curl,wget,下载速度
http://hi.baidu.com/green_lizard/item/79118bb45ff6f0eb62388e9b
http://blog.sina.com.cn/s/blog_7a9c22c70101cvth.html
输出=>0.081:0.272:0.779 |
清单 1 给出对一个流行的新闻站点执行 curl 命令的情况.输出通常是 HTML 代码,通过 -o 参数发送到/dev/null.-s 参数去掉所有状态信息.-w 参数让 curl 写出表 1 列出的计时器的状态信息:
表 1. curl 使用的计时器
| 计时器 | 描述 |
|---|---|
| time_connect | 建立到服务器的 TCP 连接所用的时间 |
| time_starttransfer | 在发出请求之后,Web 服务器返回数据的第一个字节所用的时间 |
| time_total | 完成请求所用的时间 |
| time_namelookup | DNS解析时间,从请求开始到DNS解析完毕所用时间(记得关掉 Linux 的 nscd 的服务测试) |
| speed_download | 下载速度,单位-字节每秒。 |
这些计时器都相对于事务的起始时间,甚至要先于 Domain Name Service(DNS)查询.因此,在发出请求之后,Web 服务器处理请求并开始发回数据所用的时间是 0.272 – 0.081 = 0.191 秒.客户机从服务器下载数据所用的时间是 0.779 – 0.272 = 0.507 秒.
通过观察 curl 数据及其随时间变化的趋势,可以很好地了解站点对用户的响应性.以上变量会按CURL认为合适的格式输出,输出变量需要按照%{variable_name}的格式,如果需要输出%,double一下即可,即%%,同时,\n是换行,\r是回车,\t是TAB。
当然,Web 站点不仅仅由页面组成.它还有图像、JavaScript 代码、CSS 和 cookie 要处理.curl 很适合了解单一元素的响应时间,但是有时候需要了解整个页面的装载速度.
http://bbs.chinaunix.net/thread-3640561-1-1.html
监控站点首页下载时间:
curl -o /dev/null -s -w ‘%{time_total}’ http://www.miotour.com
curl -o /dev/null -s -w ‘%{http_code}’ http://www.miotour.com
curl -o /dev/null -s -w %{http_code}:%{time_connect}:%{time_starttransfer}:%{time_total} http://www.miotour.com
结果:2.547
-s 静默输出;没有-s的话就是下面的情况,这是在脚本等情况下不需要的信息。
监控首页各项时间指标:
curl -o /dev/null -sw '%{http_code}:%{time_total}:%{time_connect}:%{time_starttransfer}\n' http://www.miotour.com
curl -o /dev/null -s -w ‘%{time_connect}:%{time_starttransfer}:%{time_total}\n’ http://www.miotour.com
结果: 0.244: 1.044: 2.672
时间指标解释 :
time_connect 建立到服务器的 TCP 连接所用的时间
time_starttransfer 在发出请求之后,Web 服务器返回数据的第一个字节所用的时间
time_total 完成请求所用的时间
在发出请求之后,Web 服务器处理请求并开始发回数据所用的时间是
(time_starttransfer)1.044 - (time_connect)0.244 = 0.8 秒
客户机从服务器下载数据所用的时间是
(time_total)2.672 - (time_starttransfer)1.044 = 1.682 秒
指定特定主机IP地址访问网站
curl -x 61.135.169.105:80 http://www.baidu.com
curl -x 61.135.169.125:80 http://www.baidu.com
======================================
http://www.ttlsa.com/perl/get-response-tome/
获取站点的各类响应时间
有时候为了测试网络情况,需要返回每个阶段的耗时时间,比如DNS解析耗时,建立连接所消耗的时间,从建立连接到准备传输所使用的时间,从建立连接到传输开始所使用的时间,整个过程耗时,下载的数据量,下载速度,上传数据量,上传速度等等。下面的脚本获取以上信息:
CURL的资料参见: http://curl.haxx.se/libcurl/c/curl_easy_getinfo.html

shell命令下也有相同的命令如下所示:
不解释了,具体参见 man curl
如需转载请注明出处:http://www.ttlsa.com/html/1465.html
http://digdeeply.org/archives/05102012.html
使用 cURL 获取站点的各类响应时间 – dns解析时间,响应时间,传输时间
使用 cURL 获取站点的各类响应时间 – dns解析时间,响应时间,传输时间等:
|
1
|
curl -o /dev/null -s -w %{http_code}:%{http_connect}:%{content_type}:%{time_namelookup}:%{time_redirect}:%{time_pretransfer}:%{time_connect}:%{time_starttransfer}:%{time_total}:%{speed_download} digdeeply.org |
这是一个本人博客站点执行 curl 命令的情况。输出通常是 HTML 代码,通过 -o 参数发送到 /dev/null。-s 参数去掉所有状态信息。-w 参数让 curl 输出的计时器的状态信息。

一次http请求中的各个时间段-dns解析,等待服务器响应,获取内容等
下边对-w参数做个详细的解释,由我(DigDeeply)翻译。有不对的地方请大家指出。(英文原文:http://curl.haxx.se/docs/manpage.html)
以下是可用的变量名:
-w, --write-out
以下变量会按CURL认为合适的格式输出,输出变量需要按照%{variable_name}的格式,如果需要输出%,double一下即可,即%%,同时,\n是换行,\r是回车,\t是TAB。
url_effective The URL that was fetched last. This is most meaningful if you've told curl to follow location: headers.
filename_effective The ultimate filename that curl writes out to. This is only meaningful if curl is told to write to a file with the --remote-name or --output option. It's most useful in combination with the --remote-header-name option. (Added in 7.25.1)
http_code http状态码,如200成功,301转向,404未找到,500服务器错误等。(The numerical response code that was found in the last retrieved HTTP(S) or FTP(s) transfer. In 7.18.2 the alias response_code was added to show the same info.)
http_connect The numerical code that was found in the last response (from a proxy) to a curl CONNECT request. (Added in 7.12.4)
time_total 总时间,按秒计。精确到小数点后三位。 (The total time, in seconds, that the full operation lasted. The time will be displayed with millisecond resolution.)
time_namelookup DNS解析时间,从请求开始到DNS解析完毕所用时间。(The time, in seconds, it took from the start until the name resolving was completed.)
time_connect 连接时间,从开始到建立TCP连接完成所用时间,包括前边DNS解析时间,如果需要单纯的得到连接时间,用这个time_connect时间减去前边time_namelookup时间。以下同理,不再赘述。(The time, in seconds, it took from the start until the TCP connect to the remote host (or proxy) was completed.)
time_appconnect 连接建立完成时间,如SSL/SSH等建立连接或者完成三次握手时间。(The time, in seconds, it took from the start until the SSL/SSH/etc connect/handshake to the remote host was completed. (Added in 7.19.0))
time_pretransfer 从开始到准备传输的时间。(The time, in seconds, it took from the start until the file transfer was just about to begin. This includes all pre-transfer commands and negotiations that are specific to the particular protocol(s) involved.)
time_redirect 重定向时间,包括到最后一次传输前的几次重定向的DNS解析,连接,预传输,传输时间。(The time, in seconds, it took for all redirection steps include name lookup, connect, pretransfer and transfer before the final transaction was started. time_redirect shows the complete execution time for multiple redirections. (Added in 7.12.3))
time_starttransfer 开始传输时间。在发出请求之后,Web 服务器返回数据的第一个字节所用的时间(The time, in seconds, it took from the start until the first byte was just about to be transferred. This includes time_pretransfer and also the time the server needed to calculate the result.)
size_download 下载大小。(The total amount of bytes that were downloaded.)
size_upload 上传大小。(The total amount of bytes that were uploaded.)
size_header 下载的header的大小(The total amount of bytes of the downloaded headers.)
size_request 请求的大小。(The total amount of bytes that were sent in the HTTP request.)
speed_download 下载速度,单位-字节每秒。(The average download speed that curl measured for the complete download. Bytes per second.)
speed_upload 上传速度,单位-字节每秒。(The average upload speed that curl measured for the complete upload. Bytes per second.)
content_type 就是content-Type,不用多说了,这是一个访问我博客首页返回的结果示例(text/html; charset=UTF-8);(The Content-Type of the requested document, if there was any.)
num_connects Number of new connects made in the recent transfer. (Added in 7.12.3)
num_redirects Number of redirects that were followed in the request. (Added in 7.12.3)
redirect_url When a HTTP request was made without -L to follow redirects, this variable will show the actual URL a redirect would take you to. (Added in 7.18.2)
ftp_entry_path The initial path libcurl ended up in when logging on to the remote FTP server. (Added in 7.15.4)
ssl_verify_result ssl认证结果,返回0表示认证成功。( The result of the SSL peer certificate verification that was requested. 0 means the verification was successful. (Added in 7.19.0))
若多次使用-w参数,按最后一个的格式输出。If this option is used several times, the last one will be used.
转载请注明:来自:DigDeeply’s Blog–使用 cURL 获取站点的各类响应时间 – dns解析时间,响应时间,传输时间
==========================
http://blog.csdn.net/ithomer/article/details/7626929
Linux抓取网页,简单方法是直接通过 curl 或 wget 两种命令。
curl 和 wget 命令,目前已经支持Linux和Windows平台,后续将介绍。
curl 和 wget支持协议
curl 支持 http,https,ftp,ftps,scp,telnet等网络协议,详见手册 man curl
wget支持 http,https,ftp网络协议,详见手册man wget
curl 和 wget下载安装
1、Ubuntu平台
wget 命令安装: sudo apt-get install wget (普通用户登录,需输入密码; root账户登录,无需输入密码)
curl 命令安装: sudo apt-get install curl (同 wget)
2、Windows平台
wget 下载地址:wget for Windows
curl 下载地址:curl Download
wget 和 curl 打包下载地址:Windows平台下的wget和curl工具包
Windows平台下,curl下载解压后,直接是curl.exe格式,拷贝到系统命令目录下 C:\Windows\System32 即可
Windows平台下,wget下载解压后,是wget-1.11.4-1-setup.exe格式,需要安装;安装后,在环境变量 - 系统变量 - Path 中添加其安装目录即可
curl 和 wget抓取实例
抓取网页,主要有url 网址和proxy代理两种方式,下面以抓取“百度”首页为例,分别介绍
1、 url 网址方式抓取
(1)curl下载百度首页内容,保存在baidu_html文件中
curl http://www.baidu.com/ -o baidu_html
(2)wget下载百度首页内容,保存在baidu_html文件中
wget http://www.baidu.com/ -O baidu_html2
有的时候,由于网速/数据丢包/服务器宕机/等原因,导致暂时无法成功下载网页
这时,可能就需要多次尝试发送连接,请求服务器的响应;如果多次仍无响应,则可以确认服务器出问题了
(1)curl多次尝试连接
curl --retry 10 --retry-delay 60 --retry-max-time 60 http://www.baidu.com/ -o baidu_html
注: --retry表示重试次数; --retry-delay表示两次重试之间的时间间隔(秒为单位); --retry-max-time表示在此最大时间内只容许重试一次(一般与--retry-delay相同)
(2)wget多次尝试连接
wget -t 10 -w 60 -T 30 http://www.baidu.com/ -O baidu_html2
注:-t(--tries)表示重试次数; -w表示两次重试之间的时间间隔(秒为单位); -T表示连接超时时间,如果超时则连接不成功,继续尝试下一次连接
附: curl 判断服务器是否响应,还可以通过一段时间内下载获取的字节量来间接判断,命令格式如下:
curl -y 60 -Y 1 -m 60 http://www.baidu.com/ -o baidu_html
注:-y表示测试网速的时间; -Y表示-y这段时间下载的字节量(byte为单位); -m表示容许请求连接的最大时间,超过则连接自动断掉放弃连接
2、 proxy代理方式抓取
proxy代理下载,是通过连接一台中间服务器间接下载url网页的过程,不是url直接连接网站服务器下载
两个著名的免费代理网站:
freeproxylists.net(全球数十个国家的免费代理,每日都更新)
xroxy.com(通过设置端口类型、代理类型、国家名称进行筛选)
在freeproxylists.net网站,选择一台中国的免费代理服务器为例,来介绍proxy代理抓取网页:
218.107.21.252:8080(ip为218.107.21.252;port为8080,中间以冒号“:”隔开,组成一个套接字)
(1)curl 通过代理抓取百度首页
curl -x 218.107.21.252:8080 -o aaaaa http://www.baidu.com(port 常见有80,8080,8086,8888,3128等,默认为80)
注:-x表示代理服务器(ip:port),即curl先连接到代理服务器218.107.21.252:8080,然后再通过218.107.21.252:8080下载百度首页,最后218.107.21.252:8080把下载的百度首页传给curl至本地(curl不是直接连接百度服务器下载首页的,而是通过一个中介代理来完成)
(2)wget 通过代理抓取百度首页
wget通过代理下载,跟curl不太一样,需要首先设置代理服务器的http_proxy=ip:port
以ubuntu为例,在当前用户目录(cd ~),新建一个wget配置文件(.wgetrc),输入代理配置:
http_proxy=218.107.21.252:8080
然后再输入wget抓取网页的命令:
wget http://www.baidu.com -O baidu_html2
代理下载截图:
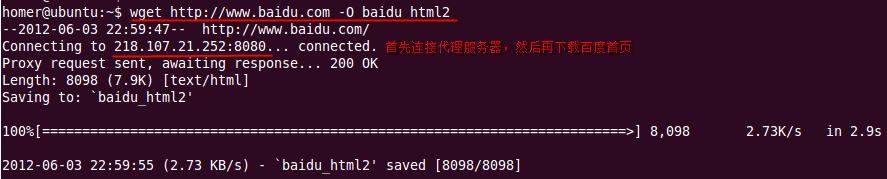
=======================
抓取的百度首页数据(截图):
其它命令参数用法,同url网址方式,在此不再赘述
ftp协议、迭代子目录等更多的curl 和 wget用法,可以man查看帮助手册
知识拓展:
在国内,由于某种原因一般难以直接访问国外某些敏感网站,需要通过 VPN 或 代理服务器才能访问
如果校园网和教育网有IPv6,则可以通过sixxs.org免费代理访问facebook、twitter、六维空间等网站
其实,除了VPN 和 IPv6+sixxs.org代理方式外,普通用户还是有其它途径访问到国外网站
下面介绍两个著名的免费代理网站:
freeproxylists.net(全球数十个国家的免费代理,每日都更新)
xroxy.com(通过设置端口类型、代理类型、国家名称进行筛选)
curl 项目实例
使用curl + freeproxylists.net免费代理,实现了全球12国家google play游戏排名的网页抓取以及趋势图查询(抓取网页模块全部使用Shell编写,核心代码约1000行)
游戏排名趋势图请见我先前的博客:JFreeChart项目实例
=======================================================
https://wen.lu/#q=curl+wget+%E4%B8%8B%E8%BD%BD%E9%80%9F%E5%BA%A6+
http://www.cnblogs.com/kudosharry/articles/2335880.html
curl vs Wget
CURL
-
基于libcurl库,libcurl是一个稳定的跨平台的类库,任何人可以免费使用其API进行开发。CURL继承了libcurl库的优良设计,这是它能成为优秀的命令行工具的重要原因。
- 管道(Pipes). CURL不仅仅遵循 传统UNIXstyle, 它在对输入和输出做更多的处理,贯彻了 "everything is a pipe" 的设计思想。

- 返回值(Return codes). curl为一系列应用返回多种结果(错误),适用于很多情况。
- 单点传送 curl仅仅单点传送数据。它只会传送用户指定的URLS,并不包含任何递归下载的逻辑,也不对html进行任何解析。
- 多协议支持. curl 支持的协议有: FTP, FTPS, HTTP, HTTPS, SCP, SFTP, TFTP, TELNET, DICT, LDAP, LDAPS, FILE, POP3, IMAP, SMTP 和 RTSP 在写这篇文章时,Wget仅仅支持 HTTP, HTTPS 和 FTP.
- 适应更多的平台: curl比wget运行在更多的平台上面,虽然curl设计当初并没有打算这样。比如: OS/400, TPF 和其他很多非UNIX的平台。
- 更强大的SSL库. curl能应用于多个不同的 SSL/TLS 库, 并提供了更多的可控性和对协议的广泛支持。
- curl支持更多的 HTTP 认证方式
- 双向通信. curl 提供了上传能力,Wget仅仅支持HTTP post 方式
- HTTP multipart/form-data 的发送能力, 这使得用户可以进行HTTP上传,模拟浏览器的行为和HTTP认证等,提供了更多操作的可能。
- 压缩. curl 支持GZIP和 inflate Content-Encoding 并且自动进行解压缩操作。
Wget
- Wget 仅仅支持命令行方式运行. 没有类库,不提供API等。
- 递归! Wget 与CURL的最大区别也是Wget的最大的优势是可以进行递归的下载,可以一次下载一个HTML页面 或者ftp列表中的所有内容。

- 更久的历史. Wget 可以追溯到 1995年,curl则要在 1997年之后出现.
- 参与开发的人员相对较. 我打赌,任何参与这两个项目的人都能感觉到这一点。
- HTTP 1.0. Wget 仍然仅仅使用 HTTP 1.0,但是它一直工作很好,并且对于最终用户没有任何影响。curl在2001年三月的时候就开始支持 HTTP 1.1 了(仍然保留对 1.0 请求的支持).
- GPL. Wget 100% 遵循 GPL v3 协议,. curl 则是 MIT licensed.
- GNU. Wget 是 GNU 项目的一部分 并且所有的版权归于 FSF. curl项目则是独立的,独立于任何组织,所有的版权属于Daniel。(哇!)
- Wget 不需要任何额外参数 就能从URL下载文件到本地, 而curl需要至少 -o 或者 -O这两个参数.
在对网站内容是否更新进行测试时,最常用的两个工具就是wget和curl。不过两个工具之间还是有一些小区别,甚至很可能影响到测试结论的。记录一下:
1、在查看response-header的时候,我们习惯用的是wget -S和curl -I,但是:wget -S的时候,发送的是GET请求,而curl -I发送的是HEAD请求。如果测试url此时没有被缓存过,直接使用curl -I进行测试,永远都会返回MISS状态。所以最好先wget一次,再用curl -I。
2、在查看下载速度时,常常发现wget和curl耗时差距较大。因为wget默认使用HTTP/1.0协议,不显式指定 –header=”Accept-Encoding: gzip,deflate”的情况下,传输的是未经压缩的文件。而curl使用HTTP/1.1协议,默认接受就是压缩格式。
3、在测试缓存层配置时,有时发现wget可以HIT的东西,curl却始终MISS。对此可以开启debug模式进行观察跟踪。
wget自带有-d参数,直接显示request-header;curl只有-D参数,在采用GET请求的时候,将response-header另存 成文件,所以只好在squid上debug请求处理流程(当然也可以去网络抓包),结果发现,curl的GET请求,都带有”Pragma: no-cache”!而wget需要另行指定–no-cache才会。按照squid的默认配置,对client_no_cache是透传的,所以 curl永远MISS,除非squid上配置了ignore-reload/reload-into-ims两个参数,才可能强制HIT。
首先申明标题党!
前几天,有一张图片访问404(从第三方站点拉去),后来查到原因是下载超过5s(wget带了超时参数--timeout=5),所以下载失败。但是直接访问原图又是非常快,基本感觉不到延时。开始怀疑是服务器网络原因,用host获取该域名的ip地址,无法ping通。
初步结论是:网络原因,无法ping通
服务器可能会设置禁ping,于是我就用wget不带超时下载了一次,发现确实可以下载,只是耗时非常严重,如图:

花了20s,才将此图完整下下来。换成curl来下载此图,结果如图:

结果就很明显,curl仅用1s的时间下载此图,而wget却用了20s才做完相同的事儿。我这并不是说curl的性能优于wget啊,换成其他网站url,时间消耗就差不多。那到底是什么原因才导致了如此巨大的差异了,勾起了我的好奇心。
用strace、tcpdump分别跟踪了wget和curl,摘取了相对核心的地方来做分析。
wget的strace结果
由于strace的内容比较多比较杂,为了方便分析摘出了比较核心的几处
- 11:52:37.877356 execve("/usr/bin/wget", ["wget", "http://newpic.jxnews.com.cn/0/11"], [/* 30 vars */]) = 0
- 11:52:37.899984 socket(PF_INET, SOCK_DGRAM, IPPROTO_IP) = 3
- 11:52:37.900043 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, 28) = 0
- 11:52:37.900114 fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
- 11:52:37.900165 fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK) = 0
- 11:52:37.900215 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}])
- 11:52:37.900284 sendto(3, "\353J\1\0\0\1\0\0\0\0\0\0\6newpic\6jxnews\3com\2c"..., 38, MSG_NOSIGNAL, NULL, 0) = 38
- 11:52:37.900773 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 (Timeout)
- 11:52:47.900462 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}])
- 11:52:47.900529 sendto(3, "\353J\1\0\0\1\0\0\0\0\0\0\6newpic\6jxnews\3com\2c"..., 38, MSG_NOSIGNAL, NULL, 0) = 38
- 11:52:47.900606 poll([{fd=3, events=POLLIN}], 1, 5000) = 0 (Timeout)
- 11:52:57.900996 close(3) = 0
- 11:52:57.901134 socket(PF_INET, SOCK_DGRAM, IPPROTO_IP) = 3
- 11:52:57.901192 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, 28) = 0
- 11:52:57.901270 fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
- 11:52:57.901322 fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK) = 0
- 11:52:57.901374 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}])
- 11:52:57.901436 sendto(3, "c\237\1\0\0\1\0\0\0\0\0\0\6newpic\6jxnews\3com\2c"..., 50, MSG_NOSIGNAL, NULL, 0) = 50
- 11:52:57.901646 poll([{fd=3, events=POLLIN}], 1, 5000) = 1 ([{fd=3, revents=POLLIN}])
- 11:52:57.902350 ioctl(3, FIONREAD, [125]) = 0
- 11:52:57.902421 recvfrom(3, "c\237\201\203\0\1\0\0\0\1\0\0\6newpic\6jxnews\3com\2c"..., 1024, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, [16]) = 125
- 11:52:57.902516 close(3) = 0
- 11:52:57.902592 socket(PF_INET, SOCK_DGRAM, IPPROTO_IP) = 3
- 11:52:57.902647 connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, 28) = 0
- 11:52:57.902707 fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
- 11:52:57.902757 fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK) = 0
- 11:52:57.902808 poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}])
- 11:52:57.902881 sendto(3, "\343\25\1\0\0\1\0\0\0\0\0\0\6newpic\6jxnews\3com\2c"..., 38, MSG_NOSIGNAL, NULL, 0) = 38
- 11:52:57.903027 poll([{fd=3, events=POLLIN}], 1, 5000) = 1 ([{fd=3, revents=POLLIN}])
- 11:52:57.983323 ioctl(3, FIONREAD, [92]) = 0
- 11:52:57.983394 recvfrom(3, "\343\25\201\200\0\1\0\1\0\2\0\0\6newpic\6jxnews\3com\2c"..., 1024, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, [16]) = 92
- 11:52:57.983482 close(3) = 0
- 11:52:57.983584 write(2, "59.52.28.153", 12) = 12
- 11:52:57.983707 write(2, "\n", 1) = 1
- 11:52:57.983825 open("/usr/share/locale/zh.GBK/LC_MESSAGES/wget.mo", O_RDONLY) = -1 ENOENT (No such file or directory)
- 11:52:57.983905 open("/usr/share/locale/zh/LC_MESSAGES/wget.mo", O_RDONLY) = -1 ENOENT (No such file or directory)
- 11:52:57.983979 write(2, "Connecting to newpic.jxnews.com."..., 55) = 55
- 11:52:57.984073 socket(PF_INET, SOCK_STREAM, IPPROTO_IP) = 3
- 11:52:57.984139 connect(3, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("59.52.28.153")}, 16) = 0
- 11:52:58.045641 write(2, "\322\321\301\254\275\323\241\243\n", 9) = 9
- 11:52:58.045760 select(4, NULL, [3], NULL, {900, 0}) = 1 (out [3], left {900, 0})
- 11:52:58.045832 write(3, "GET /0/11/84/34/11843462_991618."..., 155) = 155
在11:52:37这一刻,执行wget命令。第一个较为重要的动作是做dns解析,向域名服务器10.55.21.254发起了两次数据包的长度是38字节查询请求,得到两次timeout,在11:52:57正式关闭了请求。
系统尝试向dns服务器10.55.21.254发送长度为50字节的数据包的查询请求,并获得返回结果(这里无法知道获知返回结果)。
系统在获得返回结果后,第四次向10.55.21.254发送请求,获得返回结果后,得到url的ip地址,发起了http请求。
通过已经分析,可以得到几个结论:
1、对域名解析方式上的差异导致wget和curl的耗时差别巨大
2、第三次改变数据包的查询,虽然获取得了返回,但并没有获取域名的ip
wget的tcpdump结果
tcpdump的结果图:

相对于strace的日志,tcpdump的就比较干净,为了方便分析,还是摘除了关键部分
- 11:52:37.900351 IP wapcms-169.54429 > dns.domain: 60234+ AAAA? newpic.jxnews.com.cn. (38)
- 11:52:47.900568 IP wapcms-169.54429 > dns.domain: 60234+ AAAA? newpic.jxnews.com.cn. (38)
- 11:52:57.901476 IP wapcms-169.46106 > dns.domain: 25503+ AAAA? newpic.jxnews.com.cn.localdomain. (50)
- 11:52:57.902233 IP dns.domain > wapcms-169.46106: 25503 NXDomain 0/1/0 (125)
- 11:52:57.902924 IP wapcms-169.58634 > dns.domain: 58133+ A? newpic.jxnews.com.cn. (38)
- 11:52:57.983135 IP dns.domain > wapcms-169.58634: 58133 1/2/0 A 59.52.28.153 (92)
很清晰的与strace的结果对应上了,两次38字节的数据包timeout,一次50字节的数据包,获得返回
NXDomain 0/1/0 (125),一次38字节的请求获得域名的ip地址:59.52.28.153
curl的strace结果
- execve("/usr/bin/curl", ["curl", "http://newpic.jxnews.com.cn/0/11", "-o", "1.jpg"], [/* 31 vars */]) = 0
- = 0
- socket(PF_INET, SOCK_DGRAM, IPPROTO_IP) = 3
- connect(3, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, 28) = 0
- fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
- fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK) = 0
- poll([{fd=3, events=POLLOUT}], 1, 0) = 1 ([{fd=3, revents=POLLOUT}])
- sendto(3, "\370T\1\0\0\1\0\0\0\0\0\0\6newpic\6jxnews\3com\2c"..., 38, MSG_NOSIGNAL, NULL, 0) = 38
- poll([{fd=3, events=POLLIN}], 1, 5000) = 1 ([{fd=3, revents=POLLIN}])
- ioctl(3, FIONREAD, [92]) = 0
- recvfrom(3, "\370T\201\200\0\1\0\1\0\2\0\0\6newpic\6jxnews\3com\2c"..., 1024, 0, {sa_family=AF_INET, sin_port=htons(53), sin_addr=inet_addr("10.55.21.254")}, [16]) = 92
- close(3)
- = 0
- socket(PF_INET, SOCK_STREAM, IPPROTO_TCP) = 3
- fcntl(3, F_GETFL) = 0x2 (flags O_RDWR)
- fcntl(3, F_SETFL, O_RDWR|O_NONBLOCK) = 0
- connect(3, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr("120.203.216.133")}, 16) = -1 EINPROGRESS (Operation now in progress)
- poll([{fd=3, events=POLLOUT}], 1, 300000) = 1 ([{fd=3, revents=POLLOUT}])
- getsockopt(3, SOL_SOCKET, SO_ERROR, [0], [4]) = 0
- sendto(3, "GET /0/11/84/34/11843462_991618."..., 194, MSG_NOSIGNAL, NULL, 0) = 194
很明显的发现,curl通过一次dns查询就获取了url的ip地址,然后就发起http请求。
curl的tcpdump结果
- 15:19:39.744520 IP wapcms-169.48990 > dns.domain: 63572+ A? newpic.jxnews.com.cn. (38)
- 15:19:39.744905 IP wapcms-169.38502 > dns.domain: 13836+ PTR? 254.21.55.10.in-addr.arpa. (43)
- 15:19:39.745626 IP dns.domain > wapcms-169.38502: 13836* 1/1/0 (86)
- 15:19:39.793797 IP dns.domain > wapcms-169.48990: 63572 1/2/0 A 120.203.216.133 (92)
- 15:19:39.793890 IP wapcms-169.31975 > dns.domain: 54867+ PTR? 133.216.203.120.in-addr.arpa. (46)
- 15:19:39.848460 IP dns.domain > wapcms-169.31975: 54867 NXDomain 0/1/0 (102)
从上面基本上可以得到结论,wget与curl在域名解析上有很大的不同。
通过查阅dns协议和tcpdump的输出数据格式得到结论是:
wget兼容IPv6,而curl不兼容,该url的dns解析20s的时间发生在解析IPv6上
引申:
host命令兼容IPv6 dig不兼容 (均为不带任何附加参数)
追加证明:
wget强制使用IPv4进行dns的结果如图:

注:
dns协议见附件,相关附带知识如下:
tcpdupm中dns数据包格式
域名服务请求的格式是
src>dst:idop?flagsqtypeqclassname(len)
h2opolo.1538>helios.domain:3+A?ucbvax.berkeley.edu.(37)
主机h2opolo访问helios上的域名服务,询问和ucbvax.berkeley.edu.关联的地址记录(qtype=A).查询号是 `3'.` +'表明设置了递归请求标志.查询长度是37字节,不包括UDP和IP头.查询操作是普通的Query操作,因此op域可以忽略.如果op设置成其他什么 东西,它应该显示在`3'和`+'之间.类似的,qclass是普通的C_IN类型,也被忽略了.其他类型的qclass应该在`A'后面显示.
Tcpdump 会检查一些不规则情况,相应的结果作为补充域放在方括号内:如果某个查询包含回答,名字服务或管理机构部分,就把ancount,nscount,或 arcount显示成`[na]',`[nn]'或`[nau]',这里的n代表相应的数量.如果在第二和第三字节中,任何一个回答位(AA,RA或 rcode)或任何一个`必须为零'的位被置位,就显示`[b2&3=x]',这里的x是报头第二和第三字节的16进制数.
UDP名字服务回答
名字服务回答的格式是
src>dst:idoprcodeflagsa/n/autypeclassdata(len)
helios.domain>h2opolo.1538:33/3/7A128.32.137.3(273)
helios.domain>h2opolo.1537:2NXDomain*0/1/0(97)
第一个例子里,helios回答了h2opolo发出的标识为3的询问,一共是3个回答记录,3个名字服务记录和7个管理结构记录.第一个回答纪录的类型是 A(地址),数据是internet地址128.32.137.3.回答的全长为273字节,不包括UDP和IP报头.作为A记录的class (C_IN)可以忽略op(询问)和rcode(NoError).
在第二个例子里,helios对标识为2的询问作出域名不存在(NXDomain)的回答,没有回答记录,一个名字服务记录,而且没有管理结构.
`*'表明设置了权威回答(authoritativeanswer).由于没有回答记录,这里就不显示type,class和data.
其他标志字符可以显示为`-'(没有设置递归有效(RA))和`|'(设置消息截短(TC)).如果`问题'部分没有有效的内容,就显示`[nq]'.
注意名字服务的询问和回答一般说来比较大,68字节的snaplen可能无法捕捉到足够的报文内容.如果你的确在研究名字服务的情况,可以使用-s选项增大捕捉缓冲区.`-s128'应该效果不错了.
IPv6的正向解析与反向解析
a. 正向解析
IPv4的地址正向解析的资源记录是“A”记录。IPv6地址的正向解析目前有两种资源记录,即,“AAAA”和“A6”记录。其中, “AAAA”较早提出<4>,它是对“A”记录的简单扩展,由于IP地址由32位扩展到128位,扩大了4倍,所以资源记录由“A”扩大成4 个“A”。“AAAA”用来表示域名和IPv6地址的对应关系,并不支持地址的层次性。
“A6”在RFC2874<5>中提出,它是把一个IPv6地址与多个“A6”记录建立联系,每个“A6”记录都只包含了IPv6地址的一部分,结合后拼装成一个完整的IPv6地址。“A6”记录支持一些“AAAA”所不具备的新特性,如地址聚合,地址更改(Renumber)等。
首先,“A6”记录方式根据TLA、NLA和SLA的分配层次把128位的IPv6的地址分解成为若干级的地址前缀和地址后缀,构成了一个地址链。每个地址前缀和地址后缀都是地址链上的一环,一个完整的地址链就组成一个IPv6地址。这种思想符合IPv6地址的层次结构,从而支持地址聚合。
其次,用户在改变ISP时,要随ISP改变而改变其拥有的IPv6地址。如果手工修改用户子网中所有在DNS中注册的地址,是一件非常繁琐的事情。而在用“A6”记录表示的地址链中,只要改变地址前缀对应的ISP名字即可,可以大大减少DNS中资源记录的修改。并且在地址分配层次中越靠近底层,所需要改动的越少。
b. 反向解析
IPv6反向解析的记录和IPv4一样,是“PTR”,但地址表示形式有两种。一种是用 “.”分隔的半字节16进制数字格式(Nibble Format),低位地址在前,高位地址在后,域后缀是“IP6.INT.”。另一种是二进制串(Bit-string)格式,以“\<”开头, 16进制地址(无分隔符,高位在前,低位在后)居中,地址后加“>”,域后缀是“IP6.ARPA.”。半字节16进制数字格式与“AAAA”对应,是对IPv4的简单扩展。二进制串格式与“A6”记录对应,地址也象“A6”一样,可以分成多级地址链表示,每一级的授权用“DNAME”记录。和 “A6”一样,二进制串格式也支持地址层次特性。
总之,以地址链形式表示的IPv6地址体现了地址的层次性,支持地址聚合和地址更改。但是,由于一次完整的地址解析分成多个步骤进行,需要按照地址的分配层次关系到不同的DNS服务器进行查询。所有的查询都成功才能得到完整的解析结果。这势必会延长解析时间,出错的机会也增加。因此,需要进一步改进DNS地址链功能,提高域名解析的速度才能为用户提供理想的服务。
本文出自 “邱凯的技术博客” 博客,请务必保留此出处http://xdebug.blog.51cto.com/1135229/1130815
curl常用命令
1.下载单个文件,默认将输出打印到标准输出中(STDOUT)中
curl http://img.xxx.com
2.通过-o/-O选项保存下载的文件到指定的文件中:
-o:将文件保存为命令行中指定的文件名的文件中
curl http://img.xxx.com/2014-09-27/1411874364337558.jpg -o test.jpg
-O:使用URL中默认的文件名保存文件到本地
curl -O http://img.xxx.com/2014-09-27/1411874364337558.jpg
同时获取多个文件
1 curl -O URL1 -O URL2
若同时从同一站点下载多个文件时,curl会尝试重用链接(connection)。
curl -O http://img.xxx.com/2014-09-27/1411874364337558.jpg -O http://img.xxx.com/2014-09-27/1411874364337559.jpg
断点续传
通过使用-C选项可对大文件使用断点续传功能,如:
复制代码
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/gettext/manual/gettext.html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C – -O http://www.gnu.org/software/gettext/manual/gettext.html
7 ############### 21.1%
复制代码
对CURL使用网络限速
通过–limit-rate选项对CURL的最大网络使用进行限制
1 # 下载速度最大不会超过1000B/second
2
3 curl –limit-rate 1000B -O http://www.gnu.org/software/gettext/manual/gettext.html
下载指定时间内修改过的文件
当下载一个文件时,可对该文件的最后修改日期进行判断,如果该文件在指定日期内修改过,就进行下载,否则不下载。
该功能可通过使用-z选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
CURL授权
在访问需要授权的页面时,可通过-u选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从FTP服务器下载文件
CURL同样支持FTP下载,若在url中指定的是某个文件路径而非具体的某个要下载的文件名,CURL则会列出该目录下的所有文件名而并非下载该目录下的所有文件
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到FTP服务器
通过 -T 选项可将指定的本地文件上传到FTP服务器上
复制代码
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T “{file1,file2}” ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T – ftp://ftp.testserver.com/myfile_1.txt
复制代码
获取更多信息
通过使用 -v 和 -trace获取更多的链接信息
通过字典查询单词
复制代码
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
复制代码
为CURL设置代理
-x 选项可以为CURL添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站整理
保存与使用网站cookie信息
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
默认curl使用GET方式请求数据,这种方式下直接通过URL传递数据
可以通过 –data/-d 方式指定使用POST方式传递数据
复制代码
1 # GET
2 curl -u username https://api.github.com/user?access_token=XXXXXXXXXX
3
4 # POST
5 curl -u username –data “param1=value1¶m2=value” https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl –data @filename https://github.api.com/authorizations
复制代码
注:默认情况下,通过POST方式传递过去的数据中若有特殊字符,首先需要将特殊字符转义在传递给服务器端,如value值中包含有空格,则需要先将空格转换成%20,如:
1 curl -d “value%201″ http://hostname.com
在新版本的CURL中,提供了新的选项 –data-urlencode,通过该选项提供的参数会自动转义特殊字符。
1 curl –data-urlencode “value 1″ http://hostname.com
除了使用GET和POST协议外,还可以通过 -X 选项指定其它协议,如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl –form “fileupload=@filename.txt” http://hostname/resource
原文地址:http://www.cnblogs.com/gbyukg/p/3326825.html
———————————————————————————
使用curl / wget命令上传下载FTP
curl可以在shell下轻松上传下载ftp上的文件,相比ftp命令更具有优势,因为它能在单命令条件下,下载或者上传一个ftp文件,甚至可以删除文件。
下面看实例:
1、列出ftp服务器上的目录列表:
curl ftp://www.quany.info/ –user name:passwd
curl ftp://www.quany.info/ –u name:passwd#简洁写法
curl ftp://name:passwd@www.quany.info #简洁写法2
2、只列出目录,不显示进度条
curl ftp://www.quany.info –u name:passwd-s
3、下载一个文件:
curl ftp://www.quany.info/size.zip –u name:passwd-o size.zip
4、上载一个文件:
curl –u name:passwd-T size.mp3 ftp://www.quany.info/mp3/
5、从服务器上删除文件(使用curl传递ftp协议的DELE命令):
curl –u name:passwdftp://www.quany.info/ -X ‘DELE mp3/size.mp3′
6、另外curl不支持递归下载,不过可以用数组方式下载文件,比如我们要下载1-10.gif连续命名的文件:
curl –u name:passwdftp://www.quany.info/img/[1-10].gif –O #O字母大写
7、要连续下载多个文件:
curl –u name:passwdftp://www.quany.info/img/[one,two,three].jpg –O #O字母大写
8、wget下载文件:
用户账户:quany
用户密码:123456
ftp下载
wget ftp://quany:123456@www.quany.info/xxx.zip
http下载
wget –http-user=quany –http-passwd=123456 http://www.quany.info/xxx.zip
9、wget参数:
wget的参数较多,但大部分应用只需要如下几个常用的参数:
-r 递归;对于HTTP主机,wget首先下载URL指定的文件,然后(如果该文件是一个HTML文档的话)递归下载该文件所引用(超级连接)的所有文件(递归深度由参数-l指定)。对FTP主机,该参数意味着要下载URL指定的目录中的所有文件,递归方法与HTTP主机类似。
-N 时间戳:该参数指定wget只下载更新的文件,也就是说,与本地目录中的对应文件的长度和最后修改日期一样的文件将不被下载。
-m 镜像:相当于同时使用-r和-N参数。
-l 设置递归级数;默认为5。-l1相当于不递归;-l0为无穷递归;注意,当递归深度增加时,文件数量将呈指数级增长。
-t 设置重试次数。当连接中断(或超时)时,wget将试图重新连接。如果指定-t0,则重试次数设为无穷多。
-c 指定断点续传功能。实际上,wget默认具有断点续传功能,只有当你使用别的ftp工具下载了某一文件的一部分,并希望wget接着完成此工作的时候,才需要指定此参数。
使用举例:
wget -m -l4 -t0 http://www.quany.info/
将在本地硬盘建立http://www.quany.info/的镜像,镜像文件存入当前目录下一个名为www.quany.info的子目录中(你也可以使用-nH参数指定不建立该子目录,而直接在当前目录下建立镜像的目录结构),递归深度为4,重试次数为无穷(若连接出现问题,wget将坚韧不拔地永远重试下去,知道任务完成!)
另外一些使用频率稍低的参数如下:
-A acclist / -R rejlist:
这两个参数用于指定wget接受或排除的文件扩展名,多个名称之间用逗号隔开。例如,假设我们不想下载MPEG视频影像文件和.AU声音文件,可使用如下参数:
-R mpg,mpeg,au
其它参数还有:
-L 只扩展相对连接,该参数对于抓取指定站点很有用,可以避免向宿主主机的其他目录扩散。例如,某个人网站地址为:http://www.quany.info/~ppfl/,使用如下命令行:
wget -L http://www.quany.info/~ppfl/
则只提取该个人网站,而不涉及主机www.quany.info上的其他目录。
-k 转换连接:HTML文件存盘时,将其中的非相对连接转换成为相对连接。
-X 在下载FTP主机上的文件时,排除若干指定的目录
另外,下面参数用于设置wget的工作界面:
-v 设置wget输出详细的工作信息。
-q 设置wget不输出任何信息。
原文件:http://www.cnblogs.com/mfryf/p/3901327.html
=============
http://liangfm117.blog.163.com/blog/static/6913364420132282050624/
http://blog.chinaunix.net/uid-28671666-id-3502208.html
http://blog.51yip.com/linux/1049.html
linux curl 命令详解,以及实例
linux curl是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称url为下载工具。
一,curl命令参数,有好多我没有用过,也不知道翻译的对不对,如果有误的地方,还请指正。
- -a/--append 上传文件时,附加到目标文件
- -A/--user-agent <string> 设置用户代理发送给服务器
- - anyauth 可以使用“任何”身份验证方法
- -b/--cookie <name=string/file> cookie字符串或文件读取位置
- - basic 使用HTTP基本验证
- -B/--use-ascii 使用ASCII /文本传输
- -c/--cookie-jar <file> 操作结束后把cookie写入到这个文件中
- -C/--continue-at <offset> 断点续转
- -d/--data <data> HTTP POST方式传送数据
- --data-ascii <data> 以ascii的方式post数据
- --data-binary <data> 以二进制的方式post数据
- --negotiate 使用HTTP身份验证
- --digest 使用数字身份验证
- --disable-eprt 禁止使用EPRT或LPRT
- --disable-epsv 禁止使用EPSV
- -D/--dump-header <file> 把header信息写入到该文件中
- --egd-file <file> 为随机数据(SSL)设置EGD socket路径
- --tcp-nodelay 使用TCP_NODELAY选项
- -e/--referer 来源网址
- -E/--cert <cert[:passwd]> 客户端证书文件和密码 (SSL)
- --cert-type <type> 证书文件类型 (DER/PEM/ENG) (SSL)
- --key <key> 私钥文件名 (SSL)
- --key-type <type> 私钥文件类型 (DER/PEM/ENG) (SSL)
- --pass <pass> 私钥密码 (SSL)
- --engine <eng> 加密引擎使用 (SSL). "--engine list" for list
- --cacert <file> CA证书 (SSL)
- --capath <directory> CA目录 (made using c_rehash) to verify peer against (SSL)
- --ciphers <list> SSL密码
- --compressed 要求返回是压缩的形势 (using deflate or gzip)
- --connect-timeout <seconds> 设置最大请求时间
- --create-dirs 建立本地目录的目录层次结构
- --crlf 上传是把LF转变成CRLF
- -f/--fail 连接失败时不显示http错误
- --ftp-create-dirs 如果远程目录不存在,创建远程目录
- --ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
- --ftp-pasv 使用 PASV/EPSV 代替端口
- --ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
- --ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
- --ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
- -F/--form <name=content> 模拟http表单提交数据
- -form-string <name=string> 模拟http表单提交数据
- -g/--globoff 禁用网址序列和范围使用{}和[]
- -G/--get 以get的方式来发送数据
- -h/--help 帮助
- -H/--header <line>自定义头信息传递给服务器
- --ignore-content-length 忽略的HTTP头信息的长度
- -i/--include 输出时包括protocol头信息
- -I/--head 只显示文档信息
- 从文件中读取-j/--junk-session-cookies忽略会话Cookie
- - 界面<interface>指定网络接口/地址使用
- - krb4 <级别>启用与指定的安全级别krb4
- -j/--junk-session-cookies 读取文件进忽略session cookie
- --interface <interface> 使用指定网络接口/地址
- --krb4 <level> 使用指定安全级别的krb4
- -k/--insecure 允许不使用证书到SSL站点
- -K/--config 指定的配置文件读取
- -l/--list-only 列出ftp目录下的文件名称
- --limit-rate <rate> 设置传输速度
- --local-port<NUM> 强制使用本地端口号
- -m/--max-time <seconds> 设置最大传输时间
- --max-redirs <num> 设置最大读取的目录数
- --max-filesize <bytes> 设置最大下载的文件总量
- -M/--manual 显示全手动
- -n/--netrc 从netrc文件中读取用户名和密码
- --netrc-optional 使用 .netrc 或者 URL来覆盖-n
- --ntlm 使用 HTTP NTLM 身份验证
- -N/--no-buffer 禁用缓冲输出
- -o/--output 把输出写到该文件中
- -O/--remote-name 把输出写到该文件中,保留远程文件的文件名
- -p/--proxytunnel 使用HTTP代理
- --proxy-anyauth 选择任一代理身份验证方法
- --proxy-basic 在代理上使用基本身份验证
- --proxy-digest 在代理上使用数字身份验证
- --proxy-ntlm 在代理上使用ntlm身份验证
- -P/--ftp-port <address> 使用端口地址,而不是使用PASV
- -Q/--quote <cmd>文件传输前,发送命令到服务器
- -r/--range <range>检索来自HTTP/1.1或FTP服务器字节范围
- --range-file 读取(SSL)的随机文件
- -R/--remote-time 在本地生成文件时,保留远程文件时间
- --retry <num> 传输出现问题时,重试的次数
- --retry-delay <seconds> 传输出现问题时,设置重试间隔时间
- --retry-max-time <seconds> 传输出现问题时,设置最大重试时间
- -s/--silent静音模式。不输出任何东西
- -S/--show-error 显示错误
- --socks4 <host[:port]> 用socks4代理给定主机和端口
- --socks5 <host[:port]> 用socks5代理给定主机和端口
- --stderr <file>
- -t/--telnet-option <OPT=val> Telnet选项设置
- --trace <file> 对指定文件进行debug
- --trace-ascii <file> Like --跟踪但没有hex输出
- --trace-time 跟踪/详细输出时,添加时间戳
- -T/--upload-file <file> 上传文件
- --url <URL> Spet URL to work with
- -u/--user <user[:password]>设置服务器的用户和密码
- -U/--proxy-user <user[:password]>设置代理用户名和密码
- -v/--verbose
- -V/--version 显示版本信息
- -w/--write-out [format]什么输出完成后
- -x/--proxy <host[:port]>在给定的端口上使用HTTP代理
- -X/--request <command>指定什么命令
- -y/--speed-time 放弃限速所要的时间。默认为30
- -Y/--speed-limit 停止传输速度的限制,速度时间'秒
- -z/--time-cond 传送时间设置
- -0/--http1.0 使用HTTP 1.0
- -1/--tlsv1 使用TLSv1(SSL)
- -2/--sslv2 使用SSLv2的(SSL)
- -3/--sslv3 使用的SSLv3(SSL)
- --3p-quote like -Q for the source URL for 3rd party transfer
- --3p-url 使用url,进行第三方传送
- --3p-user 使用用户名和密码,进行第三方传送
- -4/--ipv4 使用IP4
- -6/--ipv6 使用IP6
- -#/--progress-bar 用进度条显示当前的传送状态
二,常用curl实例
1,抓取页面内容到一个文件中
- [root@krlcgcms01 mytest]# curl -o home.html http://blog.51yip.com
2,用-O(大写的),后面的url要具体到某个文件,不然抓不下来。我们还可以用正则来抓取东西
- [root@krlcgcms01 mytest]# curl -O http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
- [root@krlcgcms01 mytest]# curl -O http://blog.51yip.com/wp-content/uploads/2010/[0-9][0-9]/aaaaa.jpg
3,模拟表单信息,模拟登录,保存cookie信息
- [root@krlcgcms01 mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=****** http://blog.51yip.com/wp-login.php
4,模拟表单信息,模拟登录,保存头信息
- [root@krlcgcms01 mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=****** http://blog.51yip.com/wp-login.php
-c(小写)产生的cookie和-D里面的cookie是不一样的。
5,使用cookie文件
- [root@krlcgcms01 mytest]# curl -b ./cookie_c.txt http://blog.51yip.com/wp-admin
6,断点续传,-C(大写的)
- [root@krlcgcms01 mytest]# curl -C -O http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
7,传送数据,最好用登录页面测试,因为你传值过去后,curl回抓数据,你可以看到你传值有没有成功
- [root@krlcgcms01 mytest]# curl -d log=aaaa http://blog.51yip.com/wp-login.php
8,显示抓取错误,下面这个例子,很清楚的表明了。
- [root@krlcgcms01 mytest]# curl -f http://blog.51yip.com/asdf
- curl: (22) The requested URL returned error: 404
- [root@krlcgcms01 mytest]# curl http://blog.51yip.com/asdf
- <HTML><HEAD><TITLE>404,not found</TITLE>
- 。。。。。。。。。。。。
9,伪造来源地址,有的网站会判断,请求来源地址。
- [root@krlcgcms01 mytest]# curl -e http://localhost http://blog.51yip.com/wp-login.php
10,当我们经常用curl去搞人家东西的时候,人家会把你的IP给屏蔽掉的,这个时候,我们可以用代理
- [root@krlcgcms01 mytest]# curl -x 24.10.28.84:32779 -o home.html http://blog.51yip.com
11,比较大的东西,我们可以分段下载
- [root@krlcgcms01 mytest]# curl -r 0-100 -o img.part1 http://blog.51yip.com/wp-
- content/uploads/2010/09/compare_varnish.jpg
- % Total % Received % Xferd Average Speed Time Time Time Current
- Dload Upload Total Spent Left Speed
- 100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
- [root@krlcgcms01 mytest]# curl -r 100-200 -o img.part2 http://blog.51yip.com/wp-
- content/uploads/2010/09/compare_varnish.jpg
- % Total % Received % Xferd Average Speed Time Time Time Current
- Dload Upload Total Spent Left Speed
- 100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
- [root@krlcgcms01 mytest]# curl -r 200- -o img.part3 http://blog.51yip.com/wp-
- content/uploads/2010/09/compare_varnish.jpg
- % Total % Received % Xferd Average Speed Time Time Time Current
- Dload Upload Total Spent Left Speed
- 100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
- [root@krlcgcms01 mytest]# ls |grep part | xargs du -sh
- 4.0K one.part1
- 112K three.part3
- 4.0K two.part2
用的时候,把他们cat一下就OK了,cat img.part* >img.jpg
12,不会显示下载进度信息
- [root@krlcgcms01 mytest]# curl -s -o aaa.jpg http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
13,显示下载进度条
- [root@krlcgcms01 mytest]# curl -# -O http://blog.51yip.com/wp-content/uploads/2010/09/compare_varnish.jpg
- ######################################################################## 100.0%
14,通过ftp下载文件
- [zhangy@BlackGhost ~]$ curl -u 用户名:密码 -O http://blog.51yip.com/demo/curtain/bbstudy_files/style.css
- % Total % Received % Xferd Average Speed Time Time Time Current
- Dload Upload Total Spent Left Speed
- 101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
- [zhangy@BlackGhost ~]$ curl -O ftp://用户名:密码@ip:port/demo/curtain/bbstudy_files/style.css
15,通过ftp上传
- [zhangy@BlackGhost ~]$ curl -T test.sql ftp://用户名:密码@ip:port/demo/curtain/bbstudy_files/
转载请注明
作者:海底苍鹰
地址:http://blog.51yip.com/linux/1049.html