时序数据库的集群方案?
现在主流的时序数据库确实集群方案大多数都选择闭源,除了从技术角度上来看,商业的考量也是众多大厂必须考虑的元素之一。TDengine 作为一款全自研的开源软件,继2019年单机版开源后,在2020年也宣布集群版正式开源。这意味着,在集群搭建方面,对于研发资源单薄、时间精力都有限的企业来说,无疑是拨云见日的一则好消息。
正在苦寻方案的技术人,或者正在做技术选型的领导者们,欢迎大家移步我司官网,下载和测试
简单的广告之后,还是要用真正的技术说话,也为苦苦寻求技术方案的伙伴们提供一种新的思路。关于TDengine 集群的设计思路,可以从以下四方面来简单描述。(彩蛋!结尾有视频微课堂讲解,不想看文字的伙伴可以直接拉到最后呦~)
1、集群与主要逻辑单元
TDengine是基于硬件、软件系统不可靠、一定会有故障的假设进行设计的,是基于任何单台计算机都无足够能力处理海量数据的假设进行设计的。因此TDengine从研发的第一天起,就按照分布式高可靠架构进行设计,是完全去中心化的,是水平扩展的,这样任何单台或多台服务器宕机或软件错误都不影响系统的服务。
通过节点虚拟化并辅以自动化负载均衡技术,TDengine能最大限度地利用异构集群中的计算和存储资源。而且只要数据副本数大于一,无论是硬软件的升级、还是IDC的迁移等都无需停止集群的服务,极大地保证系统的正常运行,并且降低了系统管理员和运维人员的工作量。
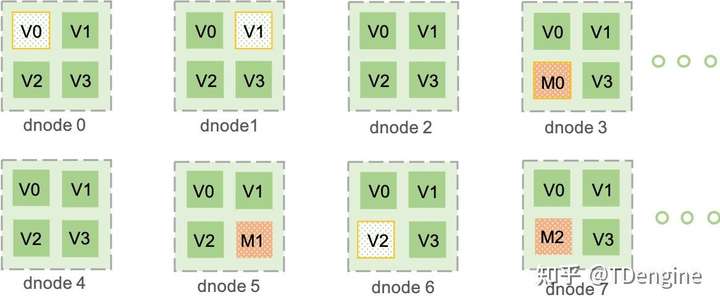
下面的示例图上有八个物理节点,每个物理节点被逻辑的划分为多个虚拟节点。
2、一典型的操作流程
为解释vnode, mnode, taosc和应用之间的关系以及各自扮演的角色,下面对写入数据这个典型操作的流程进行剖析。
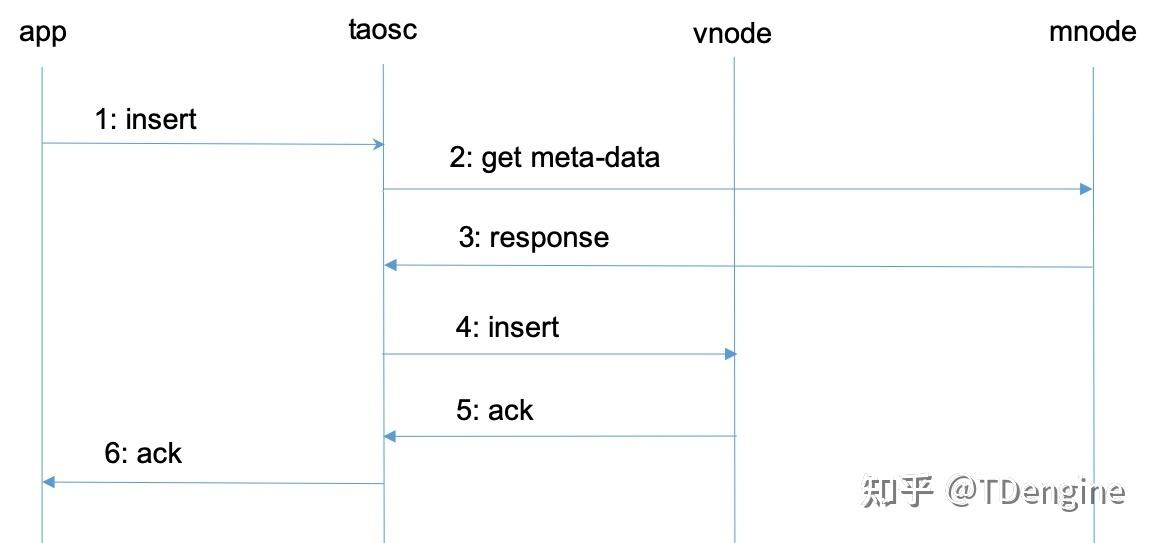
- 应用通过JDBC、ODBC或其他API接口发起插入数据的请求。
- taosc会检查缓存,看是有保存有该表的meta data。如果有,直接到第4步。如果没有,taosc将向mnode发出get meta-data请求。
- mnode将该表的meta-data返回给taosc。Meta-data包含有该表的schema, 而且还有该表所属的vgroup信息(vnode ID以及所在的dnode的IP地址,如果副本数为N,就有N组vnodeID/IP)。如果taosc迟迟得不到mnode回应,而且存在多个mnode,taosc将向下一个mnode发出请求。
- taosc向master vnode发起插入请求。
- vnode插入数据后,给taosc一个应答,表示插入成功。如果taosc迟迟得不到vnode的回应,taosc会认为该节点已经离线。这种情况下,如果被插入的数据库有多个副本,taosc将向vgroup里下一个vnode发出插入请求。
- taosc通知APP,写入成功。
3、数据分区
vnode(虚拟数据节点)保存采集的时序数据,而且查询、计算都在这些节点上进行。为便于负载均衡、数据恢复、支持异构环境,TDengine将一个物理节点根据其计算和存储资源切分为多个vnode。这些vnode的管理是TDengine自动完成的,对应用完全透明。
对于单独一个数据采集点,无论其数据量多大,一个vnode(或vnode group, 如果副本数大于1)有足够的计算资源和存储资源来处理(如果每秒生成一条16字节的记录,一年产生的原始数据不到0.5G),因此TDengine将一张表的所有数据都存放在一个vnode里,而不会让同一个采集点的数据分布到两个或多个dnode上。而且一个vnode可存储多张表的数据,一个vnode可容纳的表的数目由配置参数sessionsPerVnode指定,缺省为2000。设计上,一个vnode里所有的表都属于同一个DB。因此一个数据库DB需要的vnode或vgroup的个数等于:数据库表的数目/sessionsPerVnode。
创建DB时,系统并不会马上分配资源。但当创建一张表时,系统将看是否有已经分配的vnode, 而且是否有空位,如果有,立即在该有空位的vnode创建表。如果没有,系统将从集群中,根据当前的负载情况,在一个dnode上创建一新的vnode, 然后创建表。如果DB有多个副本,系统不是只创建一个vnode,而是一个vgroup(虚拟数据节点组)。系统对vnode的数目没有任何限制,仅仅受限于物理节点本身的计算和存储资源。
sessionsPerVnode的设置需要考虑具体场景,创建DB时,可以个性化指定该参数。该参数不宜过大,也不宜过小。过小,极端情况,就是每个数据采集点一个vnode, 这样导致系统数据文件过多。过大,虚拟化带来的优势就会丧失。给定集群计算资源的情况下,整个系统vnode的个数应该是CPU核的数目的两倍以上。
4、负载均衡
每个dnode(物理节点)都定时向 mnode(虚拟管理节点)报告其状态(包括硬盘空间、内存大小、CPU、网络、虚拟节点个数等),因此mnode了解整个集群的状态。基于整体状态,当mnode发现某个dnode负载过重,它会将dnode上的一个或多个vnode挪到其他dnode。在挪动过程中,对外服务继续进行,数据插入、查询和计算操作都不受影响。负载均衡操作结束后,应用也无需重启,将自动连接新的vnode。
如果mnode一段时间没有收到dnode的状态报告,mnode会认为这个dnode已经离线。如果离线时间超过一定时长(时长由配置参数offlineThreshold决定),该dnode将被mnode强制剔除出集群。该dnode上的vnodes如果副本数大于一,系统将自动在其他dnode上创建新的副本,以保证数据的副本数。
总结
比较常见的关于集群方案的问题,TDengien在设计之初就已经考虑到,这也是为什么很多企业纷纷将数据库迁移过来的很重要的一个原因。当企业还在花十倍甚至百倍的人力物力研发和搭建自己的集成方案时,跑在前面的企业已经借助更专业的力量和方案,实现了研发为业务赋能的承诺。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号