

Olap学习笔记
http://student-lp.iteye.com/blog/2263154
OLAP(On-LineAnalysis Processing)在线分析处理是一种共享多维信息的快速分析技术;利用多维数据库技术使用户从不同角度观察数据;用于支持复杂的分析操作,侧重于对管理人员的决策支持,可以满足分析人员快速、灵活地进行大数据复量的复杂查询的要求,并且以一种直观、易懂的形式呈现查询结果,辅助决策。
2.相关概念
(1)维
是人们观察数据的特定角度,是考虑问题时的一类属性集合构成一个维(如时间维、地理维等)。
(2)级别(Level)
人们观察数据的某个特定角度(即某个维)还可以存在细节程度不同的各个描述方面(如时间维:日期、月份、季度、年)。即维的级别。
(3)成员(Member)
维的一个取值,是数据项在某维中位置的描述。(“某年某月某日”是在时间维上位置的描述)。
(4)度量(Measure)
多维数组的取值,如“某年某月某日的工资”。
(5)钻取(Drill-up和Drill-down)
改变维的层次,变化分析的粒度。Drill-up是将低层次的数据概括到高层次的汇总数据或者说是减少维度;drill-up则是相反,是将汇总的数据深入到细节,或说是增加新维。
(6)切片和切面
是在一部分维上选定值后,关心度量数据在剩余维上的分布。如果剩余的维只有两个,则是切片;如果有三个或以上,则是切块。
(7)旋转
是变换维的方向,即在表格中重新安排维的放置(例如行列互换)
根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。
星形模型:当所有维度表连接到事实表上的时候,整个图就像一个星星,故称之为星型模型。星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连,不存在渐变维度,所以数据有一定冗余。因为有冗余,所以很多统计不需要做外部的关联查询,因此一般情况下效率比雪花模型高。维表对应于各个分析的角度,它除了主键以外还包含描述和分类信息。
雪花模型:当有多个维度表没有直接连接到事实表上,而是通过其他维度表连接到事实表上时,其图形就像雪花,故称雪花模型。雪花模型的优点是减少了数据冗余,所以一般情况下查询需要关联其他表。在冗余可接受的前提下使用星型模型。
星型模型和雪花模型的区别在于:维度表是直接连接到事实表还是其他维度表。
比如按省市县的维度分析销量。星形模型的销量事实表中字段有id,省code,市code,县code,销量。事实表直接与省、市、县关联。而雪花模型销量事实表中字段有id,县code,销量。在按省分析销量时,事实表—县维度—市维度—省维度关联起来分析。
3. 星座模式
星座模式(Fact Constellations Schema)也是星型模式的扩展。基于这种思想就有了星座模式:
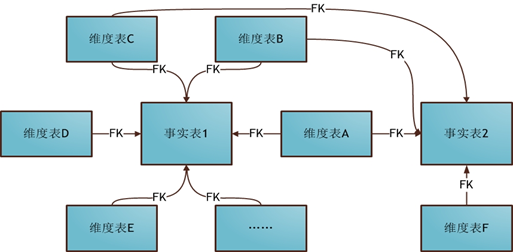
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
从大数据谈起1:OLTP和OLAP的设计区别
https://blog.csdn.net/u010482626/article/details/9213735
在设计大数据处理系统时,首先需要从这两个层面来考虑,需要考虑的因素包括:1、数据大小有多大;2、数据如何使用;3、数据更新频率。
从目前来看需要大数据的主要应用领域,也只有两个:联机事务处理OLTP(On-line Transaction Processing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP
是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。一般就是把大数据用于在线业务,比如淘宝的订单交易、商品展示、历史交易、百度的网页搜索、新浪的微博内容展示等。这种需求要求有实时性,查询以后需要在秒级别返回,且对于服务稳定性和容错性有一定要求的。另外,读操作的数量远远大于写操作,且增量数据的大小要远远小于历史数据。在设计OLTP的数据系统中,主要技术难点有:
分层、分片、分布式事务
OLAP
是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。一般不需要表关联,直接读取单表即可。
OLAP主要是做离线分析,对时效性要求不高,跑几个小时到几天问题都不大,并且机器挂了也没事,大不了restart一下。但是这种系统往往数据量非常大,维数特别多,基本都需要把历史数据全部扫描1-2遍。在设计OLAP系统里主要涉及到技术有:
列存储、降维、切分
|
OLTP |
OLAP |
|
|
用户 |
操作人员,低层管理人员 |
决策人员,高级管理人员 |
|
功能 |
日常操作处理 |
分析决策 |
|
设计 |
面向应用 |
面向主题 |
|
数据 |
当前的, 最新的细节的, 二维的分立的 |
历史的, 聚集的, 多维的,集成的, 统一的 |
|
存取 |
读/写数十条记录 |
读上百万条记录 |
|
工作单位 |
简单的读写 |
复杂查询 |
|
DB大小 |
0-100G |
TB-PB级别 |
OLTP做起来相对容易。小型项目用mysql+redis+memcached足够应付。大型项目在开源社区的支持下,hadoop +hbase+redis也可以从无到有地应对需求。而大型商业产品推出的分布式数据库,和一些开源分布式产品,例如淘宝开源的OceanBase都在保证分布式数据库的ACID的原子性上进行了一定程度的尝试。
OLAP较为复杂,由于数据是多维的, SQL语言Hold不住了。在这方面建模和抽象变得很重要,如何解决数据的语义性和查询的可描述性变得很困难。目前OLAP主要的开源产品包括HDFS、HIVE和Impala等
总体来看,如何根据需求来设计系统才是一个技术人员需要考虑的问题,过分的设计和过分的资源消耗都是不合适。下次我们再介绍下OLTP里的分层思想
BI学习之一创建一个简单的Olap多维数据集的展现
讲解利用vs创建一个商业智能项目->Analysis Services项目。简单讲解如何创建维度表、事实表和分析报表。
第二篇:数据仓库与数据集市建模
写的特别好。重点看下。
缓慢变化维度问题
虽然,维表的数据比事实表更稳定。但不论如何维度在某些时候总会发生一些变化。在之前曾抛出一个问题:为什么维度建模后的关系不是***ID,而是***Key了。这样做的目的其实就是为了解决一种被称为缓慢维度变化(slowly changing dimension)的问题。在维度变化后,一部分历史信息就被丢掉了。比如张三是某公司会员。
但仅仅这么做还是不够的,代理码需要配合时间戳,以及行标识符使用才能解决缓慢维度变化的问题。如下CUSTOMER表使用该方法避免缓慢维度变化:
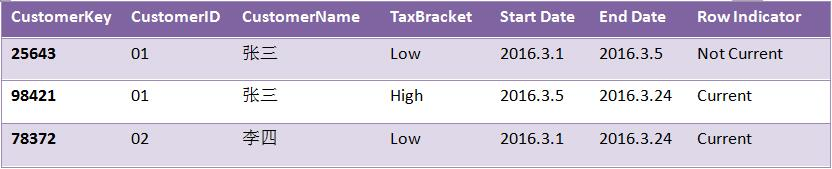
可以看到用户张三对应新维度的TaxBracket状态由Low变成了High。如果需要统计张三的相关行为,那么可以让所有记录用CustomerID字段Join事实表;如果要统计当前TaxBracket为Low的用户状态,则可将Row Indicator字段为Current的记录用CustomerKey字段Join事实表;如果要统计历史TaxBracket状态为Low的用户情况,则只需要将TaxBracket属性为Low的用户记录的CustomerKey属性与事实表关联。
第三篇:数据仓库系统的实现与使用(含OLAP重点讲解)

