8分钟了解TDengine的WAL机制
 WAL(Write Ahead Log),是 TDengine 的一个重要的功能模块,它可以实现数据的容错能力,保证数据的高可用。
WAL(Write Ahead Log),是 TDengine 的一个重要的功能模块,它可以实现数据的容错能力,保证数据的高可用。
作者:陈玉 涛思数据

WAL(Write Ahead Log),是 TDengine 的一个重要的功能模块,它可以实现数据的容错能力,保证数据的高可用。
听着复杂,其实也很简单。对于关系型数据库的使用者来说,它大概就相当于 Oracle 中的 redolog ,MySQL 中的 binlog 和 redolog,里面记录的是一切关于数据库的更新修改操作。
Write Ahead Log 翻译一下是“预写日志”,含义就是:在数据写入存储之前,先按照时间顺序在日志中做一下记录,这样就可以确保应用能够通过这个日志将数据库恢复到任意的某个状态,即使数据库因为断电等意外事故宕机,也能避免数据的丢失。
目前,TDengine社区版尚不支持将数据回滚到指定时间,如有需要,可以联系我们的企业版团队来解决。
TDengine 中的 WAL 实现机制稍有特殊。它把 WAL 分为两部分,一种是 mnode 目录下的 WAL,一种是 vnode 目录下的 WAL。(为了方便本文的阅读,这里需要大家首先了解TDengine的基础架构:管理节点(mnode)和虚拟数据节点(vnode)的概念:https://www.taosdata.com/docs/cn/v2.0/architecture)
在 TDengine 的数据文件路径下(默认为/var/lib/taos),就可以看到上述目录结构。
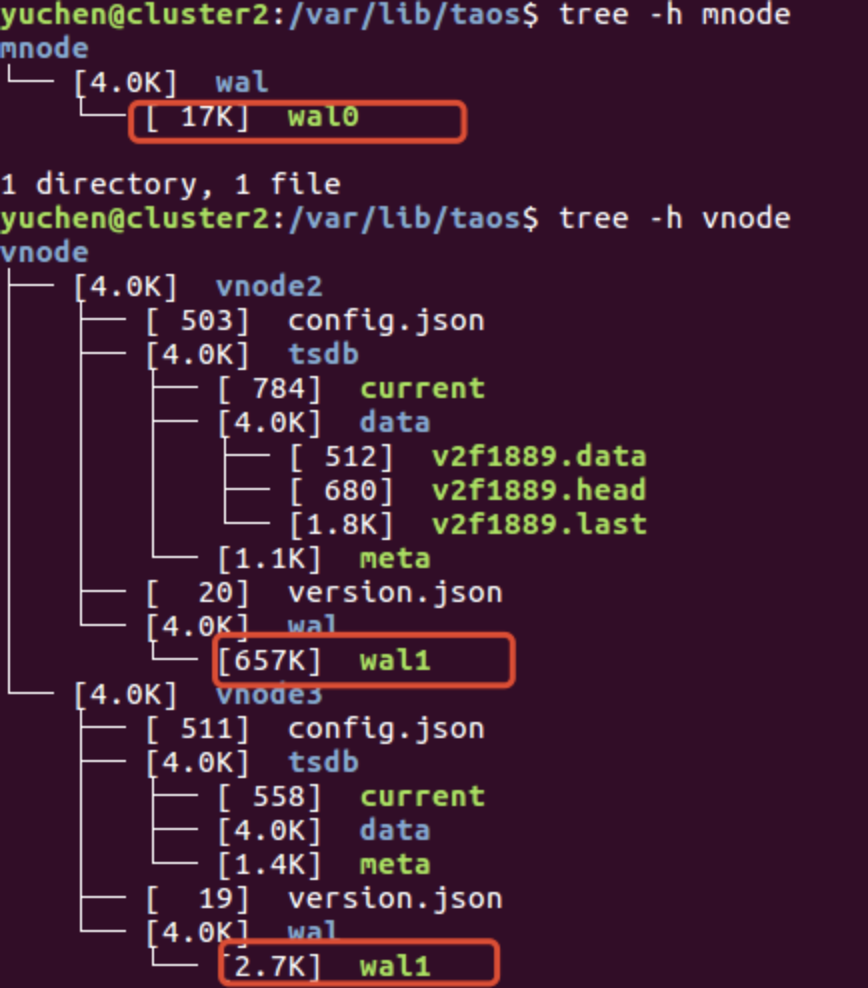
mnode 的 WAL 内容是持久化在硬盘上的,作为最重要的管理节点,它的 WAL 记录着所有关于数据库的 DDL 操作(比如创建删除操作:create dnode,create account,create mnode,create user,create table, drop dnode ,drop table等,或者修改操作:alter database,alter table ,alter user等)
而 vnode 目录下的 WAL 则主要负责记录着写入数据的操作,与此同时也记录着对表的 DDL 操作,在触发落盘后会清零。(这就是我们在之前的文章——比如《存储成本仅为OpenTSDB的1/10,TDengine的最大杀手锏竟然是什么?》——中经常提及的部分,大家可以结合此文阅读,以加深理解。)
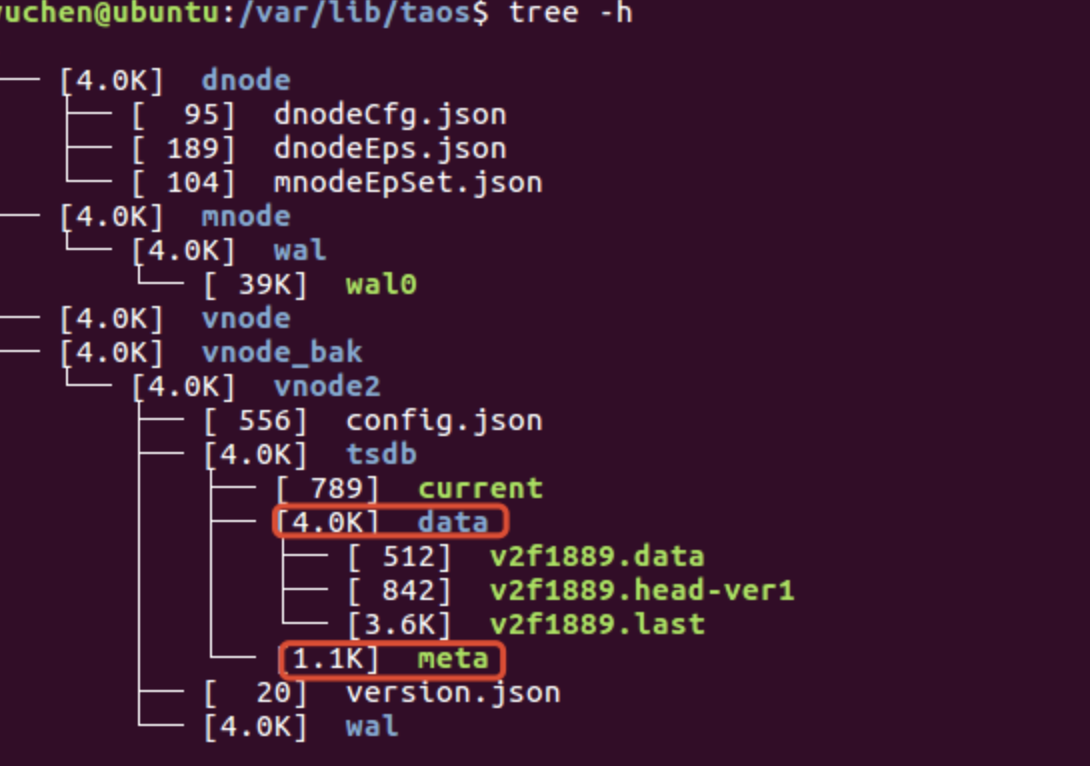
之后,写入 vnode 的时序数据会落盘到数据文件目录 /vnode/vnodeX/tsdb/data 下面。而对于表的 DDL 操作(也就是表的元数据)则会落盘到数据文件目录/vnode/vnodeX/tsdb/meta文件中,如下所示:
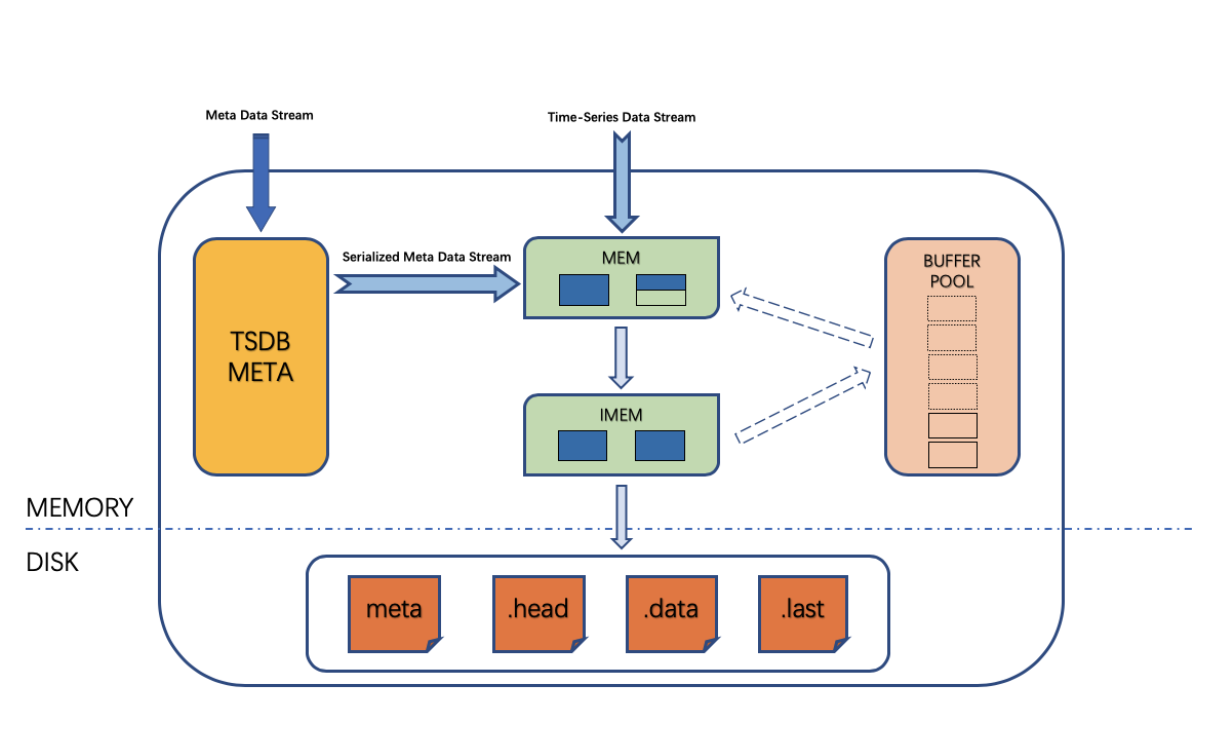
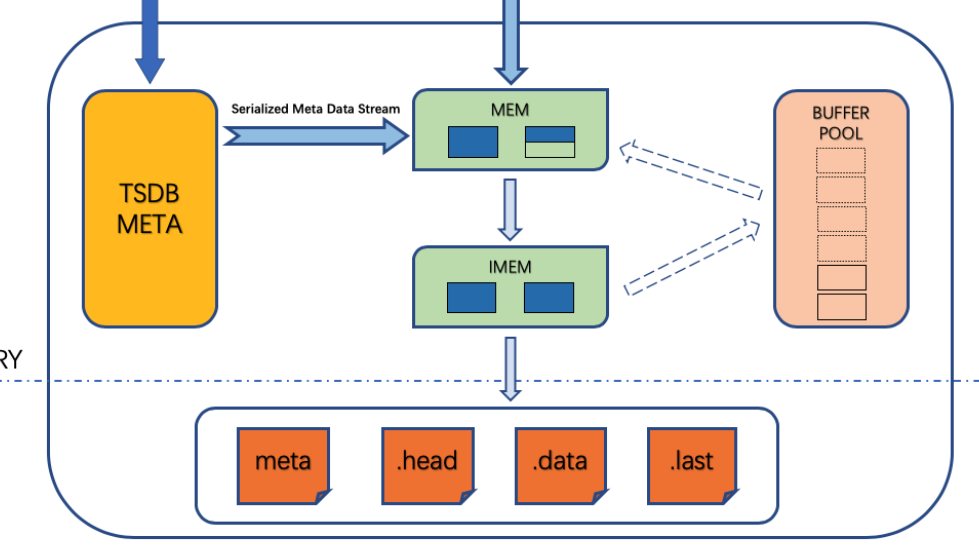
上面的第二张图是 vnode 的工作流程,从这里我们可以更清楚地看到时序数据和元数据是如何在写满三分之一的 buffer pool 后落地到磁盘的(一个 meta 文件,一个数据文件组:.data、.head、.last文件)。
总结而言,mnode 通过 WAL 记录了集群、用户、数据库以及表的元数据等信息。而 vnode 通过 WAL 记录了数据和表的元数据,并且会在落盘触发后清零,而其记录的表的元数据会被写入到 meta 文件,时序数据会被写入到 data 目录。
在了解了 WAL 的作用后,接下来会衍生出细节的场景:
首先,WAL 是将数据库数据更新操作按照时间顺序追加更新的日志文件。数据库进程 taosd 在启动的时候会逐行读取 mnode 下的 WAL 文件并操作,直到最后一行,才能顺利启动服务。
这样的构造下,可能会导致这个问题出现:
1. 当累计的 DDL 操作过多时,TDengine 的启动会变慢——那么要如何避免这种情况的发生呢?
首先,当子表数量绝对大的时候,这个情况是没法避免的。但是这是一个很大的数量级,对于绝大多数用户都是达不到的。
更容易出现的是这种情况:这个环境表数量并不是很多,但是却充满了频繁的删库删表重建表等操作。比如,创建一个十万子表的超级表后删掉,然后再重建这个超级表。等到数据库启动加载WAL的时候,即便前面的 create table 和 drop table 都是无效的操作,但是还会被操作一遍,而且删表操作本身在加载的时候也会更慢一些,从而大幅拖慢 TDengine 的启动速度。
因此,为了避免这种情况,生产环境上一定要慎重。尤其是要尽量杜绝删库、删除超级表这些重大操作,如果是为了调试,反复重建的测试操作一定要在测试环境进行,生产环境不可延用测试环境直接建库建表投入使用,除非该服务器的 TDengine 已经卸载干净。
2.那如果是使用时间太久,或者各种更改表结构的操作无可避免,导致 mnode 下的 WAL 过大,是不是无解了呢?
对于这种情况,在 2.1.5 版本之后,我们提供了离线压缩 Mnode WAL 的方案来解决:
1)单机:
- systemctl stop taosd。
- taosd --compact-mnode-wal,如果执行正常的话,会在数据文件目录下生成 mnode_bak 目录,用于保存原数据。
- systemctl start taosd,这样 TDengine 就会使用压缩过的 wal 日志来启动数据库服务进程。
2)集群:
- show mnodes ,确认 mnode 节点所在的服务器,并且区分 mnode 的 master 和 slave。
- systemctl stop taosd,停止集群所有节点。
- 【可选】移出所有mnode 节点上的 mnode_bak目录。
- 在 mnode master 服务器上,以 root 权限执行 taosd --compact-mnode-wal 。
- 将 mnode master 压缩后的 mnode/wal/* 文件复制到其他 slave 节点对应目录。
- 重启集群。
值得注意的是,taosd --compact-mnode-wal 命令第一次的运行时间与压缩前集群启动时间基本相同,要等到下次再启动的时候速度才会变快。
此外,在未来的 TDengine 3.0 版本中,这也会是我们的重大的优化项。由于 WAL 也会变成分布式的存储,届时,即使是在亿级别表数量的情况下,TDengine 的启停速度也都不再会是问题。而且这项优化不过是 3.0 版本诸多特性的冰山一角。这项调整的背后代表着 TDengine 对于很多重要模块的优化重构,稳定性和性能都会大幅提高,多项重磅功能也会上线。
从 1.0 时代跟过来的老用户应该会对 2.0 的版本的进步深有感触,3.0 版本可以说更是青出于蓝。
让我们一起期待。
想了解更多TDengine的具体细节,欢迎大家在GitHub上查看相关源代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号