《DensePose: Dense Human Pose Estimation In The Wild》阅读笔记
在这项工作中,我们建立了RGB图像和人体surface-based的表示之间的密集对应关系,我们称之为密集人体姿态估计。我们首先通过引入高效的annotation pipeline来收集出现在COCO数据集中的5万人的密集对应关系。然后,我们使用我们的数据集来训练基于CNN的系统,“in the wild”实现密集的对应关系,也就是背景,遮挡和尺度变化。我们通过训练能够填补缺失的ground truth值的“inpainting”网络来提高我们的训练集的有效性,并报告过去可以实现的最佳结果方面的明显改进。我们试验用全卷积网络和region-based的模型,并观察后者的优越性;我们通过cascading进一步提高准确性,获得实时提供高精度结果的系统。
这项工作旨在通过建立从2D图像到3D人体surface-based的密集对应关系,进一步推动人类对图像理解的包络。我们可以将此任务理解为涉及其他几个问题,例如物体检测,姿态估计,局部和实例分割,作为特殊情况或先决条件。解决这个问题的应用需要超越平面标志性定位(如图形,增强现实或人机交互)的问题,也可能成为实现基于3D物体理解的基石。
将单个RGB图像视为输入,基于此我们建立了surface points和image pixels之间的对应关系。
我们的工作集中在可以说是最重要的视觉类别 - 人类。
https://www.jiqizhixin.com/articles/20180209 机器之心
该论文的方法:采用全面的监督学习方法,ground-truth是correspondences(RGB图像与人体的surface model)翻译成一对联系???我们发明了一种标注流程(annotation pipeline)来收集ground-truth,来源于COCO数据集中的5万个人,标注后的数据集称作DensePose-COCO。
DenseReg针对人脸,DensePose则针对复杂度更高、更灵活的人体姿态。与Mask-RCNN相结合,实时性很高。包含数十个人的复杂场景:在GTX 1080 GPU上,我们的系统运行对于240×320图像为每秒20-26帧或对于800×1100图像为每秒4-5帧。
该工作的贡献点:
- 第二节。DensePose-COCO数据集。发明一种标注流程(annotation pipeline)来手动收集COCO数据集人体与SMPL模型之间的对应关系,即ground-truth。3D信息。
- 第三节。?。我们使用结果数据集来训练基于CNN的系统,通过回归任何image pixels处的身体surface coordinates,在in the wild提供密集的coordinates关系。基于DeepLab(语义分割)与MaskRCNN(目标检测),观察region-based模型在完全卷积网络上的优越性????改进现有模型。
- 第四节。探索建构数据集的不同方式?。监督信号被定义在每个训练样本随机选择的图片像素子集上,使用这些稀疏的对应关系来训练‘teacher’网络,该网络可以在图像域的其余部分“inpaint(恢复、去水印)”监督信号,有效提高了性能。
我们的实验表明,密集的人体姿态估计在很大程度上是可行的,但仍有改进空间。我们用一些定性结果和方向来总结我们的论文,说明该方法的潜力。
二、DensePose-COCO数据集
5万个人,500万个手工标注(对应关系)。
2.1标注系统
目标:建立2D图像到surface-based的对应关系。该论文提出一种标注流程(annotation pipeline)能高效率地收集image-to-surface的对应关系(即标签)。
第一阶段:,如图2所示,标注着描绘身体区域(语义分割,头部、躯干、上/下臂、上/下腿、手、脚),为了简化UV参数化,将各区域设计成与平面同构,将肢体和躯干分成下/上和前/后部分。
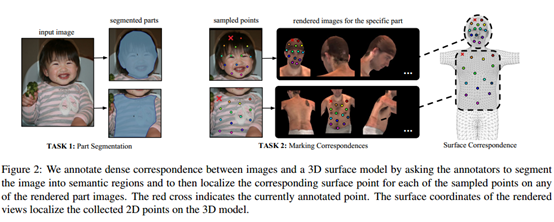
对于头、手、脚,使用SMPL模型提供的UV场。对于其他部分,通过应用于成对测地距离的多维缩放获得展开。得到24区域的UV场,如图1右侧所示。

标注者只需关注服装背后的身体部分,这样标注不会随着服装变化而复杂化。第二阶段:使用Kmeans获得一组大致等距的点对每个区域进行采样,标注者将这些点与surface对应。采样点的数量根据区域大小而变化,最多为14。为了简化任务,通过相同身体部位的6个预渲染视图来展开surface,并允许在任何一个上面放置标志,如图3所示。这样便于标注者选择一个最为方便的视角。

当标注者在任何一个视图上标点时,对应坐标点会同时显示在其他视图上。
通过我们的工作,区域分割与image-to-surface对应,他们的标注工作的耗费差不多,而后者明显有更高的复杂度。效果如图4所示。

2.2标注者的准确性
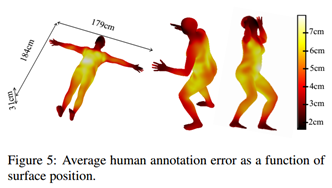
根据黄金标准来评估标注系统的准确性。给标注者提供合成图像,让其标注,测试他们的准确率。图像k的第i个点,真实值与标注值的误差:

g是测地线距离(geodesic distance)。误差情况如图5,可以看出头、手、脚等可以帮助定位的地方误差较小,被衣服覆盖住的地方误差较大。
2.3评估
逐点评估。通过正确点比例(RCP,Ratio of Correct Point)评估整个图像的准确率,如果测地线距离小于某个阈值则定义为正确点。
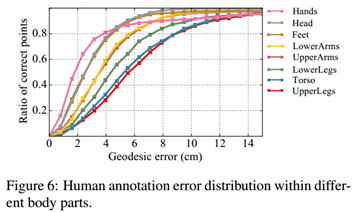
逐实例评估。通过关键点相似度(OSK,object keypoint similarity)评估一个人的姿态。引入测地线点相似度(GPS,geodesic point similarity),作为对应点的匹配分数。
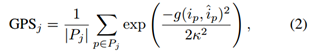
Pj是实体j的点集,k是归一化参数。k=0.255,使得误差大于30cm的时候,单点GPS=0.5。
三、Dense Human Pose Estimation密集人体姿态估计
目标:训练一个能预测image pixels和surface points之间密集对应关系的深层网络。
DenseReg方法 + Mask-RCNN架构 + 改进 = DensePose-RCNN系统
级联拓展,进一步提高准确率。基于interpolation(插补、添加)的方法,允许我们将稀疏监督信号变为更密集更有效的变体。
3.1Fully-convolutional dense pose regression全卷积密集姿态回归
最简单的架构使用完全卷积网络(FCN),该网络结合了分类和回归任务,类似于DenseReg。在第一步中,我们将一个pixel归类为属于背景或者几个区域部分中的一个,它们提供surface coordinates的粗略估计。这相当于使用标准交叉熵损失进行训练的标签任务。第二步,回归系统指出每个区域中的pixel的确切coordinates(坐标)。由于人体结构复杂,因此我们将其分解为多个独立的身体区域,并使用局部二维coordinates系对每个区域进行参数化,以识别该表面部分上任何节点的位置。
首先粗略估计像素所属的位置,然后通过一些小规模校正将其与精确位置对齐。具体地,图像位置i处的坐标回归可以如下公式化
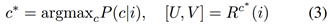
在第一阶段,将位置i分配给身体区域c*(要满足最高后验概率),由分类分支计算得到。在第二阶段,使用回归器Rc* 把点i放置于区域c*的UV坐标参数化中?。在该任务的例子中,c可以取25个值(包括背景),意味着Px是一个25路分类器,之后训练24个回归函数Rc,每个回归函数提供点i在这个身体区域上的2D坐标。在训练时,我们使用交叉熵损失进行区域分类,并使用平滑的L1损失来训练每个回归器。如果像素在特定身体区域内,则仅对该区域考虑回归损失。
3.2Region-based Dense Pose Regression基于区域的密集姿态回归
使用FCN(全卷积网络)使得该系统特别容易训练,但需加载相同的多任务深度网络,包括区域分割和关键点定位,同时需要尺度不变性(这对于COCO图像人体来说变得很有挑战性)。所以该论文采用region-based的方法,其中包括级联的提案区域(ROI,regions-of-interest)[34,15],通过ROI-pooling提取区域自适应特征[16,15],并将结果特征提供给一个区域特定的分支。复杂的体系结构被分解为可控模块,并通过ROI-pooling实现尺度选择机制(scale-selection)。同时,他们也可以以端到端的方式联合训练[34]。
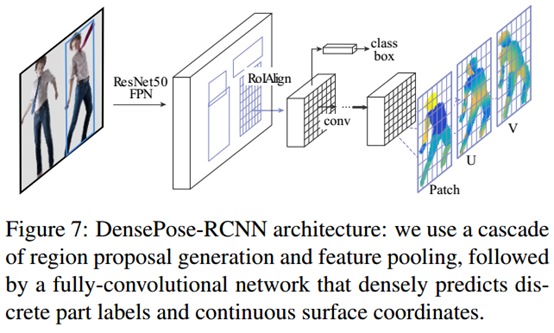
我们采用[15]中介绍的设置,涉及构建特征金字塔网络[25]的特征以及ROI-Align pooling(这些对于需要空间精度的任务来说非常重要)。我们将这种架构适应于我们的任务,以便在每个选定区域内获得密集的区域标签(part labels)和坐标(coordinates)。
如图7所示,在ROI-pooling之上引入一个完全卷积网络FCN,生成一个分类(classification)和一个回归器(regression head),用于提供区域分配(part assignment)和坐标预测(part coordinates predictions),如DenseReg。为简单起见,我们使用与MaskRCNN的关键点分支完全相同的体系结构,由8个交替的3×3完全卷积和512个通道的ReLU层组成。在这个分支的顶部,有与FCN baseline 类似的分类和回归损失,但在此处是proposed region内裁剪的监督信号。
预测时,我们的系统使用GTX1080显卡在320x240图像上以25fps运行,在800x1100图像上以4-5fps运行。
3.3Multi-task cascaded architectures多任务级联架构
迭代细化的思想已广泛应用[ 45,30 ],所以该处也采用级联架构。级联结构为后续阶段提供更好的上下文context,并通过深度监督的好处提升效果[24]。
如图8所示,并不仅仅局限于单个任务中的级联,而是利用来自相关任务的信息,例如关键点估计和实体区域分割(这些信息已经被Mask-RCNN架构成功解决[15])。这使我们能够利用任务协同作用和不同监督来源的互补优点。

3.4Distillation-based ground-truth interpolation
基于升华的ground-truth插值(把ground-truth进行插值,变为密集型,比喻成升华Distillation)
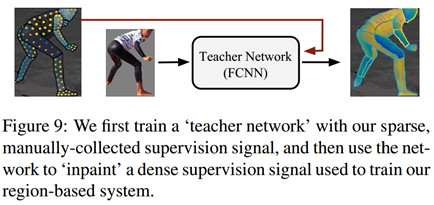
尽管我们的目标是在测试时进行密集的姿态估计,但在每个训练样本中,我们仅注释pixel的稀疏子集,大约每个人100-150个。这在训练过程中并不一定会造成问题,因为我们可以使得我们的分类/回归损失忽略了不收集 ground-truth对应点的点,只需将它们不包含在每pixel点损失的总和中[39]。但是,我们注意到,通过对监督信号的数值“inpainting(恢复)”原本未注释的位置,我们获得了更好的结果。为此,我们采用了一种基于学习的方法,首先训练一个“teacher”网络(如图9所示),在观察到的地方重建ground truth值,然后将其部署在完整图像域上,产生密集的监督信号。特别是,我们只保留网络对标记为前景的区域的预测,如人类收集的部分mask所示,以便忽略背景区域上的网络错误。
四、实验
训练集48K人,测试集2.3k人(1.5k张图像)。
训练集:COCO-train partition,测试集:COCO keypoints-minival partition。。。作者团队目前正在收集COCO数据集的其余部分的注释标签,将允许进行竞争模式评估。
在评估4.3中的“in the wild”密集姿态估计之前。在4.1节使用受限的“单人”设置,使用ground-truth boxes裁剪的输入图像。这会影响检测性能,并为我们提供受控设置,以评估COCO-DensePose数据集的有用性。
4.1 Single-Person Dense Pose Estimation单人密集姿态估计
在4.1.1小节将COCO-DensePose 数据集与其他密集姿态估计监督源进行比较,然后在4.1.2小节比较基于模型的系统[2]与我们经过有区别训练系统的性能。[2]的系统没有使用与我们的模型相同数量的数据进行训练; 因此,这种比较主要是为了显示我们用于判别训练的大规模数据集的优点。
4.1.1 Manual supervision versus surrogates
首先评估COCO-DensePose相对于现有半自动或合成监督信号而言,是否提高了密集姿态估计的准确性。
半自动方法用于[22]的“Unite the People”(UP)数据集,其中人类标注者验证了将SMPL 3D可变形模型[27]拟合到2D图像的结果。然而,模型拟合通常在存在遮挡或极端姿势时失败,并且永远不能保证完全成功-例如,即使在去掉大部分拟合结果之后,脚仍然经常在[22]中未对准。由于ground-truth本身可能存在系统误差,因此这既模糊了训练集,又模糊了评估集。
合成的ground-truth可以通过绘制图像使用基于表面的模型来建立 [ 32,31,35,11,5,29 ]。这最近已应用于[ 43 ]的SURREAL数据集中的人体姿势,其中SMPL模型 [ 27 ]使用CMU Mocap数据集构成 [ 28 ]。然而,由于渲染图像和自然图像的统计数据不同,协变量偏移可能会出现。
由于这两种方法都使用与我们工作中使用的相同的SMPL曲面模型,因此我们可以直接比较结果,也可以组合数据集。我们在SMPL模型上为UP数据集和60k SURREAL模型的所有8514个图像渲染我们的密集坐标和密集部分标签以进行比较。
在图11中,我们使用Deeplab类型的架构,评估了使用不同数据集训练的stride=8的ResNet-101 FCN的测试性能。在训练期间,我们使用缩放,裁剪和旋转来扩充来自所有数据集的样本。我们观察到替代数据集的性能较差,而它们的组合能产生更好的结果。尽管如此,它们的性能远低于通过我们的DensePose数据集训练获得的性能,而将DensePose与SURREAL相结合会导致网络性能的适度下降。基于这些结果,我们完全依靠DensePose数据集进行剩余实验中的训练,即使域适应可能在未来使用[9] 利用合成的监督来源。
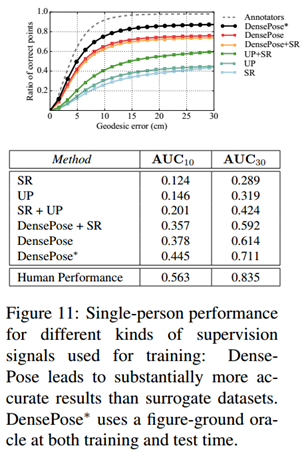
图11表格中的最后一行(DensePose*)表示我们通过使用COCO人工分割掩模获得额外的性能提升,以便在训练和测试期间以平均强度替换背景强度,并且还通过在多个尺度上评估网络并对结果取平均值。显然,使用其他方法的结果不能直接比较,因为我们使用其他信息来删除背景结构。尽管如此,由此产生的预测与人类表现更接近 - 因此我们将其作为“teacher网络”来获得对Sec4.2中实验的密集监督。
4.1.2 FCNN- vs Model-based pose estimation
在图 11中, 我们将我们的方法与[2]的SMPLify流水线进行比较,该流水线将3D SMPL模型拟合到基于预先计算的一组地标点的图像。我们使用[ 22 ]提供的代码,将DeeperCut姿态估计界标检测器[ 17 ]用于14个标志性结果,并使用[ 22 ]中提出的91个标志性替代方案。请注意,这些标志性探测器是在MPII数据集上训练的。由于整个身体在MPII数据集中可见,为了公平比较,我们分别评估可见16/17或17/17地标的图像以及整个测试集。我们观察到,虽然速度快了几个数量级(0.04-0.25“对比60-200”),但自下而上的前馈方法在很大程度上优于迭代的模型拟合结果。如上所述,这种准确性的差异表明我们可以使用DensePose-COCO进行歧视性训练。
4.2. Multi-Person Dense Pose Estimation多人姿态估计
确定了DensePose-COCO数据集的优点后,我们现在转向研究网络架构对in-the-wild密集姿态估计的影响。在图 12是总结结果。

我们首先观察到,基于FCN的in-the-wild表现(曲线'DensePose-FCN')现在显着低于图12中的DensePose曲线。即使我们应用多尺度测试策略,使用不同尺度的输入图像融合多次运行的概率[47],FCN也不足以处理对象尺度的变化。
然后我们通过切换到基于区域的系统,在曲线'DensePose-RCNN'中观察到性能的巨大提升。到目前为止的网络已经使用手动注释的稀疏点集进行了训练。在曲线'DensePose-RCNN-Distillation(升华)'中,我们看到使用由我们的DensePose传递的密集监督信号训练集上的系统产生了实质性的改进(由稀疏信息插值出密集信息)。最后,在'DensePose-RCNN-Cascade'中,我们展示了由于引入级联而实现的性能:Sec3.3几乎匹配'DensePose* '图12的曲线 。
这是一个非常积极的结果:如4.1节所述,'DensePose* '曲线对应于一项非常特殊的评估,包括:(a)在ground-truth盒周围裁剪物体并修复它们的比例(b)通过使用ground-truth物体mask来消除训练和测试中的背景(c)尺度上的集合。因此,它可以理解为我们在in-the-wild操作时可以获得的上限。我们看到我们最好的系统略低于该性能水平,这清楚地揭示了我们引入的三个修改的功效,即基于区域的处理,修复监督信号和级联。
在表1中,我们报告了第2节中描述的AP和AR指标。 因为我们在架构中改变了不同的选择。我们使用ResNet-50和ResNet-101骨架进行了实验,并观察到大型网络(表1中的前两行)的性能仅有微不足道的提升 。因此,我们的其余实验基于Resense-50-FPN版本的DensePose-RCNN。表1中间部分显示的以下两个实验 表明了对多任务学习的影响。
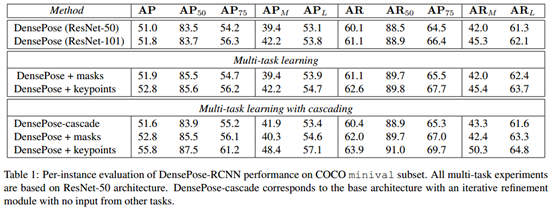
使用掩码或关键点分支扩充网络可以改善这两个辅助任务中的任何一个。表1的最后一部分 报告了通过使用图8的网络设置级联获得的密集姿态估计的改进 。特别是从关键点分支中加入额外的指导可以显着提高性能。
4.3. Qualitative Results定性结果
在本节中,我们提供了额外的定性结果,以进一步证明我们方法的性能。在图 13中,我们显示了由我们的方法产生的定性结果,其中对应性是根据“鱼网”可视化的,即叠加在人体上的估计的UV坐标的等值线。正如这些结果所表明的,我们的方法能够处理大量的咬合,缩放和姿势变化,同时还能成功地将衣服或衣服等衣服背后的人体产生幻觉。
在图14中,我们演示了一个简单的面向图形的应用程序,我们将从[ 43 ]取得的纹理RGB强度映射到估计的UV身体坐标 - 整个视频可以在我们项目的网站http://densepose.org上找到。
5. Conclusion结论
在这项工作中,我们使用有区别的训练模型解决了密集的人体姿势估计的任务。我们引入了COCO-DensePose,这是一个大型的地面实况图像表面对应数据集,并开发了新的架构,使我们能够以每秒多帧的速度恢复图像与体表之间高度精确的密集对应关系。我们预计这将为增强现实或图形中的下游任务铺平道路,同时也帮助我们解决将图像与语义3D对象表示相关联的一般问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号