如何使用 TDengine Sink Connector?
小 T 导读:TDengine Kafka Connector 在 TDengine 的官方文档上放出来已经有一段时间了,我们也收到了一些开发者的反馈。文档中的教程使用 Confluent 平台(集成了 Kafka)演示了如何使用 Source Connector 和 Sink Connector,但是很多开发者在生产环境中并没有使用 Confluent,所以为方便大家,本文将使用独立部署的 Kafka 来演示。
本文包含以下内容:
- 如何使用 TDengine Sink Connector, 把数据从 Kafka 同步到 TDengine。
- TDengine Sink Connector 的实现原理。
- 一个简单的测试脚本,帮助你在自己的环境中快速测试。通过更改生成测试数据的程序和配置参数,你可以模拟自己的使用场景。
- 测试同步同一个 topic,使用不同分区数和不同 Sink 任务数对性能的影响。
背景知识
如果你对文章开头出现的术语并不陌生,那么可以跳过这一部分。
· 什么是 Kafka?
Kafka 的核心是一个通用的、分布式的、可重复消费的消息队列。
与之相比,作为一款时序数据库(Time-Series Database),TDengine 也可看作针对结构化的时序数据的消息队列。
· 什么是 Kafka Connect? 为什么使用 Kafka Connect?
Kafka Connect 是 Kafka 的一个组件,简化了 Kafka 与其它数据源的集成。用户通过 Kafka Connect 读写 Kafka;通过 Kafka Connect 插件(也称 Kafka Connector)来读写各种数据源。
为方便集成,Kafka 已经提供了生产者和消费者 API 以及客户端库,那为什么还需要 Kafka Connect 呢?因为一个好的 Kafka 客户端程序,不是单单生产或消费数据,还需要考虑容错、重启、日志、弹性伸缩、序列化以及反序列化等。当开发者自己完成了这一切,就相当于开发了一个和 Kafka Connect 类似的东西。
与 Kafka 集成是 Kafka Connect 已经解决的问题,用户不需要重复造轮子,只有少数边缘场景才需要定制化的集成方案。
TDengine Sink Connector 的实现原理
TDengine Sink Connector 用于将 Kafka 中指定 topic 的数据(批量或实时)同步到 TDengine 的 database 中。
启动 Sink Connector 需要一个 properties 配置文件。详细配置见官方文档的配置参考。
Sink Connector 内部的实现非常简单,整体工作流程分为以下几个步骤:
- Connect 框架根据配置启动 N 个消费者线程。
- N 个消费者同时订阅数据,并用配置文件中指定的 key.converter 和 value.converter 做反序列化。
- Connect 框架把反序列化后的数据传递给 N 个 SinkTask 的实例。
- SinkTask 使用 TDengine 提供的 schemaless 写入接口来写入数据。
上述 4 个步骤,只有最后一步写数据是 Sink Connector 需要关心的,其它都是 Connect 框架自动实现的。
下面重点讨论几个问题。
· 支持的数据格式
因为使用了 schemaless 写入接口,因此 TDengine Sink Connector 只支持三种格式的数据:InfluxDB 行协议格式、 OpenTSDB Telnet 协议格式 和 OpenTSDB JSON 协议格式。使用配置项 db.schemaless 来指定写入时使用的数据格式。例如:
db.schemaless=line
如果 Kafka 中的数据已经是这三种格式之一,那么配置文件中的 value.converer,只需指定为 Connnect 内置的 org.apache.kafka.connect.storage.StringConverter。
value.converter=org.apache.kafka.connect.storage.StringConverter
如果 Kafka 中已有的数据不是上述三种之一,则需要实现自己的 Converter 类, 将其转换为三种格式之一,这个链接也许能帮到你。
· 如何指定 Consumer 的参数?
既然 Connect 框架已经帮我们做了 Consumer 要做的事,那么我们怎么来控制 Consumer 的行为呢?比如如何控制 Consumer 订阅的主题?如何控制 Consumer 每次 poll 的消息数和时间间隔?
对于订阅哪些主题,可以用配置项 topics 来指定。
如果想覆盖 Consumer 的其它默认配置,可以直接在 Sink Connector 的配置文件中编写,但是要加前缀 “consumer.override.”,比如想把每次 poll 的最大消息数改为 3000, 可以这样配置:
consumer.override.max.poll.records=3000
· 如何控制写入线程数?
对于 Kafka Connect Sink,task 本质上就是消费者线程,接收从 topic 的分区读出来的数据。用配置参数 tasks.max 来控制最大任务数,一个任务一个线程。实际启动的任务数还与 topic 的分区数有关。如果你有 10 个分区,并且 tasks.max 设置为 5, 那么每个 task 会收到 2 个分区的数据,并跟踪 2 个分区的 offsets。如果你配置的 tasks.max 比 partition 数大, Connect 会启动的 task 数与 topic 的 partition 数相同。如果你订阅了 5 个 topic,每个 topic 都是 1 个分区, 并且设置 tasks.max = 5, 那么实际会启动多少个任务呢?答案是 1 个, 任务数与 topic 数量没有关系。
TDengine Sink Connector 使用示例
这一部分我们在一台 Linux 服务器上搭建测试环境,并运行简单的示例程序。示例中将 Kafka 部署到了个人的 home 目录。操作时请注意把路径中的用户名(bding)替换为自己的用户名。
· 环境准备
- Java 1.8
- Maven
- 安装并启动了 TDengine 相关服务进程:taosd 和 taosAdapter。
第一步:安装 Kafka
wget https://dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.tgz tar -xzf kafka_2.13-3.2.0.tgz
编辑 .bash_profile, 加入:
export KAFKA_HOME=/home/bding/kafka_2.13-3.2.0 export PATH=$PATH:$KAFKA_HOME/bin
source .bash_profile
第二步:配置 Kafka
配置 Kafka Connect 加载插件的路径。
cd kafka_2.13-3.2.0/config/ vi connect-standalone.properties
追加
plugin.path=/home/bding/connectors
修改 Connector 插件的日志级别。这一步非常重要,我们将通过插件的日志统计同步数据花费的时间。
vi connect-log4j.properties
追加
log4j.logger.com.taosdata.kafka.connect.sink=DEBUG
第三步:编译并安装插件
git clone git@github.com:taosdata/kafka-connect-tdengine.git cd kafka-connect-tdengine mvn clean package unzip -d ~/connectors target/components/packages/taosdata-kafka-connect-tdengine-*.zip
第四步:启动 ZooKeeper Server 和 Kafka Server
zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
第五步:创建 topic
kafka-topics.sh --create --topic meters --partitions 1 --bootstrap-server localhost:9092
第六步:生成测试数据
将下列脚本保存为 gen-data.py:
#!/usr/bin/python3
import random
import sys
topic = sys.argv[1]
count = int(sys.argv[2])
start_ts = 1648432611249000000
location = ["SanFrancisco", "LosAngeles", "SanDiego"]
for i in range(count):
ts = start_ts + i
row = f"{topic},location={location[i % 3]},groupid=2 current={random.random() * 10},voltage={random.randint(100, 300)},phase={random.random()} {ts}"
print(row)
然后执行:
python3 gen-data.py meters 10000 | kafka-console-producer.sh --broker-list localhost:9092 --topic meters
生成 10000 条 InfluxDB 行协议格式的数据到 topic meters。每条数据又包含 2 个标签字段和 3 个数据字段。
第七步:启动 Kafka Connect
将下列配置保存为 sink-test.properties。
name=TDengineSinkConnector connector.class=com.taosdata.kafka.connect.sink.TDengineSinkConnector tasks.max=1 topics=meters connection.url=jdbc:TAOS://127.0.0.1:6030 connection.user=root connection.password=taosdata connection.database=power db.schemaless=line key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter
然后执行:
connect-standalone.sh -daemon $KAFKA_HOME/config/connect-standalone.properties sink-test.properties
第八步:检查 TDengine 中的数据
使用 TDengine CLI 查询 power 数据库 meters 表,检查是否正好包含 10000 条数据。
[bding@vm95 test]$ taos
Welcome to the TDengine shell from Linux, Client Version:2.6.0.4
Copyright (c) 2022 by TAOS Data, Inc. All rights reserved.
taos> select count(*) from power.meters;
count(*) |
========================
10000 |
TDengine Sink Connector 性能测试
· 测试流程
这一部分,我们将上面示例步骤中的第四步到第七步封装成可重复运行的 shell 脚本,并做以下修改:
- 将 topic 的分区数作为脚本的第 1 个参数, 同时配置 tasks.max,使其等于分区数。这样我们可以控制每次测试使用的写入线程数。
- 将生成测试数据的条数作为脚本的第 2 个参数,用来控制每次测试同步的数据量。
- 启动测试前清空所有数据,测试结束后停止 Connect、Kafka 和 ZooKeeper。
每次测试都先写数据到 Kafka,然后再启动 Connect 同步数据到 TDengine,这样做可以把同步数据的压力全部集中到 Sink 插件这边。我们统计 Sink Connector 从接收到第一批数据到接收到最后一批数据之间的时间,作为同步数据的总耗时。
完整脚本如下:
#!/bin/bash
if [ $# -lt 2 ];then
echo "Usage: ./run-test.sh <num_of_partitions> <total_records>"
exit 0
fi
echo "---------------------------TEST STARTED---------------------------------------"
echo clean data and logs
taos -s "DROP DATABASE IF EXISTS power"
rm -rf /tmp/kafka-logs /tmp/zookeeper
rm -f $KAFKA_HOME/logs/connect.log
np=$1 # number of partitions
total=$2 # number of records
echo number of partitions is $np, number of recordes is $total.
echo start zookeeper
zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties
echo start kafka
sleep 3
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
sleep 5
echo create topic
kafka-topics.sh --create --topic meters --partitions $np --bootstrap-server localhost:9092
kafka-topics.sh --describe --topic meters --bootstrap-server localhost:9092
echo generate test data
python3 gen-data.py meters $total | kafka-console-producer.sh --broker-list localhost:9092 --topic meters
echo alter connector configuration setting tasks.max=$np
sed -i "s/tasks.max=.*/tasks.max=${np}/" sink-test.properties
echo start kafka connect
connect-standalone.sh -daemon $KAFKA_HOME/config/connect-standalone.properties sink-test.properties
echo -e "\e[1;31m open another console to monitor connect.log. press enter when no more data received.\e[0m"
read
echo stop connect
jps | grep ConnectStandalone | awk '{print $1}' | xargs kill
echo stop kafka server
kafka-server-stop.sh
echo stop zookeeper
zookeeper-server-stop.sh
# extract timestamps of receiving the first batch of data and the last batch of data
grep "records" $KAFKA_HOME/logs/connect.log | grep meters- > tmp.log
start_time=`cat tmp.log | grep -Eo "[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2},[0-9]{3}" | head -1`
stop_time=`cat tmp.log | grep -Eo "[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2},[0-9]{3}" | tail -1`
echo "--------------------------TEST FINISHED------------------------------------"
echo "| records | partitions | start time | stop time |"
echo "|---------|------------|------------|-----------|"
echo "| $total | $np | $start_time | $stop_time |"
如果要测试使用 1 个分区,共 100 万条数据的性能,可以这样执行:
./run-test.sh 1 1000000
执行过程的截图如下:
注意中间有一个交互过程。因为脚本无法确定数据是否同步完,需要用户监控 connect.log 来确定是否已经消费完了所有数据,例如:
[bding@vm95 ~]$ cd kafka_2.13-3.2.0/logs/ [bding@vm95 logs]$ tail -f connect.log [2022-06-21 17:39:00,176] DEBUG [TDengineSinkConnector|task-0] Received 500 records. First record kafka coordinates:(meters-0-314496). Writing them to the database... (com.taosdata.kafka.connect.sink.TDengineSinkTask:101) [2022-06-21 17:39:00,180] DEBUG [TDengineSinkConnector|task-0] Received 500 records. First record kafka coordinates:(meters-0-314996). Writing them to the database... (com.taosdata.kafka.connect.sink.TDengineSinkTask:101)
当日志不再滚动,就说明已经消费完了
· 测试结果
写入速度与数据量和线程数的关系表
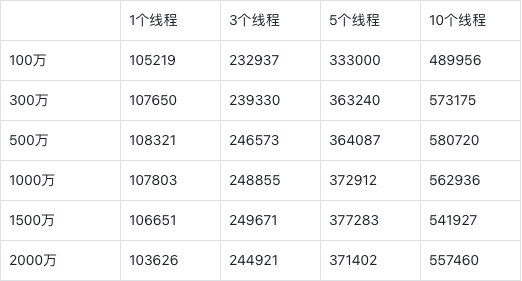
上表第 1 列为总数据量,第 1 行为消费者线程数,也是写入线程数。中间为平均每秒写入记录数。
写入速度与数据量和线程数的关系图
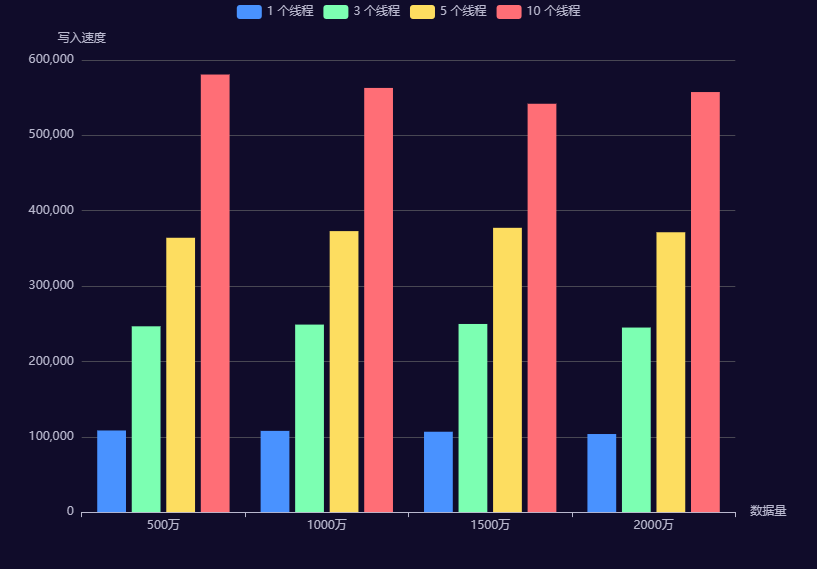
结果分析
从上图可以看出,相同数据量,线程越多写入速度越快。当使用单线程写入时,每秒能写入大概 10 万以上。当使用 5 个线程写入时,每秒写入大概 35 万左右。当使用10 个线程时,每秒能写入55 万左右。
写入速度比较平稳,与总数据量关系不大。
同时也发现线程增加越多,线程增加带来的速度提升越少。线程数从 1 变到 10,速度只从 10 万变到 50 万。可能的原因是数据在各个分区分布不均匀。有的 task 执行时间长,有的 task 执行时间短,数据量越大,数据倾斜越大。比如 1000 万数据,10个分区的时候,各分区的数据量:
[bding@vm95 kafka-logs]$ du -h ./ -d 1 125M ./meters-8 149M ./meters-7 119M ./meters-9 138M ./meters-4 110M ./meters-3 158M ./meters-6 131M ./meters-5 105M ./meters-0 113M ./meters-2 99M ./meters-1
另一个影响多线程写入速度的是数据的乱序程度。本测试场景中,多条时间线的数据随机分配到了不同分区,当单线程写入时(即 1 个分区时),数据是严格有序的,写入速度最快。线程越多乱序程度越大。
所以在实际应用场景中,建议将同一个子表的数据,放在 Kafka 同一个分区中。
附录
· 测试程序
本文中用到的所有代码和原始测试结果数据都已上传到 GitHub 仓库。
· 测试环境

想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号