一文读懂TDengine的窗口查询功能
作为一款时序数据库(Time-Series Database),TDengine 提供了按时间自动划分窗口并执行查询的能力。这个功能的用途和使用场景你是不是清楚呢?本文将为你介绍这一功能及其典型使用场景。
什么是窗口查询?
时序数据常常需要根据采集时间对数据进行查询,本质上是在时间轴上划分出时间窗口,并对窗口内的数据进行聚合和查询计算。比如一个最简单的场景:查询”2018-01-01 00:00:00.000″到”2018-01-31 00:00:00.000″原始数据的最大值、最小值、平均值,则”2018-01-01 00:00:00.000″到”2018-01-31 00:00:00.000″就形成了一个查询的时间窗口。
在实际生产应用中,业务场景要求的查询条件往往比这个更复杂,需要时序数据库能够按照不同规则、沿时间轴进行窗口划分,并对各个窗口内的时序数据分别进行聚合、选择计算等操作。
TDengine 提供的三种窗口查询能力详解
TDengine 从 2.2.x.x 版本起,支持了三类时序窗口查询,分别是等间隔窗口(interval)、状态窗口(state_window)和会话窗口(session),大大简化了应用开发时对时间序列逻辑的处理。
窗口查询,从子表的查询语法为:
SELECT function_list FROM tb_name [WHERE where_condition] [SESSION(ts_col, tol_val)][STATE_WINDOW(col)] [INTERVAL(interval [, offset]) [SLIDING sliding]] [FILL({NONE | VALUE | PREV | NULL | LINEAR | NEXT})]
窗口查询,从超级表的查询语法为:
SELECT function_list FROM stb_name [WHERE where_condition] [INTERVAL(interval [, offset]) [SLIDING sliding]] [FILL({NONE | VALUE | PREV | NULL | LINEAR | NEXT})] [GROUP BY tags]
下面分别看一下这三类时序窗口查询功能。
1. 等间隔窗口(interval)
按照固定的时间窗口长度,周期性地对时间轴进行窗口划分,并允许对每个窗口内的数据进行聚合查询。
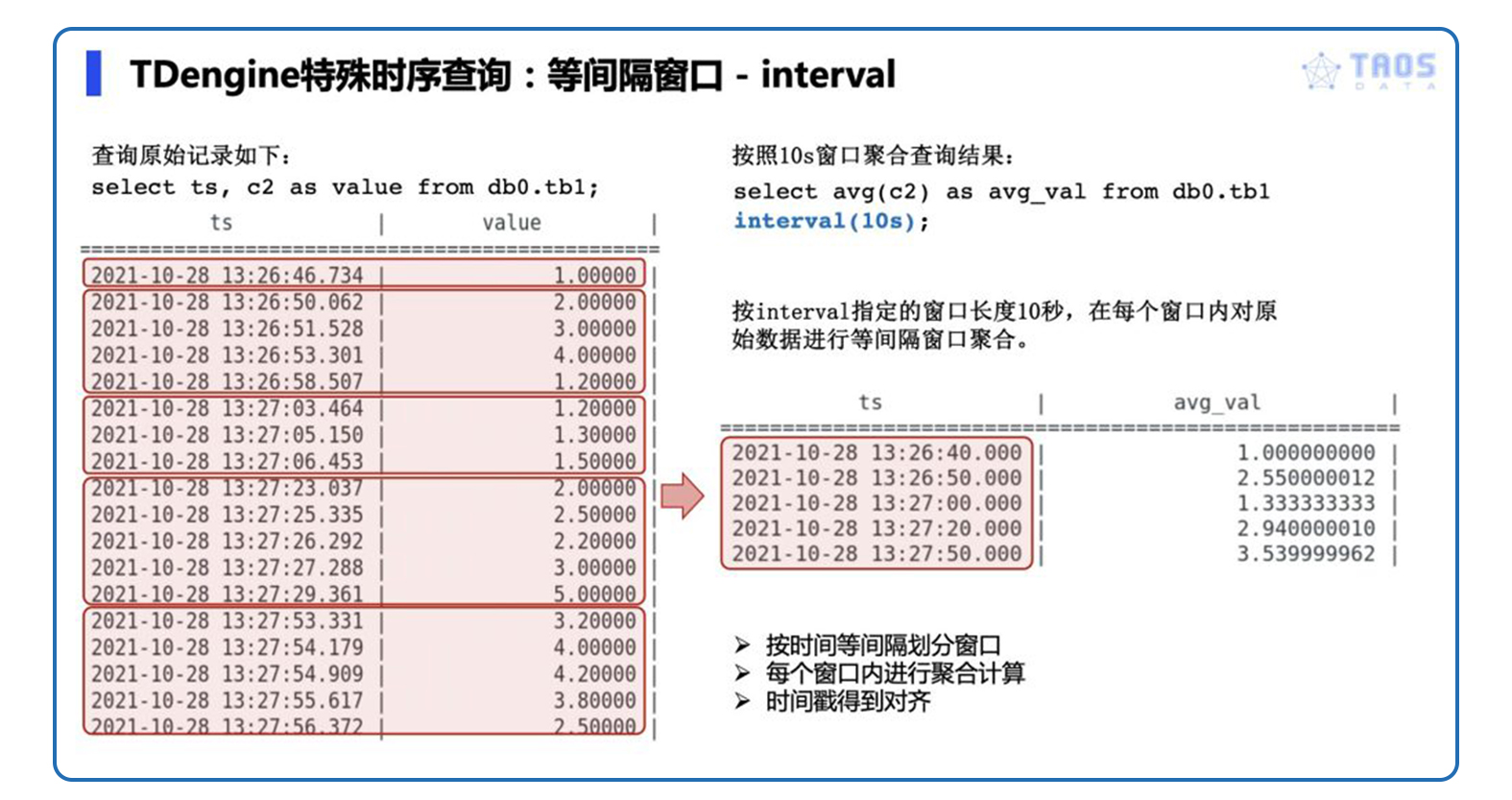
我们再通过几个例子看看等间隔窗口的具体应用场景。
在工业生产中,有很多监控指标需要实时展示趋势线。但有些指标如振动等,实际采集的频率非常高,如果展示原始数据会难以看清趋势,同时由于数据量过于密集,会给前端页面的展示造成巨大压力。
但通过 interval 等间隔窗口,可以按照指定窗口长度对原始数据做聚合(相当于对原始数据进行了降采样),之后再展示趋势线时,前端展示需要从数据库拉取的数据量会大大减少,从而显著提高效率。
下图中,绿色曲线为基于每 60 秒采集一次的原始数据直接展示绘制的曲线,橙色曲线为对原始数据按照 5 分钟长度进行窗口划分后求取平均值的曲线,可以看到橙色曲线这种情况下,很好地反映了整体的数据变化趋势,而前端绘图所需的数据量却减少了 80%。
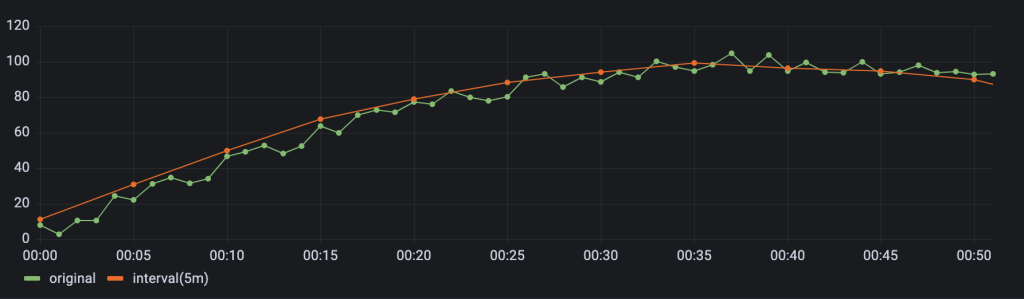
在实际生产中高频采集数据的趋势线,均可以考虑通过 TDengine 的 interval 语法提供的降采样能力,在不丢失整体趋势信息的情况下,快速展示数据。
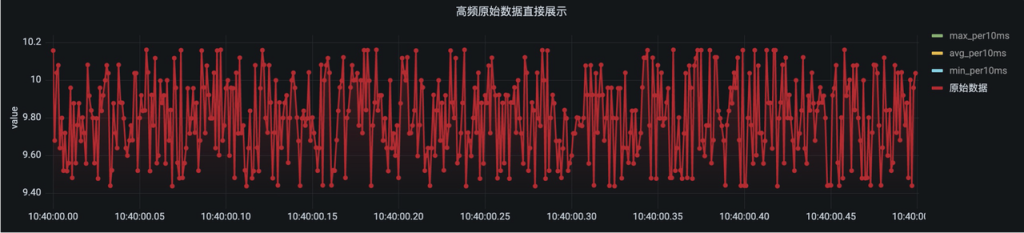
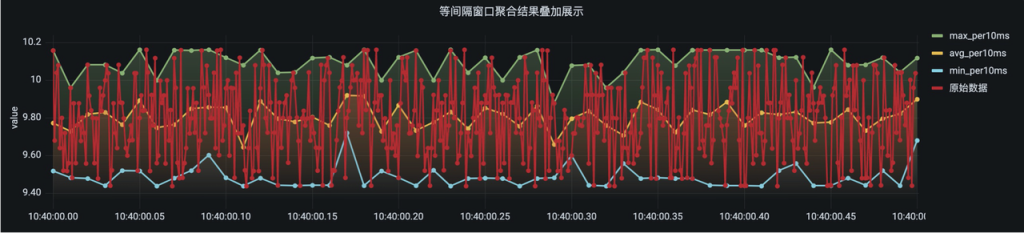
2. 状态窗口(state_window)
状态窗口让用户可以按照某个整型/字符串型的采集量(一般是表征状态的值,如设备工作模式等)的值来划分窗口,将该状态值连续不变的记录划入同一个窗口。然后对每个窗口内的采集值进行avg/max/min等统计聚合、或计算状态持续时间等。
比如加工厂的机床运维人员,需要统计每个机床的工作和待机的时间,这本质上是以工作状态 “status” 这个状态量的值来划分窗口,并统计窗口时长。
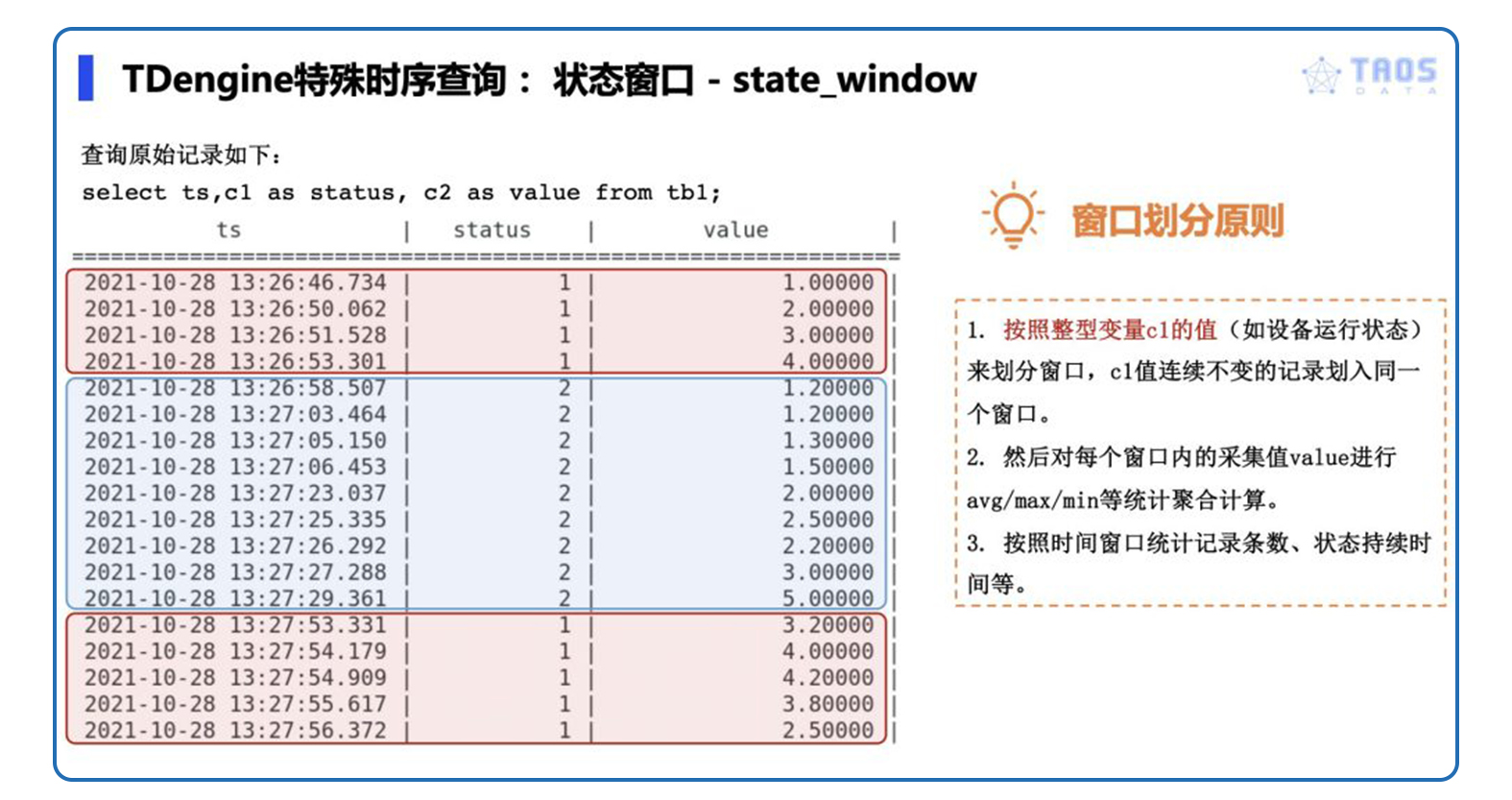
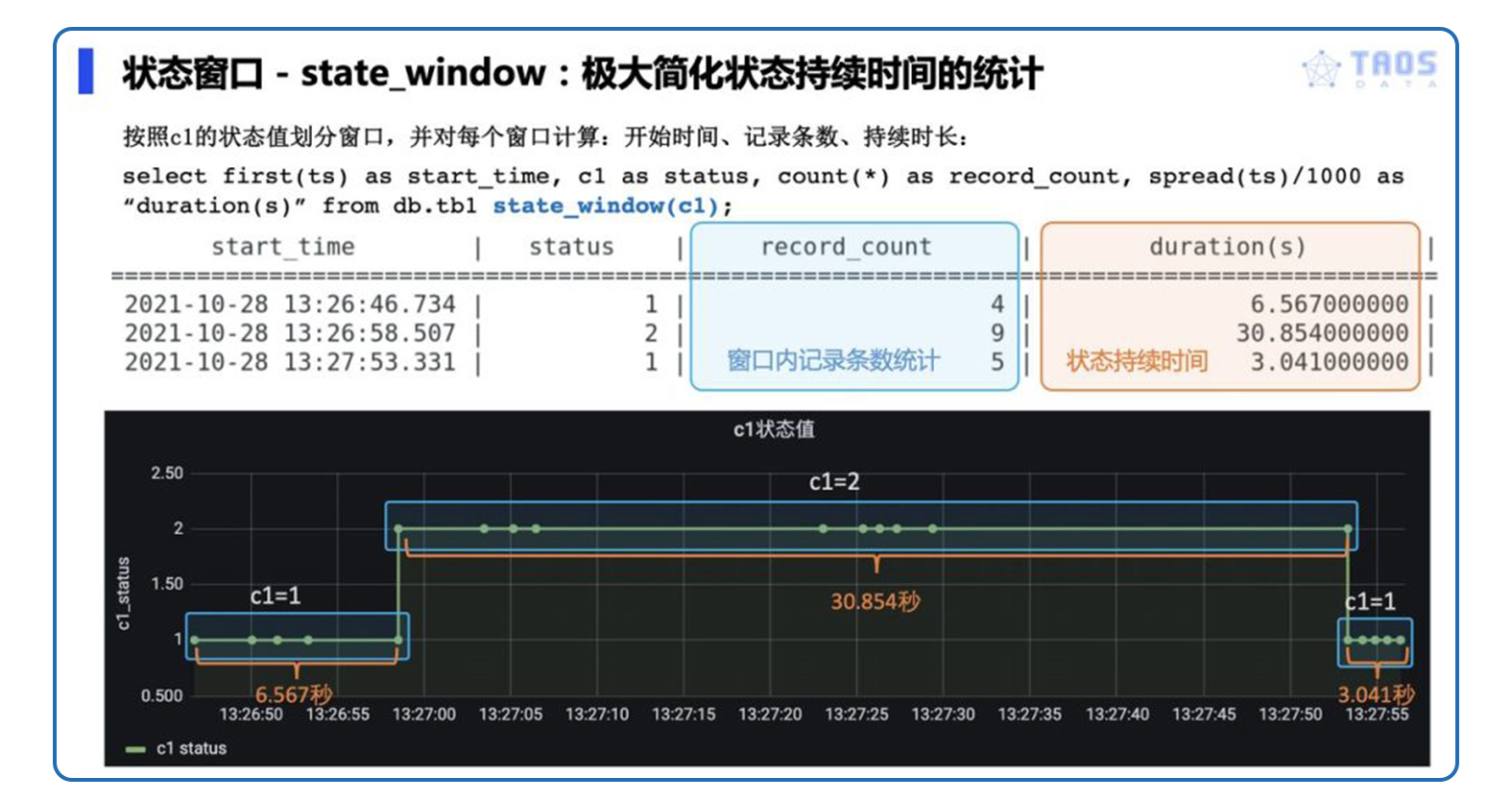
上图中 “status” 列,表征设备的当前工作状态,状态窗口对 “status” 值的连续变化情况进行判断,划分出三个窗口,并可以分别对每个窗口进行聚合,比如计算每个窗口内的开始时间、结束时间、总记录条数、平均值、窗口持续时间等。这些均可在 TDengine 中通过一条 SQL 查询语句直接实现,具体 SQL 语句和查询结果见下图。
3. 会话窗口(session)
在详细讨论会话窗口之前,我们先看车联网平台的一个典型应用场景:通过车辆行驶数据对车辆行程进行划分。一部车从发动起步,到停车熄火的中间行驶过程视为一个完整的“行程”。车辆在行驶时,车载 T-Box 一般会按照 30 秒的间隔,向车联网平台发送自身的状态数据;而停车熄火时,则不再发送。因此,通过分析车辆上报消息的连续性,可以推算出该车辆的行程。
会话窗口让用户可以按照上报记录的时间连续性来划分窗口,即相邻两条记录时间间隔不超过某一阈值,则划归同一窗口;超过该阈值,则老窗口结束,新窗口开始;然后对每个窗口进行诸如持续时间等统计,或对窗口内的原始采集数据进行各种聚合计算,可以是 avg/max/min/count 或其他用户自定义函数。
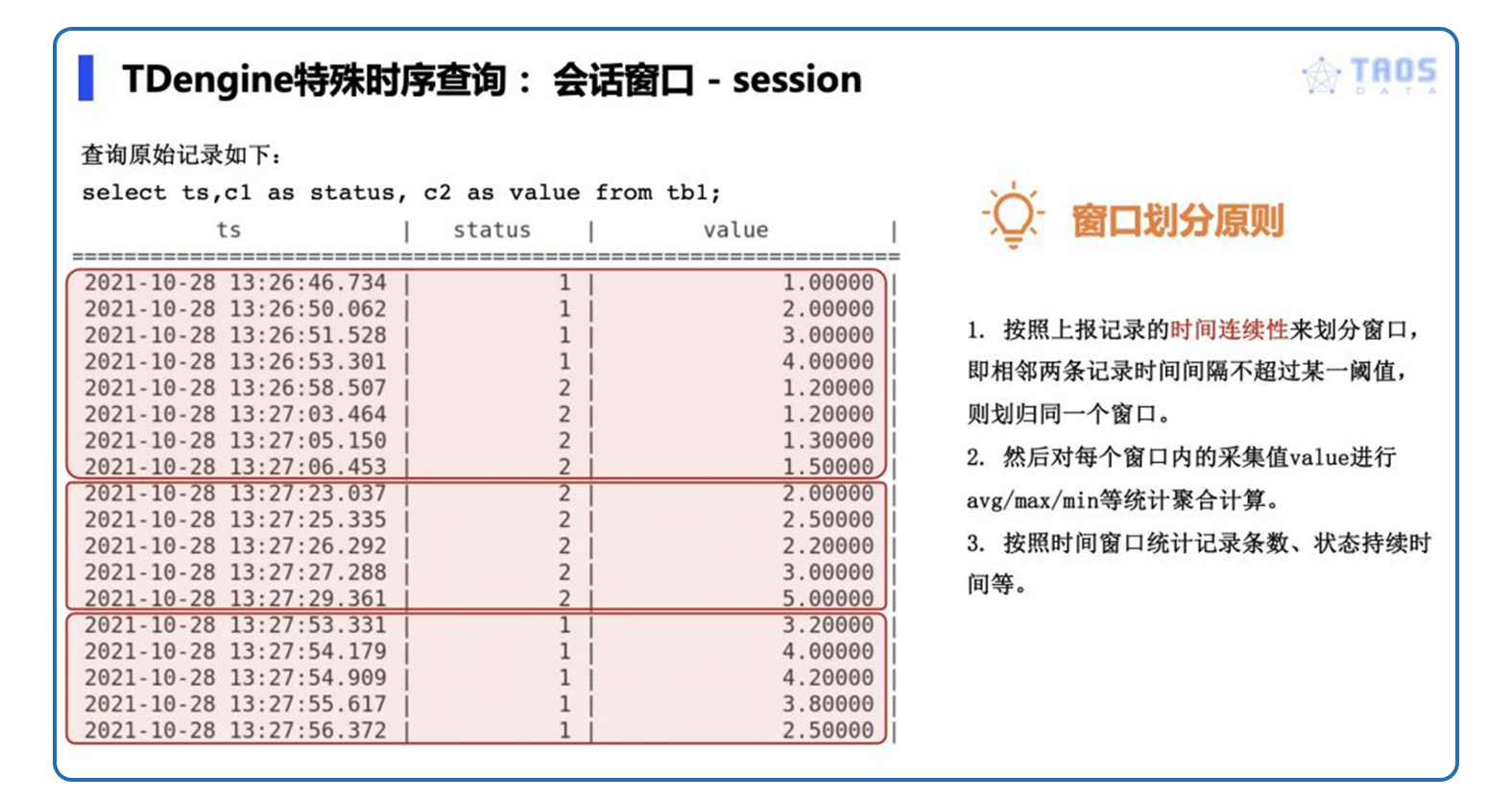
会话窗口针对的场景是:让用户通过一条 SQL 语句实现按时序数据的“连续程度”来自动划分窗口。
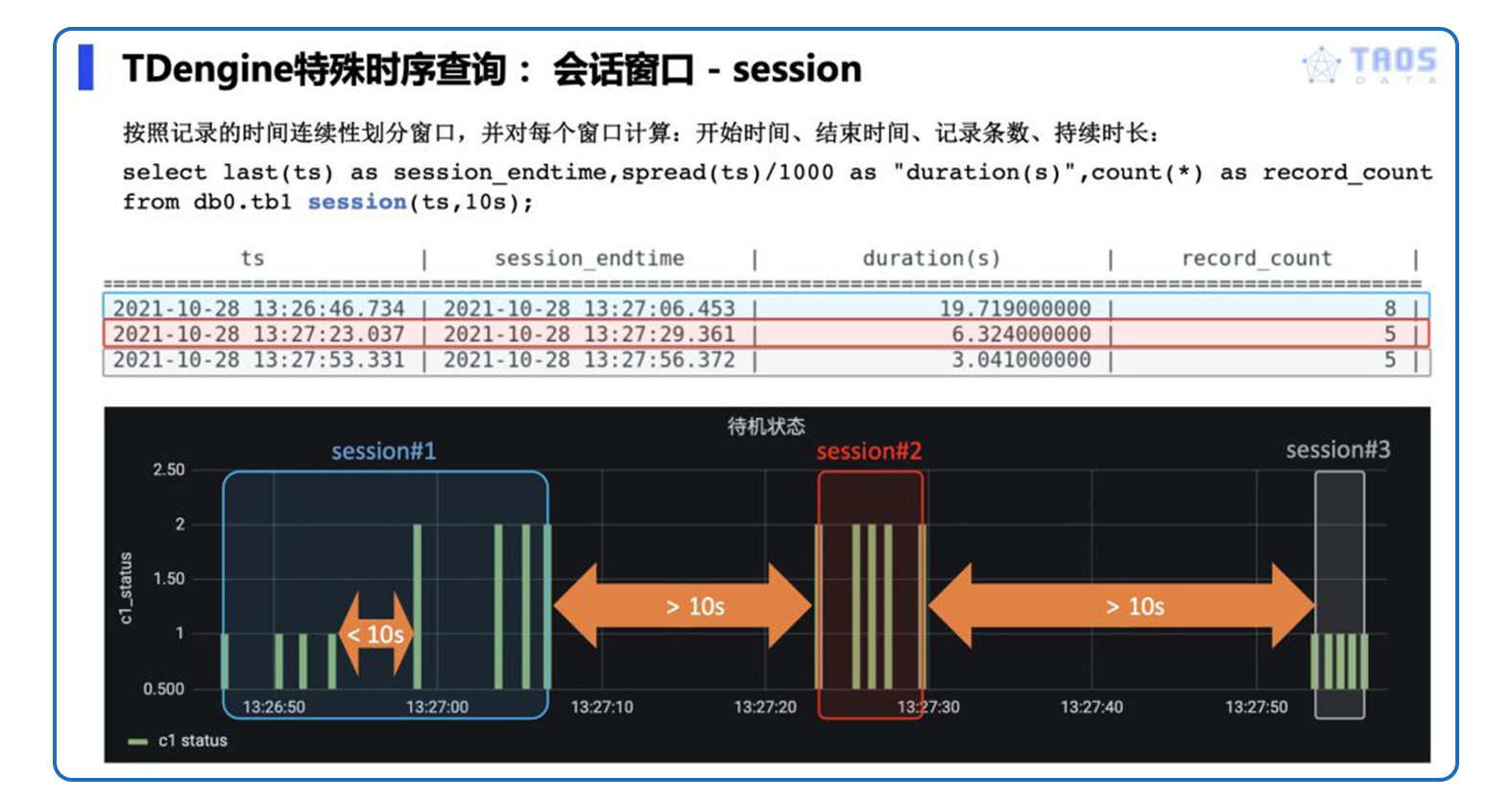
如下图中的 SQL 所示,用户设置 session ( ts, 10s ),就是将相邻记录时间间隔小于 10 秒的记录划分到同一个 session window 内;而对间隔超过 10 秒的两条相邻记录则划分到不同窗口。这样就在下图中划分出了蓝色、红色、灰色标示出的 3 个窗口,每个窗口可独立计算窗口开始/结束时间、窗口长度、窗口内记录数等用户感兴趣的统计量。
总结
时序数据除了数据量大、结构相对简单的特点外,还在查询场景中大量涉及时间戳的处理。我们往往要根据业务场景,按时间戳对采集数据进行分组并计算。对于这类计算,如果开发者将原始数据读入内存,再由应用层程序去处理时间窗口划分的逻辑,就不得不面对读取海量原始时序记录的磁盘 IO、CPU 及内存开销,同时业务层代码复杂度也变得更高。
如果开发者可以灵活运用 TDengine 这样的 Database 提供的时序数据窗口划分能力,结合业务场景,选择合适的窗口划分函数来将相关计算负荷下沉到数据库层,则能大大提升系统响应性能、减少负载开销,起到事半功倍的效果。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号