TDengine 助力京东云 IoT 数据统计改造
 实现了海量物联数据的高性能、低成本的存储。
实现了海量物联数据的高性能、低成本的存储。
作者:何佳瑞
小 T 导读: 在万物互联的时代,大到企业数字化转型、数字城市建设,小到和生活息息相关的家居生活、智能驾驶、运动健康等,都离不开智能物理设备广泛的连接和互通。AIoT 是人工智能和 IoT 技术的融合,通过物联设备网产生、收集来自不同维度的、海量的数据存储于云端、边缘端和设备端再通过海量数据分析引擎,以及更高形式的机器学习、神经网络,实现万物数据化、万物智联化。

2014 年起,京东从智能家居领域开始发力,在业界率先推出语音交互入口-叮咚智能音箱,实现了广泛的设备品类互联生态,同时整合集团内部零售、物流、大健康、工业品等关键领域的物联网技术能力,持续助力社区、城市、车联、工业等关键行业领域,广泛服务于实体经济,助力企业转型升级。本文在京东云 IoT 多年来行业实践经验积累的基础上,分享在数据存储方面的一些做法。
一、场景与痛点
数据是数字化时代企业的核心资产。京东云智能家居场景维护着大量的智能设备,这些设备联网后,会根据设备设定的速率持续产生时序数据,比如有的设备采样间隔是 15 秒。京东云 IoT 团队结合本公司数据特点与业务需求,对多种工业时序数据库进行了技术选型,以解决庞大的数据存储和计算带来的挑战:
- 数据存储具有较高的数据压缩比,节约存储资源,降低 IT 成本
- 写入和查询性能优异,数据库底层逻辑的优化可以减少 CPU 开销
- 支持数据预聚合,拥有丰富的计算算子
- 强有力的稳定架构
二、技术选型
我们对两种业界主流的时序数据库做了分析和测试:
- OpenTSDB:基于 HBase 的分布式、可伸缩的时间序列数据库。作为基于通用存储开发的时序数据库典型代表,起步比较早,在时序数据库领域的认可度相对较高,但 HBase 成本高的问题无法免除。
- TDengine:在性能、成本、运维难度等方面都表现不俗,支持横向扩展,且高可用。
通过实际对比测试,我们初步选定 TDengine 作为数据存储方案。TDengine 相比于 OpenTSDB 有明显的优势:
- TDengine 写入吞吐量高出 200%
- 1 亿条记录平均查询时间提升 100 倍
- 100 万条记录读取时间提升 32 倍
- 1 亿条记录按时间分组取均值时间提升 40 倍
- 成本开销降低 2-3 倍
三、数据建模
TDengine 数据建模需根据数据的特性设计相应的 Schema,以达到最好的性能表现。对于物联网设备而言,是围绕着设备孪生工作的。设备有对应的物类型、物模型,物模型描述了设备的属性感知和交互行为。因此,我们基于物类型、物模型进行了 Schema 的设计:
- 基于物类型、物模型创建超级表
- 数据聚合以字表为维度,按照物模型及数据特性,选择不同的聚合算子进行聚合
超级表举例如下:

四、落地实施
结合业务需求与数据特点,我们采用的方案是:将设备上报的元数据存储在 metadata 库中,然后通过定时任务的方式,每小时以设备的维度,根据物模型,进行数据聚合,将聚合后的数据存储在 statistics 库中。同时为了减少数据存储的压力,将 metadata 的数据过期时间设置为固定时长。

五、改造效果
在与 TDengine 工程师沟通后, 我们只使用了 3 台 4C16G 构成的 TDengine 的集群,就承载了线上的业务。
数据聚合方面,根据 TDengine 的性能、机器配置和前期测试的时间开销,只需很短的时间就完成了全量设备的数据聚合。
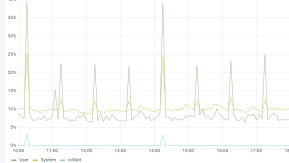
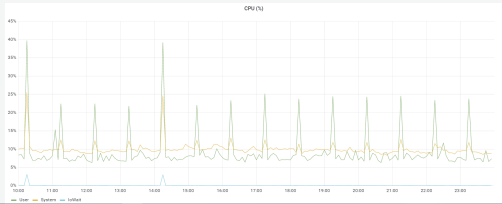
CPU 方面,一直很稳定,在常态下 CPU 低于 10%,由于设备的数据聚合需要消耗大量的 CPU,因此在每个整点 CPU 会有所上升,但是不超过 45%的负载。
六、总结
通过一段时间的运行,TDengine 在成本、性能和使用便利性方面相比 OpenTSDB 都有非常大的优势,实现了海量物联数据的高性能、低成本的存储。
在项目实施过程中, TDengine 的工程师提供了专业、及时的帮助,在此表示感谢。希望 TDengine 能够继续提升性能和稳定性,开发出更多的新特性、新功能,实现更大的突破。
⬇️点击下方图片查看活动详情,把iPhone 13 Pro带回家!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号