从具体实践出发,手把手教你 TDengine 最佳建模方式
作为一款高效便捷的大数据平台,TDengine 的使用体验极为极为流畅,用户可以轻松实现数据的实时采集、存储与分析,快速获取所需的信息和洞察。但在追求最佳实践的过程中,我们仍需关注一些关键问题。例如,多个设备是否应该向同一个子表写入数据?在数据列过滤查询与基于标签的过滤查询之间,效率的差异有多大?此外,如何实现数据的高效压缩也是值得探讨的话题。本篇文章将通过具体的案例分析,详细讲解这些问题,以期帮助大家更深入地理解并高效使用 TDengine。
场景描述
以某智能电表为例,可采集电压、电流、漏电流、线路端子温度、有功功率、功率因数、电量等参数,数据每 2 分钟通过 mqtt 上报一次,通过 TDengine mqtt 可视化连接器进行采集,需要对各个累计电量和平均功率进行统计。
需求描述
聚焦用电量和平均功率统计分析:
- 查询用电量
- 年度总耗电量
- 昨日用电量
- 用电趋势,最近 30 天,每天的用电量
- 查询近 24 小时的设备功率趋势,按小时展示,每个小时的数据为:该小时单位内,每个设备平均功率的总和
建模和存在问题
1.建模内容
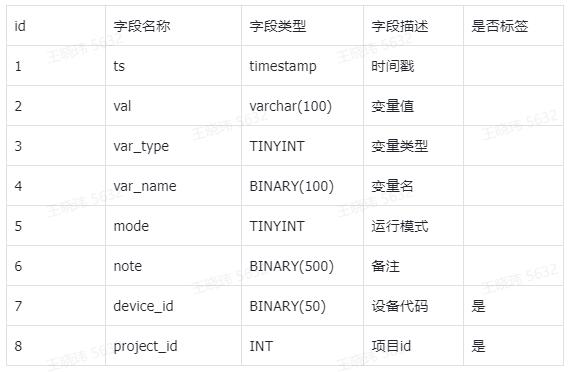
2.建模说明
- 客户为了将超级表通用化,避免不同表具字段数目不统一情况,所以用了变量类型、 变量值和变量名称 3 个字段,将宽表模型变成了单列模型
- 由于变量值包括整型、 浮点型 、离散型等,便将其设置为字符串类型 ,便于不同类型数据都能写入
-
目前 var_name 列基数为 {current,power}
- cum_power:当前用电量
- power :功率
3.查询效果
- 目前查询近半年的数据每个月的累计值需要近 20 秒
4.建模问题点评
客户的建模方式虽然可以对各种场景适配,但不是最优建模,存在以下问题:
- 对于来自同一电表的多个数据字段,将其分别处理成多个独立的插入(insert)操作。在每次插入操作时,系统会利用本地时间生成精确到毫秒的时间戳,确保每个记录都具有独特的时间标记。然而,在处理大量电表数据的情况下,由于缺乏批量插入的策略,这种逐条记录的插入方法可能会导致性能上的不足。
- 由于将不同采集量的数值汇总至同一字段,导致数值之间的差异极大,这不仅影响了一级增量(delta)压缩的效率,还增加了存储空间的占用。
- 当来自同一电表的不同采集量数据被存储在同一字段中时,由于数据量的差异,无法实现在磁盘上的连续存储。这种情况在查询过程中会导致与磁盘的交互次数显著增加,从而严重影响查询效率。
- 由于所有采集值都被存储在同一个字段中,每次查询特定采集量时,都需要进行数据过滤。此外,相对于标签字段,动态字段通常不支持索引,即使该字段理论上可以索引,但由于列的基数较低,建立的索引也无法提供有效的性能提升。在数据量较大的情况下,这将不可避免地导致查询速度变慢。
建议建模内容
按照宽表形式展示,对于不同类型的设备,建立不同的超级表。
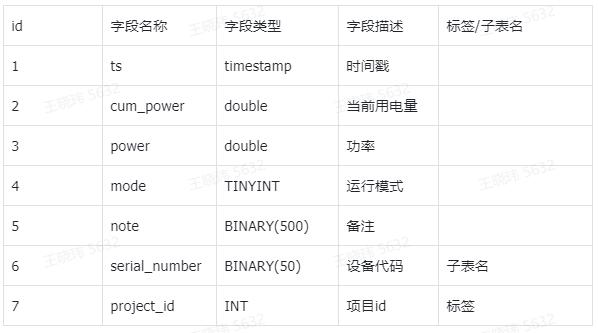
相关语句
-
建表语句
- 创建超级表
create STABLE if not exists iot.device (ts timestamp, cum_power double, power double,mode TINYINT, note BINARY(500))TAGS ( project_id INT);
- 创建超子表
create table serial_number using device tags(1)
-
查询用电量
- 当月总耗电量
select sum(a) from (select spread(cum_power)as a from iot.device where project_id=1 and ts>to_char(now,"yyyy-mm-01") partition by tbname)
- 当年总耗电量
select sum(a) from (select spread(cum_power)as a from iot.device where project_id=1 and ts>to_char(now,"yyyy-01-01") partition by tbname)
- 昨日用电量
select sum(a) from (select spread(cum_power)as a from iot.device where project_id=1 and ts<timetruncate(now,1d) and ts>=(timetruncate(now,1d)-1d) partition by tbname)
- 用电趋势,最近 30 天、每天的用电量
select last(t),sum(a) from (select _wstart as t,spread(cum_power)as a from iot.device where project_id=1 and ts<now and ts>=(timetruncate(now,1d)-30d) partition by tbname interval(1d) order by t) interval(1d)
-
查询功率相关
- 查询近 24 小时的设备功率趋势——按小时展示每个设备平均功率的总和
select last(t),sum(a) from(select _wstart as t,avg(power)as a from iot.device where project_id=1 and ts<now and ts>=(timetruncate(now,1h)-24h) partition by tbname interval(1h) order by t)interval(1h)
总结
TDengine 的高效写入、查询性能和数据压缩能力,得益于其创新的“一个设备一张表”的设计理念。因此,在进行数据建模时,我们应以这一理念为指导,确保系统的长期稳定性和性能最优化,有效预防未来数据量剧增时可能出现的结构性调整需求,从而减少潜在的复杂性和成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号