

[操作系统] 字节序中的大端序和小端序的区别
先上结论 , 咱们默认人读字节时 , 从右往左读 , 这就是小端序 , 因为计算机处理的时候会从低位到高位处理 , 和人的习惯正好相反
本文转自公众号:网管daobidao
字节序,又称端序或尾序(英语中用单词:Endianness 表示),在计算机领域中,指电脑内存中或在数字通信链路中,占用多个字节的数据的字节排列顺序。
在几乎所有的平台上,多字节对象都被存储为连续的字节序列。例如在 Go 语言中,一个类型为int的变量x地址为0x100,那么其指针&x的值为0x100。且x的四个字节将被存储在内存的0x100, 0x101, 0x102, 0x103位置。
字节的排列方式有两个通用规则:
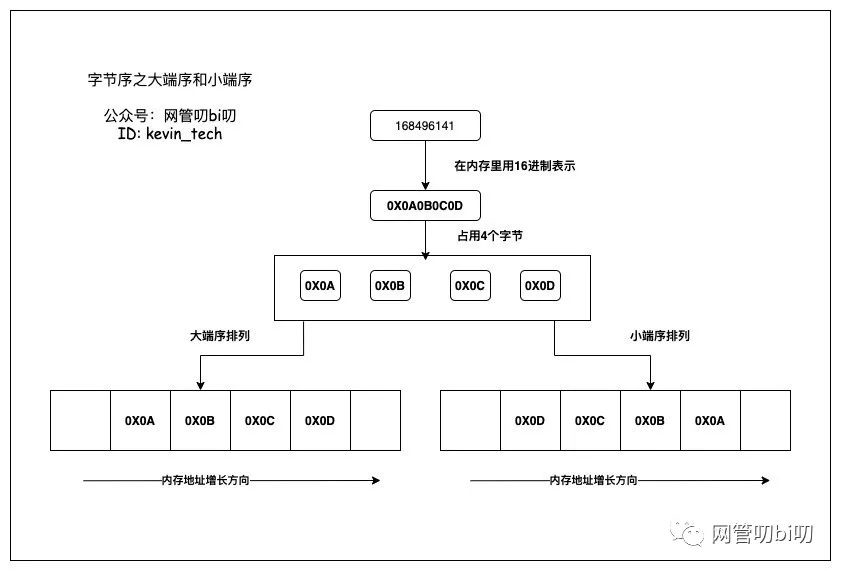
- 大端序(Big-Endian)将数据的低位字节存放在内存的高位地址,高位字节存放在低位地址。这种排列方式与数据用字节表示时的书写顺序一致,符合人类的阅读习惯。
- 小端序(Little-Endian),将一个多位数的低位放在较小的地址处,高位放在较大的地址处,则称小端序。小端序与人类的阅读习惯相反,但更符合计算机读取内存的方式,因为CPU读取内存中的数据时,是从低地址向高地址方向进行读取的。
上面的文字描述有点抽象,我们拿一个例子来解释一下字节排列时的大端序和小端序。
在内存中存放整型数值168496141 需要4个字节,这个数值的对应的16进制表示是0X0A0B0C0D,这个数值在用大端序和小端序排列时的在内存中的示意图如下:
为何要有字节序
很多人会问,为什么会有字节序,统一用大端序不行吗?答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。在计算机内部,小端序被广泛应用于现代 CPU 内部存储数据;而在其他场景,比如网络传输和文件存储则使用大端序。
Go语言对字节序的处理
Go 语言存储数据时的字节序依赖所在平台的 CPU,处理大小端序的代码位于 encoding/binary ,包中的全局变量BigEndian用于操作大端序数据,LittleEndian用于操作小端序数据,这两个变量所对应的数据类型都实现了ByteOrder接口。

package main import ( "encoding/binary" "fmt" "unsafe" ) const INT_SIZE = int(unsafe.Sizeof(0)) //64位操作系统,8 bytes //判断我们系统中的字节序类型 func systemEdian() { var i = 0x01020304 fmt.Println("&i:",&i) bs := (*[INT_SIZE]byte)(unsafe.Pointer(&i)) if bs[0] == 0x04 { fmt.Println("system edian is little endian") } else { fmt.Println("system edian is big endian") } fmt.Printf("temp: 0x%x,%v\n",bs[0],&bs[0]) fmt.Printf("temp: 0x%x,%v\n",bs[1],&bs[1]) fmt.Printf("temp: 0x%x,%v\n",bs[2],&bs[2]) fmt.Printf("temp: 0x%x,%v\n",bs[3],&bs[3]) } //测试大端序 func testBigEndian() { var testInt int32 = 0x01020304 fmt.Printf("%d use big endian: \n", testInt) testBytes := make([]byte, 4) binary.BigEndian.PutUint32(testBytes, uint32(testInt)) fmt.Println("int32 to bytes:", testBytes) fmt.Printf("int32 to bytes: %x \n", testBytes) convInt := binary.BigEndian.Uint32(testBytes) fmt.Printf("bytes to int32: %d\n\n", convInt) } //测试小端序 func testLittleEndian() { var testInt int32 = 0x01020304 fmt.Printf("%x use little endian: \n", testInt) testBytes := make([]byte, 4) binary.LittleEndian.PutUint32(testBytes, uint32(testInt)) fmt.Printf("int32 to bytes: %x \n", testBytes) convInt := binary.LittleEndian.Uint32(testBytes) fmt.Printf("bytes to int32: %d\n\n", convInt) } func main() { systemEdian() fmt.Println("") testBigEndian() testLittleEndian() }
&i: 0xc000084000 system edian is little endian temp: 0x4,0xc000084000 temp: 0x3,0xc000084001 temp: 0x2,0xc000084002 temp: 0x1,0xc000084003 16909060 use big endian: int32 to bytes: [1 2 3 4] int32 to bytes: 01020304 bytes to int32: 16909060 1020304 use little endian: int32 to bytes: 04030201 bytes to int32: 16909060
大端序是从左往右符合人的习惯 , 小端序是从右往左 , 不符合人的习惯 , 上面的代码 , 第一个是显示当前系统是大端序还是小端序
后面两个是存储int32 的两种方式




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2020-02-24 [PHP] 使用PHP在mongodb中进行嵌套查询
2017-02-24 [Linux] PHP程序员玩转Linux系列-备份还原MySQL
2016-02-24 [android] 短信发送器