[日常] MySQL的哈希索引和原理研究测试
1.哈希索引 :(hash index)基于哈希表实现,只有精确匹配到索引列的查询,才会起到效果。
对于每一行数据,存储引擎都会对所有的索引列计算出一个哈希码(hash code),哈希码是一个
较小的整数值,并且不同键值的行计算出来的哈希码也不一样。
2.只有Memory存储引擎显式支持哈希索引,但是原理可以用在伪哈希索引上
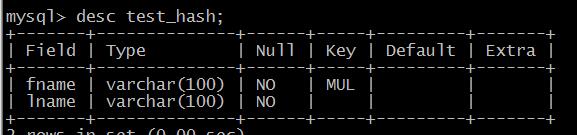
表结构如下:
create table test_hash(
fname varchar(100) not null default '',
lname varchar(100) not null default '',
index using hash(fname)
) engine=memory
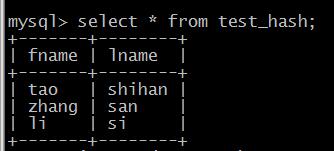
insert into test_hash values ('zhang','san'),('tao','shihan'),('li','si');
3.假设会有这样一个哈希函数f(),该返回下面的哈希码整数值
f('tao')=2323
f('zhang')=7437
f('li')=8784
4.一张哈希表,存储着对应关系,槽编号是循序的,值数据行不是
槽(Slot) 值(Value)
2323 指向第2行数据
7437 指向第1行数据
8784 指向第3行数据
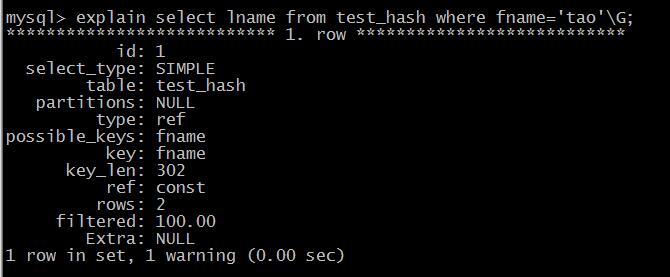
5.select lname from test_hash where fname='tao'\G;
mysql先计算'tao'的哈希值,f('tao')=2323,然后根据该值在哈希索引表中查找对应的行,找到它指向的是
第2行数据,直接查询第2行数据,判断fname是tao,确保正确
6.哈希冲突:不同的值得到了相同的哈希码,例如f('tao')=2323 f('wang')=2323,此时就是出现了哈希冲突
当出现哈希冲突时,相同的数据会存储在链表中,遍历链表找到符合的。
7.特点:
1)哈希索引只包含哈希码和指针,不存储数据字段值
2)哈希索引数据并不是按循序存储的,因此无法用于排序
3)因为要通过查询值计算确定的哈希码,所以哈希索引不支持部分匹配,不支持范围查找,只支持等值比较查询
4)当哈希冲突很多的时候,效率会降低
在InnoDB存储引擎上,可以基于上面的原理,实现伪哈希索引,配合默认的B-Tree索引
十年开发经验程序员,离职全心创业中,历时三年开发出的产品《唯一客服系统》
一款基于Golang+Vue开发的在线客服系统,软件著作权编号:2021SR1462600。一套可私有化部署的网站在线客服系统,编译后的二进制文件可直接使用无需搭开发环境,下载zip解压即可,仅依赖MySQL数据库,是一个开箱即用的全渠道在线客服系统,致力于帮助广大开发者/公司快速部署整合私有化客服功能。
开源地址:唯一客服(开源学习版)
官网地址:唯一客服官网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号