "Enabling downlink limit"
#downlink limit
##clear dev eth1 rule
tc qdisc del dev eth1 root 2>/dev/null
##define root and default rule
tc qdisc add dev eth1 root handle 10: htb default 70
##define downlink max rate
tc class add dev eth1 parent 10: classid 10:1 htb rate 128kbps ceil 128kbps
##define second leaf
#tc class add dev eth1 parent 10:1 classid 10:10 htb rate 2kbps ceil 32kbps prio 2
#tc class add dev eth1 parent 10:1 classid 10:20 htb rate 2kbps ceil 32kbps prio 2
#tc class add dev eth1 parent 10:1 classid 10:30 htb rate 32kbps ceil 212kbps prio 3
tc class add dev eth1 parent 10:1 classid 10:40 htb rate 5kbps ceil 20kbps prio 0
tc class add dev eth1 parent 10:1 classid 10:50 htb rate 2kbps ceil 17kbps prio 1
tc class add dev eth1 parent 10:1 classid 10:60 htb rate 2kbps ceil 17kbps prio 1
tc class add dev eth1 parent 10:1 classid 10:70 htb rate 3kbps ceil 5kbps prio 1
##define rule for second leaf
#tc qdisc add dev eth1 parent 10:10 handle 101: pfifo
#tc qdisc add dev eth1 parent 10:20 handle 102: pfifo
#tc qdisc add dev eth1 parent 10:30 handle 103: pfifo
#tc qdisc add dev eth1 parent 10:40 handle 104: pfifo
#tc qdisc add dev eth1 parent 10:50 handle 105: pfifo
#tc qdisc add dev eth1 parent 10:60 handle 106: pfifo
#tc qdisc add dev eth1 parent 10:70 handle 107: pfifo
##tc qdisc add dev eth1 parent 10:10 handle 101: sfq perturb 10
##tc qdisc add dev eth1 parent 10:20 handle 102: sfq perturb 10
##tc qdisc add dev eth1 parent 10:30 handle 103: sfq perturb 10
tc qdisc add dev eth1 parent 10:40 handle 104: sfq perturb 5
tc qdisc add dev eth1 parent 10:50 handle 105: sfq perturb 10
tc qdisc add dev eth1 parent 10:60 handle 106: sfq perturb 10
tc qdisc add dev eth1 parent 10:70 handle 107: sfq perturb 10
##define fw for ipfilter
#tc filter add dev eth1 parent 10: protocol ip prio 100 handle 10 fw classid 10:10
#tc filter add dev eth1 parent 10: protocol ip prio 100 handle 20 fw classid 10:20
#tc filter add dev eth1 parent 10: protocol ip prio 100 handle 30 fw classid 10:30
tc filter add dev eth1 parent 10: protocol ip prio 100 handle 40 fw classid 10:40
tc filter add dev eth1 parent 10: protocol ip prio 100 handle 50 fw classid 10:50
tc filter add dev eth1 parent 10: protocol ip prio 100 handle 60 fw classid 10:60
tc filter add dev eth1 parent 10: protocol ip prio 100 handle 70 fw classid 10:70
echo "Enabling mangle "
# uploads
#iptables -t mangle -A PREROUTING -s 192.168.0.6 -m layer7 --l7proto dns -j MARK --set-mark 10
#iptables -t mangle -A PREROUTING -s 192.168.0.6 -m layer7 --l7proto smtp -j MARK --set-mark 20
#iptables -t mangle -A PREROUTING -s 192.168.0.6 -m layer7 --l7proto http -j MARK --set-mark 30
##为ip地址打标记以便进行流量控制--上传
#iptables -t mangle -A PREROUTING -s 192.168.0.52 -j MARK --set-mark 40
#iptables -t mangle -A PREROUTING -s 192.168.0.0/24 -j MARK --set-mark 70
#iptables -t mangle -A PREROUTING -s 192.168.0.3 -j MARK --set-mark 60
# downloads
#iptables -t mangle -A POSTROUTING -d 192.168.0.6 -m layer7 --l7proto dns -j MARK --set-mark 10
#iptables -t mangle -A POSTROUTING -d 192.168.0.6 -m layer7 --l7proto smtp -j MARK --set-mark 20
#iptables -t mangle -A POSTROUTING -d 192.168.0.6 -m layer7 --l7proto http -j MARK --set-mark 30
##为ip地址打标记以便进行流量控制--下载
#iptables -t mangle -A POSTROUTING -d 192.168.0.52 -j MARK --set-mark 40
#iptables -t mangle -A POSTROUTING -d 192.168.0.0/24 -j MARK --set-mark 70
#iptables -t mangle -A POSTROUTING -d 192.168.0.3 -j MARK --set-mark 60
DDOS Protection Script
#!/bin/sh
# Firewall script made by Magarus for verlihubforums.com and adminzone.ro
# Copyright @ 2007 - Saftoiu Mihai, All rights reserved.
# The distribution of this script without Saftoiu Mihai's
# approval is a violation of copyright and will be persued to the
# full extent of the law. You may use it ONLY for non-commercial use,
# except without the author's explicit approval.
# Define constants - Leave them alone
IPTABLES=`which iptables`
MODPROBE=`which modprobe`
$MODPROBE ip_conntrack
$MODPROBE ipt_recent
NR_IP=""
IP_LOOP=""
PORT_LOOP=""
# Modify tcp/ip parameters
# Reduce timeout
echo "15" > /proc/sys/net/ipv4/tcp_fin_timeout
# Increase backlog and max conn
echo "3000" > /proc/sys/net/core/netdev_max_backlog
echo "3000" > /proc/sys/net/core/somaxconn
# Reduce timeouts and retransmissions
echo "300" > /proc/sys/net/ipv4/tcp_keepalive_time
echo "15" > /proc/sys/net/ipv4/tcp_keepalive_intvl
echo "1" > /proc/sys/net/ipv4/tcp_keepalive_probes
echo "1" > /proc/sys/net/ipv4/tcp_syncookies
echo "2" > /proc/sys/net/ipv4/tcp_synack_retries
echo "1" > /proc/sys/net/ipv4/tcp_syn_retries
# Increase SYN backlog
echo "28000" > /proc/sys/net/ipv4/tcp_max_syn_backlog
# Decrease timeouts
echo "10" > /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_timeout_syn_recv
echo "40" > /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_timeout_syn_sent
# Check for spoofing / Use 2 instead of 1 bellow if it doesn't fix it
echo "1" > /proc/sys/net/ipv4/conf/all/rp_filter
# See that conntrack doesn't get overflowed
echo "220000" > /proc/sys/net/ipv4/ip_conntrack_max
# Use scaling
echo "1" > /proc/sys/net/ipv4/tcp_window_scaling
# Remove overhead and unnecessary tcp/icmp params.
echo "0" > /proc/sys/net/ipv4/tcp_sack
echo "0" > /proc/sys/net/ipv4/conf/all/accept_source_route
echo "1" > /proc/sys/net/ipv4/icmp_echo_ignore_broadcasts
echo "1" > /proc/sys/net/ipv4/icmp_ignore_bogus_error_responses
echo "1" > /proc/sys/net/ipv4/conf/all/log_martians
echo "0" > /proc/sys/net/ipv4/tcp_timestamps
# Increase available memory
echo "16777216" > /proc/sys/net/core/rmem_max
echo "16777216" > /proc/sys/net/core/wmem_max
echo "4096 87380 16777216" > /proc/sys/net/ipv4/tcp_rmem
echo "4096 87380 16777216" > /proc/sys/net/ipv4/tcp_wmem
echo "1" > /proc/sys/net/ipv4/tcp_no_metrics_save
# Increase number of ports available (this is a must for future apache fix)
echo "1024 65000" > /proc/sys/net/ipv4/ip_local_port_range
# Function for protection/hub/ip
protect_hub(){
$IPTABLES -A OUTPUT -s $IP_LOOP -p tcp --sport $PORT_LOOP --tcp-flags ALL PSH,ACK -m string --algo bm --string Pk=version --to 300 -j RST_LOOP_OUT
$IPTABLES -A INPUT -d $IP_LOOP -p tcp --dport $PORT_LOOP --syn -j SYN_CHECK
$IPTABLES -A INPUT -d $IP_LOOP -p tcp --dport $PORT_LOOP --tcp-flags ALL PSH,ACK -m string --algo bm --string MyNick --to 100 -j REJECT --reject-with tcp-reset
$IPTABLES -A INPUT -d $IP_LOOP -p tcp --dport $PORT_LOOP -m state --state RELATED,ESTABLISHED -j ACCEPT
$IPTABLES -A INPUT -d $IP_LOOP -p tcp --dport $PORT_LOOP -j DROP
$IPTABLES -A INPUT -d $IP_LOOP -p udp --dport $PORT_LOOP -j DROP
$IPTABLES -A SYN_CHECK -d $IP_LOOP -p tcp --dport $PORT_LOOP -m hashlimit --hashlimit 2/min --hashlimit-mode srcip,dstip
--hashlimit-name dcclients --hashlimit-burst 1 --hashlimit-htable-expire 30000 --hashlimit-htable-gcinterval 1000 -j ACCEPT
$IPTABLES -A SYN_CHECK -d $IP_LOOP -p tcp --dport $PORT_LOOP -j REJECT --reject-with tcp-reset
$IPTABLES -A RST_LOOP_OUT -d $IP_LOOP -p tcp --sport $PORT_LOOP --tcp-flags ALL PSH,ACK -m conntrack --ctexpire 1:1000 -j REJECT --reject-with tcp-reset
$IPTABLES -A RST_LOOP_OUT -d $IP_LOOP -p tcp --sport $PORT_LOOP --tcp-flags ALL FIN,PSH,ACK -m conntrack --ctexpire 1:1000 -j REJECT --reject-with tcp-reset
}
# Main()
firewall_run(){
clear
echo -e "n Anti DDOS firewall for verlihub software, Copyright @ 2007 Saftoiu Mihai nn"
echo -e " How many ip addresses do you have allocated for your running hubs? c" && read NR_IP
NR_IP=`expr $NR_IP + 1`
ctl="1"
while [ "$ctl" -lt "$NR_IP" ]; do
echo -e "n Input ip no. $ctl = c"
read IP[$ctl]
let "ctl += 1"
done
echo -e "n"
ctl="1"
# Define custom chains
# Check syn chain frequency drops anyway
$IPTABLES -N SYN_CHECK
# Reset output packets so hub doesn't get locked up on output
$IPTABLES -N RST_LOOP_OUT
# Drop all junk data
$IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j DROP
$IPTABLES -A INPUT -p tcp -m state --state INVALID,UNTRACKED -j DROP
# Enter loop
while [ "$ctl" -lt "$NR_IP" ]; do
IP_LOOP="${IP[$ctl]}"
echo -e "n How many hub ports are there on this ip ${IP[$ctl]}? c"
read NR_PORTS && NR_PORTS=`expr $NR_PORTS + 1` && ctlx="1"
while [ "$ctlx" -lt "$NR_PORTS" ]; do
echo -e "n Input port $ctlx for ${IP[$ctl]} : c"
read PORT[$ctlx] && PORT_LOOP="${PORT[$ctlx]}"
protect_hub
let "ctlx += 1"
done
let "ctl += 1"
done
}
# Clear the rules and any i might add
firewall_clear(){
clear
echo -e "nn Firewall rules are now being cleared...n"
$IPTABLES -t mangle -F
$IPTABLES -t filter -F
$IPTABLES -t raw -F
$IPTABLES -Z
$IPTABLES -X
$IPTABLES -P INPUT ACCEPT
$IPTABLES -P OUTPUT ACCEPT
$IPTABLES -P FORWARD ACCEPT
$IPTABLES -L
echo -e "n Firewall CLEARED!"
}
# Run-time options
case "$1" in
'start') firewall_run ;;
'stop') firewall_clear ;;
*) echo -e "nUsage: $0 [OPTION]..."
echo -e "nOPTIONS:"
echo -e " start Run the firewall."
echo -e " stop Stop the firewall."
echo -e "n " ;;
esac
====================================
http://www.heminjie.com/system/linux/1649.html
connlimit功能:
connlimit模块允许你限制每个客户端IP的并发连接数,即每个IP同时连接到一个服务器个数。
connlimit模块主要可以限制内网用户的网络使用,对服务器而言则可以限制每个IP发起的连接数。
connlimit参数:
–connlimit-above n #限制为多少个
–connlimit-mask n #这组主机的掩码,默认是connlimit-mask 32 ,即每个IP.
例子:
限制同一IP同时最多100个http连接iptables -I INPUT -p tcp --syn --dport 80 -m connlimit --connlimit-above 100 -j REJECT只允许每组C类IP同时100个http连接
或
iptables -I INPUT -p tcp --syn --dport 80 -m connlimit ! --connlimit-above 100 -j ACCEPTiptables -p tcp --syn --dport 80 -m connlimit --connlimit-above 100 --connlimit-mask 24 -j REJECT只允许每个IP同时5个80端口转发,超过的丢弃iptables -I FORWARD -p tcp --syn --dport 80 -m connlimit --connlimit-above 5 -j DROP限制某IP最多同时100个http连接iptables -A INPUT -s 222.222.222.222 -p tcp --syn --dport 80 -m connlimit --connlimit-above 100 -j REJECT限制每IP在一定的时间(比如60秒)内允许新建立最多100个http连接数iptables -A INPUT -p tcp --dport 80 -m recent --name BAD_HTTP_ACCESS --update --seconds 60 --hitcount 100 -j REJECT
iptables -A INPUT -p tcp --dport 80 -m recent --name BAD_HTTP_ACCESS --set -j ACCEPT
http://zhaotao110.blog.sohu.com/301062128.html
一、问题
1. SYN Flood介绍
前段时间网站被攻击多次,其中最猛烈的就是TCP洪水攻击,即SYN Flood。
SYN Flood是当前最流行的DoS(拒绝服务攻击)与DDoS(分布式拒绝服务攻击)的方式之一,这是一种利用TCP协议缺陷,发送大量伪造的TCP连接请求,常用假冒的IP或IP号段发来海量的请求连接的第一个握手包(SYN包),被攻击服务器回应第二个握手包(SYN+ACK包),因为对方是假冒IP,对方永远收不到包且不会回应第三个握手包。导致被攻击服务器保持大量SYN_RECV状态的“半连接”,并且会重试默认5次回应第二个握手包,塞满TCP等待连接队列,资源耗尽(CPU满负荷或内存不足),让正常的业务请求连接不进来。
详细的原理,网上有很多介绍,应对办法也很多,但大部分没什么效果,这里介绍我们是如何诊断和应对的。
2. 诊断
我们看到业务曲线大跌时,检查机器和DNS,发现只是对外的web机响应慢、CPU负载高、ssh登陆慢甚至有些机器登陆不上,检查系统syslog:
# tail -f /var/log/messages
Apr 18 11:21:56 web5 kernel: possible SYN flooding on port 80. Sending cookies.
检查连接数增多,并且SYN_RECV 连接特别多:
# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAIT 16855
CLOSE_WAIT 21
SYN_SENT 99
FIN_WAIT1 229
FIN_WAIT2 113
ESTABLISHED 8358
SYN_RECV 48965
CLOSING 3
LAST_ACK 313
根据经验,正常时检查连接数如下:
# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAIT 42349
CLOSE_WAIT 1
SYN_SENT 4
FIN_WAIT1 298
FIN_WAIT2 33
ESTABLISHED 12775
SYN_RECV 259
CLOSING 6
LAST_ACK 432
以上就是TCP洪水攻击的两大特征。执行netstat -na>指定文件,保留罪证。
3. 应急处理
根据netstat查看到的对方IP特征:
# netstat -na |grep SYN_RECV|more
利用iptables临时封掉最大嫌疑攻击的IP或IP号段,例如对方假冒173.*.*.*号段来攻击,短期禁用173.*.*.*这个大号段(要确认小心不要封掉自己的本地IP了!)
# iptables -A INPUT -s 173.0.0.0/8 -p tcp –dport 80 -j DROP
再分析刚才保留的罪证,分析业务,用iptables解封正常173.*.*.*号段内正常的ip和子网段。这样应急处理很容易误伤,甚至可能因为封错了导致ssh登陆不了服务器,并不是理想方式。
4. 使用F5挡攻击
应急处理毕竟太被动,因为本机房的F5比较空闲,运维利用F5来挡攻击,采用方式:让客户端先和F5三次握手,连接建立之后F5才转发到后端业务服务器。后来被攻击时F5上看到的现象:
1. 连接数比平时多了500万,攻击停止后恢复。
2. 修改F5上我们业务的VS模式后,F5的CPU消耗比平时多7%,攻击停止后恢复。
3. 用F5挡效果明显,后来因攻击无效后,用户很少来攻击了,毕竟攻击也是有成本的。
5. 调整系统参数挡攻击
没有F5这种高级且昂贵的设备怎么办?我测试过以下参数组合能明显减小影响,准备以后不用F5抗攻击。
第一个参数tcp_synack_retries = 0是关键,表示回应第二个握手包(SYN+ACK包)给客户端IP后,如果收不到第三次握手包(ACK包)后,不进行重试,加快回收“半连接”,不要耗光资源。
不修改这个参数,模拟攻击,10秒后被攻击的80端口即无法服务,机器难以ssh登录; 用命令netstat -na |grep SYN_RECV检测“半连接”hold住180秒;
修改这个参数为0,再模拟攻击,持续10分钟后被攻击的80端口都可以服务,响应稍慢些而已,只是ssh有时也登录不上;检测“半连接”只hold住3秒即释放掉。
修改这个参数为0的副作用:网络状况很差时,如果对方没收到第二个握手包,可能连接服务器失败,但对于一般网站,用户刷新一次页面即可。这些可以在高峰期或网络状况不好时tcpdump抓包验证下。
根据以前的抓包经验,这种情况很少,但为了保险起见,可以只在被tcp洪水攻击时临时启用这个参数。
tcp_synack_retries默认为5,表示重发5次,每次等待30~40秒,即“半连接”默认hold住大约180秒。详细解释:
an SYN request. In other words, this tells the system how many times to try to establish a passive
TCP connection that was started by another host.
This variable takes an integer value, but should under no circumstances be larger than 255 for the
same reasons as for the tcp_syn_retries variable. Each retransmission will take aproximately 30-40
seconds. The default value of the tcp_synack_retries variable is 5, and hence the default timeout
of passive TCP connections is aproximately 180 seconds.
之所以可以把tcp_synack_retries改为0,因为客户端还有tcp_syn_retries参数,默认是5,即使服务器端没有重发SYN+ACK包,客户端也会重发SYN握手包。详细解释:
packet for an active TCP connection attempt.
This variable takes an integer value, but should not be set higher than 255 since each
retransmission will consume huge amounts of time as well as some amounts of bandwidth. Each
connection retransmission takes aproximately 30-40 seconds. The default setting is 5, which
would lead to an aproximate of 180 seconds delay before the connection times out.
第二个参数net.ipv4.tcp_max_syn_backlog = 200000也重要,具体多少数值受限于内存。
以下配置,第一段参数是最重要的,第二段参数是辅助的,其余参数是其他作用的:
# vi /etc/sysctl.conf
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#最关键参数,默认为5,修改为0 表示不要重发
net.ipv4.tcp_synack_retries = 0
#半连接队列长度
net.ipv4.tcp_max_syn_backlog = 200000
#系统允许的文件句柄的最大数目,因为连接需要占用文件句柄
fs.file-max = 819200
#用来应对突发的大并发connect 请求
net.core.somaxconn = 65536
#最大的TCP 数据接收缓冲(字节)
net.core.rmem_max = 1024123000
#最大的TCP 数据发送缓冲(字节)
net.core.wmem_max = 16777216
#网络设备接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
net.core.netdev_max_backlog = 165536
#本机主动连接其他机器时的端口分配范围
net.ipv4.ip_local_port_range = 10000 65535
# ……省略其它……
|
使配置生效:
# sysctl -p
注意,以下参数面对外网时,不要打开。因为副作用很明显,具体原因请google,如果已打开请显式改为0,然后执行sysctl -p关闭。因为经过试验,大量TIME_WAIT状态的连接对系统没太大影响:
|
1
2
3
4
5
6
7
8
|
#当出现 半连接 队列溢出时向对方发送syncookies,调大 半连接 队列后没必要
net.ipv4.tcp_syncookies = 0
#TIME_WAIT状态的连接重用功能
net.ipv4.tcp_tw_reuse = 0
#时间戳选项,与前面net.ipv4.tcp_tw_reuse参数配合
net.ipv4.tcp_timestamps = 0
#TIME_WAIT状态的连接回收功能
net.ipv4.tcp_tw_recycle = 0
|
为了处理大量连接,还需改大另一个参数:
# vi /etc/security/limits.conf
在底下添加一行表示允许每个用户都最大可打开409600个文件句柄(包括连接):
* – nofile 409600
6. 参考资料
文件句柄不要超过系统限制/usr/include/linux/fs.h,相关链接: http://blog.yufeng.info/archives/1380
#define NR_OPEN (1024*1024) /* Absolute upper limit on fd num */
内核参数详细解释:http://www.frozentux.net/ipsysctl-tutorial/chunkyhtml/tcpvariables.html
7. 结束语
TCP洪水攻击还没完美解决方案,希望本文对您有所帮助,让您快速了解。
http://xficc.blog.51cto.com/1189288/1605869
iptables 指令
语法:
iptables [-t table] command [match] [-j target/jump]
-t 参数用来指定规则表,内建的规则表有三个,分别是:nat、mangle 和 filter,
当未指定规则表时,则一律视为是 filter。
各个规则表的功能如下:
nat 此规则表拥有 Prerouting 和 postrouting 两个规则链,主要功能为进行一对一、一对多、多对多等网址转译工作(SNATDNAT),由于转译工作的特性,需进行目的地网址转译的封包,就不需要进行来源网址转译,反之亦然,因此为了提升改写封包的率,在防火墙运作时,每个封包只会经过这个规则表一次。如果我们把封包过滤的规则定义在这个数据表里,将会造成无法对同一包进行多次比对,因此这个规则表除了作网址转译外,请不要做其它用途。
mangle 此规则表拥有 Prerouting、FORWARD 和 postrouting 三个规则链。除了进行网址转译工作会改写封包外,在某些特殊应用可能也必须去改写封包(TTL、TOS)或者是设定 MARK(将封包作记号,以进行后续的过滤),这时就必须将这些工作定义在 mangle 规则表中,由于使用率不高,我们不打算在这里讨论 mangle 的用法。
filter 这个规则表是预设规则表,拥有 INPUT、FORWARD 和 OUTPUT 三个规则链,这个规则表顾名思义是用来进行封包过滤的理动作(例如:DROP、 LOG、 ACCEPT 或 REJECT),我们会将基本规则都建立在此规则表中。
主要包含:: 命令表 用来增加(-A、-I)删除(-D)修改(-R)查看(-L)规则等;
常用参数 用来指定协议(-p)、源地址(-s)、源端口(--sport)、目的地址(-d)、目的端口(--dport)、
进入网卡(-i)、出去网卡(-o)等设定包信息(即什么样的包);
用来描述要处理包的信息。
常用处理动作 用 -j 来指定对包的处理(ACCEPT、DROP、REJECT、REDIRECT等)。
1、常用命令列表: 常用命令(-A追加规则、-D删除规则、-R修改规则、-I插入规则、-L查看规则)
命令 -A, --append
范例 iptables -A INPUT ...
说明 新增规则(追加方式)到某个规则链(这里是INPUT规则链)中,该规则将会成为规则链中的最后一条规则。
命令 -D, --delete
范例 iptables -D INPUT --dport 80 -j DROP
iptables -D INPUT 1
说明 从某个规则链中删除一条规则,可以输入完整规则,或直接指定规则编号加以删除。
命令 -R, --replace
范例 iptables -R INPUT 1 -s 192.168.0.1 -j DROP
说明 取代现行规则,规则被取代后并不会改变顺序。(1是位置)
命令 -I, --insert
范例 iptables -I INPUT 1 --dport 80 -j ACCEPT
说明 插入一条规则,原本该位置(这里是位置1)上的规则将会往后移动一个顺位。
命令 -L, --list
范例 iptables -L INPUT
说明 列出某规则链中的所有规则。
命令 -F, --flush
范例 iptables -F INPUT
说明 删除某规则链(这里是INPUT规则链)中的所有规则。
命令 -Z, --zero
范例 iptables -Z INPUT
说明 将封包计数器归零。封包计数器是用来计算同一封包出现次数,是过滤阻断式攻击不可或缺的工具。
命令 -N, --new-chain
范例 iptables -N allowed
说明 定义新的规则链。
命令 -X, --delete-chain
范例 iptables -X allowed
说明 删除某个规则链。
命令 -P, --policy
范例 iptables -P INPUT DROP
说明 定义过滤政策。 也就是未符合过滤条件之封包,预设的处理方式。
命令 -E, --rename-chain
范例 iptables -E allowed disallowed
说明 修改某自订规则链的名称。
2、常用封包比对参数:(-p协议、-s源地址、-d目的地址、--sport源端口、--dport目的端口、-i 进入网卡、-o 出去网卡)
参数 -p, --protocol (指定协议)
范例 iptables -A INPUT -p tcp (指定协议) -p all 所有协议, -p !tcp 去除tcp外的所有协议。
说明 比对通讯协议类型是否相符,可以使用 ! 运算子进行反向比对,例如:-p ! tcp ,
意思是指除 tcp 以外的其它类型,包含udp、icmp ...等。如果要比对所有类型,则可以使用 all 关键词,例如:-p all。
参数 -s, --src, --source (指定源地址,指定源端口--sport)
例如: iptables -A INPUT -s 192.168.1.1
说明 用来比对封包的来源 IP,可以比对单机或网络,比对网络时请用数字来表示屏蔽,
例如:-s 192.168.0.0/24,比对 IP 时可以使用 ! 运算子进行反向比对,
例如:-s ! 192.168.0.0/24。
参数 -d, --dst, --destination (指定目的地址,指定目的端口--dport)
例如: iptables -A INPUT -d 192.168.1.1
说明 用来比对封包的目的地 IP,设定方式同上。
参数 -i, --in-interface (指定入口网卡) -i eth+ 所有网卡
例如: iptables -A INPUT -i eth0
说明 用来比对封包是从哪片网卡进入,可以使用通配字符 + 来做大范围比对,
例如:-i eth+ 表示所有的 ethernet 网卡,也以使用 ! 运算子进行反向比对,
例如:-i ! eth0。
参数 -o, --out-interface (指定出口网卡)
例如: iptables -A FORWARD -o eth0
说明 用来比对封包要从哪片网卡送出,设定方式同上。
参数 --sport, --source-port (源端口)
例如: iptables -A INPUT -p tcp --sport 22
说明 用来比对封包的来源端口号,可以比对单一埠,或是一个范围,
例如:--sport 22:80,表示从 22 到 80 端口之间都算是符合件,
如果要比对不连续的多个埠,则必须使用 --multiport 参数,详见后文。比对埠号时,可以使用 ! 运算子进行反向比对。
参数 --dport, --destination-port (目的端口)
例如: iptables -A INPUT -p tcp --dport 22
说明 用来比对封包的目的端口号,设定方式同上。
参数 --tcp-flags (只过滤TCP中的一些包,比如SYN包,ACK包,FIN包,RST包等等)
例如: iptables -p tcp --tcp-flags SYN,FIN,ACK SYN
说明 比对 TCP 封包的状态旗号,参数分为两个部分,第一个部分列举出想比对的旗号,
第二部分则列举前述旗号中哪些有被设,未被列举的旗号必须是空的。TCP 状态旗号包括:SYN(同步)、ACK(应答)、
FIN(结束)、RST(重设)、URG(紧急)PSH(强迫推送) 等均可使用于参数中,除此之外还可以使用关键词 ALL 和
NONE 进行比对。比对旗号时,可以使用 ! 运算子行反向比对。
参数 --syn
例如: iptables -p tcp --syn
说明 用来比对是否为要求联机之 TCP 封包,与 iptables -p tcp --tcp-flags SYN,
FIN,ACK SYN 的作用完全相同,如果使用 !运算子,可用来比对非要求联机封包。
参数 -m multiport --source-port
例如: iptables -A INPUT -p tcp -m multiport --source-port 22,53,80,110
说明 用来比对不连续的多个来源埠号,一次最多可以比对 15 个埠,可以使用 !
运算子进行反向比对。
参数 -m multiport --destination-port
例如: iptables -A INPUT -p tcp -m multiport --destination-port 22,53,80,110
说明 用来比对不连续的多个目的地埠号,设定方式同上。
参数 -m multiport --port
例如: iptables -A INPUT -p tcp -m multiport --port 22,53,80,110
说明 这个参数比较特殊,用来比对来源埠号和目的埠号相同的封包,设定方式同上。
注意:在本范例中,如果来源端口号为 80目的地埠号为 110,这种封包并不算符合条件。
参数 --icmp-type
例如: iptables -A INPUT -p icmp --icmp-type 8
说明 用来比对 ICMP 的类型编号,可以使用代码或数字编号来进行比对。
请打 iptables -p icmp --help 来查看有哪些代码可用。
参数 -m limit --limit
例如: iptables -A INPUT -m limit --limit 3/hour
说明 用来比对某段时间内封包的平均流量,上面的例子是用来比对:每小时平均流量是
否超过一次 3 个封包。 除了每小时平均次外,也可以每秒钟、每分钟或每天平均一次,
默认值为每小时平均一次,参数如后: /second、 /minute、/day。 除了进行封数量的
比对外,设定这个参数也会在条件达成时,暂停封包的比对动作,以避免因骇客使用洪水
攻击法,导致服务被阻断。
参数 --limit-burst
范例 iptables -A INPUT -m limit --limit-burst 5
说明 用来比对瞬间大量封包的数量,上面的例子是用来比对一次同时涌入的封包是否超
过 5 个(这是默认值),超过此上限的封将被直接丢弃。使用效果同上。
参数 -m mac --mac-source
范例 iptables -A INPUT -m mac --mac-source 00:00:00:00:00:01
说明 用来比对封包来源网络接口的硬件地址,这个参数不能用在 OUTPUT 和 Postrouting规则炼上,这是因为封包要送出到网后,才能由网卡驱动程序透过 ARP 通讯协议查出目的地的 MAC 地址,所以 iptables 在进行封包比对时,并不知道封包会送到个网络接口去。
参数 --mark
范例 iptables -t mangle -A INPUT -m mark --mark 1
说明 用来比对封包是否被表示某个号码,当封包被比对成功时,我们可以透过 MARK 处理动作,将该封包标示一个号码,号码最不可以超过 4294967296。
参数 -m owner --uid-owner
范例 iptables -A OUTPUT -m owner --uid-owner 500
说明 用来比对来自本机的封包,是否为某特定使用者所产生的,这样可以避免服务器使用
root 或其它身分将敏感数据传送出,可以降低系统被骇的损失。可惜这个功能无法比对出
来自其它主机的封包。
参数 -m owner --gid-owner
范例 iptables -A OUTPUT -m owner --gid-owner 0
说明 用来比对来自本机的封包,是否为某特定使用者群组所产生的,使用时机同上。
参数 -m owner --pid-owner
范例 iptables -A OUTPUT -m owner --pid-owner 78
说明 用来比对来自本机的封包,是否为某特定行程所产生的,使用时机同上。
参数 -m owner --sid-owner
范例 iptables -A OUTPUT -m owner --sid-owner 100
说明 用来比对来自本机的封包,是否为某特定联机(Session ID)的响应封包,使用时
机同上。
参数 -m state --state
范例 iptables -A INPUT -m state --state RELATED,ESTABLISHED
说明 用来比对联机状态,联机状态共有四种:INVALID、ESTABLISHED、NEW 和 RELATED。
INVALID 表示该封包的联机编号(Session ID)无法辨识或编号不正确。
ESTABLISHED 表示该封包属于某个已经建立的联机。
NEW 表示该封包想要起始一个联机(重设联机或将联机重导向)。
RELATED 表示该封包是属于某个已经建立的联机,所建立的新联机。例如:FTP-DATA 联机必定是源自某个 FTP 联机。
3、常用的处理动作: (-j 指定对满足条件包的处理,常用动作有ACCEPT接受报、DROP丢弃报、REJECT丢弃报并通知对方、REDIRECT重定向包等)
-j 参数用来指定要进行的处理动作,常用的处理动作包括:ACCEPT、REJECT、DROP、REDIRECT、MASQUERADE、LOG、DNAT、SNAT、MIRROR、QUEUE、RETURN、MARK,分别说明如下:
ACCEPT 将封包放行,进行完此处理动作后,将不再比对其它规则,直接跳往下一个规则链(natostrouting)。
REJECT 拦阻该封包,并传送封包通知对方,可以传送的封包有几个选择:ICMP port-unreachable、ICMP echo-reply 或是 tcp-reset(这个封包会要求对方关闭联机),进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
例如:iptables -A FORWARD -p TCP --dport 22 -j REJECT --reject-with tcp-reset
DROP 丢弃封包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
REDIRECT 将封包重新导向到另一个端口(PNAT),进行完此处理动作后,将会继续比对其它规则。
这个功能可以用来实作通透式porxy 或用来保护 web 服务器。
例如:iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
MASQUERADE 改写封包来源 IP 为防火墙 NIC IP,可以指定 port 对应的范围,进行完此处理动作后,直接跳往下一个规则(mangleostrouting)。这个功能与 SNAT 略有不同,当进行 IP 伪装时,不需指定要伪装成哪个 IP,IP 会从网卡直接读,当使用拨接连线时,IP 通常是由 ISP 公司的 DHCP 服务器指派的,这个时候 MASQUERADE 特别有用。
例如:iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1024-31000
LOG 将封包相关讯息纪录在 /var/log 中,详细位置请查阅 /etc/syslog.conf 组态档,进行完此处理动作后,将会继续比对其规则。
例如:iptables -A INPUT -p tcp -j LOG --log-prefix "INPUT packets"
SNAT 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则(mangleostrouting)。
例如:iptables -t nat -A POSTROUTING -p tcp-o eth0 -j SNAT --to-source 194.236.50.155-194.236.50.160:1024-32000
DNAT 改写封包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规炼(filter:input 或 filter:forward)。
例如:iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.1-192.168.1.10:80-100
MIRROR 镜射封包,也就是将来源 IP 与目的地 IP 对调后,将封包送回,进行完此处理动作后,将会中断过滤程序。
QUEUE 中断过滤程序,将封包放入队列,交给其它程序处理。透过自行开发的处理程序,可以进行其它应用,
例如:计算联机费......等。
RETURN 结束在目前规则炼中的过滤程序,返回主规则炼继续过滤,如果把自订规则炼看成是一个子程序,那么这个动作,就相当提早结束子程序并返回到主程序中。
MARK 将封包标上某个代号,以便提供作为后续过滤的条件判断依据,进行完此处理动作后,将会继续比对其它规则。
例如:iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 2
四.拓展模块
1.按来源MAC地址匹配
# iptables -t filter -A FORWARD -m --mac-source 00:02:b2:03:a5:f6 -j DROP
拒绝转发来自该MAC地址的数据包
2.按多端口或连续端口匹配
20: 表示20以后的所有端口
20:100 表示20到100的端口
:20 表示20之前的所有端口
-m multiport [--prots, --sports,--dports]
例子:
# iptables -A INPUT -p tcp -m multiport --dports 21,20,25,53,80 -j ACCEPT 【多端口匹配】
# iptables -A INPUT -p tcp --dport 20: -j ACCEPT
# iptables -A INPUT -p tcp --sport 20:80 -j ACCEPT
# iptables -A INPUT -p tcp --sport :80 -j ACCEPT
3.还可以按数据包速率和状态匹配
-m limit --limit 匹配速率 如: -m limit --limit 50/s -j ACCEPT
-m state --state 状态 如: -m state --state INVALID,RELATED -j ACCEPT
4.还可以限制链接数
-m connlimit --connlimit-above n 限制为多少个
例如:
iptables -I FORWARD -p tcp -m connlimit --connlimit-above 9 -j DROP //表示限制链接数最大为9个
5、模拟随机丢包率
iptables -A FORWARD -p icmp -m statistic --mode random --probability 0.31 -j REJECT //表示31%的丢包率
或者
-m random --average 5 -j DROP 表示模拟丢掉5%比例的包
相关知识:
Linux 中延时模拟
设置延时 3s :
tc qdisc add dev eth0 root netem delay 3000ms
可以在 3000ms 后面在加上一个延时,比如 ’3000ms 200ms‘表示 3000ms ± 200ms ,延时范围 2800 – 3200 之间.
结果显示如下
Linux 中丢包模拟
设置丢包 50% ,iptables 也可以模拟这个,但一下不记的命令了,下次放上来:
tc qdisc change dev eth0 root netem loss 50%
上面的设丢包,如果给后面的 50% 的丢包比率修改成 ’50% 80%’ 时,这时和上面的延时不一样,这是指丢包比率为 50-80% 之间。
本文出自 “智能化未来_XFICC” 博客,请务必保留此出处http://xficc.blog.51cto.com/1189288/1605869
http://blog.sina.com.cn/s/blog_56c8a4cc0100hfjy.html
前一版地址:http://bbs.dualwan.cn/thread-12192-1-1.html
PS:其实ZD的dualwan的QOS已经很好了,但是不同的人要求不同,
我这个脚本是专为miniISP多机共享所写。改脚本仅仅适用于dualwan,其他固件或linux PC可能需要改动。
仍然是单WAN的,不打算写多WAN的,多WAN的先飘过。
主要变化有:
1.小包定义发生变化:
上传数据包中长度小于128Byte并且状态为ESTABLISHED的数据包
下载数据包中长度小于256Byte并且状态为ESTABLISHED的数据包
这个ESTABLISHED是什么东东呢?
解释:iptables中数据包有INVALID,ESTABLISHED,NEW,RELATED,UNTRACKED等状态。
具体解释:http://man.chinaunix.net/network ... html#USERLANDSTATES
这个ESTABLISHED指连接已经完全建立的数据包了,而NEW指新建一个连接所使用的第一个数据包。
这样,就排除了那些状态为NEW的小包。
好处:有些人总是热衷于“修改XP最大连接数”来提高BT下载速率。其实这个所谓的“最大连接数”是指“最大并发连接数”,
也就是XP每秒能够发送状态为NEW的数据包,默认值是10。有些垃圾的BT软件将其修改为1000,这样庞大的连接数将会导致
瞬间上传速率非常大,如果将其优先级设置太高,将会导致网络延迟的震荡(一会高一会低)。
PS:“修改XP最大连接数”是无法提高BT下载的速率的,最多可以提高达到最大速率的时间。比如说不修改30秒达到最大速率,修改
后可能10秒就达到最大速率。但是会带来操作系统不稳定,路由器压力增大,蠕虫攻击,网络延迟震荡等不良后果。
微软在IT业混了几十年,从来就不提倡所谓的“修改最大连接数”。
2.不再对利用web端口进行下载BT数据包进行单独的分类,直接进入IP分类。
但正常的web浏览仍然具有较高的优先级。
3.游戏爆发的定义:
当某个内网IP的速率小于10KB/S的时候,那么该IP的数据包进入“游戏爆发队列”。时间为5秒。
“游戏爆发队列”的优先级仅仅低于“小包队列”
对于那些只玩游戏不下载的IP有帮助。
4.需要修改的参数减少,特殊队列的速率直接用总速率计算,不用用户干预。
5.对特殊IP改变限速规则的方法作了举例说明。
6.连接数限制,单IP限速等没有改变,仅仅做了一些效率优化
用法:打开路由器web管理界面,把脚本粘贴到“系统管理----脚本设置----防火墙----保存”,保存之后重启路由器。
(其实不重启也可以,只要切换到“新增功能---IPID调整----保存”,保存之后,脚本即可生效)
注意最好不要同时开启其它QOS.
可修改参数说明:
网段号:UIP,NET
IPS="2",IPE="8"
开始和结束IP192.168.1.2---192.168.1.8
UP=35,DOWN=180
总上传速率35KB/S,总下载速率180KB/S
UPLOADR=1,UPLOADC=8
单IP保证上传速率1KB/S,最大上传速率8KB/S
DOWNLOADR=$(($DOWN/$((IPE-IPS+5)))),DOWNLOADC=$(($DOWN*80/100))
DOWNLOADR是单IP保证下载速率,DOWNLOADC是最大下载速率。
已经由总下载速率DOWN计算,可自行修改为指定数字。
参数修改建议:
1.总带宽最好设小点,以保证更好的网络延迟。
比如2MADSL实际下载可达205KB/S我设180KB/S。实际上传45KB/S我设置35KB/S。
PS:上传速率对网络延迟的影响比下载更大。
2.修改变量时候注意引号和逗号是英文的,空格不要乱加,一旦错误将导致脚本运行异常
3.保证速率不要调得过大,否则反而缺少“保证”
改变特殊IP限速规则:
(0--7,数字越小优先级越高)普通IP的优先级是5,小包的优先级是0,游戏爆发的优先级是1,web浏览的优先级是3
如果要把192.168.1.5限速为:保证上传5KB/S,最大上传20KB/S,保证下载30KB/S,最大下载180KB/S,并且改IP优先级是4,
只需要在脚本的最后加上:
tc class replace dev imq1 parent 1:1 classid 1:5 htb rate 5kbps ceil 20kbpskbps prio 4
tc class replace dev imq0 parent 1:1 classid 1:5 htb rate 30kbps ceil 180kbpskbps prio 4
tc qdisc replace dev imq1 parent 1:5 handle 5: sfq perturb 15
tc qdisc replace dev imq0 parent 1:5 handle 5: sfq perturb 15
其中1:5,5:和IP尾数相关(因为192.168.1.5的尾数是5),prio 4表示优先级是4(比一般IP优先级高)
再比如要把经常BT下载的192.168.1.7限速:保证上传1KB/S,最大上传5KB/S,保证下载5KB/S,最大下载50KB/S,并且改IP优先级是6,
只需要在脚本的最后加上:
tc class replace dev imq1 parent 1:1 classid 1:7 htb rate 1kbps ceil 5kbpskbps prio 6
tc class replace dev imq0 parent 1:1 classid 1:7 htb rate 5kbps ceil 50kbpskbps prio 6
tc qdisc replace dev imq1 parent 1:7 handle 7: sfq perturb 15
tc qdisc replace dev imq0 parent 1:7 handle 7: sfq perturb 15
依次类推,想加的特殊IP限速规则都可以添加。
脚本如下:(以#开头的说明性文字可以删除,第1行除外 好用的吼下,不好用自己闷头揣摩,或则当我是骗子也可以
好用的吼下,不好用自己闷头揣摩,或则当我是骗子也可以 )
)
#变量初始化(速率单位是KB/S)
UIP="192.168.1."
NET="192.168.1.0/24"
IPS="2"
IPE="8"
UP=35
DOWN=180
UPLOADR=1
UPLOADC=8
DOWNLOADR=$(($DOWN/$((IPE-IPS+5))))
DOWNLOADC=$(($DOWN*80/100))
#装载核心模块,创建QOS专用链
insmod imq
insmod ipt_IMQ
insmod ipt_length.o
insmod ipt_hashlimit.o
ifconfig imq1 up
ifconfig imq0 up
iptables -t mangle -N QOSDOWN
iptables -t mangle -N QOSUP
iptables -t mangle -I FORWARD -s $NET -j QOSUP
iptables -t mangle -I FORWARD -d $NET -j QOSDOWN
iptables -t mangle -A QOSDOWN -j IMQ --todev 0
iptables -t mangle -A QOSUP -j IMQ --todev 1
#在5秒内平均下载速率小于10KB/S的IP进入高优先级队列253
iptables -t mangle -N GAME_BURST
iptables -t mangle -A QOSDOWN -m length --length 256: -j GAME_BURST
iptables -t mangle -A GAME_BURST -m hashlimit --hashlimit 10/sec --hashlimit-burst 100 --hashlimit-mode dstip --hashlimit-name game_burst -j RETURN
iptables -t mangle -A GAME_BURST -m recent --rdest --name game_burst --set -j RETURN
iptables -t mangle -A QOSDOWN -m recent --rdest --name game_burst ! --rcheck --seconds 5 -j MARK --set-mark-return 253
iptables -t mangle -A QOSDOWN -p tcp -m mport --sports 80,443 -j BCOUNT
iptables -t mangle -A QOSDOWN -p tcp -m mport --sports 80,443 -m bcount --range :307200 -j MARK --set-mark-return 255
iptables -t mangle -A QOSDOWN -m state --state ESTABLISHED -m length --length :256 -j MARK --set-mark-return 254
iptables -t mangle -A QOSUP -p tcp -m mport --dports 80,443 -j BCOUNT
iptables -t mangle -A QOSUP -p tcp -m mport --dports 80,443 -m bcount --range :204800 -j MARK --set-mark-return 255
iptables -t mangle -A QOSUP -m state --state ESTABLISHED -m length --length :128 -j MARK --set-mark-return 254
iptables -t mangle -I QOSUP -m state --state NEW -p udp --dport 53 -j RETURN
iptables -t mangle -A QOSDOWN -j MARK --ipaddr 1
iptables -t mangle -A QOSUP -j MARK --ipaddr 0
#根队列初始化
tc qdisc del dev imq0 root
tc qdisc del dev imq1 root
tc qdisc add dev imq0 root handle 1: htb
tc qdisc add dev imq1 root handle 1: htb
tc class add dev imq1 parent 1: classid 1:1 htb rate $((UP))kbps
tc class add dev imq0 parent 1: classid 1:1 htb rate $((DOWN))kbps
#小包,web浏览和游戏爆发队列限速
tc class add dev imq1 parent 1:1 classid 1:254 htb rate $((UP))kbps quantum 12000 prio 0
tc class add dev imq1 parent 1:1 classid 1:255 htb rate $((UP/5))kbps ceil $((UP/2))kbps quantum 2000 prio 3
tc filter add dev imq1 parent 1:0 protocol ip prio 5 handle 255 fw flowid 1:255
tc filter add dev imq1 parent 1:0 protocol ip prio 4 handle 254 fw flowid 1:254
tc class add dev imq0 parent 1:1 classid 1:254 htb rate $((DOWN))kbps quantum 12000 prio 0
tc class add dev imq0 parent 1:1 classid 1:255 htb rate $((DOWN*20/100))kbps ceil $((DOWN*80/100))kbps prio 3
tc filter add dev imq0 parent 1:0 protocol ip prio 5 handle 255 fw flowid 1:255
tc filter add dev imq0 parent 1:0 protocol ip prio 4 handle 254 fw flowid 1:254
tc class add dev imq0 parent 1:1 classid 1:253 htb rate $((DOWN/2))kbps quantum 5000 prio 1
tc filter add dev imq0 parent 1:0 protocol ip prio 5 handle 253 fw flowid 1:253
#所有普通IP单独限速
i=$IPS;
while [ $i -le $IPE ]
do
tc class add dev imq1 parent 1:1 classid 1:$i htb rate $((UPLOADR))kbps ceil $((UPLOADC))kbps quantum 1000 prio 5
tc qdisc add dev imq1 parent 1:$i handle $i: sfq perturb 15
tc filter add dev imq1 parent 1:0 protocol ip prio 6 handle $i fw classid 1:$i
tc class add dev imq0 parent 1:1 classid 1:$i htb rate $((DOWNLOADR))kbps ceil $((DOWNLOADC))kbps quantum 1000 prio 5
tc qdisc add dev imq0 parent 1:$i handle $i: sfq perturb 15
tc filter add dev imq0 parent 1:0 protocol ip prio 6 handle $i fw classid 1:$i
i=`expr $i + 1`
done
#每IP限制TCP连接数100,UDP连接数150,并且对DNS,WEB,QQ等端口例外
iptables -t mangle -N CONNLMT
iptables -t mangle -I FORWARD -m state --state NEW -s $NET -j CONNLMT
iptables -t mangle -A CONNLMT -p tcp -m connlimit --connlimit-above 100 -j DROP
iptables -t mangle -A CONNLMT -p ! tcp -m connlimit --connlimit-above 150 -j DROP
iptables -t mangle -I CONNLMT -p udp -m mport --dports 53,4000:8000 -j RETURN
iptables -t mangle -I CONNLMT -p tcp -m mport --dports 20:23,25,80,110,443 -j RETURN
#改变特殊IP限速规则(自己依照说明添加)
儿童节发布K26支持任意网段限速QOS脚本,打得openwrt满地找牙
[i=s] 本帖最后由 zhoutao0712 于 2011-6-1 02:00 编辑 [/i]儿童节来临之际,特发布K26核心 QOS脚本,支持任意网段限速(包括pppoe-server以及pptp-server),打得openwrt势力满地找牙。
[color=Red]本脚本为dualwan K26专用,注意看脚本中的说明,同时请先阅读这个帖对某些参数的说明[/color]
[url]http://bbs.dualwan.cn/thread-24602-1-1.html[/url]
欢迎大家试用,保持快乐童心,不要被金钱污染了心灵:lol[code]#Copyright (C) 20010-2011 zhoutao0712
#默认速率为4M ADSL,自己依据实际情况修改
UP=35
DOWN=360
#下面是默认的单IP限制速率
UPLOADR=2
UPLOADC=$((UP*4/10))
DOWNLOADR=15
DOWNLOADC=$((DOWN*7/10))
WAN_IF=$(nvram get wan_iface)
IPM="iptables -t mangle"
modprobe imq;modprobe ipt_IMQ;modprobe ipt_web;modprobe xt_length;modprobe xt_hashlimit
ifconfig imq0 up;ifconfig imq1 up
$IPM -N NEWLMT
$IPM -I PREROUTING -m state --state NEW -j NEWLMT
$IPM -A NEWLMT -i $WAN_IF -j RETURN
$IPM -A NEWLMT -s $(nvram get lan_ipaddr)/24 -d $(nvram get lan_ipaddr)/24 -j RETURN
$IPM -A NEWLMT -p udp -m mport --dports 53,67,68,1900 -j RETURN
$IPM -A NEWLMT -p udp -m connlimit --connlimit-above 100 -j DROP
$IPM -A NEWLMT -p tcp --syn -m connlimit --connlimit-above 200 -j DROP
$IPM -A NEWLMT -m hashlimit --hashlimit-name newlmt --hashlimit-mode srcip --hashlimit 20 -j RETURN
$IPM -A NEWLMT -p tcp --dport 80 -m limit --limit 20 -j RETURN
$IPM -A NEWLMT -j DROP
iptables -N UDPLMT
iptables -I FORWARD -o $WAN_IF -p udp -j UDPLMT
iptables -A UDPLMT -m hashlimit --hashlimit-mode srcip --hashlimit-name udplmt --hashlimit 120 -j RETURN
iptables -A UDPLMT -p udp -m mport --dports 53,8000 -m limit --limit 30 -j RETURN
iptables -A UDPLMT -j DROP
$IPM -N QOSDOWN
$IPM -N QOSUP
$IPM -I FORWARD -i $WAN_IF -j QOSDOWN
$IPM -I INPUT -i $WAN_IF -j QOSDOWN
$IPM -I POSTROUTING -o $WAN_IF -j QOSUP
$IPM -I FORWARD -o $WAN_IF -m hashlimit --hashlimit-mode srcip --hashlimit-name online --hashlimit-htable-expire 150000 --hashlimit 10
$IPM -A QOSDOWN -p udp --sport 53 -j RETURN
$IPM -A QOSUP -p udp --dport 53 -j RETURN
$IPM -A QOSDOWN -p tcp ! --syn -m length --length :100 -j RETURN
$IPM -A QOSUP -p tcp ! --syn -m length --length :80 -j RETURN
$IPM -A QOSDOWN -j IMQ --todev 0
$IPM -A QOSUP -j IMQ --todev 1
$IPM -A PREROUTING -p tcp -m connmark ! --mark 80 -m web --path ".exe$ .rar$ .iso$ .zip$ .rm$ .rmvb$ .wma$ .avi$" -j CONNMARK --set-mark 80
$IPM -A QOSDOWN -m connmark --mark 80 -j MARK --set-mark-return 80
$IPM -A QOSUP -m connmark --mark 80 -j MARK --set-mark-return 80
$IPM -A QOSDOWN -p tcp -m length --length :768 -j MARK --set-mark-return 255
$IPM -A QOSUP -p tcp -m length --length :512 -j MARK --set-mark-return 255
$IPM -A QOSDOWN -p tcp -m mport --sports 80,443,25,110 -j BCOUNT
$IPM -A QOSDOWN -p tcp -m mport --sports 80,443,25,110 -m bcount --range :153600 -j MARK --set-mark-return 254
$IPM -A QOSUP -p tcp -m mport --dports 80,443,25,110 -j BCOUNT
$IPM -A QOSUP -p tcp -m mport --dports 80,443,25,110 -m bcount --range :51200 -j MARK --set-mark-return 254
$IPM -A QOSDOWN -j MARK --set-mark 0
$IPM -A QOSUP -j MARK --set-mark 0
if [ $(cat /tmp/qos_state) -eq 1 ]
then
exit
else
echo 1 >/tmp/qos_state
fi
tc qdisc del dev imq0 root;tc qdisc del dev imq1 root
tc qdisc add dev imq0 root handle 1: htb default 9999
tc qdisc add dev imq1 root handle 1: htb default 9999
tc class add dev imq1 parent 1: classid 1:1 htb rate $((UP))kbps
tc class add dev imq0 parent 1: classid 1:1 htb rate $((DOWN))kbps
tc class add dev imq0 parent 1:1 classid 1:a255 htb rate $((DOWN/4))kbps quantum 15000 prio 1
tc filter add dev imq0 parent 1:0 protocol ip prio 5 handle 255 fw flowid 1:a255
tc class add dev imq1 parent 1:1 classid 1:a255 htb rate $((UP))kbps quantum 15000 prio 1
tc filter add dev imq1 parent 1:0 protocol ip prio 5 handle 255 fw flowid 1:a255
tc class add dev imq0 parent 1:1 classid 1:a254 htb rate $((DOWN/10))kbps ceil $((DOWN*7/10))kbps quantum 8000 prio 3
tc qdisc add dev imq0 parent 1:a254 handle a254 sfq perturb 12
tc filter add dev imq0 parent 1:0 protocol ip prio 10 handle 254 fw flowid 1:a254
tc class add dev imq1 parent 1:1 classid 1:a254 htb rate $((UP/8))kbps ceil $((UP/2))kbps quantum 1500 prio 3
tc qdisc add dev imq1 parent 1:a254 handle a254 sfq perturb 12
tc filter add dev imq1 parent 1:0 protocol ip prio 10 handle 254 fw flowid 1:a254
export MM=1
qos_ip()
{
n=$(echo $1|cut -d '-' -f1|cut -d '.' -f4)
m=$(echo $1|cut -d '-' -f2|cut -d '.' -f4)
NET=$(echo $1|cut -d '.' -f1-3)
while [ $n -le $m ]
do
NN=$(printf "%02x\n" $n)
tc cl ad dev imq0 parent 1:1 classid 1:$MM$NN htb rate $2kbps ceil $3kbps quantum 2000 prio 5
tc qd ad dev imq0 parent 1:$MM$NN handle $MM$NN sfq perturb 12
tc fi ad dev imq0 parent 1: protocol ip prio 200 u32 match ip dst $NET.$n flowid 1:$MM$NN
tc cl ad dev imq1 parent 1:1 classid 1:$MM$NN htb rate $4kbps ceil $5kbps quantum 1500 prio 5
tc qd ad dev imq1 parent 1:$MM$NN handle $MM$NN sfq limit 64 perturb 12
tc fi ad dev imq1 parent 1: protocol ip prio 200 u32 match ip src $NET.$n flowid 1:$MM$NN
n=$((n+1))
done
MM=$((MM+1))
}
zhoutao_qos_ip()
{
case "$2" in
'')
qos_ip $1 $DOWNLOADR $DOWNLOADC $UPLOADR $UPLOADC
;;
*)
qos_ip $1 $2 $3 $4 $5
esac
}
tc class add dev imq1 parent 1:1 classid 1:9999 htb rate 1kbps ceil $((UP/5))kbps quantum 1500 prio 7
tc class add dev imq0 parent 1:1 classid 1:9999 htb rate 2kbps ceil $((DOWN))kbps quantum 1500 prio 7
##* * * * * * * * * 限 速 示 例 * * * * * * * * * * * * * *
##1.如果使用脚本开始处默认的单IP限制速率
zhoutao_qos_ip 192.168.1.100-192.168.1.102
zhoutao_qos_ip 10.0.0.22
##2.如果想自定义限制速率,下面的例子表示192.168.1.2-192.168.1.6的
##保证下载速率,最大下载速率,保证上传速率,最大上传速率依次为
## 20KB/S,120KB/S,2KB/S,12KB/S,注意数字之间的空格
zhoutao_qos_ip 192.168.1.2-192.168.1.6 20 120 2 12
#下面这句不要删掉哦
echo 0 >/tmp/qos_state
#下面是单机在线时候关闭限速的代码
cat >/tmp/qos_scheduler <<"EOF"
echo 1 >/tmp/state_scheduler
if [ $(wc -l </proc/net/ipt_hashlimit/online) -le 1 ]
then
ifconfig imq0 down
ifconfig imq1 down
exit
fi
if [ $(ifconfig |grep -c imq0) -eq 0 ]
then
ifconfig imq0 up
ifconfig imq1 up
fi
EOF
chmod +x /tmp/qos_scheduler
cru d qos_scheduler
echo -e '*/1 * * * * sh /tmp/qos_scheduler #qos_scheduler#' >>/tmp/var/spool/cron/crontabs/root
[/code]
转载本站文章请注明,转载自:扶凯[http://www.php-oa.com]
本文链接: http://www.php-oa.com/2009/06/23/linux_tc.html
公司一台服务器,网络环境太高,那台服务器和源服务器连接下载,就跑到400M-500M,为了控制一下,所以研究了一下TC。来做流量控制.给他控制到小点,不要让这一台占了所有的网络。TC很是强大啊,很多所谓的硬件路由器,都是基于这个做的。
TC介绍
在 linux 中,TC 有二种控制方法 CBQ 和 HTB.HTB 是设计用来替换 CBQ 的。它是一个层次式的过滤框架.
TC包括三个基本的构成块:
队列规定 qdisc(queueing discipline )、类(class)和分类器(Classifiers)
TC 中的队列(queueing discipline):
用来实现控制网络的收发速度.通过队列,linux可以将网络数据包缓存起来,然后根据用户的设置,在尽量不中断连接(如 TCP)的前提下来平滑网络流量.需要注意的是,linux对接收队列的控制不够好,所以我们一般只用发送队列,即“控发不控收”.它封装了其他两个主要 TC组件(类和分类器)。内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然后,内核会 尽可能多地从qdisc里面取出数据包,把它们交给网络适配器驱动模块。
最简单的 QDisc 是 pfifo 它不对进入的数据包做任何的处理,数据包采用先入先出的方式通过队列。不过,它会保存网络接口一时无法处理的数据包。
队列规则包括FIFO(先进先出),RED(随机早期探测),SFQ(随机公平队列)和令牌桶(Token Bucket),类基队列(CBQ),CBQ 是一种超级队列,即它能够包含其它队列(甚至其它CBQ)。
TC 中的 Class 类
class 用来表示控制策略.很显然,很多时候,我们很可能要对不同的IP实行不同的流量控制策略,这时候我们就得用不同的class来表示不同的控制策略了.
TC 中的 Filter 规则
filter 用来将用户划入到具体的控制策略中(即不同的 class 中).比如,现在,我们想对xxa,xxb两个IP实行不同的控制策略(A,B),这时,我们可用 filter 将 xxa 划入到控制策略 A,将 xxb 划入到控制策略 B,filter 划分的标志位可用 u32 打标功能或 IPtables 的 set-mark (大多使用iptables 来做标记)功能来实现。
目前,TC可以使用的过滤器有:fwmark分类器,u32 分类器,基于路由的分类器和 RSVP 分类器(分别用于IPV6、IPV4)等;其中,fwmark 分类器允许我们使用 Linux netfilter 代码选择流量,而 u32 分类器允许我们选择基于 ANY 头的流量 .需要注意的是,filter (过滤器)是在QDisc 内部,它们不能作为主体。
TC 的应用流程
数据包->iptables(在通过iptables时,iptables根据不同的ip来设置不同的mark)->TC(class)->TC(queue)
应用
假设 eth0 位是服务器的外网网络接口。
开始之前,先要清除 eth0所有队列规则
tc qdisc del dev eth0 root 2> /dev/null > /dev/null
1) 定义最顶层(根)队列规则,并指定 default 类别编号
tc qdisc add dev eth0 root handle 1: htb default 2
2) 定义第一层的 1:1 类别 (速度)
本来是要多定义第二层叶类别,但目前来看,这个应用中就可以了.
tc class add dev eth0 parent 1:1 classid 1:2 htb rate 98mbit ceil 100mbit prio 2 tc class add dev eth0 parent 1:1 classid 1:3 htb rate 1mbit ceil 2mbit prio 2
注:以上就是我们控制输出服务器的速度,一个为98M,一个为 2M.
rate: 是一个类保证得到的带宽值.如果有不只一个类,请保证所有子类总和是小于或等于父类.
prio:用来指示借用带宽时的竞争力,prio越小,优先级越高,竞争力越强.
ceil: ceil是一个类最大能得到的带宽值.
同时为了不使一个会话永占带宽,添加随即公平队列sfq.
tc qdisc add dev eth0 parent 1:2 handle 2: sfq perturb 10 tc qdisc add dev eth0 parent 1:3 handle 3: sfq perturb 10
3) 设定过滤器
过滤器可以使用本身的 u32 也可以使用 iptables 来打上标记
指定在root 类 1:0 中,对 192..168.0.2 的过滤,使用 1:2 的规则,来给他 98M 的速度,写法就如下
tc filter add dev eth0 protocol ip parent 1:0 u32 match ip src 192.168.0.2 flowid 1:2 tc filter add dev eth0 protocol ip parent 1:0 u32 match ip src 192.168.0.1 flowid 1:3
如果是所有 ip 写法就如
tc filter add dev eth0 protocol ip parent 1: prio 50 u32 match ip dst 0.0.0.0/0 flowid 1:10
使用 Iptables 来配合过滤器
还可以使用这个方法,但需要借助下面的 iptables 的命令来做标记了
tc filter add dev eth0 parent 1: protocol ip prio 1 handle 2 fw flowid 1:2 tc filter add dev eth0 parent 1: protocol ip prio 1 handle 2 fw flowid 1:3
iptables 只要打上记号就行了
iptables -t mangle -A POSTROUTING -d 192.168.0.2 -j MARK --set-mark 10 iptables -t mangle -A POSTROUTING -d 192.168.0.3 -j MARK --set-mark 20
TC对最对高速度的控制
Rate ceiling 速率限度
参数ceil指定了一个类可以用的最大带宽, 用来限制类可以借用多少带宽.缺省的ceil是和速率一样
这个特性对于ISP是很有用的, 因为他们一般限制被服务的用户的总量即使其他用户没有请求服务.(ISPS 很想用户付更多的钱得到更好的服务) ,注根类是不允许被借用的, 所以没有指定ceil
注: ceil的数值应该至少和它所在的类的速率一样高, 也就是说ceil应该至少和它的任何一个子类一样高
Burst 突发
网络硬件只能在一个时间发送一个包这仅仅取决于一个硬件的速率. 链路共享软件可以利用这个能力动态产生多个连接运行在不同的速度. 所以速率和ceil不是一个即时度量只是一个在一个时间里发送包的平均值. 实际的情况是怎样使一个流量很小的类在某个时间类以最大的速率提供给其他类. burst 和cburst 参数控制多少数据可以以硬件最大的速度不费力的发送给需要的其他类.
如果cburst 小于一个理论上的数据包他形成的突发不会超过ceil 速率, 同样的方法TBF的最高速率也是这样.
你可能会问, 为什么需要bursts . 因为它可以很容易的提高向应速度在一个很拥挤的链路上. 比如WWW 流量是突发的. 你访问主页. 突发的获得并阅读. 在空闲的时间burst将再"charge"一次.
注: burst 和cburst至少要和其子类的值一样大.
TC命令格式:
加入
tc qdisc [ add | change | replace | link ] dev DEV [ parent qdisc-id | root ] [ handle qdisc-id ] qdisc [ qdisc specific parameters ]
tc class [ add | change | replace ] dev DEV parent qdisc-id [ classid class-id ] qdisc [ qdisc specific parameters ]
tc filter [ add | change | replace ] dev DEV [ parent qdisc-id | root ] protocol protocol prio priority filtertype [ filtertype specific parameters ] flowid flow-id
显示
tc [-s | -d ] qdisc show [ dev DEV ]
tc [-s | -d ] class show dev DEV tc filter show dev DEV
查看TC的状态
tc -s -d qdisc show dev eth0
tc -s -d class show dev eth0
删除tc规则
tc qdisc del dev eth0 root
实例
使用 TC 下载限制单个IP 进行速度控制
tc qdisc add dev eth0 root handle 1: htb r2q 1 tc class add dev eth0 parent 1: classid 1:1 htb rate 30mbit ceil 60mbit tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.1.2 flowid 1:1
就可以限制192.168.1.2的下载速度为30Mbit最高可以60Mbit ,其中 r2q,是指没有default的root,使整个网络的带宽没有限制
使用 TC 对整段 IP 进行速度控制
tc qdisc add dev eth0 root handle 1: htb r2q 1 tc class add dev eth0 parent 1: classid 1:1 htb rate 50mbit ceil 1000mbit tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.111.0/24 flowid 1:1
就可以限制192.168.111.0 到255 的带宽为3000k了,实际下载速度为200k左右。
这种情况下,这个网段所有机器共享这200k的带宽。
还可以加入一个sfq(随机公平队列)
tc qdisc add dev eth0 root handle 1: htb r2q 1 tc class add dev eth0 parent 1: classid 1:1 htb rate 3000kbit burst 10k tc qdisc add dev eth0 parent 1:1 handle 10: sfq perturb 10 tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.111.168 flowid 1:1
sfq,他可以防止一个段内的一个ip占用整个带宽。
使用 TC 控制服务器对外的速度为 10M
如下,我要管理一台服务器,只能向外发 10M 的数据
tc qdisc del dev eth0 root tc qdisc add dev eth0 root handle 1: htb tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit ceil 100mbit tc class add dev eth0 parent 1:1 classid 1:10 htb rate 10mbit ceil 10mbit tc qdisc add dev eth0 parent 1:10 sfq perturb 10 tc filter add dev eth0 protocol ip parent 1: prio 2 u32 match ip dst 220.181.xxx.xx/32 flowid 1:1 # 上面这台,让 220.181.xxx.xx/32 这台跑默认的,主要是为了让这个 ip 连接进来不被控制 tc filter add dev eth0 protocol ip parent 1: prio 50 u32 match ip dst 0.0.0.0/0 flowid 1:10 # 默认让所有的流量都从这个通过
参考:http://blog.chinaunix.net/u3/94771/showart_1906064.html
http://liuleijsjx.javaeye.com/blog/402152
tc filter 的handle
设置过滤器,handle是iptables作mark的值,让被iptables在mangle链做了mark的不同的值选择不同的通道classid,而prio是过滤器的优先级别
注:这样我们就告诉内核,数据包会有一个特定的FWMARK标记值(handle x fw),表明它应该送给哪个类(classid x:x)。
lcb注:实际中,也可能是ebtables -t broute -L 中的-j mark来匹配;
例如:
tc qdisc add dev eth0 root handle 1:htb default 91
tc class add dev eth0 parent 1:0 classid1:30 htb rate 2mbit ceil 4mbit prio 2
tc class add dev eth0 parent 1:30 classid 1:31 htbrate 0.5mbit ceil 2mbit prio 3
tc qdisc add dev eth0 parent 1:31 handle 31:sfq perturb 10
iv)接着添加过滤器.
tc filter add dev eth0 parent 1: protocol ipprio 31 handle 31 fw flowid 1:31
v)用iptable打标
iptables -t mangle -I FORWARD 2 -i eth1 -d $IPaddr--j RETURN
再例如:
CODE:
iptables -t mangle -I OUTPUT -o eth1 -p tcp --sport 20 -j MARK --set-mark 0x10000001
iptables -t mangle -I OUTPUT -o eth1 -p tcp --sport 21 -j MARK --set-mark 0x10000001
tc qdisc add dev eth1 root handle 1: htb
tc class add dev eth1 parent 1: classid 1:1 htb rate 1000Mbit ceil 1000Mbit
tc class add dev eth1 parent 1:1 classid 1:11 htb rate 5Mbit ceil 6Mbit
tc qdisc add dev eth1 parent 1:11 handle 11: sfq perturb 10
tc filter add dev eth1 parent 1:0 protocol ip prio 11 handle 0x10000001 fw classid 1:11
1
调度类型 wrr
# tc q s
qdisc prio 1: dev atm0 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
2
调度类型 sp
# tc q s
qdisc htb 1: dev atm0 r2q 50 default 1 direct_packets_stat 0
3 r2q ( 注:可以简单的计算如下: 适合速率=MTC*r2q )
现在是个接触quantums概念的很好的时机.实际上当一些想借用带宽的类服务于其他竞争的类之前相互给定的一定数量的字节, 这个数量被称为quantums . 你应该明白如果一些竞争的类是可以从它的父类那里得到所需的quantums; 精确的指定quantums的数量尽可能的小并其大于MTU是很重要的.
一般你不需要手工指定一个quantums因为HTB会根据计算选择数值.计算类的quantum相对于用r2q参数分配; 它的缺省的值是10因为典型的MTU是1500,缺省值很适合速率为15 kBps (120 kbit).当你创建队列最小的速率指定r2q 1, 比较适合速率为12 kbit;如果你需要手工指定quantum 当你添加或者更改类,如果预想计算的值是不适合的你可以清除日志里的警告. 当你用命令行指定了quantum 类的r2q将被忽略.
如果A和B是不同的客户这个解决方案看起来很好, 但是如果A 付了40kbps 他可能更希望他不用的WWW的带宽可以用在自己的其他服务上而并不想分享个B. 这种需求是可以通过HTB的类的层次得到解决的.
Smallest rate : 16kbit = 2 kilobyt / r2q (=10) = 200. And this is < 1500. So
you get warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 1.2 Mbyte > 60.000. So you get
warnings.
If you do
tc qdisc add dev eth0 root handle 1: htb default 10 r2q 1
Smallest rate : 16kbit = 2kilobyte / r2k = 2000. And this is > 1500. So no
warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 12.5 Mbyte > 60.000. So you get
warnings. But you can overrule the quantum :
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 128kbit burst 2k
quantum 60000
Quantum is used when 2 classes are getting more bandwidth then the rate. So
it's only important for sharing the remaining bandwidth. In that case, each
class may send quantum bytes.
htb控制流量时,当最小速度低于15kbit时,会因为r2q值默认为10,不足2kbyte/r2q<1500,然后就会报错class xxxxx is small. Consider r2q change.
当最大速度为50Mbit时,因为50M=》大于6Mbyte/r2q>=60000,而报错
class xxxxx is Big. Consider r2q change.
解决的方法是调整r2q的值或者把限制改大或调小。如:
tc qdisc add dev eth0 root handle 1: htb default 10 r2q 1
if (!cl->level) {
// 如果是叶子节点, 设置其定额, 当出现赤字时会按定额大小增加
cl->un.leaf.quantum = rtab->rate.rate / q->rate2quantum;
// 如果计算出的定额量太小或太大, 说明rate2quantum参数该调整了, 这就是tc命令中的r2q参数
// 对于不同的带宽, 要选择不同的r2q值
if (!hopt->quantum && cl->un.leaf.quantum < 1000) {
// 定额太小
printk(KERN_WARNING
"HTB: quantum of class %X is small. Consider r2q
cl->classid);
cl->un.leaf.quantum = 1000;
}
if (!hopt->quantum && cl->un.leaf.quantum > 200000) {
// 定额太大
printk(KERN_WARNING
"HTB: quantum of class %X is big. Consider r2q
cl->classid);
cl->un.leaf.quantum = 200000;
}
有道理,试试先
tc qdisc add dev eth0 root handle 1: htb default 11
改为
tc qdisc add dev eth0 root handle 1: htb default 11 r2q 64
warnings 消失
我的是100M带宽
参考:
r2q is "rate to quantum" is used to calculate the quantum for each class : quantum = rate / r2q. Quantum must
be 1500 < quantum < 60000. Otherwise you will get warnings from the kernel. Solution : choose r2q so for each class 1500 < quantum < 60000 Or choose the best r2q you can and specify the quantum manually if you add a class.
Smallest rate : 16kbit = 2 kilobyt / r2q (=10) = 200. And this is < 1500.
So you get warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 1.2 Mbyte > 60.000.
So you get warnings.
If you do
tc qdisc add dev eth0 root handle 1: htb default 10 r2q 1
Smallest rate : 16kbit = 2kilobyte / r2k = 2000. And this is > 1500.
So no warnings.
Biggest rate : 100mbit = 12.5 mbyte / r2q = 12.5 Mbyte > 60.000.
So you get warnings. But you can overrule the quantum :
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 128kbit burst 2k quantum 60000
Quantum is used when 2 classes are getting more bandwidth then the rate. So it's only important for sharing the remaining bandwidth. In that case, each class may send quantum bytes.
4
下载限制单个IP
tc qdisc add dev eth0 root handle 1: htb r2q 1
tc class add dev eth0 parent 1: classid 1:1 htb rate 30mbit ceil 60mbit
tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.1.2 flowid 1:1
就可以限制192.168.1.2的下载速度为30Mbit最高可以60Mbit
r2q,是指没有default的root,使整个网络的带宽没有限制
下载整段IP
tc qdisc add dev eth0 root handle 1: htb r2q 1
tc class add dev eth0 parent 1: classid 1:1 htb rate 50mbit ceil 1000mbit
tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.111.0/24 flowid 1:1
就可以限制192.168.111.0 到255 的带宽为3000k了,实际下载速度为200k左右。
这种情况下,这个网段所有机器共享这200k的带宽。
还可以加入一个sfq(随机公平队列)
tc qdisc add dev eth0 root handle 1: htb r2q 1
tc class add dev eth0 parent 1: classid 1:1 htb rate 3000kbit burst 10k
tc qdisc add dev eth0 parent 1:1 handle 10: sfq perturb 10
tc filter add dev eth0 parent 1: protocol ip prio 16 u32 match ip dst 192.168.111.168 flowid 1:1
sfq,他可以防止一个段内的一个ip占用整个带宽。
5
Rate ceiling 速率限度
参数ceil指定了一个类可以用的最大带宽, 用来限制类可以借用多少带宽。缺省的ceil是和速率一样
这个特性对于ISP是很有用的, 因为他们一般限制被服务的用户的总量即使其他用户没有请求服务。(ISPS 很想用户付更多的钱得到更好的服务) ,注根类是不允许被借用的, 所以没有指定ceil
注: ceil的数值应该至少和它所在的类的速率一样高, 也就是说ceil应该至少和它的任何一个子类一样高
Burst 突发
网络硬件只能在一个时间发送一个包这仅仅取决于一个硬件的速率。 链路共享软件可以利用这个能力动态产生多个连接运行在不同的速度。所以速率和ceil不是一个即时度量只是一个在一个时间里发送包的平均值。实际的情况是怎样使一个流量很小的类在某个时间类以最大的速率提供给其他类。 burst 和cburst 参数控制多少数据可以以硬件最大的速度不费力的发送给需要的其他类。
如果cburst 小于一个理论上的数据包他形成的突发不会超过ceil 速率, 同样的方法TBF的最高速率也是这样。
你可能会问, 为什么需要bursts . 因为它可以很容易的提高向应速度在一个很拥挤的链路上。 比如WWW 流量是突发的。 你访问主页。 突发的获得并阅读。 在空闲的时间burst将再"charge"一次。
注: burst 和cburst至少要和其子类的值一样大。
6
什么是MTU?
MTU 是 Maximum Transmission Unit 的缩写。意思是网络上传送的最大数据包,单位是字节。如果本机的MTU比网关的MTU大,大的数据包就会被拆开来传送,这样会产生很多数据包碎片,增加丢 包率,降低网络速度。把本机的MTU设成比网关的MTU小或相同,就可以减少丢包。不同的接入方式,MTU值是不一样的,下面是常用的几种接入方式默认的 MTU值:
EtherNet (以太网)1500
PPPoE(ADSL) 1492
Dial-up(modem) 576
由此可以看出,一个标准以太网 Frame 是 1500 Bytes,那么我们知道了这一点,可以利用iptables来进行带宽限制
iptables中有个limit模块,遗憾的是他只能限制packet,而不是bytes
但是我们现在已经知道了一个标准Ethernet Frame是1500 Bytes,这样就好做了
下面给大家演示一个限制upload速率的实例(已经通过测试)
# Limit Platinum
iptables -A FORWARD -s 10.39.1.1 -m state --state NEW,ESTABLISHED,RELATED -m limit --limit 20/s -j ACCEPT
iptables -A FORWARD -s 10.39.1.1 -j DROP
当然,用这种方法可以比 tc 更灵活,可以基于 IP、PORT 去进行控制,也可以针对 INPUT/OUTPUT/FORWARD 进行限制
这样唯一不好的是,不一定每个 packet 都是 1500 Bytes,这样的限制只是一个大概,并非精确,一般速度均有所偏差
数据在由内核发送给接口(网卡)发送出去之前把数据首先放到 这个接口对应的qdisc里,然后再从qdisc里面把数据取出发送到接口。
|--class--|
内核 --> qdisc(filters) |--class--| -->接口
|--class--|
如上图所示:qdisc下面可以包含很多的 class,class下面也可以继续包含class,qdisc同时还包含很多的filters(filters不分等级层次),每一个filter都映射到一个class。数据到达qdisc的时候,会遍历这个qdisc下面的filters,filter解析IP数据包是否符合这个filter。如果符合,这个数据包就会被送到映射大那个class里面。
我们可以对class进行限速,那么进入这个class的数据就会以特定的速度限制进行发送。所以在做限速的时候首先根据要求建立qdiscs-classes的树形等级结构。然后建立filters,把不同类型的数据包过滤到不同的class里面。对其进行限速。
U32分类起详解:
Filter的匹配类型有好多中。最常用的是u32匹配:
The U32 selector contains definition of the pattern, that will be matched to the currently processed packet. Precisely, it defines which bits are to be matched in the packet header and nothing more, but this simple method is very powerful. Let’s take a look at the following examples, taken directly from a pretty complex, real-world filter:
U32选择器定义了一些模式,以匹配当前处理的包。确切的说,他就是定义了包头(packet header)的具体哪个位上应该是什么。看起来非常简单,却非常强大。如下:
# tc filter add dev eth0 protocol ip parent 1:0 pref 10 u32 \
match u32 00100000 00ff0000 at 0 flowid 1:10
For now, leave the first line alone - all these parameters describe the filter’s hash tables. Focus on the selector line, containing match keyword. This selector will match to IP headers, whose second byte will be 0x10 (0010). As you can guess, the 00ff number is the match mask, telling the filter exactly which bits to match. Here it’s 0xff, so the byte will match if it’s exactly 0x10. The at keyword means that the match is to be started at specified offset (in bytes) -- in this case it’s beginning of the packet. Translating all that to human language, the packet will match if its Type of Service field will have ‘low delay’ bits set. Let’s analyze another rule:
上面的那个例子,撇开第一行不管,u32说明要匹配32位(其实未必有那么多,后面的mask来规定这32中真正有效的位数)。00100000是16进制的一个32位数。00Ff0000是这个32位数的掩码,这里表示只有9-16位有效。At 0表示偏移位置(相对于包的开头)为0。Flowid 1:10 是说把符合的数据送入的class。下面看这个例子:
# tc filter add dev eth0 protocol ip parent 1:0 pref 10 u32 \
match u32 00000016 0000ffff at nexthdr+0 flowid 1:10
The nexthdr option means next header encapsulated in the IP packet, i.e. header of upper-layer
protocol. The match will also start here at the beginning of the next header. The match should occur in the second, 32-bit word of the header. In TCP and UDP protocols this field contains packet’s destination port. The number is given in big-endian format, i.e. older bits first, so we simply read 0x0016 as 22 decimal, which stands for SSH service if this was TCP. As you guess, this match is ambiguous without a context, and we will discuss this later.
Nexthdr (next header)指的是这个IP 数据包上层协议(tcp/udp)的头。+0说明偏移为0。在tcp/udp协议中,这个部分是目的端口号(源端口号和目的端口号各自16位,源端口号在前)。以上这个说明目的断口号是22。代表是SSH服务的端口号。
Having understood all the above, we will find the following selector quite easy to read: match c0a80100 ffffff00 at 16 . What we got here is a three byte match at 17-th byte, counting from the IP header start. This will match for packets with destination address anywhere in 192.168.1/24 network.
Match c0a80100 ffffff00 at 16
就表示目的地址是 192.168.1/24。
另外u32还提供了一些容易使用的表达,例子如下
# tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match \
ip dport 22 0xffff flowid 10:1
目标端口地址是22
# tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match \
ip sport 80 0xffff flowid 10:1
源端口地址是80
# tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 \
match ip dst 4.3.2.1/32 flowid 10:1
目标ip地址是 4.3.2.1,32可以省略
# tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 \
match ip src 1.2.3.4/32 flowid 10:1
源IP地址是 1.2.3.4,
一个小例子,让本地机器访问外部网址的时候上传速度为100kbit,访问内部网址的时候为100Mbit
/sbin/tc qdisc del dev eth0 root
/sbin/tc qdisc add dev eth0 root handle 100: cbq bandwidth 100mbit avpkt 1000
/sbin/tc class add dev eth0 parent 100:0 classid 100:1 cbq bandwidth 100Mbit rate 1000kbit allot 1514 weight 2Kbit prio 8 maxburst 8 avpkt 1000 bounded
/sbin/tc class add dev eth0 parent 100:0 classid 100:2 cbq bandwidth 100Mbit rate 100mbit allot 1514 weight 2Kbit prio 8 maxburst 8 avpkt 1000 bounded
/sbin/tc filter add dev eth0 parent 100:0 protocol ip prio 5 u32 match ip dst 0.0.0.0/0 flowid 100:1
/sbin/tc filter add dev eth0 parent 100:0 protocol ip prio 2 u32 match ip dst 192.168.1.0/24 flowid 100:2
说明:在filter中prio小的先被执行,0.0.0.0/0表示任意目标地址。
令牌桶:
令牌桶是一种网络通讯中常见的缓冲区工作原理,它有两个重要的参数,令牌桶容量n和令牌产生速率s。我们可以把令牌当成是门票,而令牌桶则是负责制作和发 放门票的管理员,它手里最多有n张令牌。一开始,管理员开始手里有n张令牌。每当一个数据包到达后,管理员就看看手里是否还有可用的令牌。如果有,就把令 牌发给这个数据包,hashlimit就告诉iptables,这个数据包被匹配了。而当管理员把手上所有的令牌都发完了,再来的数据包就拿不到令牌了。 这时,hashlimit模块就告诉iptables,这个数据包不能被匹配。
除了发放令牌之外,只要令牌桶中的令牌数量少于n,它就会以速率s来产生新的令牌,直到令牌数量到达n为止。
通过令牌桶机制,即可以有效的控制单位时间内通过(匹配)的数据包数量,又可以容许短时间内突发的大量数据包的通过(只要数据包数量不超过令牌桶n)。
hashlimit模块提供了两个参数--hashlimit和--hashlimit-burst,分别对应于令牌产生速率和令牌桶容量。
除了令牌桶模型外,hashlimit匹配的另外一个重要概念是匹配项。一个示例脚本,从TC HOW-TO上转载:
------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# The Ultimate Setup For Your Internet Connection At Home
#
#
# Set the following values to somewhat less than your actual download
# and uplink speed. In kilobits
DOWNLINK=6200
UPLINK=650
DEV=eth0
# clean existing down- and uplink qdiscs, hide errors
tc qdisc del dev $DEV root 2> /dev/null > /dev/null
tc qdisc del dev $DEV ingress 2> /dev/null > /dev/null
###### uplink
# install root HTB, point default traffic to 1:20:
tc qdisc add dev $DEV root handle 1: htb default 20
# shape everything at $UPLINK speed - this prevents huge queues in your
# DSL modem which destroy latency:
tc class add dev $DEV parent 1: classid 1:1 htb rate ${UPLINK}kbit burst 6k
# high prio class 1:10:
tc class add dev $DEV parent 1:1 classid 1:10 htb rate ${UPLINK}kbit burst 6k prio 1
# bulk & default class 1:20 - gets slightly less traffic,
# and a lower priority:
tc class add dev $DEV parent 1:1 classid 1:20 htb rate $[9*$UPLINK/10]kbit burst 6k prio 2
# both get Stochastic Fairness:
tc qdisc add dev $DEV parent 1:10 handle 10: sfq perturb 10
tc qdisc add dev $DEV parent 1:20 handle 20: sfq perturb 10
# TOS Minimum Delay (ssh, NOT scp) in 1:10:
tc filter add dev $DEV parent 1:0 protocol ip prio 10 u32 match ip tos 0x10 0xff flowid 1:10
# ICMP (ip protocol 1) in the interactive class 1:10 so we
# can do measurements & impress our friends:
tc filter add dev $DEV parent 1:0 protocol ip prio 10 u32 match ip protocol 1 0xff flowid 1:10
# To speed up downloads while an upload is going on, put ACK packets in
# the interactive class:
tc filter add dev $DEV parent 1: protocol ip prio 10 u32 match ip protocol 6 0xff match u8 0x05 0x0f at 0 match u16 0x0000 0xffc0 at 2 match u8 0x10 0xff at 33 flowid 1:10
# rest is 'non-interactive' ie 'bulk' and ends up in 1:20
########## downlink #############
# slow downloads down to somewhat less than the real speed to prevent
# queuing at our ISP. Tune to see how high you can set it.
# ISPs tend to have *huge* queues to make sure big downloads are fast
#
# attach ingress policer:
tc qdisc add dev $DEV handle ffff: ingress
# filter *everything* to it (0.0.0.0/0), drop everything that's
# coming in too fast:
tc filter add dev $DEV parent ffff: protocol ip prio 50 u32 match ip src 0.0.0.0/0 police rate ${DOWNLINK}kbit burst 10k
iptables-extensions
Section: iptables 1.4.18 (8)Updated:
Index
NAME
iptables-extensions --- list of extensions in the standard iptables distributionSYNOPSIS
ip6tables [-m name [module-options...]] [-j target-name [target-options...]iptables [-m name [module-options...]] [-j target-name [target-options...]
MATCH EXTENSIONS
iptables can use extended packet matching modules with the -m or --match options, followed by the matching module name; after these, various extra command line options become available, depending on the specific module. You can specify multiple extended match modules in one line, and you can use the -h or --help options after the module has been specified to receive help specific to that module. The extended match modules are evaluated in the order they are specified in the rule.If the -p or --protocol was specified and if and only if an unknown option is encountered, iptables will try load a match module of the same name as the protocol, to try making the option available.
addrtype
This module matches packets based on their address type. Address types are used within the kernel networking stack and categorize addresses into various groups. The exact definition of that group depends on the specific layer three protocol.The following address types are possible:
- UNSPEC
- an unspecified address (i.e. 0.0.0.0)
- UNICAST
- an unicast address
- LOCAL
- a local address
- BROADCAST
- a broadcast address
- ANYCAST
- an anycast packet
- MULTICAST
- a multicast address
- BLACKHOLE
- a blackhole address
- UNREACHABLE
- an unreachable address
- PROHIBIT
- a prohibited address
- THROW
- FIXME
- NAT
- FIXME
- XRESOLVE
- [!] --src-type type
- Matches if the source address is of given type
- [!] --dst-type type
- Matches if the destination address is of given type
- --limit-iface-in
- The address type checking can be limited to the interface the packet is coming in. This option is only valid in the PREROUTING, INPUT and FORWARD chains. It cannot be specified with the --limit-iface-out option.
- --limit-iface-out
- The address type checking can be limited to the interface the packet is going out. This option is only valid in the POSTROUTING, OUTPUT and FORWARD chains. It cannot be specified with the --limit-iface-in option.
ah (IPv6-specific)
This module matches the parameters in Authentication header of IPsec packets.- [!] --ahspi spi[:spi]
- Matches SPI.
- [!] --ahlen length
- Total length of this header in octets.
- --ahres
- Matches if the reserved field is filled with zero.
ah (IPv4-specific)
This module matches the SPIs in Authentication header of IPsec packets.- [!] --ahspi spi[:spi]
cluster
Allows you to deploy gateway and back-end load-sharing clusters without the need of load-balancers.This match requires that all the nodes see the same packets. Thus, the cluster match decides if this node has to handle a packet given the following options:
- --cluster-total-nodes num
- Set number of total nodes in cluster.
- [!] --cluster-local-node num
- Set the local node number ID.
- [!] --cluster-local-nodemask mask
- Set the local node number ID mask. You can use this option instead of --cluster-local-node.
- --cluster-hash-seed value
- Set seed value of the Jenkins hash.
Example:
- iptables -A PREROUTING -t mangle -i eth1 -m cluster --cluster-total-nodes 2 --cluster-local-node 1 --cluster-hash-seed 0xdeadbeef -j MARK --set-mark 0xffff
- iptables -A PREROUTING -t mangle -i eth2 -m cluster --cluster-total-nodes 2 --cluster-local-node 1 --cluster-hash-seed 0xdeadbeef -j MARK --set-mark 0xffff
- iptables -A PREROUTING -t mangle -i eth1 -m mark ! --mark 0xffff -j DROP
- iptables -A PREROUTING -t mangle -i eth2 -m mark ! --mark 0xffff -j DROP
And the following commands to make all nodes see the same packets:
- ip maddr add 01:00:5e:00:01:01 dev eth1
- ip maddr add 01:00:5e:00:01:02 dev eth2
- arptables -A OUTPUT -o eth1 --h-length 6 -j mangle --mangle-mac-s 01:00:5e:00:01:01
- arptables -A INPUT -i eth1 --h-length 6 --destination-mac 01:00:5e:00:01:01 -j mangle --mangle-mac-d 00:zz:yy:xx:5a:27
- arptables -A OUTPUT -o eth2 --h-length 6 -j mangle --mangle-mac-s 01:00:5e:00:01:02
- arptables -A INPUT -i eth2 --h-length 6 --destination-mac 01:00:5e:00:01:02 -j mangle --mangle-mac-d 00:zz:yy:xx:5a:27
In the case of TCP connections, pickup facility has to be disabled to avoid marking TCP ACK packets coming in the reply direction as valid.
- echo 0 > /proc/sys/net/netfilter/nf_conntrack_tcp_loose
comment
Allows you to add comments (up to 256 characters) to any rule.- --comment comment
- Example:
- iptables -A INPUT -i eth1 -m comment --comment "my local LAN"
connbytes
Match by how many bytes or packets a connection (or one of the two flows constituting the connection) has transferred so far, or by average bytes per packet.The counters are 64-bit and are thus not expected to overflow ;)
The primary use is to detect long-lived downloads and mark them to be scheduled using a lower priority band in traffic control.
The transferred bytes per connection can also be viewed through `conntrack -L` and accessed via ctnetlink.
NOTE that for connections which have no accounting information, the match will always return false. The "net.netfilter.nf_conntrack_acct" sysctl flag controls whether new connections will be byte/packet counted. Existing connection flows will not be gaining/losing a/the accounting structure when be sysctl flag is flipped.
- [!] --connbytes from[:to]
- match packets from a connection whose packets/bytes/average packet size is more than FROM and less than TO bytes/packets. if TO is omitted only FROM check is done. "!" is used to match packets not falling in the range.
- --connbytes-dir {original|reply|both}
- which packets to consider
- --connbytes-mode {packets|bytes|avgpkt}
- whether to check the amount of packets, number of bytes transferred or the average size (in bytes) of all packets received so far. Note that when "both" is used together with "avgpkt", and data is going (mainly) only in one direction (for example HTTP), the average packet size will be about half of the actual data packets.
- Example:
- iptables .. -m connbytes --connbytes 10000:100000 --connbytes-dir both --connbytes-mode bytes ...
connlimit
Allows you to restrict the number of parallel connections to a server per client IP address (or client address block).- --connlimit-upto n
- Match if the number of existing connections is below or equal n.
- --connlimit-above n
- Match if the number of existing connections is above n.
- --connlimit-mask prefix_length
- Group hosts using the prefix length. For IPv4, this must be a number between (including) 0 and 32. For IPv6, between 0 and 128. If not specified, the maximum prefix length for the applicable protocol is used.
- --connlimit-saddr
- Apply the limit onto the source group. This is the default if --connlimit-daddr is not specified.
- --connlimit-daddr
- Apply the limit onto the destination group.
Examples:
- # allow 2 telnet connections per client host
- iptables -A INPUT -p tcp --syn --dport 23 -m connlimit --connlimit-above 2 -j REJECT
- # you can also match the other way around:
- iptables -A INPUT -p tcp --syn --dport 23 -m connlimit --connlimit-upto 2 -j ACCEPT
- # limit the number of parallel HTTP requests to 16 per class C sized source network (24 bit netmask)
- iptables -p tcp --syn --dport 80 -m connlimit --connlimit-above 16 --connlimit-mask 24 -j REJECT
- # limit the number of parallel HTTP requests to 16 for the link local network
- (ipv6) ip6tables -p tcp --syn --dport 80 -s fe80::/64 -m connlimit --connlimit-above 16 --connlimit-mask 64 -j REJECT
- # Limit the number of connections to a particular host:
- ip6tables -p tcp --syn --dport 49152:65535 -d 2001:db8::1 -m connlimit --connlimit-above 100 -j REJECT
connmark
This module matches the netfilter mark field associated with a connection (which can be set using the CONNMARK target below).- [!] --mark value[/mask]
- Matches packets in connections with the given mark value (if a mask is specified, this is logically ANDed with the mark before the comparison).
conntrack
This module, when combined with connection tracking, allows access to the connection tracking state for this packet/connection.- [!] --ctstate statelist
- statelist is a comma separated list of the connection states to match. Possible states are listed below.
- [!] --ctproto l4proto
- Layer-4 protocol to match (by number or name)
- [!] --ctorigsrc address[/mask]
- [!] --ctorigdst address[/mask]
- [!] --ctreplsrc address[/mask]
- [!] --ctrepldst address[/mask]
- Match against original/reply source/destination address
- [!] --ctorigsrcport port[:port]
- [!] --ctorigdstport port[:port]
- [!] --ctreplsrcport port[:port]
- [!] --ctrepldstport port[:port]
- Match against original/reply source/destination port (TCP/UDP/etc.) or GRE key. Matching against port ranges is only supported in kernel versions above 2.6.38.
- [!] --ctstatus statelist
- statuslist is a comma separated list of the connection statuses to match. Possible statuses are listed below.
- [!] --ctexpire time[:time]
- Match remaining lifetime in seconds against given value or range of values (inclusive)
- --ctdir {ORIGINAL|REPLY}
- Match packets that are flowing in the specified direction. If this flag is not specified at all, matches packets in both directions.
States for --ctstate:
- INVALID
- The packet is associated with no known connection.
- NEW
- The packet has started a new connection, or otherwise associated with a connection which has not seen packets in both directions.
- ESTABLISHED
- The packet is associated with a connection which has seen packets in both directions.
- RELATED
- The packet is starting a new connection, but is associated with an existing connection, such as an FTP data transfer, or an ICMP error.
- UNTRACKED
- The packet is not tracked at all, which happens if you explicitly untrack it by using -j CT --notrack in the raw table.
- SNAT
- A virtual state, matching if the original source address differs from the reply destination.
- DNAT
- A virtual state, matching if the original destination differs from the reply source.
Statuses for --ctstatus:
- NONE
- None of the below.
- EXPECTED
- This is an expected connection (i.e. a conntrack helper set it up).
- SEEN_REPLY
- Conntrack has seen packets in both directions.
- ASSURED
- Conntrack entry should never be early-expired.
- CONFIRMED
- Connection is confirmed: originating packet has left box.
cpu
- [!] --cpu number
- Match cpu handling this packet. cpus are numbered from 0 to NR_CPUS-1 Can be used in combination with RPS (Remote Packet Steering) or multiqueue NICs to spread network traffic on different queues.
Example:
iptables -t nat -A PREROUTING -p tcp --dport 80 -m cpu --cpu 0 -j REDIRECT --to-port 8080
iptables -t nat -A PREROUTING -p tcp --dport 80 -m cpu --cpu 1 -j REDIRECT --to-port 8081
dccp
- [!] --source-port,--sport port[:port]
- [!] --destination-port,--dport port[:port]
- [!] --dccp-types mask
- Match when the DCCP packet type is one of 'mask'. 'mask' is a comma-separated list of packet types. Packet types are: REQUEST RESPONSE DATA ACK DATAACK CLOSEREQ CLOSE RESET SYNC SYNCACK INVALID.
- [!] --dccp-option number
- Match if DCCP option set.
devgroup
Match device group of a packets incoming/outgoing interface.- [!] --src-group name
- Match device group of incoming device
- [!] --dst-group name
- Match device group of outgoing device
dscp
This module matches the 6 bit DSCP field within the TOS field in the IP header. DSCP has superseded TOS within the IETF.- [!] --dscp value
- Match against a numeric (decimal or hex) value [0-63].
- [!] --dscp-class class
- Match the DiffServ class. This value may be any of the BE, EF, AFxx or CSx classes. It will then be converted into its according numeric value.
dst (IPv6-specific)
This module matches the parameters in Destination Options header- [!] --dst-len length
- Total length of this header in octets.
- --dst-opts type[:length][,type[:length]...]
- numeric type of option and the length of the option data in octets.
ecn
This allows you to match the ECN bits of the IPv4/IPv6 and TCP header. ECN is the Explicit Congestion Notification mechanism as specified in RFC3168- [!] --ecn-tcp-cwr
- This matches if the TCP ECN CWR (Congestion Window Received) bit is set.
- [!] --ecn-tcp-ece
- This matches if the TCP ECN ECE (ECN Echo) bit is set.
- [!] --ecn-ip-ect num
- This matches a particular IPv4/IPv6 ECT (ECN-Capable Transport). You have to specify a number between `0' and `3'.
esp
This module matches the SPIs in ESP header of IPsec packets.- [!] --espspi spi[:spi]
eui64 (IPv6-specific)
This module matches the EUI-64 part of a stateless autoconfigured IPv6 address. It compares the EUI-64 derived from the source MAC address in Ethernet frame with the lower 64 bits of the IPv6 source address. But "Universal/Local" bit is not compared. This module doesn't match other link layer frame, and is only valid in the PREROUTING, INPUT and FORWARD chains.frag (IPv6-specific)
This module matches the parameters in Fragment header.- [!] --fragid id[:id]
- Matches the given Identification or range of it.
- [!] --fraglen length
- This option cannot be used with kernel version 2.6.10 or later. The length of Fragment header is static and this option doesn't make sense.
- --fragres
- Matches if the reserved fields are filled with zero.
- --fragfirst
- Matches on the first fragment.
- --fragmore
- Matches if there are more fragments.
- --fraglast
- Matches if this is the last fragment.
hashlimit
hashlimit uses hash buckets to express a rate limiting match (like the limit match) for a group of connections using a single iptables rule. Grouping can be done per-hostgroup (source and/or destination address) and/or per-port. It gives you the ability to express "N packets per time quantum per group" or "N bytes per seconds" (see below for some examples).A hash limit option (--hashlimit-upto, --hashlimit-above) and --hashlimit-name are required.
- --hashlimit-upto amount[/second|/minute|/hour|/day]
- Match if the rate is below or equal to amount/quantum. It is specified either as a number, with an optional time quantum suffix (the default is 3/hour), or as amountb/second (number of bytes per second).
- --hashlimit-above amount[/second|/minute|/hour|/day]
- Match if the rate is above amount/quantum.
- --hashlimit-burst amount
- Maximum initial number of packets to match: this number gets recharged by one every time the limit specified above is not reached, up to this number; the default is 5. When byte-based rate matching is requested, this option specifies the amount of bytes that can exceed the given rate. This option should be used with caution -- if the entry expires, the burst value is reset too.
- --hashlimit-mode {srcip|srcport|dstip|dstport},...
- A comma-separated list of objects to take into consideration. If no --hashlimit-mode option is given, hashlimit acts like limit, but at the expensive of doing the hash housekeeping.
- --hashlimit-srcmask prefix
- When --hashlimit-mode srcip is used, all source addresses encountered will be grouped according to the given prefix length and the so-created subnet will be subject to hashlimit.prefix must be between (inclusive) 0 and 32. Note that --hashlimit-srcmask 0 is basically doing the same thing as not specifying srcip for --hashlimit-mode, but is technically more expensive.
- --hashlimit-dstmask prefix
- Like --hashlimit-srcmask, but for destination addresses.
- --hashlimit-name foo
- The name for the /proc/net/ipt_hashlimit/foo entry.
- --hashlimit-htable-size buckets
- The number of buckets of the hash table
- --hashlimit-htable-max entries
- Maximum entries in the hash.
- --hashlimit-htable-expire msec
- After how many milliseconds do hash entries expire.
- --hashlimit-htable-gcinterval msec
- How many milliseconds between garbage collection intervals.
Examples:
- matching on source host
- "1000 packets per second for every host in 192.168.0.0/16" => -s 192.168.0.0/16 --hashlimit-mode srcip --hashlimit-upto 1000/sec
- matching on source port
- "100 packets per second for every service of 192.168.1.1" => -s 192.168.1.1 --hashlimit-mode srcport --hashlimit-upto 100/sec
- matching on subnet
- "10000 packets per minute for every /28 subnet (groups of 8 addresses) in 10.0.0.0/8" => -s 10.0.0.8 --hashlimit-mask 28 --hashlimit-upto 10000/min
- matching bytes per second
- "flows exceeding 512kbyte/s" => --hashlimit-mode srcip,dstip,srcport,dstport --hashlimit-above 512kb/s
- matching bytes per second
- "hosts that exceed 512kbyte/s, but permit up to 1Megabytes without matching" --hashlimit-mode dstip --hashlimit-above 512kb/s --hashlimit-burst 1mb
hbh (IPv6-specific)
This module matches the parameters in Hop-by-Hop Options header- [!] --hbh-len length
- Total length of this header in octets.
- --hbh-opts type[:length][,type[:length]...]
- numeric type of option and the length of the option data in octets.
helper
This module matches packets related to a specific conntrack-helper.- [!] --helper string
- Matches packets related to the specified conntrack-helper.
-
string can be "ftp" for packets related to a ftp-session on default port. For other ports append -portnr to the value, ie. "ftp-2121".
Same rules apply for other conntrack-helpers.
-
hl (IPv6-specific)
This module matches the Hop Limit field in the IPv6 header.- [!] --hl-eq value
- Matches if Hop Limit equals value.
- --hl-lt value
- Matches if Hop Limit is less than value.
- --hl-gt value
- Matches if Hop Limit is greater than value.
icmp (IPv4-specific)
This extension can be used if `--protocol icmp' is specified. It provides the following option:- [!] --icmp-type {type[/code]|typename}
- This allows specification of the ICMP type, which can be a numeric ICMP type, type/code pair, or one of the ICMP type names shown by the command
iptables -p icmp -h
icmp6 (IPv6-specific)
This extension can be used if `--protocol ipv6-icmp' or `--protocol icmpv6' is specified. It provides the following option:- [!] --icmpv6-type type[/code]|typename
- This allows specification of the ICMPv6 type, which can be a numeric ICMPv6 type, type and code, or one of the ICMPv6 type names shown by the command
ip6tables -p ipv6-icmp -h
iprange
This matches on a given arbitrary range of IP addresses.- [!] --src-range from[-to]
- Match source IP in the specified range.
- [!] --dst-range from[-to]
- Match destination IP in the specified range.
ipv6header (IPv6-specific)
This module matches IPv6 extension headers and/or upper layer header.- --soft
- Matches if the packet includes any of the headers specified with --header.
- [!] --header header[,header...]
- Matches the packet which EXACTLY includes all specified headers. The headers encapsulated with ESP header are out of scope. Possible header types can be:
- hop|hop-by-hop
- Hop-by-Hop Options header
- dst
- Destination Options header
- route
- Routing header
- frag
- Fragment header
- auth
- Authentication header
- esp
- Encapsulating Security Payload header
- none
- No Next header which matches 59 in the 'Next Header field' of IPv6 header or any IPv6 extension headers
- proto
- which matches any upper layer protocol header. A protocol name from /etc/protocols and numeric value also allowed. The number 255 is equivalent to proto.
ipvs
Match IPVS connection properties.- [!] --ipvs
- packet belongs to an IPVS connection
- Any of the following options implies --ipvs (even negated)
- [!] --vproto protocol
- VIP protocol to match; by number or name, e.g. "tcp"
- [!] --vaddr address[/mask]
- VIP address to match
- [!] --vport port
- VIP port to match; by number or name, e.g. "http"
- --vdir {ORIGINAL|REPLY}
- flow direction of packet
- [!] --vmethod {GATE|IPIP|MASQ}
- IPVS forwarding method used
- [!] --vportctl port
- VIP port of the controlling connection to match, e.g. 21 for FTP
length
This module matches the length of the layer-3 payload (e.g. layer-4 packet) of a packet against a specific value or range of values.- [!] --length length[:length]
limit
This module matches at a limited rate using a token bucket filter. A rule using this extension will match until this limit is reached. It can be used in combination with the LOG target to give limited logging, for example.xt_limit has no negation support - you will have to use -m hashlimit ! --hashlimit rate in this case whilst omitting --hashlimit-mode.
- --limit rate[/second|/minute|/hour|/day]
- Maximum average matching rate: specified as a number, with an optional `/second', `/minute', `/hour', or `/day' suffix; the default is 3/hour.
- --limit-burst number
- Maximum initial number of packets to match: this number gets recharged by one every time the limit specified above is not reached, up to this number; the default is 5.
mac
- [!] --mac-source address
- Match source MAC address. It must be of the form XX:XX:XX:XX:XX:XX. Note that this only makes sense for packets coming from an Ethernet device and entering the PREROUTING,FORWARD or INPUT chains.
mark
This module matches the netfilter mark field associated with a packet (which can be set using the MARK target below).- [!] --mark value[/mask]
- Matches packets with the given unsigned mark value (if a mask is specified, this is logically ANDed with the mask before the comparison).
mh (IPv6-specific)
This extension is loaded if `--protocol ipv6-mh' or `--protocol mh' is specified. It provides the following option:- [!] --mh-type type[:type]
- This allows specification of the Mobility Header(MH) type, which can be a numeric MH type, type or one of the MH type names shown by the command
ip6tables -p mh -h
multiport
This module matches a set of source or destination ports. Up to 15 ports can be specified. A port range (port:port) counts as two ports. It can only be used in conjunction with -p tcpor -p udp.- [!] --source-ports,--sports port[,port|,port:port]...
- Match if the source port is one of the given ports. The flag --sports is a convenient alias for this option. Multiple ports or port ranges are separated using a comma, and a port range is specified using a colon. 53,1024:65535 would therefore match ports 53 and all from 1024 through 65535.
- [!] --destination-ports,--dports port[,port|,port:port]...
- Match if the destination port is one of the given ports. The flag --dports is a convenient alias for this option.
- [!] --ports port[,port|,port:port]...
- Match if either the source or destination ports are equal to one of the given ports.
nfacct
The nfacct match provides the extended accounting infrastructure for iptables. You have to use this match together with the standalone user-space utility nfacct.The only option available for this match is the following:
- --nfacct-name name
- This allows you to specify the existing object name that will be use for accounting the traffic that this rule-set is matching.
To use this extension, you have to create an accounting object:
- nfacct add http-traffic
Then, you have to attach it to the accounting object via iptables:
- iptables -I INPUT -p tcp --sport 80 -m nfacct --nfacct-name http-traffic
- iptables -I OUTPUT -p tcp --dport 80 -m nfacct --nfacct-name http-traffic
Then, you can check for the amount of traffic that the rules match:
- nfacct get http-traffic
- { pkts = 00000000000000000156, bytes = 00000000000000151786 } = http-traffic;
You can obtain nfacct from http://www.netfilter.org or, alternatively, from the git.netfilter.org repository.
osf
The osf module does passive operating system fingerprinting. This modules compares some data (Window Size, MSS, options and their order, TTL, DF, and others) from packets with the SYN bit set.- [!] --genre string
- Match an operating system genre by using a passive fingerprinting.
- --ttl level
- Do additional TTL checks on the packet to determine the operating system. level can be one of the following values:
- •
- 0 - True IP address and fingerprint TTL comparison. This generally works for LANs.
- •
- 1 - Check if the IP header's TTL is less than the fingerprint one. Works for globally-routable addresses.
- •
- 2 - Do not compare the TTL at all.
- --log level
- Log determined genres into dmesg even if they do not match the desired one. level can be one of the following values:
- •
- 0 - Log all matched or unknown signatures
- •
- 1 - Log only the first one
- •
- 2 - Log all known matched signatures
You may find something like this in syslog:
Windows [2000:SP3:Windows XP Pro SP1, 2000 SP3]: 11.22.33.55:4024 -> 11.22.33.44:139 hops=3 Linux [2.5-2.6:] : 1.2.3.4:42624 -> 1.2.3.5:22 hops=4
OS fingerprints are loadable using the nfnl_osf program. To load fingerprints from a file, use:
nfnl_osf -f /usr/share/xtables/pf.os
To remove them again,
nfnl_osf -f /usr/share/xtables/pf.os -d
The fingerprint database can be downlaoded from http://www.openbsd.org/cgi-bin/cvsweb/src/etc/pf.os .
owner
This module attempts to match various characteristics of the packet creator, for locally generated packets. This match is only valid in the OUTPUT and POSTROUTING chains. Forwarded packets do not have any socket associated with them. Packets from kernel threads do have a socket, but usually no owner.- [!] --uid-owner username
- [!] --uid-owner userid[-userid]
- Matches if the packet socket's file structure (if it has one) is owned by the given user. You may also specify a numerical UID, or an UID range.
- [!] --gid-owner groupname
- [!] --gid-owner groupid[-groupid]
- Matches if the packet socket's file structure is owned by the given group. You may also specify a numerical GID, or a GID range.
- [!] --socket-exists
- Matches if the packet is associated with a socket.
physdev
This module matches on the bridge port input and output devices enslaved to a bridge device. This module is a part of the infrastructure that enables a transparent bridging IP firewall and is only useful for kernel versions above version 2.5.44.- [!] --physdev-in name
- Name of a bridge port via which a packet is received (only for packets entering the INPUT, FORWARD and PREROUTING chains). If the interface name ends in a "+", then any interface which begins with this name will match. If the packet didn't arrive through a bridge device, this packet won't match this option, unless '!' is used.
- [!] --physdev-out name
- Name of a bridge port via which a packet is going to be sent (for packets entering the FORWARD, OUTPUT and POSTROUTING chains). If the interface name ends in a "+", then any interface which begins with this name will match. Note that in the nat and mangle OUTPUT chains one cannot match on the bridge output port, however one can in the filter OUTPUTchain. If the packet won't leave by a bridge device or if it is yet unknown what the output device will be, then the packet won't match this option, unless '!' is used.
- [!] --physdev-is-in
- Matches if the packet has entered through a bridge interface.
- [!] --physdev-is-out
- Matches if the packet will leave through a bridge interface.
- [!] --physdev-is-bridged
- Matches if the packet is being bridged and therefore is not being routed. This is only useful in the FORWARD and POSTROUTING chains.
pkttype
This module matches the link-layer packet type.- [!] --pkt-type {unicast|broadcast|multicast}
policy
This modules matches the policy used by IPsec for handling a packet.- --dir {in|out}
- Used to select whether to match the policy used for decapsulation or the policy that will be used for encapsulation. in is valid in the PREROUTING, INPUT and FORWARD chains, outis valid in the POSTROUTING, OUTPUT and FORWARD chains.
- --pol {none|ipsec}
- Matches if the packet is subject to IPsec processing. --pol none cannot be combined with --strict.
- --strict
- Selects whether to match the exact policy or match if any rule of the policy matches the given policy.
For each policy element that is to be described, one can use one or more of the following options. When --strict is in effect, at least one must be used per element.
- [!] --reqid id
- Matches the reqid of the policy rule. The reqid can be specified with setkey using unique:id as level.
- [!] --spi spi
- Matches the SPI of the SA.
- [!] --proto {ah|esp|ipcomp}
- Matches the encapsulation protocol.
- [!] --mode {tunnel|transport}
- Matches the encapsulation mode.
- [!] --tunnel-src addr[/mask]
- Matches the source end-point address of a tunnel mode SA. Only valid with --mode tunnel.
- [!] --tunnel-dst addr[/mask]
- Matches the destination end-point address of a tunnel mode SA. Only valid with --mode tunnel.
- --next
- Start the next element in the policy specification. Can only be used with --strict.
quota
Implements network quotas by decrementing a byte counter with each packet. The condition matches until the byte counter reaches zero. Behavior is reversed with negation (i.e. the condition does not match until the byte counter reaches zero).- [!] --quota bytes
- The quota in bytes.
rateest
The rate estimator can match on estimated rates as collected by the RATEEST target. It supports matching on absolute bps/pps values, comparing two rate estimators and matching on the difference between two rate estimators.For a better understanding of the available options, these are all possible combinations:
- •
- rateest operator rateest-bps
- •
- rateest operator rateest-pps
- •
- (rateest minus rateest-bps1) operator rateest-bps2
- •
- (rateest minus rateest-pps1) operator rateest-pps2
- •
- rateest1 operator rateest2 rateest-bps(without rate!)
- •
- rateest1 operator rateest2 rateest-pps(without rate!)
- •
- (rateest1 minus rateest-bps1) operator (rateest2 minus rateest-bps2)
- •
- (rateest1 minus rateest-pps1) operator (rateest2 minus rateest-pps2)
- --rateest-delta
- For each estimator (either absolute or relative mode), calculate the difference between the estimator-determined flow rate and the static value chosen with the BPS/PPS options. If the flow rate is higher than the specified BPS/PPS, 0 will be used instead of a negative value. In other words, "max(0, rateest#_rate - rateest#_bps)" is used.
- [!] --rateest-lt
- Match if rate is less than given rate/estimator.
- [!] --rateest-gt
- Match if rate is greater than given rate/estimator.
- [!] --rateest-eq
- Match if rate is equal to given rate/estimator.
In the so-called "absolute mode", only one rate estimator is used and compared against a static value, while in "relative mode", two rate estimators are compared against another.
- --rateest name
- Name of the one rate estimator for absolute mode.
- --rateest1 name
- --rateest2 name
- The names of the two rate estimators for relative mode.
- --rateest-bps [value]
- --rateest-pps [value]
- --rateest-bps1 [value]
- --rateest-bps2 [value]
- --rateest-pps1 [value]
- --rateest-pps2 [value]
- Compare the estimator(s) by bytes or packets per second, and compare against the chosen value. See the above bullet list for which option is to be used in which case. A unit suffix may be used - available ones are: bit, [kmgt]bit, [KMGT]ibit, Bps, [KMGT]Bps, [KMGT]iBps.
Example: This is what can be used to route outgoing data connections from an FTP server over two lines based on the available bandwidth at the time the data connection was started:
# Estimate outgoing rates
iptables -t mangle -A POSTROUTING -o eth0 -j RATEEST --rateest-name eth0 --rateest-interval 250ms --rateest-ewma 0.5s
iptables -t mangle -A POSTROUTING -o ppp0 -j RATEEST --rateest-name ppp0 --rateest-interval 250ms --rateest-ewma 0.5s
# Mark based on available bandwidth
iptables -t mangle -A balance -m conntrack --ctstate NEW -m helper --helper ftp -m rateest --rateest-delta --rateest1 eth0 --rateest-bps1 2.5mbit --rateest-gt --rateest2 ppp0 --rateest-bps2 2mbit -j CONNMARK --set-mark 1
iptables -t mangle -A balance -m conntrack --ctstate NEW -m helper --helper ftp -m rateest --rateest-delta --rateest1 ppp0 --rateest-bps1 2mbit --rateest-gt --rateest2 eth0 --rateest-bps2 2.5mbit -j CONNMARK --set-mark 2
iptables -t mangle -A balance -j CONNMARK --restore-mark
realm (IPv4-specific)
This matches the routing realm. Routing realms are used in complex routing setups involving dynamic routing protocols like BGP.- [!] --realm value[/mask]
- Matches a given realm number (and optionally mask). If not a number, value can be a named realm from /etc/iproute2/rt_realms (mask can not be used in that case).
recent
Allows you to dynamically create a list of IP addresses and then match against that list in a few different ways.For example, you can create a "badguy" list out of people attempting to connect to port 139 on your firewall and then DROP all future packets from them without considering them.
--set, --rcheck, --update and --remove are mutually exclusive.
- --name name
- Specify the list to use for the commands. If no name is given then DEFAULT will be used.
- [!] --set
- This will add the source address of the packet to the list. If the source address is already in the list, this will update the existing entry. This will always return success (or failure if ! is passed in).
- --rsource
- Match/save the source address of each packet in the recent list table. This is the default.
- --rdest
- Match/save the destination address of each packet in the recent list table.
- --masknetmask
- Netmask that will be applied to this recent list.
- [!] --rcheck
- Check if the source address of the packet is currently in the list.
- [!] --update
- Like --rcheck, except it will update the "last seen" timestamp if it matches.
- [!] --remove
- Check if the source address of the packet is currently in the list and if so that address will be removed from the list and the rule will return true. If the address is not found, false is returned.
- --seconds seconds
- This option must be used in conjunction with one of --rcheck or --update. When used, this will narrow the match to only happen when the address is in the list and was seen within the last given number of seconds.
- --reap
- This option can only be used in conjunction with --seconds. When used, this will cause entries older than the last given number of seconds to be purged.
- --hitcount hits
- This option must be used in conjunction with one of --rcheck or --update. When used, this will narrow the match to only happen when the address is in the list and packets had been received greater than or equal to the given value. This option may be used along with --seconds to create an even narrower match requiring a certain number of hits within a specific time frame. The maximum value for the hitcount parameter is given by the "ip_pkt_list_tot" parameter of the xt_recent kernel module. Exceeding this value on the command line will cause the rule to be rejected.
- --rttl
- This option may only be used in conjunction with one of --rcheck or --update. When used, this will narrow the match to only happen when the address is in the list and the TTL of the current packet matches that of the packet which hit the --set rule. This may be useful if you have problems with people faking their source address in order to DoS you via this module by disallowing others access to your site by sending bogus packets to you.
Examples:
- iptables -A FORWARD -m recent --name badguy --rcheck --seconds 60 -j DROP
- iptables -A FORWARD -p tcp -i eth0 --dport 139 -m recent --name badguy --set -j DROP
Steve's ipt_recent website (http://snowman.net/projects/ipt_recent/) also has some examples of usage.
/proc/net/xt_recent/* are the current lists of addresses and information about each entry of each list.
Each file in /proc/net/xt_recent/ can be read from to see the current list or written two using the following commands to modify the list:
- echo +addr >/proc/net/xt_recent/DEFAULT
- to add addr to the DEFAULT list
- echo -addr >/proc/net/xt_recent/DEFAULT
- to remove addr from the DEFAULT list
- echo / >/proc/net/xt_recent/DEFAULT
- to flush the DEFAULT list (remove all entries).
The module itself accepts parameters, defaults shown:
- ip_list_tot=100
- Number of addresses remembered per table.
- ip_pkt_list_tot=20
- Number of packets per address remembered.
- ip_list_hash_size=0
- Hash table size. 0 means to calculate it based on ip_list_tot, default: 512.
- ip_list_perms=0644
- Permissions for /proc/net/xt_recent/* files.
- ip_list_uid=0
- Numerical UID for ownership of /proc/net/xt_recent/* files.
- ip_list_gid=0
- Numerical GID for ownership of /proc/net/xt_recent/* files.
rpfilter
Performs a reverse path filter test on a packet. If a reply to the packet would be sent via the same interface that the packet arrived on, the packet will match. Note that, unlike the in-kernel rp_filter, packets protected by IPSec are not treated specially. Combine this match with the policy match if you want this. Also, packets arriving via the loopback interface are always permitted. This match can only be used in the PREROUTING chain of the raw or mangle table.- --loose
- Used to specifiy that the reverse path filter test should match even if the selected output device is not the expected one.
- --validmark
- Also use the packets' nfmark value when performing the reverse path route lookup.
- --accept-local
- This will permit packets arriving from the network with a source address that is also assigned to the local machine.
- --invert
- This will invert the sense of the match. Instead of matching packets that passed the reverse path filter test, match those that have failed it.
Example to log and drop packets failing the reverse path filter test:
iptables -t raw -N RPFILTER
iptables -t raw -A RPFILTER -m rpfilter -j RETURN
iptables -t raw -A RPFILTER -m limit --limit 10/minute -j NFLOG --nflog-prefix "rpfilter drop"
iptables -t raw -A RPFILTER -j DROP
iptables -t raw -A PREROUTING -j RPFILTER
Example to drop failed packets, without logging:
iptables -t raw -A RPFILTER -m rpfilter --invert -j DROP
rt (IPv6-specific)
Match on IPv6 routing header- [!] --rt-type type
- Match the type (numeric).
- [!] --rt-segsleft num[:num]
- Match the `segments left' field (range).
- [!] --rt-len length
- Match the length of this header.
- --rt-0-res
- Match the reserved field, too (type=0)
- --rt-0-addrs addr[,addr...]
- Match type=0 addresses (list).
- --rt-0-not-strict
- List of type=0 addresses is not a strict list.
sctp
- [!] --source-port,--sport port[:port]
- [!] --destination-port,--dport port[:port]
- [!] --chunk-types {all|any|only} chunktype[:flags] [...]
- The flag letter in upper case indicates that the flag is to match if set, in the lower case indicates to match if unset.
Chunk types: DATA INIT INIT_ACK SACK HEARTBEAT HEARTBEAT_ACK ABORT SHUTDOWN SHUTDOWN_ACK ERROR COOKIE_ECHO COOKIE_ACK ECN_ECNE ECN_CWR SHUTDOWN_COMPLETE ASCONF ASCONF_ACK FORWARD_TSN
chunk type available flags
DATA I U B E i u b e
ABORT T t
SHUTDOWN_COMPLETE T t(lowercase means flag should be "off", uppercase means "on")
Examples:
iptables -A INPUT -p sctp --dport 80 -j DROP
iptables -A INPUT -p sctp --chunk-types any DATA,INIT -j DROP
iptables -A INPUT -p sctp --chunk-types any DATA:Be -j ACCEPT
set
This module matches IP sets which can be defined by ipset(8).- [!] --match-set setname flag[,flag]...
- where flags are the comma separated list of src and/or dst specifications and there can be no more than six of them. Hence the command
iptables -A FORWARD -m set --match-set test src,dst- will match packets, for which (if the set type is ipportmap) the source address and destination port pair can be found in the specified set. If the set type of the specified set is single dimension (for example ipmap), then the command will match packets for which the source address can be found in the specified set.
- --return-nomatch
- If the --return-nomatch option is specified and the set type supports the nomatch flag, then the matching is reversed: a match with an element flagged with nomatch returns true, while a match with a plain element returns false.
- ! --update-counters
- If the --update-counters flag is negated, then the packet and byte counters of the matching element in the set won't be updated. Default the packet and byte counters are updated.
- ! --update-subcounters
- If the --update-subcounters flag is negated, then the packet and byte counters of the matching element in the member set of a list type of set won't be updated. Default the packet and byte counters are updated.
- [!] --packets-eq value
- If the packet is matched an element in the set, match only if the packet counter of the element matches the given value too.
- --packets-lt value
- If the packet is matched an element in the set, match only if the packet counter of the element is less than the given value as well.
- --packets-gt value
- If the packet is matched an element in the set, match only if the packet counter of the element is greater than the given value as well.
- [!] -bytes-eq value
- If the packet is matched an element in the set, match only if the byte counter of the element matches the given value too.
- --bytes-lt value
- If the packet is matched an element in the set, match only if the byte counter of the element is less than the given value as well.
- --bytes-gt value
- If the packet is matched an element in the set, match only if the byte counter of the element is greater than the given value as well.
The packet and byte counters related options and flags are ignored when the set was defined without counter support.
The option --match-set can be replaced by --set if that does not *** with an option of other extensions.
Use of -m set requires that ipset kernel support is provided, which, for standard kernels, is the case since Linux 2.6.39.
socket
This matches if an open socket can be found by doing a socket lookup on the packet.- --transparent
- Ignore non-transparent sockets.
state
The "state" extension is a subset of the "conntrack" module. "state" allows access to the connection tracking state for this packet.- [!] --state state
- Where state is a comma separated list of the connection states to match. Only a subset of the states unterstood by "conntrack" are recognized: INVALID, ESTABLISHED, NEW, RELATEDor UNTRACKED. For their description, see the "conntrack" heading in this manpage.
statistic
This module matches packets based on some statistic condition. It supports two distinct modes settable with the --mode option.Supported options:
- --mode mode
- Set the matching mode of the matching rule, supported modes are random and nth.
- [!] --probability p
- Set the probability for a packet to be randomly matched. It only works with the random mode. p must be within 0.0 and 1.0. The supported granularity is in 1/2147483648th increments.
- [!] --every n
- Match one packet every nth packet. It works only with the nth mode (see also the --packet option).
- --packet p
- Set the initial counter value (0 <= p <= n-1, default 0) for the nth mode.
string
This modules matches a given string by using some pattern matching strategy. It requires a linux kernel >= 2.6.14.- --algo {bm|kmp}
- Select the pattern matching strategy. (bm = Boyer-Moore, kmp = Knuth-Pratt-Morris)
- --from offset
- Set the offset from which it starts looking for any matching. If not passed, default is 0.
- --to offset
- Set the offset up to which should be scanned. That is, byte offset-1 (counting from 0) is the last one that is scanned. If not passed, default is the packet size.
- [!] --string pattern
- Matches the given pattern.
- [!] --hex-string pattern
- Matches the given pattern in hex notation.
tcp
These extensions can be used if `--protocol tcp' is specified. It provides the following options:- [!] --source-port,--sport port[:port]
- Source port or port range specification. This can either be a service name or a port number. An inclusive range can also be specified, using the format first:last. If the first port is omitted, "0" is assumed; if the last is omitted, "65535" is assumed. If the first port is greater than the second one they will be swapped. The flag --sport is a convenient alias for this option.
- [!] --destination-port,--dport port[:port]
- Destination port or port range specification. The flag --dport is a convenient alias for this option.
- [!] --tcp-flags mask comp
- Match when the TCP flags are as specified. The first argument mask is the flags which we should examine, written as a comma-separated list, and the second argument comp is a comma-separated list of flags which must be set. Flags are: SYN ACK FIN RST URG PSH ALL NONE. Hence the command
iptables -A FORWARD -p tcp --tcp-flags SYN,ACK,FIN,RST SYN
will only match packets with the SYN flag set, and the ACK, FIN and RST flags unset. - [!] --syn
- Only match TCP packets with the SYN bit set and the ACK,RST and FIN bits cleared. Such packets are used to request TCP connection initiation; for example, blocking such packets coming in an interface will prevent incoming TCP connections, but outgoing TCP connections will be unaffected. It is equivalent to --tcp-flags SYN,RST,ACK,FIN SYN. If the "!" flag precedes the "--syn", the sense of the option is inverted.
- [!] --tcp-option number
- Match if TCP option set.
tcpmss
This matches the TCP MSS (maximum segment size) field of the TCP header. You can only use this on TCP SYN or SYN/ACK packets, since the MSS is only negotiated during the TCP handshake at connection startup time.- [!] --mss value[:value]
- Match a given TCP MSS value or range.
time
This matches if the packet arrival time/date is within a given range. All options are optional, but are ANDed when specified. All times are interpreted as UTC by default.- --datestart YYYY[-MM[-DD[Thh[:mm[:ss]]]]]
- --datestop YYYY[-MM[-DD[Thh[:mm[:ss]]]]]
- Only match during the given time, which must be in ISO 8601 "T" notation. The possible time range is 1970-01-01T00:00:00 to 2038-01-19T04:17:07.
- If --datestart or --datestop are not specified, it will default to 1970-01-01 and 2038-01-19, respectively.
- --timestart hh:mm[:ss]
- --timestop hh:mm[:ss]
- Only match during the given daytime. The possible time range is 00:00:00 to 23:59:59. Leading zeroes are allowed (e.g. "06:03") and correctly interpreted as base-10.
- [!] --monthdays day[,day...]
- Only match on the given days of the month. Possible values are 1 to 31. Note that specifying 31 will of course not match on months which do not have a 31st day; the same goes for 28- or 29-day February.
- [!] --weekdays day[,day...]
- Only match on the given weekdays. Possible values are Mon, Tue, Wed, Thu, Fri, Sat, Sun, or values from 1 to 7, respectively. You may also use two-character variants (Mo, Tu, etc.).
- --contiguous
- When --timestop is smaller than --timestart value, match this as a single time period instead distinct intervals. See EXAMPLES.
- --kerneltz
- Use the kernel timezone instead of UTC to determine whether a packet meets the time regulations.
About kernel timezones: Linux keeps the system time in UTC, and always does so. On boot, system time is initialized from a referential time source. Where this time source has no timezone information, such as the x86 CMOS RTC, UTC will be assumed. If the time source is however not in UTC, userspace should provide the correct system time and timezone to the kernel once it has the information.
Local time is a feature on top of the (timezone independent) system time. Each process has its own idea of local time, specified via the TZ environment variable. The kernel also has its own timezone offset variable. The TZ userspace environment variable specifies how the UTC-based system time is displayed, e.g. when you run date, or what you see on your desktop clock. The TZ string may resolve to different offsets at different dates, which is what enables the automatic time-jumping in userspace. when DST changes. The kernel's timezone offset variable is used when it has to convert between non-UTC sources, such as FAT filesystems, to UTC (since the latter is what the rest of the system uses).
The caveat with the kernel timezone is that Linux distributions may ignore to set the kernel timezone, and instead only set the system time. Even if a particular distribution does set the timezone at boot, it is usually does not keep the kernel timezone offset - which is what changes on DST - up to date. ntpd will not touch the kernel timezone, so running it will not resolve the issue. As such, one may encounter a timezone that is always +0000, or one that is wrong half of the time of the year. As such, using --kerneltz is highly discouraged.
EXAMPLES. To match on weekends, use:
- -m time --weekdays Sa,Su
Or, to match (once) on a national holiday block:
- -m time --datestart 2007-12-24 --datestop 2007-12-27
Since the stop time is actually inclusive, you would need the following stop time to not match the first second of the new day:
- -m time --datestart 2007-01-01T17:00 --datestop 2007-01-01T23:59:59
During lunch hour:
- -m time --timestart 12:30 --timestop 13:30
The fourth Friday in the month:
- -m time --weekdays Fr --monthdays 22,23,24,25,26,27,28
(Note that this exploits a certain mathematical property. It is not possible to say "fourth Thursday OR fourth Friday" in one rule. It is possible with multiple rules, though.)
Matching across days might not do what is expected. For instance,
- -m time --weekdays Mo --timestart 23:00 --timestop 01:00 Will match Monday, for one hour from midnight to 1 a.m., and then again for another hour from 23:00 onwards. If this is unwanted, e.g. if you would like 'match for two hours from Montay 23:00 onwards' you need to also specify the --contiguous option in the example above.
tos
This module matches the 8-bit Type of Service field in the IPv4 header (i.e. including the "Precedence" bits) or the (also 8-bit) Priority field in the IPv6 header.- [!] --tos value[/mask]
- Matches packets with the given TOS mark value. If a mask is specified, it is logically ANDed with the TOS mark before the comparison.
- [!] --tos symbol
- You can specify a symbolic name when using the tos match for IPv4. The list of recognized TOS names can be obtained by calling iptables with -m tos -h. Note that this implies a mask of 0x3F, i.e. all but the ECN bits.
ttl (IPv4-specific)
This module matches the time to live field in the IP header.- [!] --ttl-eq ttl
- Matches the given TTL value.
- --ttl-gt ttl
- Matches if TTL is greater than the given TTL value.
- --ttl-lt ttl
- Matches if TTL is less than the given TTL value.
u32
U32 tests whether quantities of up to 4 bytes extracted from a packet have specified values. The specification of what to extract is general enough to find data at given offsets from tcp headers or payloads.- [!] --u32 tests
- The argument amounts to a program in a small language described below.
- tests := location "=" value | tests "&&" location "=" value
- value := range | value "," range
- range := number | number ":" number
a single number, n, is interpreted the same as n:n. n:m is interpreted as the range of numbers >=n and <=m.
- location := number | location operator number
- operator := "&" | "<<" | ">>" | "@"
The operators &, <<, >> and && mean the same as in C. The = is really a set membership operator and the value syntax describes a set. The @ operator is what allows moving to the next header and is described further below.
There are currently some artificial implementation limits on the size of the tests:
- *
- no more than 10 of "=" (and 9 "&&"s) in the u32 argument
- *
- no more than 10 ranges (and 9 commas) per value
- *
- no more than 10 numbers (and 9 operators) per location
To describe the meaning of location, imagine the following machine that interprets it. There are three registers:
- A is of type char *, initially the address of the IP header
- B and C are unsigned 32 bit integers, initially zero
The instructions are:
- number B = number;
- C = (*(A+B)<<24) + (*(A+B+1)<<16) + (*(A+B+2)<<8) + *(A+B+3)
- &number C = C & number
- << number C = C << number
- >> number C = C >> number
- @number A = A + C; then do the instruction number
Any access of memory outside [skb->data,skb->end] causes the match to fail. Otherwise the result of the computation is the final value of C.
Whitespace is allowed but not required in the tests. However, the characters that do occur there are likely to require shell quoting, so it is a good idea to enclose the arguments in quotes.
Example:
- match IP packets with total length >= 256
- The IP header contains a total length field in bytes 2-3.
- --u32 "0 & 0xFFFF = 0x100:0xFFFF"
- read bytes 0-3
- AND that with 0xFFFF (giving bytes 2-3), and test whether that is in the range [0x100:0xFFFF]
Example: (more realistic, hence more complicated)
- match ICMP packets with icmp type 0
- First test that it is an ICMP packet, true iff byte 9 (protocol) = 1
- --u32 "6 & 0xFF = 1 && ...
- read bytes 6-9, use & to throw away bytes 6-8 and compare the result to 1. Next test that it is not a fragment. (If so, it might be part of such a packet but we cannot always tell.) N.B.: This test is generally needed if you want to match anything beyond the IP header. The last 6 bits of byte 6 and all of byte 7 are 0 iff this is a complete packet (not a fragment). Alternatively, you can allow first fragments by only testing the last 5 bits of byte 6.
... 4 & 0x3FFF = 0 && ...- Last test: the first byte past the IP header (the type) is 0. This is where we have to use the @syntax. The length of the IP header (IHL) in 32 bit words is stored in the right half of byte 0 of the IP header itself.
... 0 >> 22 & 0x3C @ 0 >> 24 = 0"- The first 0 means read bytes 0-3, >>22 means shift that 22 bits to the right. Shifting 24 bits would give the first byte, so only 22 bits is four times that plus a few more bits.&3C then eliminates the two extra bits on the right and the first four bits of the first byte. For instance, if IHL=5, then the IP header is 20 (4 x 5) bytes long. In this case, bytes 0-1 are (in binary) xxxx0101 yyzzzzzz, >>22 gives the 10 bit value xxxx0101yy and &3C gives 010100. @ means to use this number as a new offset into the packet, and read four bytes starting from there. This is the first 4 bytes of the ICMP payload, of which byte 0 is the ICMP type. Therefore, we simply shift the value 24 to the right to throw out all but the first byte and compare the result with 0.
Example:
- TCP payload bytes 8-12 is any of 1, 2, 5 or 8
- First we test that the packet is a tcp packet (similar to ICMP).
- --u32 "6 & 0xFF = 6 && ...
- Next, test that it is not a fragment (same as above).
... 0 >> 22 & 0x3C @ 12 >> 26 & 0x3C @ 8 = 1,2,5,8"- 0>>22&3C as above computes the number of bytes in the IP header. @ makes this the new offset into the packet, which is the start of the TCP header. The length of the TCP header (again in 32 bit words) is the left half of byte 12 of the TCP header. The 12>>26&3C computes this length in bytes (similar to the IP header before). "@" makes this the new offset, which is the start of the TCP payload. Finally, 8 reads bytes 8-12 of the payload and = checks whether the result is any of 1, 2, 5 or 8.
udp
These extensions can be used if `--protocol udp' is specified. It provides the following options:- [!] --source-port,--sport port[:port]
- Source port or port range specification. See the description of the --source-port option of the TCP extension for details.
- [!] --destination-port,--dport port[:port]
- Destination port or port range specification. See the description of the --destination-port option of the TCP extension for details.
unclean (IPv4-specific)
This module takes no options, but attempts to match packets which seem malformed or unusual. This is regarded as experimental.TARGET EXTENSIONS
iptables can use extended target modules: the following are included in the standard distribution.AUDIT
This target allows to create audit records for packets hitting the target. It can be used to record accepted, dropped, and rejected packets. See auditd for additional details.- --type {accept|drop|reject}
- Set type of audit record.
Example:
- iptables -N AUDIT_DROP
- iptables -A AUDIT_DROP -j AUDIT --type drop
- iptables -A AUDIT_DROP -j DROP
CHECKSUM
This target allows to selectively work around broken/old applications. It can only be used in the mangle table.- --checksum-fill
- Compute and fill in the checksum in a packet that lacks a checksum. This is particularly useful, if you need to work around old applications such as dhcp clients, that do not work well with checksum offloads, but don't want to disable checksum offload in your device.
CLASSIFY
This module allows you to set the skb->priority value (and thus classify the packet into a specific CBQ class).- --set-class major:minor
- Set the major and minor class value. The values are always interpreted as hexadecimal even if no 0x prefix is given.
CLUSTERIP (IPv4-specific)
This module allows you to configure a simple cluster of nodes that share a certain IP and MAC address without an explicit load balancer in front of them. Connections are statically distributed between the nodes in this cluster.- --new
- Create a new ClusterIP. You always have to set this on the first rule for a given ClusterIP.
- --hashmode mode
- Specify the hashing mode. Has to be one of sourceip, sourceip-sourceport, sourceip-sourceport-destport.
- --clustermac mac
- Specify the ClusterIP MAC address. Has to be a link-layer multicast address
- --total-nodes num
- Number of total nodes within this cluster.
- --local-node num
- Local node number within this cluster.
- --hash-init rnd
- Specify the random seed used for hash initialization.
CONNMARK
This module sets the netfilter mark value associated with a connection. The mark is 32 bits wide.- --set-xmark value[/mask]
- Zero out the bits given by mask and XOR value into the ctmark.
- --save-mark [--nfmask nfmask] [--ctmask ctmask]
- Copy the packet mark (nfmark) to the connection mark (ctmark) using the given masks. The new nfmark value is determined as follows:
- ctmark = (ctmark & ~ctmask) ^ (nfmark & nfmask)
- i.e. ctmask defines what bits to clear and nfmask what bits of the nfmark to XOR into the ctmark. ctmask and nfmask default to 0xFFFFFFFF.
- --restore-mark [--nfmask nfmask] [--ctmask ctmask]
- Copy the connection mark (ctmark) to the packet mark (nfmark) using the given masks. The new ctmark value is determined as follows:
- nfmark = (nfmark & ~nfmask) ^ (ctmark & ctmask);
- i.e. nfmask defines what bits to clear and ctmask what bits of the ctmark to XOR into the nfmark. ctmask and nfmask default to 0xFFFFFFFF.
- --restore-mark is only valid in the mangle table.
The following mnemonics are available for --set-xmark:
- --and-mark bits
- Binary AND the ctmark with bits. (Mnemonic for --set-xmark 0/invbits, where invbits is the binary negation of bits.)
- --or-mark bits
- Binary OR the ctmark with bits. (Mnemonic for --set-xmark bits/bits.)
- --xor-mark bits
- Binary XOR the ctmark with bits. (Mnemonic for --set-xmark bits/0.)
- --set-mark value[/mask]
- Set the connection mark. If a mask is specified then only those bits set in the mask are modified.
- --save-mark [--mask mask]
- Copy the nfmark to the ctmark. If a mask is specified, only those bits are copied.
- --restore-mark [--mask mask]
- Copy the ctmark to the nfmark. If a mask is specified, only those bits are copied. This is only valid in the mangle table.
CONNSECMARK
This module copies security markings from packets to connections (if unlabeled), and from connections back to packets (also only if unlabeled). Typically used in conjunction with SECMARK, it is valid in the security table (for backwards compatibility with older kernels, it is also valid in the mangle table).- --save
- If the packet has a security marking, copy it to the connection if the connection is not marked.
- --restore
- If the packet does not have a security marking, and the connection does, copy the security marking from the connection to the packet.
CT
The CT target allows to set parameters for a packet or its associated connection. The target attaches a "template" connection tracking entry to the packet, which is then used by the conntrack core when initializing a new ct entry. This target is thus only valid in the "raw" table.- --notrack
- Disables connection tracking for this packet.
- --helper name
- Use the helper identified by name for the connection. This is more flexible than loading the conntrack helper modules with preset ports.
- --ctevents event[,...]
- Only generate the specified conntrack events for this connection. Possible event types are: new, related, destroy, reply, assured, protoinfo, helper, mark (this refers to the ctmark, not nfmark), natseqinfo, secmark (ctsecmark).
- --expevents event[,...]
- Only generate the specified expectation events for this connection. Possible event types are: new.
- --zone id
- Assign this packet to zone id and only have lookups done in that zone. By default, packets have zone 0.
- --timeout name
- Use the timeout policy identified by name for the connection. This is provides more flexible timeout policy definition than global timeout values available at /proc/sys/net/netfilter/nf_conntrack_*_timeout_*.
DNAT
This target is only valid in the nat table, in the PREROUTING and OUTPUT chains, and user-defined chains which are only called from those chains. It specifies that the destination address of the packet should be modified (and all future packets in this connection will also be mangled), and rules should cease being examined. It takes the following options:- --to-destination [ipaddr[-ipaddr]][:port[-port]]
- which can specify a single new destination IP address, an inclusive range of IP addresses. Optionally a port range, if the rule also specifies one of the following protocols: tcp,udp, dccp or sctp. If no port range is specified, then the destination port will never be modified. If no IP address is specified then only the destination port will be modified. In Kernels up to 2.6.10 you can add several --to-destination options. For those kernels, if you specify more than one destination address, either via an address range or multiple --to-destination options, a simple round-robin (one after another in cycle) load balancing takes place between these addresses. Later Kernels (>= 2.6.11-rc1) don't have the ability to NAT to multiple ranges anymore.
- --random
- If option --random is used then port mapping will be randomized (kernel >= 2.6.22).
- --persistent
- Gives a client the same source-/destination-address for each connection. This supersedes the SAME target. Support for persistent mappings is available from 2.6.29-rc2.
- IPv6 support available since Linux kernels >= 3.7.
DSCP
This target allows to alter the value of the DSCP bits within the TOS header of the IPv4 packet. As this manipulates a packet, it can only be used in the mangle table.- --set-dscp value
- Set the DSCP field to a numerical value (can be decimal or hex)
- --set-dscp-class class
- Set the DSCP field to a DiffServ class.
ECN (IPv4-specific)
This target allows to selectively work around known ECN blackholes. It can only be used in the mangle table.- --ecn-tcp-remove
- Remove all ECN bits from the TCP header. Of course, it can only be used in conjunction with -p tcp.
HL (IPv6-specific)
This is used to modify the Hop Limit field in IPv6 header. The Hop Limit field is similar to what is known as TTL value in IPv4. Setting or incrementing the Hop Limit field can potentially be very dangerous, so it should be avoided at any cost. This target is only valid in mangle table.Don't ever set or increment the value on packets that leave your local network!
- --hl-set value
- Set the Hop Limit to `value'.
- --hl-dec value
- Decrement the Hop Limit `value' times.
- --hl-inc value
- Increment the Hop Limit `value' times.
HMARK
Like MARK, i.e. set the fwmark, but the mark is calculated from hashing packet selector at choice. You have also to specify the mark range and, optionally, the offset to start from. ICMP error messages are inspected and used to calculate the hashing.Existing options are:
- --hmark-tuple tuple
- Possible tuple members are: src meaning source address (IPv4, IPv6 address), dst meaning destination address (IPv4, IPv6 address), sport meaning source port (TCP, UDP, UDPlite, SCTP, DCCP), dport meaning destination port (TCP, UDP, UDPlite, SCTP, DCCP), spi meaning Security Parameter Index (AH, ESP), and ct meaning the usage of the conntrack tuple instead of the packet selectors.
- --hmark-mod value (must be > 0)
- Modulus for hash calculation (to limit the range of possible marks)
- --hmark-offset value
- Offset to start marks from.
- For advanced usage, instead of using --hmark-tuple, you can specify custom
- prefixes and masks:
- --hmark-src-prefix cidr
- The source address mask in CIDR notation.
- --hmark-dst-prefix cidr
- The destination address mask in CIDR notation.
- --hmark-sport-mask value
- A 16 bit source port mask in hexadecimal.
- --hmark-dport-mask value
- A 16 bit destination port mask in hexadecimal.
- --hmark-spi-mask value
- A 32 bit field with spi mask.
- --hmark-proto-mask value
- An 8 bit field with layer 4 protocol number.
- --hmark-rnd value
- A 32 bit random custom value to feed hash calculation.
Examples:
iptables -t mangle -A PREROUTING -m conntrack --ctstate NEW
-j HMARK --hmark-tuple ct,src,dst,proto --hmark-offset 10000 --hmark-mod 10 --hmark-rnd 0xfeedcafe
iptables -t mangle -A PREROUTING -j HMARK --hmark-offset 10000 --hmark-tuple src,dst,proto --hmark-mod 10 --hmark-rnd 0xdeafbeef
IDLETIMER
This target can be used to identify when interfaces have been idle for a certain period of time. Timers are identified by labels and are created when a rule is set with a new label. The rules also take a timeout value (in seconds) as an option. If more than one rule uses the same timer label, the timer will be restarted whenever any of the rules get a hit. One entry for each timer is created in sysfs. This attribute contains the timer remaining for the timer to expire. The attributes are located under the xt_idletimer class:/sys/class/xt_idletimer/timers/<label>
When the timer expires, the target module sends a sysfs notification to the userspace, which can then decide what to do (eg. disconnect to save power).
- --timeout amount
- This is the time in seconds that will trigger the notification.
- --label string
- This is a unique identifier for the timer. The maximum length for the label string is 27 characters.
LED
This creates an LED-trigger that can then be attached to system indicator lights, to blink or illuminate them when certain packets pass through the system. One example might be to light up an LED for a few minutes every time an SSH connection is made to the local machine. The following options control the trigger behavior:- --led-trigger-id name
- This is the name given to the LED trigger. The actual name of the trigger will be prefixed with "netfilter-".
- --led-delay ms
- This indicates how long (in milliseconds) the LED should be left illuminated when a packet arrives before being switched off again. The default is 0 (blink as fast as possible.) The special value inf can be given to leave the LED on permanently once activated. (In this case the trigger will need to be manually detached and reattached to the LED device to switch it off again.)
- --led-always-blink
- Always make the LED blink on packet arrival, even if the LED is already on. This allows notification of new packets even with long delay values (which otherwise would result in a silent prolonging of the delay time.)
- Example:
- Create an LED trigger for incoming SSH traffic:
- iptables -A INPUT -p tcp --dport 22 -j LED --led-trigger-id ssh
- Then attach the new trigger to an LED:
- echo netfilter-ssh >/sys/class/leds/ledname/trigger
LOG (IPv6-specific)
Turn on kernel logging of matching packets. When this option is set for a rule, the Linux kernel will print some information on all matching packets (like most IPv6 IPv6-header fields) via the kernel log (where it can be read with dmesg or syslogd). This is a "non-terminating target", i.e. rule traversal continues at the next rule. So if you want to LOG the packets you refuse, use two separate rules with the same matching criteria, first using target LOG then DROP (or REJECT).- --log-level level
- Level of logging, which can be (system-specific) numeric or a mnemonic. Possible values are (in decreasing order of priority): emerg, alert, crit, error, warning, notice, infoor debug.
- --log-prefix prefix
- Prefix log messages with the specified prefix; up to 29 letters long, and useful for distinguishing messages in the logs.
- --log-tcp-sequence
- Log TCP sequence numbers. This is a security risk if the log is readable by users.
- --log-tcp-options
- Log options from the TCP packet header.
- --log-ip-options
- Log options from the IPv6 packet header.
- --log-uid
- Log the userid of the process which generated the packet.
LOG (IPv4-specific)
Turn on kernel logging of matching packets. When this option is set for a rule, the Linux kernel will print some information on all matching packets (like most IP header fields) via the kernel log (where it can be read with dmesg or syslogd). This is a "non-terminating target", i.e. rule traversal continues at the next rule. So if you want to LOG the packets you refuse, use two separate rules with the same matching criteria, first using target LOG then DROP (or REJECT).- --log-level level
- Level of logging, which can be (system-specific) numeric or a mnemonic. Possible values are (in decreasing order of priority): emerg, alert, crit, error, warning, notice, infoor debug.
- --log-prefix prefix
- Prefix log messages with the specified prefix; up to 29 letters long, and useful for distinguishing messages in the logs.
- --log-tcp-sequence
- Log TCP sequence numbers. This is a security risk if the log is readable by users.
- --log-tcp-options
- Log options from the TCP packet header.
- --log-ip-options
- Log options from the IP packet header.
- --log-uid
- Log the userid of the process which generated the packet.
MARK
This target is used to set the Netfilter mark value associated with the packet. It can, for example, be used in conjunction with routing based on fwmark (needs iproute2). If you plan on doing so, note that the mark needs to be set in the PREROUTING chain of the mangle table to affect routing. The mark field is 32 bits wide.- --set-xmark value[/mask]
- Zeroes out the bits given by mask and XORs value into the packet mark ("nfmark"). If mask is omitted, 0xFFFFFFFF is assumed.
- --set-mark value[/mask]
- Zeroes out the bits given by mask and ORs value into the packet mark. If mask is omitted, 0xFFFFFFFF is assumed.
The following mnemonics are available:
- --and-mark bits
- Binary AND the nfmark with bits. (Mnemonic for --set-xmark 0/invbits, where invbits is the binary negation of bits.)
- --or-mark bits
- Binary OR the nfmark with bits. (Mnemonic for --set-xmark bits/bits.)
- --xor-mark bits
- Binary XOR the nfmark with bits. (Mnemonic for --set-xmark bits/0.)
MASQUERADE (IPv6-specific)
This target is only valid in the nat table, in the POSTROUTING chain. It should only be used with dynamically assigned IPv6 (dialup) connections: if you have a static IP address, you should use the SNAT target. Masquerading is equivalent to specifying a mapping to the IP address of the interface the packet is going out, but also has the effect that connections areforgotten when the interface goes down. This is the correct behavior when the next dialup is unlikely to have the same interface address (and hence any established connections are lost anyway).- --to-ports port[-port]
- This specifies a range of source ports to use, overriding the default SNAT source port-selection heuristics (see above). This is only valid if the rule also specifies -p tcp or -p udp.
- --random
- Randomize source port mapping If option --random is used then port mapping will be randomized.
-
MASQUERADE (IPv4-specific)
This target is only valid in the nat table, in the POSTROUTING chain. It should only be used with dynamically assigned IP (dialup) connections: if you have a static IP address, you should use the SNAT target. Masquerading is equivalent to specifying a mapping to the IP address of the interface the packet is going out, but also has the effect that connections areforgotten when the interface goes down. This is the correct behavior when the next dialup is unlikely to have the same interface address (and hence any established connections are lost anyway).- --to-ports port[-port]
- This specifies a range of source ports to use, overriding the default SNAT source port-selection heuristics (see above). This is only valid if the rule also specifies -p tcp or -p udp.
- --random
- Randomize source port mapping If option --random is used then port mapping will be randomized (kernel >= 2.6.21).
-
MIRROR (IPv4-specific)
This is an experimental demonstration target which inverts the source and destination fields in the IP header and retransmits the packet. It is only valid in the INPUT, FORWARD andPREROUTING chains, and user-defined chains which are only called from those chains. Note that the outgoing packets are NOT seen by any packet filtering chains, connection tracking or NAT, to avoid loops and other problems.NETMAP
This target allows you to statically map a whole network of addresses onto another network of addresses. It can only be used from rules in the nat table.- --to address[/mask]
- Network address to map to. The resulting address will be constructed in the following way: All 'one' bits in the mask are filled in from the new `address'. All bits that are zero in the mask are filled in from the original address.
- IPv6 support available since Linux kernels >= 3.7.
NFLOG
This target provides logging of matching packets. When this target is set for a rule, the Linux kernel will pass the packet to the loaded logging backend to log the packet. This is usually used in combination with nfnetlink_log as logging backend, which will multicast the packet through a netlink socket to the specified multicast group. One or more userspace processes may subscribe to the group to receive the packets. Like LOG, this is a non-terminating target, i.e. rule traversal continues at the next rule.- --nflog-group nlgroup
- The netlink group (0 - 2^16-1) to which packets are (only applicable for nfnetlink_log). The default value is 0.
- --nflog-prefix prefix
- A prefix string to include in the log message, up to 64 characters long, useful for distinguishing messages in the logs.
- --nflog-range size
- The number of bytes to be copied to userspace (only applicable for nfnetlink_log). nfnetlink_log instances may specify their own range, this option overrides it.
- --nflog-threshold size
- Number of packets to queue inside the kernel before sending them to userspace (only applicable for nfnetlink_log). Higher values result in less overhead per packet, but increase delay until the packets reach userspace. The default value is 1.
NFQUEUE
This target is an extension of the QUEUE target. As opposed to QUEUE, it allows you to put a packet into any specific queue, identified by its 16-bit queue number. It can only be used with Kernel versions 2.6.14 or later, since it requires the nfnetlink_queue kernel support. The queue-balance option was added in Linux 2.6.31, queue-bypass in 2.6.39.- --queue-num value
- This specifies the QUEUE number to use. Valid queue numbers are 0 to 65535. The default value is 0.
- --queue-balance value:value
- This specifies a range of queues to use. Packets are then balanced across the given queues. This is useful for multicore systems: start multiple instances of the userspace program on queues x, x+1, .. x+n and use "--queue-balance x:x+n". Packets belonging to the same connection are put into the same nfqueue.
- --queue-bypass
- By default, if no userspace program is listening on an NFQUEUE, then all packets that are to be queued are dropped. When this option is used, the NFQUEUE rule is silently bypassed instead. The packet will move on to the next rule.
- --queue-cpu-fanout
- Available starting Linux kernel 3.10. When used together with --queue-balance this will use the CPU ID as an index to map packets to the queues. The idea is that you can improve performance if there's a queue per CPU. This requires --queue-balance to be specified.
NOTRACK
This target disables connection tracking for all packets matching that rule. It is obsoleted by -j CT --notrack. Like CT, NOTRACK can only be used in the raw table.RATEEST
The RATEEST target collects statistics, performs rate estimation calculation and saves the results for later evaluation using the rateest match.- --rateest-name name
- Count matched packets into the pool referred to by name, which is freely choosable.
- --rateest-interval amount{s|ms|us}
- Rate measurement interval, in seconds, milliseconds or microseconds.
- --rateest-ewmalog value
- Rate measurement averaging time constant.
REDIRECT
This target is only valid in the nat table, in the PREROUTING and OUTPUT chains, and user-defined chains which are only called from those chains. It redirects the packet to the machine itself by changing the destination IP to the primary address of the incoming interface (locally-generated packets are mapped to the localhost address, 127.0.0.1 for IPv4 and ::1 for IPv6).- --to-ports port[-port]
- This specifies a destination port or range of ports to use: without this, the destination port is never altered. This is only valid if the rule also specifies one of the following protocols: tcp, udp, dccp or sctp.
- --random
- If option --random is used then port mapping will be randomized (kernel >= 2.6.22).
- IPv6 support available starting Linux kernels >= 3.7.
REJECT (IPv6-specific)
This is used to send back an error packet in response to the matched packet: otherwise it is equivalent to DROP so it is a terminating TARGET, ending rule traversal. This target is only valid in the INPUT, FORWARD and OUTPUT chains, and user-defined chains which are only called from those chains. The following option controls the nature of the error packet returned:- --reject-with type
- The type given can be icmp6-no-route, no-route, icmp6-adm-prohibited, adm-prohibited, icmp6-addr-unreachable, addr-unreach, icmp6-port-unreachable or port-unreach which return the appropriate ICMPv6 error message (port-unreach is the default). Finally, the option tcp-reset can be used on rules which only match the TCP protocol: this causes a TCP RST packet to be sent back. This is mainly useful for blocking ident (113/tcp) probes which frequently occur when sending mail to broken mail hosts (which won't accept your mail otherwise). tcp-reset can only be used with kernel versions 2.6.14 or later.
REJECT (IPv4-specific)
This is used to send back an error packet in response to the matched packet: otherwise it is equivalent to DROP so it is a terminating TARGET, ending rule traversal. This target is only valid in the INPUT, FORWARD and OUTPUT chains, and user-defined chains which are only called from those chains. The following option controls the nature of the error packet returned:- --reject-with type
- The type given can be icmp-net-unreachable, icmp-host-unreachable, icmp-port-unreachable, icmp-proto-unreachable, icmp-net-prohibited, icmp-host-prohibited or icmp-admin-prohibited (*) which return the appropriate ICMP error message (port-unreachable is the default). The option tcp-reset can be used on rules which only match the TCP protocol: this causes a TCP RST packet to be sent back. This is mainly useful for blocking ident (113/tcp) probes which frequently occur when sending mail to broken mail hosts (which won't accept your mail otherwise).
(*) Using icmp-admin-prohibited with kernels that do not support it will result in a plain DROP instead of REJECT
SAME (IPv4-specific)
Similar to SNAT/DNAT depending on chain: it takes a range of addresses (`--to 1.2.3.4-1.2.3.7') and gives a client the same source-/destination-address for each connection.N.B.: The DNAT target's --persistent option replaced the SAME target.
- --to ipaddr[-ipaddr]
- Addresses to map source to. May be specified more than once for multiple ranges.
- --nodst
- Don't use the destination-ip in the calculations when selecting the new source-ip
- --random
- Port mapping will be forcibly randomized to avoid attacks based on port prediction (kernel >= 2.6.21).
SECMARK
This is used to set the security mark value associated with the packet for use by security subsystems such as SELinux. It is valid in the security table (for backwards compatibility with older kernels, it is also valid in the mangle table). The mark is 32 bits wide.- --selctx security_context
SET
This module adds and/or deletes entries from IP sets which can be defined by ipset(8).- --add-set setname flag[,flag...]
- add the address(es)/port(s) of the packet to the set
- --del-set setname flag[,flag...]
- delete the address(es)/port(s) of the packet from the set
- where flag(s) are src and/or dst specifications and there can be no more than six of them.
- --timeout value
- when adding an entry, the timeout value to use instead of the default one from the set definition
- --exist
- when adding an entry if it already exists, reset the timeout value to the specified one or to the default from the set definition
Use of -j SET requires that ipset kernel support is provided, which, for standard kernels, is the case since Linux 2.6.39.
SNAT
This target is only valid in the nat table, in the POSTROUTING chain. It specifies that the source address of the packet should be modified (and all future packets in this connection will also be mangled), and rules should cease being examined. It takes the following options:- --to-source [ipaddr[-ipaddr]][:port[-port]]
- which can specify a single new source IP address, an inclusive range of IP addresses. Optionally a port range, if the rule also specifies one of the following protocols: tcp, udp,dccp or sctp. If no port range is specified, then source ports below 512 will be mapped to other ports below 512: those between 512 and 1023 inclusive will be mapped to ports below 1024, and other ports will be mapped to 1024 or above. Where possible, no port alteration will occur. In Kernels up to 2.6.10, you can add several --to-source options. For those kernels, if you specify more than one source address, either via an address range or multiple --to-source options, a simple round-robin (one after another in cycle) takes place between these addresses. Later Kernels (>= 2.6.11-rc1) don't have the ability to NAT to multiple ranges anymore.
- --random
- If option --random is used then port mapping will be randomized (kernel >= 2.6.21).
- --persistent
- Gives a client the same source-/destination-address for each connection. This supersedes the SAME target. Support for persistent mappings is available from 2.6.29-rc2.
- IPv6 support available since Linux kernels >= 3.7.
TCPMSS
This target allows to alter the MSS value of TCP SYN packets, to control the maximum size for that connection (usually limiting it to your outgoing interface's MTU minus 40 for IPv4 or 60 for IPv6, respectively). Of course, it can only be used in conjunction with -p tcp.This target is used to overcome criminally braindead ISPs or servers which block "ICMP Fragmentation Needed" or "ICMPv6 Packet Too Big" packets. The symptoms of this problem are that everything works fine from your Linux firewall/router, but machines behind it can never exchange large packets:
- 1.
- Web browsers connect, then hang with no data received.
- 2.
- Small mail works fine, but large emails hang.
- 3.
- ssh works fine, but scp hangs after initial handshaking.
Workaround: activate this option and add a rule to your firewall configuration like:
iptables -t mangle -A FORWARD -p tcp --tcp-flags SYN,RST SYN
-j TCPMSS --clamp-mss-to-pmtu- --set-mss value
- Explicitly sets MSS option to specified value. If the MSS of the packet is already lower than value, it will not be increased (from Linux 2.6.25 onwards) to avoid more problems with hosts relying on a proper MSS.
- --clamp-mss-to-pmtu
- Automatically clamp MSS value to (path_MTU - 40 for IPv4; -60 for IPv6). This may not function as desired where asymmetric routes with differing path MTU exist --- the kernel uses the path MTU which it would use to send packets from itself to the source and destination IP addresses. Prior to Linux 2.6.25, only the path MTU to the destination IP address was considered by this option; subsequent kernels also consider the path MTU to the source IP address.
These options are mutually exclusive.
TCPOPTSTRIP
This target will strip TCP options off a TCP packet. (It will actually replace them by NO-OPs.) As such, you will need to add the -p tcp parameters.- --strip-options option[,option...]
- Strip the given option(s). The options may be specified by TCP option number or by symbolic name. The list of recognized options can be obtained by calling iptables with -j TCPOPTSTRIP -h.
TEE
The TEE target will clone a packet and redirect this clone to another machine on the local network segment. In other words, the nexthop must be the target, or you will have to configure the nexthop to forward it further if so desired.- --gateway ipaddr
- Send the cloned packet to the host reachable at the given IP address. Use of 0.0.0.0 (for IPv4 packets) or :: (IPv6) is invalid.
To forward all incoming traffic on eth0 to an Network Layer logging box:
-t mangle -A PREROUTING -i eth0 -j TEE --gateway 2001:db8::1
TOS
This module sets the Type of Service field in the IPv4 header (including the "precedence" bits) or the Priority field in the IPv6 header. Note that TOS shares the same bits as DSCP and ECN. The TOS target is only valid in the mangle table.- --set-tos value[/mask]
- Zeroes out the bits given by mask (see NOTE below) and XORs value into the TOS/Priority field. If mask is omitted, 0xFF is assumed.
- --set-tos symbol
- You can specify a symbolic name when using the TOS target for IPv4. It implies a mask of 0xFF (see NOTE below). The list of recognized TOS names can be obtained by calling iptables with -j TOS -h.
The following mnemonics are available:
- --and-tos bits
- Binary AND the TOS value with bits. (Mnemonic for --set-tos 0/invbits, where invbits is the binary negation of bits. See NOTE below.)
- --or-tos bits
- Binary OR the TOS value with bits. (Mnemonic for --set-tos bits/bits. See NOTE below.)
- --xor-tos bits
- Binary XOR the TOS value with bits. (Mnemonic for --set-tos bits/0. See NOTE below.)
NOTE: In Linux kernels up to and including 2.6.38, with the exception of longterm releases 2.6.32 (>=.42), 2.6.33 (>=.15), and 2.6.35 (>=.14), there is a bug whereby IPv6 TOS mangling does not behave as documented and differs from the IPv4 version. The TOS mask indicates the bits one wants to zero out, so it needs to be inverted before applying it to the original TOS field. However, the aformentioned kernels forgo the inversion which breaks --set-tos and its mnemonics.
TPROXY
This target is only valid in the mangle table, in the PREROUTING chain and user-defined chains which are only called from this chain. It redirects the packet to a local socket without changing the packet header in any way. It can also change the mark value which can then be used in advanced routing rules. It takes three options:- --on-port port
- This specifies a destination port to use. It is a required option, 0 means the new destination port is the same as the original. This is only valid if the rule also specifies -p tcp or -p udp.
- --on-ip address
- This specifies a destination address to use. By default the address is the IP address of the incoming interface. This is only valid if the rule also specifies -p tcp or -p udp.
- --tproxy-mark value[/mask]
- Marks packets with the given value/mask. The fwmark value set here can be used by advanced routing. (Required for transparent proxying to work: otherwise these packets will get forwarded, which is probably not what you want.)
TRACE
This target marks packets so that the kernel will log every rule which match the packets as those traverse the tables, chains, rules.A logging backend, such as ipt_LOG or nfnetlink_log, must be loaded for this to be visible. The packets are logged with the string prefix: "TRACE: tablename:chainname:type:rulenum " where type can be "rule" for plain rule, "return" for implicit rule at the end of a user defined chain and "policy" for the policy of the built in chains.
It can only be used in the raw table.
TTL (IPv4-specific)
This is used to modify the IPv4 TTL header field. The TTL field determines how many hops (routers) a packet can traverse until it's time to live is exceeded.Setting or incrementing the TTL field can potentially be very dangerous, so it should be avoided at any cost. This target is only valid in mangle table.
Don't ever set or increment the value on packets that leave your local network!
- --ttl-set value
- Set the TTL value to `value'.
- --ttl-dec value
- Decrement the TTL value `value' times.
- --ttl-inc value
- Increment the TTL value `value' times.
ULOG (IPv4-specific)
This target provides userspace logging of matching packets. When this target is set for a rule, the Linux kernel will multicast this packet through a netlink socket. One or more userspace processes may then subscribe to various multicast groups and receive the packets. Like LOG, this is a "non-terminating target", i.e. rule traversal continues at the next rule.- --ulog-nlgroup nlgroup
- This specifies the netlink group (1-32) to which the packet is sent. Default value is 1.
- --ulog-prefix prefix
- Prefix log messages with the specified prefix; up to 32 characters long, and useful for distinguishing messages in the logs.
- --ulog-cprange size
- Number of bytes to be copied to userspace. A value of 0 always copies the entire packet, regardless of its size. Default is 0.
- --ulog-qthreshold size
- Number of packet to queue inside kernel. Setting this value to, e.g. 10 accumulates ten packets inside the kernel and transmits them as one netlink multipart message to userspace. Default is 1 (for backwards compatibility).
Index
- NAME
- SYNOPSIS
- MATCH EXTENSIONS
- addrtype
- ah (IPv6-specific)
- ah (IPv4-specific)
- cluster
- comment
- connbytes
- connlimit
- connmark
- conntrack
- cpu
- dccp
- devgroup
- dscp
- dst (IPv6-specific)
- ecn
- esp
- eui64 (IPv6-specific)
- frag (IPv6-specific)
- hashlimit
- hbh (IPv6-specific)
- helper
- hl (IPv6-specific)
- icmp (IPv4-specific)
- icmp6 (IPv6-specific)
- iprange
- ipv6header (IPv6-specific)
- ipvs
- length
- limit
- mac
- mark
- mh (IPv6-specific)
- multiport
- nfacct
- osf
- owner
- physdev
- pkttype
- policy
- quota
- rateest
- realm (IPv4-specific)
- recent
- rpfilter
- rt (IPv6-specific)
- sctp
- set
- socket
- state
- statistic
- string
- tcp
- tcpmss
- time
- tos
- ttl (IPv4-specific)
- u32
- udp
- unclean (IPv4-specific)
- TARGET EXTENSIONS
- AUDIT
- CHECKSUM
- CLASSIFY
- CLUSTERIP (IPv4-specific)
- CONNMARK
- CONNSECMARK
- CT
- DNAT
- DSCP
- ECN (IPv4-specific)
- HL (IPv6-specific)
- HMARK
- IDLETIMER
- LED
- LOG (IPv6-specific)
- LOG (IPv4-specific)
- MARK
- MASQUERADE (IPv6-specific)
- MASQUERADE (IPv4-specific)
- MIRROR (IPv4-specific)
- NETMAP
- NFLOG
- NFQUEUE
- NOTRACK
- RATEEST
- REDIRECT
- REJECT (IPv6-specific)
- REJECT (IPv4-specific)
- SAME (IPv4-specific)
- SECMARK
- SET
- SNAT
- TCPMSS
- TCPOPTSTRIP
- TEE
- TOS
- TPROXY
- TRACE
- TTL (IPv4-specific)
- ULOG (IPv4-specific)
This document was created by man2html, using the manual pages.
Time: 14:41:34 GMT, May 10, 2013

 浙公网安备 33010602011771号
浙公网安备 33010602011771号