许多用户会有一个疑问,“落盘”俩字听起来就很底层,似乎无法和手头的性能问题联系到一起,本篇文章的目的就是让大家对它们俩建立起直观的认识。
许多用户会有一个疑问,“落盘”俩字听起来就很底层,似乎无法和手头的性能问题联系到一起,本篇文章的目的就是让大家对它们俩建立起直观的认识。
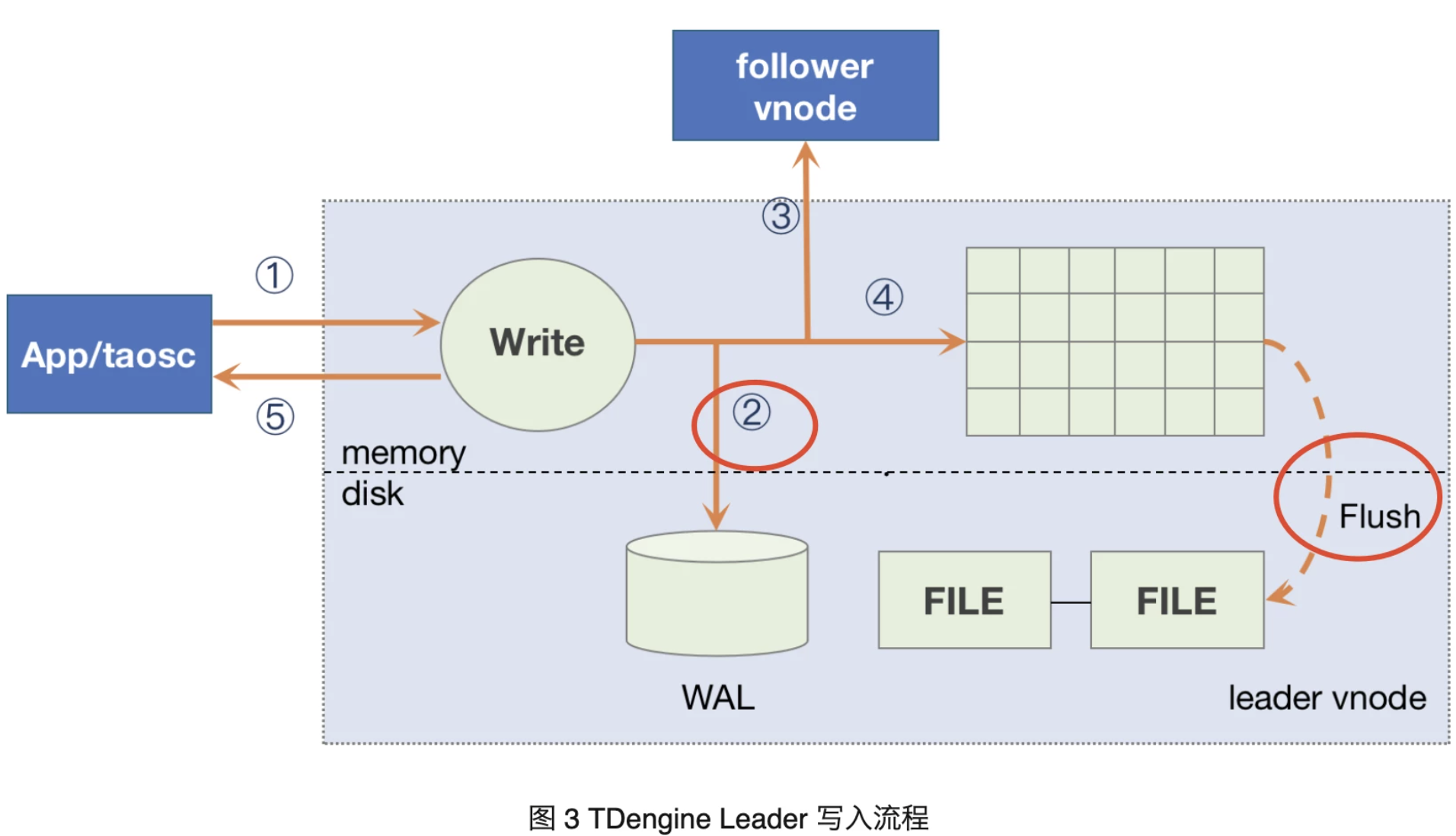
写到数据库的数据总要保存起来——所以时序数据库(Time Series Database) TDengine 中经常提到的“落盘”,其实指的是内存中的数据持久化到存储的过程。在 TDengine 中,对 vnode 的写入流程如下。(不了解vnode的用户,建议先移步 https://docs.taosdata.com/tdinternal/arch/)
根据图中所示:内存和硬盘发生持久化的操作有两部分,本文的“落盘”指的是右侧标红部分,即是时序数据持久化到 $DataDir/vnode/vnodeX/tsdb/ 下数据文件的过程。
![]()
一 . 触发逻辑变化:
熟悉 2.0 版本的朋友们都知道,触发落盘的机制有二:
- 写满该 vnode 三分之一的缓冲池(建库时指定,2.0 为建库参数 cache * blocks 的值, 3.0 替换为建库参数 buffer);
- 数据库服务进程停止的时候;
在 3.0 版本,触发落盘的机制变为:
- 写满该 vnode 三分之一的缓冲池之后,超过“落盘最小间隔”即可自动落盘。出于安全考虑,该参数没有提供可配置选项;
- 数据库服务进程停止的时候;(3.0.4.0 版本数据库单副本情况下提供)
- 提供手动落盘的命令,flush database dbname。
二.架构优化:
那么它具体都达成了哪些优化呢?
首先,在设计上 3.0 对落盘功能和过期数据检测做了解耦。
在 2.0 的时候,只有数据库在落盘之后,才会触发比对数据文件的时间范围清理过期的文件数据的机制,从而释放硬盘空间,详情可参考:https://mp.weixin.qq.com/s/uJEQwN0NnmSTBAMOecAtoA。
自 3.0 版本开始,数据库的过期文件清理依靠 trim database dbname 的命令来完成。到 3.0.3.0 版本,又增加了定时检测来自动执行 trim database。这让 3.0 的磁盘空间回收变得更加高效及时。
其次,提供手动落盘的命令。令落盘控制更加灵活。此外,由于时序数据的压缩是发生在落盘阶段的,因此对于我们统计数据的磁盘实际占用,计算压缩率都有很大的帮助。
三.配置优化:
1.落盘时,内存中的行式存储的时序数据会被转为列式存储的数据块,然后执行压缩。因此,形成数据块的过程直接影响着后续的磁盘占用和查询效率,这也是 TDengine 性能优化最核心的部分之一,它是由数据库的一系列参数决定的,具体可参考文章(文章:关于 3.0 和 2.0 的数据文件差异以及性能优化思路)。
2.TDengine 执行落盘的任务是异步的,这样当写满 1 块缓冲池后,就可以无延迟地利用起来剩余的 2 块缓冲池。但是如果 buffer 设置太小,就会导致落盘仍未结束时,但是已经用光了所有三块缓冲池。这个时候数据库就只能进入等待阶段,写入查询都会受到影响,直到可用的缓冲池返回。
可以看出,在这个环节中,缓冲池的大小是十分重要的,这个值由建库时的 buffer 参数指定,建库后可修改(具体可参考:https://docs.taosdata.com/taos-sql/database/)。
3.另外,如果是落盘线程这一侧到达瓶颈导致没有可用的缓冲池返回,则可以选择增加 numOfCommitThreads 参数值,这个参数代表每个节点上的落盘线程数量,默认等于二分之一的cpu核数。
具体优化方式需要结合自己的实际情况决定,如写入频率、表宽、性能需求等等。并没有一项固定参数的单独调试就可以调试到最优状态,大家可以结合历史多期文章自行调试,也可以直接联系企业版团队做定制化的优化方案。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号