spark学习笔记
一、Spark官方文档 - 中文翻译
http://www.cnblogs.com/BYRans/p/5292763.html#42
二、Spark入门实战系列
http://www.cnblogs.com/shishanyuan/p/4699644.html
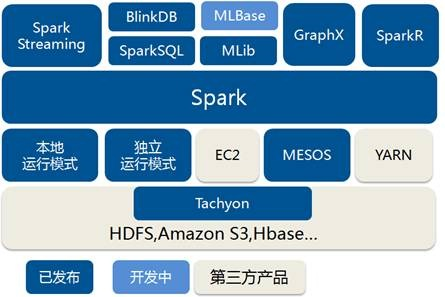
1、Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
l运行速度快
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
l易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
l通用性强
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理,它们都是由AMP实验室提供,能够无缝的集成并提供一站式解决平台。
l随处运行
Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
1.6.2 Spark常用术语
|
术语 |
描述 |
|
Application |
Spark的应用程序,包含一个Driver program和若干Executor |
|
SparkContext |
Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor |
|
Driver Program |
运行Application的main()函数并且创建SparkContext |
|
Executor |
是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。 每个Application都会申请各自的Executor来处理任务 |
|
Cluster Manager |
在集群上获取资源的外部服务 (例如:Standalone、Mesos、Yarn) |
|
Worker Node |
集群中任何可以运行Application代码的节点,运行一个或多个Executor进程 |
|
Task |
运行在Executor上的工作单元 |
|
Job |
SparkContext提交的具体Action操作,常和Action对应 |
|
Stage |
每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet |
|
RDD |
是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类 |
|
DAGScheduler |
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
|
TaskScheduler |
将Taskset提交给Worker node集群运行并返回结果 |
|
Transformations |
是Spark API的一种类型,Transformation返回值还是一个RDD, 所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的 |
|
Action |
是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。 |