TDengine 应用实录:存储缩减超过 60%,HBase 等集群指数级下线
小 T 导读:狮桥集团的网货平台与金融 GPS 系统,对于车辆轨迹收集与计算有着强需求。GPS 每日产生总量在 40 亿左右,需要为业务方提供实时末次位置查询,近 180 日行驶轨迹查询,类似车辆轨迹对比查询,以及一些风险逾期的智能分析等等。应用 TDengine 后,他们的整体数据存储缩减超过 60% 以上,节省了大量硬件资源。
一、缘起
2021 年 10 月,我偶然读到 Jeff(涛思数据创始人陶建辉)所作的一篇讲述父亲的文章,言辞之恳切,也让我回想起了自己和父亲的种种过往,于是在 TGO(鲲鹏会)微信群中加了 Jeff 的微信。彼时恰逢我们技术选型之时,在和他的寒暄之中,我了解到了时序数据库 TDengine,我和 Jeff 一拍即合。带着业务上的场景和问题,我们约见了一次,他的热情及对 TDengine 的精妙设计深深吸引了我,对于我所提出的一些细节问题,他甚至拿出来最初写的代码为我讲解,吃惊之余也让我非常感动。
和 Jeff 的这次会面让我更加了解了 TDengine,也让我看到了国产开源产品的希望。经过审慎的思考,我们选择将 TDengine 接入到系统之中,在一切尘埃落定后我整理出了这篇文章,对 TDengine 的技术架构特点、我们自身业务的实践思路及应用效果进行了相关阐述,希望能帮到有需要的朋友。
二、业务背景
狮桥集团的网货平台与金融 GPS 系统,对于车辆轨迹收集与计算有着强需求。狮桥大数据团队自研星熠平台采用国标 JT808 协议前置接收数据,通过 Flink 实时计算写入到多个存储模块,最终利用络绎大数据 GPS 平台进行业务呈现,支撑集团多个业务系统的风控、贷前、反欺诈等模块。GPS 每日产生总量在 40 亿左右,需要为业务方提供实时末次位置查询,近 180 日行驶轨迹查询,类似车辆轨迹对比查询,以及一些风险逾期的智能分析等等。
三、从系统架构的迭代看业务需求
纵观狮桥集团的产品历史,技术架构共进行过四个大版本的迭代。
阶段一
最初构建系统时,由于工期、团队规模以及服务器资源的限制,实现上非常粗糙,仅能够完成最基本的功能。架构大概如下:

在此模式下,我们通过 MQ 接入厂商的数据,利用非分布式的实时计算能力传输到系统当中,仅仅实现了实时的位置查询以及一些非常基础的功能。
阶段二
之后我们进行了一次很大的改版,构建起了大数据集群,通过 Yarn 统一来进行资源调度,采用分布式的方式进行实时处理,实现了弹性伸缩,同时也在做 Spark Streaming 到 Flink 的过渡。业务上,从这个版本开始我们也接入了不同的 GPS 数据源,并且针对不同数据源的数据实现了实时切换查询,系统的复杂度提升较高。
与此同时,GPS 的轨迹数据在业务中开始使用,这就要求我们必须有存储的方案,需求是实时写批量读,即可以高效插入数据的同时还能够快速扫描大量数据。我们最终采用了 Kudu 进行存储,同时利用 Impala 在应用层进行 SQL 解析与加速,方便应用同学进行开发。此外,我们还需要留存 GPS 的数据,会将其进行压缩并写入到 HDFS 中。

阶段三
随着功能的逐渐增加,我们对散落的技术点进行了不断的整合——对所有的实时计算进行了 Flink 的统一,对所有离线的计算进行了 Spark 的统一。在这个过程中,也一直在对 GPS 数据的存储进行尝试和探索。
由于 Kudu+Impala 的模式是一个存储和解释引擎分离的架构体系,优雅与否放在一边,更重要的是, Impala 毕竟是运行在 OLAP 平台上的解释引擎,不适合在生产环境里做高并发的查询引擎,这违背 Impala 的设计初衷。随着不断深入的调研,我们尝试使用 Hbase、Clickhouse 替换 Kudu。此时系统架构演变为了计算引擎逐渐固化、存储引擎不断迭代的形态。
从存储功能而言,我们希望能够读写兼顾、支持 SQL,同时还有合理的分区策略,这一点 Hbase 肯定不能满足,因此我们寄希望于 Clickhouse。在这个阶段中 Clickhouse 的表现确实也不错,但还是没有完全满足需求。

阶段四
2021 年,我们在 GPS 平台基础之上进行了协议层的开发,构建了 JT808 协议层平台,并且和原 GPS 系统进行了打通。这样一来,我们就可以在市场上按照协议来进行厂商的筛选,提高竞价和议价能力,提升整个平台的效能。而在这个过程中,存储层的调研也带来了一个好消息,我们发现了一款名为 TDengine 的时序数据库。
此前,我们对 ClickHouse 进行了一系列的测试,虽然效果还算不错,但对于某些场景而言仍然存在问题,以轨迹查询(一般是对单个车辆的轨迹进行查询)为例,虽然列式存储有着天然的优势,但如果 HBase 的 rowkey 设计的更精巧一些,那使用 Hbase 进行时间周期的轨迹查询将会更加直接高效,然而 HBase 天然又对 SQL 非常不友好。因此我们一直在思考一个问题,是否有一个存储技术既可以兼并读写性能,又可以契合到我们的业务场景,且还是 SQL 原生的?
本身 GPS 的数据就类似于设备产生的数据,即时序数据,因此我们开始基于时序数据库赛道进行了一轮筛选。因为同处 TGO“大家庭”中,Jeff 所创立的 TDengine 自然而然地走进了我的视线中,殊不知,这次遇见让我们跳过了千辛万苦,直接触碰到了时序数据库赛道的“天花板”。
四、为什么我会选择 TDengine?
TDengine 有着非常精妙的架构设计,它是基于物联网典型业务场景和数据特性所设计和优化的优秀时序数据库产品。下面我把一些打动我的优雅设计策略为大家进行下分享。
Device = Table
可以说,这个概念直接颠覆了我们对于普通数据库的认知。无论是 ClickHouse 还是其他数据库,大都是从业务维度来构建库表,而在 TDengine 中是以采集点为单位来构建表,一个 device 就等于一个表。
对于狮桥来讲,如果我们有 50 万辆车跑在路上,那么就需要构建出 50 万张表。乍一听,好像有点不可思议,但是抛开固有思路,这样做的第一个优点就是解决了我们在上述架构演变的第三阶段中希望解决的问题,即我们希望一个设备在一个时间范围内的数据是连续存储且可以整块获取的,这样基本上歼灭了磁盘的随机访问,类似于 Kafka 的顺序读写机制,可以获得最高的效率,TDengine 在这一点上完全解决了我们的痛点。
同时,这个新型概念也让时序数据的写入速度有了非常大的提升,你可以用 Kafka 的顺序写入的思路去理解。
在表级别上做了“继承”
这个小标题可能不太贴切,但是它带来的效果有些类似。众所周知,TDengine 有个超级表的概念,通过定义超级表的标签可以归类不同的超级表,每一个超级表是一类普通表的抽象集合统称,在进行普通表的聚合操作时,通过其“继承”(或者叫做实现)的超级表进行预聚合(类似于索引查询),可以大幅提升效率,减少磁盘扫描。
科学的逻辑单元划分
在 TDengine 中,所有的逻辑单元都叫做 node,在每个 node 之前加一个字母,不同的逻辑节点就诞生了:
- 物理节点(Pnode),代表物理(机)节点,通俗来说即裸金属节点
- 数据节点(Dnode),代表运行实例,也是数据存储的组合单元
- 虚拟节点(Vnode),是真正负责数据存储与使用的最小工作单元,Vnode 组合而成 Dnode
这种划分的科学之处就在于,数据进行分片时将 Dnode 中的 Vnode 进行分散即可,而每一个 Vnode 中会有多个 device 的数据表,这个类似于 MongoDB 的 Sharding 的机制。根据 TDengine 的设计初衷,为了对 device 中的数据进行连续有序的存储,它会针对一个 device 进行单 Vnode 的强映射,而不会拆成多个 Vnode,这样就避免了因数据散落在不同位置(物理节点)还需要通过网络 merge 的问题,最大程度上提升了效率。
在 TDengine 中,利用的是 Vgroup 的机制保证数据的副本高可靠,这块可以进入 TDengine 官网参看文档,写的非常清楚。总而言之,这些职能划分和逻辑设计使得 TDengine 既可以满足高可靠,又能够对 device 级别吞吐提供读写数据需求。当然,具体有多强,大家可以参看压测对比,也可以自己尝试一下。
Mnode 的两个精妙之处
在上面的解释中,我特意避开了 Mnode 的说明,下面我要单独讲解。
从逻辑意义上理解 Mnode 很简单,就是 Meta Data 的管理者,在很多中间件中都有这个角色,比如 Hadoop 的 NameNode、Kafka 中通过 Zookeeper 保存的 Metadata 信息。但是 TDengine 的 Mnode 有两个功能非常巧妙。
Mnode 是幽灵般的存在,究竟在哪一个 Dnode 上都是系统自动实现的,用户无法选择。当用户需要访问 TDengine 的集群时,肯定要先知道 Mnode 在哪里,继而才能通过 Mnode 来获取集群信息和数据,这个过程是通过 taosc(client 模块)进行访问的。设计的精妙之处在于,这个过程中你直接访问集群中的任何一个 Dnode 都可以获取到 Mnode 的信息,从而免去了从一个 metadata center 中去获取元数据。这种设计策略在 ES 和新版的 Kafka 中都在使用,用一句话形容就是形式上去中心化的元数据存储与获取机制,在这一点的架构设计上,TDengine 走在了时代的前列。
其次,Mnode 可以帮助监控 Dnode 的负载情况,一旦遇到 Dnode 负载压力高、数据存储热点分布不均衡的场景,Mnode 可以帮助转移 Dnode 的数据,从而消除倾斜。值得一提的是,在这个过程中,对外服务是不会停止的。
五、我们在 TDengine 上的实践
轨迹数据存储与查询
鉴于 TDengine 的特性,用它来存储轨迹数据非常合适。我们在 JT808 协议平台后挂上了 Kafka,通过 Flink 直接把数据写入到了 TDengine 中。在和 TDengine 的小伙伴进行探讨与优化的过程中,我们惊奇地发现,TDengine 写入时的 driver 多采用堆外内存的读写策略,对数据缓存和写入做了极大的优化,写入效率非常高。
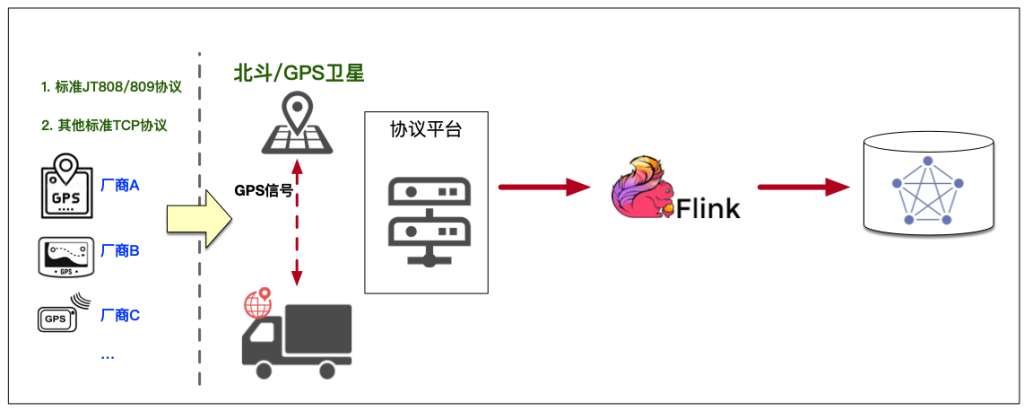
在数据查询上,由于 TDengine 天然支持 SQL,应用开发同学的学习成本呈现几何级的下降,极大地提升了开发效率。对他们来说,数据不管是存在 MySQL 还是 Oracle 抑或是 TDengine 都是完全透明的。
末次位置查询
此前,我们需要使用 Flink 把数据打入到 Redis 集群中,进行末次位置的存储与查询。而 TDengine 中的“最新热数据缓存”的策略恰恰契合到了我们的需求,Redis 集群就可以直接省略了。当我们研究到这个功能时,简直热泪盈眶——这不是针对某一个业务的帮助,而是在对一整个行业进行了透彻的洞察之后所设计出来的灵魂级的功能。
大家都知道 LRU,这种管理缓存策略的初衷是,我们不知道数据以何种方式进入到系统中,只能用随机与无序来定义数据,通过 LRU 的机制可以筛选出未来可能会被使用的数据来进行缓存,用“猜想”的方式来提供查询加速。
而 TDengine 本身就是为 IoT 而生,它洞察到了时序数据的特性,从而采用以时间顺序来设计的 FIFO 来定义缓存的策略,即新鲜的数据会落在缓存中,方便企业查询最新产生的热数据。依靠着这个设计,我们只需要一个简单的 SQL 即可从内存中以最快速度获取想要的数据,此时 TDengine 摇身一变,就成为了一个支持 SQL 的内存数据库。在部署了 TDengine 之后,我们下线了一整套的末次位置 Redis 集群。
自动化的分区与数据保存策略
上文中我们讲到过 TDengine 的分片机制,那分区又是如何做到的?在我们使用时发现,TDengine 可以设置 days 的参数进行数据存储,以时间范围对数据进行分区。简单来说,我们的场景是搜索过去 180 天内的轨迹数据,但是更多的场景都是以月的纬度来搜索,那我们我们可以把 days 设置成 30,这样数据就是以每个月分块,搜索的时候也是整体捞出,效率非常高。
而超过 180 天的数据,我们不会去进行展示搜索,因为数据在 HDFS 上还有压缩的存储,所以我们通过 TDengine 的 keep 参数来设置数据保留多久,即设置 keep=180,这样超过 180 天的数据会被自动清除,对存储极为友好。
使用 TDengine 后的效果
从时序数据量大的特点出发,TDengine 有着一系列非常高效的压缩手段。大家可能都知道 ES 中的 FOR 或者 RBM 等压缩算法,我猜想 TDengine 中应该也使用了类似的压缩方式,使得整体数据轻巧且有序。
应用 TDengine 后,我们整体数据存储缩减超过 60% 以上,集群更是指数级的下线——末次位置查询的 Redis、轨迹查询的 Hbase 集群集体下掉、Clickhouse 也不再用作轨迹存储,把裸金属用在了更需要蛮力干活的地方。目前 TDengine 在“降本”方面给予了我们巨大的帮助,相信未来在其助力下,我们也会在“增效”的道路上越走越远。
六、写在最后
从我的感受来讲,TDengine 是一家年轻有活力的企业,工程师文化非常浓厚。我很喜欢和 Jeff 探讨技术,每每看到他拿出笔记本打开 IDE 看每一行的源代码时,我就越发觉得我们应该重新认识程序员这个职业,伟大的不仅仅是那些商业领袖,更多的是用一行行代码来改变世界、怀揣着梦想却又务实的人们。
希望 TDengine 未来能多举办一些 Meetup 来进行更多的交流,也可以做一些 Best Practice 的讲解。在一些语言与中间件上,直接出一些简单的 Showcase,便于大家上手实践,一起来见证这个时代最好的时序数据库的成长。
作者简介
杨路,前狮桥集团大数据团队负责人,深耕大数据平台架构与三高应用平台建设,标准技术控一枚。InfoQ 连载《大画 Spark》作者。
想了解更多 TDengine 的具体细节,欢迎大家在GitHub上查看相关源代码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号