格创东智选择 TDengine,实现海量数据实时全生命周期管理
 TDengine在处理超高频的数据采集、边缘智能计算框架、数据流引擎和数据模型等方面效果显著。
TDengine在处理超高频的数据采集、边缘智能计算框架、数据流引擎和数据模型等方面效果显著。
作者:唐时涛
小 T 导读:格创东智科技有限公司成立于 2018 年,孵化于中国 500 强企业 TCL,是我国知名的工业互联网平台服务商。公司依托 TCL 集团 40 年工业场景和制造基因沉淀,基于“面向工业现场”的研发方向和“连接、协同、共享”的发展理念,深度融合人工智能、大数据、云计算、物联网等前沿技术,打造了新一代具有自主知识产权的工业互联网平台——"东智工业应用智能平台"。

作为东智工业应用智能平台产品家族的物联网平台,G-Things 为工业设备提供了安全可靠的连接通信能力,其支持数据采集、规则引擎、数据转发、指令下发、数据可视化,同时提供开放的 API 与第三方系统快速对接,为工业企业提供高效率、低成本、高可靠的工业物联网解决方案。
从采集的数据类型上来看,平台采集的设备数据以及系统业务主要有以下时序数据特性:
- 设备所有采集的数据是时序性的、结构化的
- 设备采集点的数据源是唯一的
- 数据存在时效性
- 以写操作为主,读操作为辅
- 需要统计、聚合的实时计算操作
- 数据的查询一般指定时间区间
- 支持高频数据接入
为了让用户在最大程度上实现降本增效,G-Things 在接入不同的租户时,会从用户类型(轻量级、重量级等)、设备规模、设备采集的数据量等角度帮助用户选择适配合理的时序数据持久化落地方案。
一、时序数据库选型调研
自 2019 年我们便开始关注一些国内的数据库,通过调研发现 TDengine 很适合我们的业务场景,它拥有读写性能强大、部署简单、超强的数据压缩比等特性,同时超级表、子表的标签 tag 设计也很好地契合了平台物模型中的设备模型、设备概念。
为了验证 TDengine 在读写、存储等方面的性能,我们将其与 Cassandra 、OpenTSDB 在同等条件之下进行了相关的读写性能对比测试,测试结果如下:
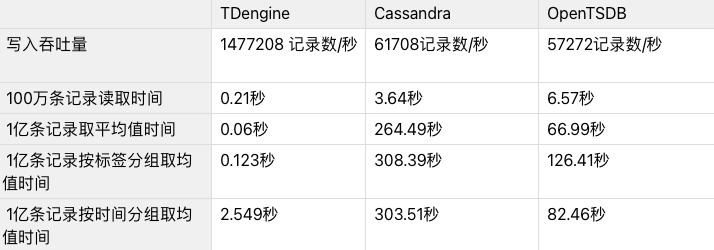
在同等数据集和硬件环境下,对比发现:
TDengine 的性能远超 Cassandra 和 OpenTSDB,写入性能分别是两者的近 20 倍、25 倍,读取性能约为 17 倍、32 倍,聚合函数性能约为 4000 倍、1000 倍,按标签分组查询性能约为 2500 倍、1000 倍,按时间分组查询性能约为 119 倍、40 倍,压缩比约为 26 倍、5 倍。
基于此,TDengine 在选型中脱颖而出。
二、技术架构与具体实践
具体到实际业务中,我们使用 TDengine 主要存储以下三种类型的数据:
- 租户设备上抛的原始数据。经过实时计算处理后保存,租户彼此之间数据隔离,一个租户一个 TDengine 库
- 系统计算设备状态变更的日志数据
- 系统中跟设备关联的相关控制台的操作日志数据
TDengine 在平台中的总体架构图如下所示:
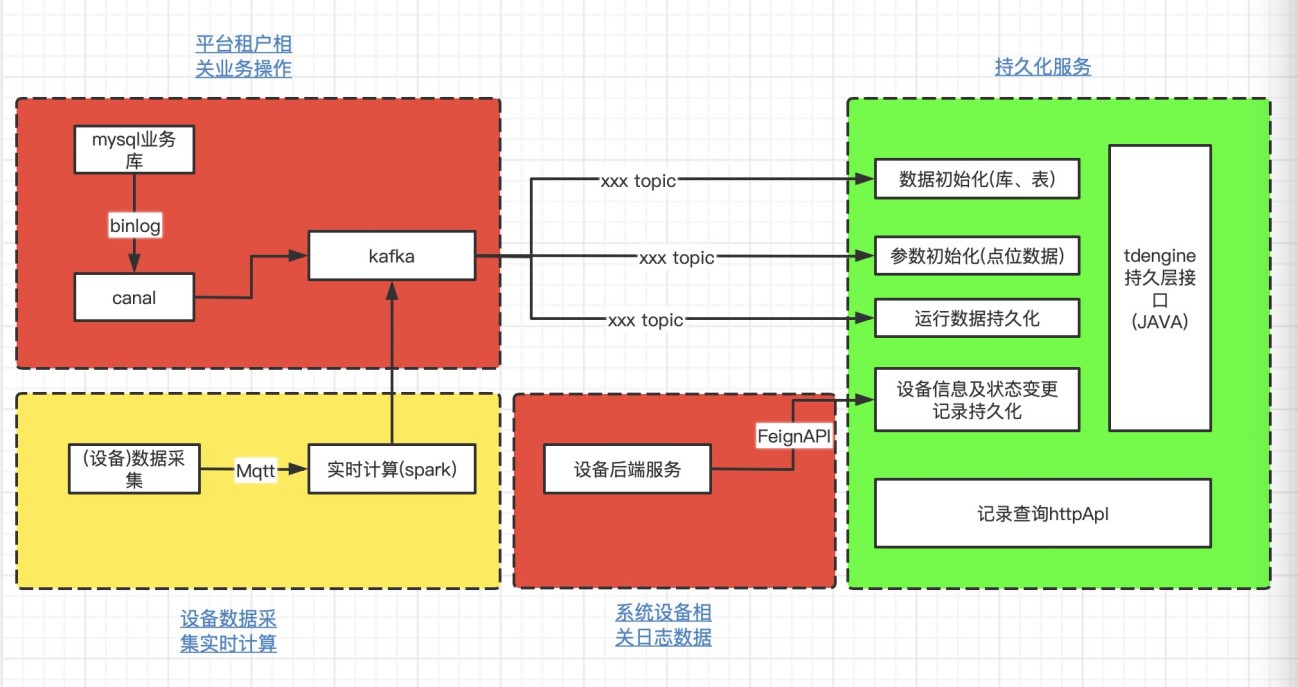
相比于原架构,使用 TDengine 之后出现了以下变化:
- 平台接入的租户相关库、表通过监听 Kafka 中的 binlog 日志自动初始化,每个设备点设置独立一张表,数据分层清晰
- 将 Cassandra、KairosDB、OpenTSDB 均更换为 TDengine
- 可以使用 API 或 SDK 对 TDengine 进行读写
- 减少了数据流流动、处理以及服务之间的消息通讯步骤
- TDengine 提供的丰富函数减少了实时处理的数据计算
- TDengine 提升了读写速度,减少了数据流处理时间
2.1 TDengine 表结构设计
具体到表结构设计上,在我们的实际场景中,采用的是一个租户一个 database 的方式进行创建,这样的好处有三点:
- 可以为不同的租户提供独立的数据库,用户数据隔离级别很高,安全性很好
- 有助于简化数据模型的扩展设计,满足不同租户的独特需求
- 如果出现故障,恢复数据相对简单
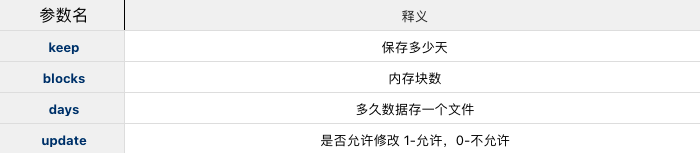
create database xxx keep 365 days 10 blocks 4 update 1;
2.2 设备运行数据
设备运行数据以设备模型为超级表,该超级表命名规则为 pd_模型标志,例如:pd_devicemodel001,以设备参数为子表名。具体的建表语句如下:
create table pd_devicemodel001(ts timestamp, smallint_value smallint, int_value int,bigint_value bigint,double_value double,boolean_value bool,string_value nchar(200) ) tags( device_model_mark nchar(25) ,device_mark nchar(25), param_mark nchar(25)) ;
如果需要创建的是单个参数的数据表,那子表命名规则是 pd_模型标志_参数标志,例如:
pd_devicemodel001_param01。具体的建表语句如下:
create table pd_devicemodel001_param01 using pd_devicemodel001 tags ("device01","did01","di0001");
2.3 设备状态变更日志
在设备状态变更日志时超级表命名为 device_state_change_log,代码如下所示:
create table if not exists device_state_change_log (ts timestamp, change_type nchar(10), status_before nchar(10),status_after nchar(10)) tags ( device_model_mark nchar(25) ,device_mark nchar(25));
如果是单个设备一张子表的模式,子表命名规则为 dsl_模型标志_设备标志,例如:al_model01_device01。
create table if not exists %s using device_state_change_log tags ( "devicemodleMark001","device01");
2.4 设备信息变更日志
在设备信息变更日志时超级表命名为 device_info_change_log,代码如下所示:
create table if not exists device_info_change_log (ts timestamp, opera_user nchar(50), change_type nchar(10),change_info nchar(50), info_before nchar(200),info_after nchar(200)) tags ( device_model_mark nchar(25) ,device_mark nchar(25));
单个设备一张子表情况下,子表命名规则为 dil_模型标志_设备标志,例如:al_model01_device01。
create table if not exists %s using device_info_change_log tags ( "devicemodleMark001","device01" )
2.5 问题及解决
我们刚开始使用的是 TDengine 2.0.13.0 的版本,在建表以及使用过程中遇到了一些问题,主要包括以下 3 点:
- TDengine 数据列需要提前创建
- TDengine 数据列长度不可修改
- 在新建设备操作日志表时,提示 DB error: invalid SQL: row length exceeds max length (0.000505s)
在我们跟涛思数据的技术专家进行相关沟通后,他们建议将 TDengine 升级到 2.2.2.0 的最新稳定版本,该版本支持数据列的动态新增、修改。在沟通中还发现,上面问题中“建表报错”一项是因为单条记录数据超长了,按理说总长度不能超过 16KB,后面我们对字段长度进行了调整,问题随即迎刃而解。
三、具体的效果展示
接下来为大家展示一下 TDengine 在压缩率(存储)、写入、查询等性能上的各种数据。
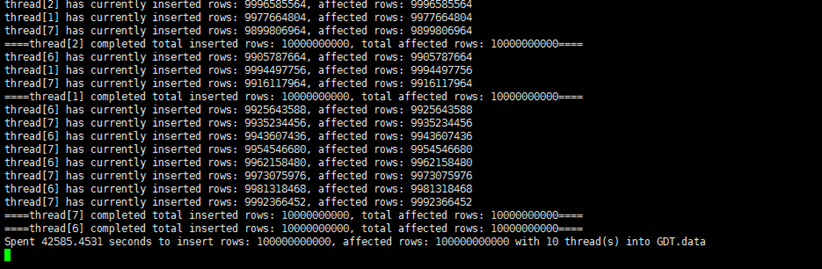
3.1 单机写入性能
1)模拟 10 个厂区的数据、每个厂区 10000 个监测点,每个监测点从 2020-01-01 00:00:00.000 开始写入模拟数据,记录时间戳间隔 5 秒,每个测点写入 100 万条记录
2)写入的数据应当保持一致,生成方式为:将 10000 条真实采集的数据复制 100 份,时间戳按照 5 秒间隔自动生成,分别作为不同测点的数据写入数据库
3)记录以下内容,并观察写入过程中客户端线程数、CPU、内存资源使用率:
- 确认 1000 亿条记录全部正确写入数据库
- 平均每秒写入点数
- 所有写入请求完成的总时延
最终显示的结果为——条数/秒:2348220 总时延(秒):42585.4531
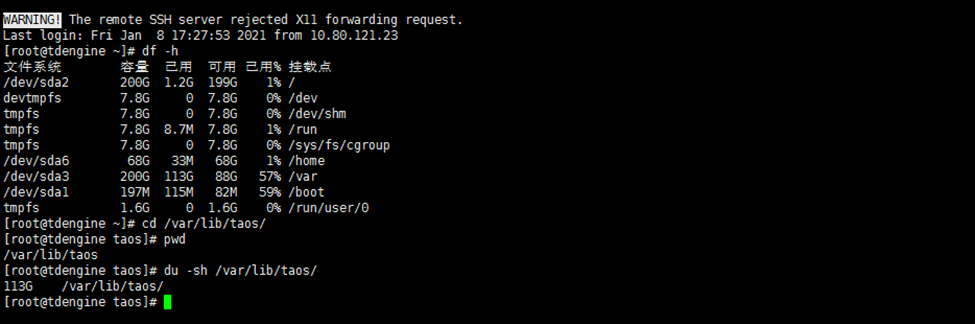
3.2 时序数据库压缩比
1)确认 1000 亿条记录原始数据文件大小,不计算标签为 1117.59GB,算上标签为 67.666TB;
2)落盘后数据文件大小(自带缓存的时序库需重启服务保证数据文件落盘);
3)计算压缩比=落盘后数据文件大小/原始数据文件大小;
落盘后所有文件大小为 113GB,压缩比为 10.11%
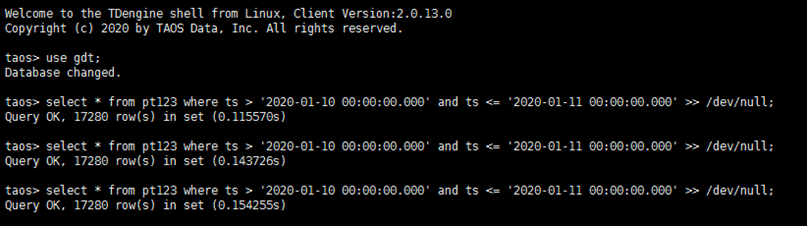
3.3 时序数据库单测点原始历史数据投影查询性能
1)随机选择任一个测点,查询该测点在某个时间段内的历史数据,比如从 2020-01-10 00:00:00.000 到 2020-01-11 00:00:00.000 一天内的共 17280 条数据记录(数据输出到文件)。
数据库中对应查询语句为:
select * from pt123 where ts >= '2020-01-10 00:00:00.000' and ts <= '2020-01-11 00:00:00.000' >> /dev/null
2)记录以下内容:
- 确认查询结果、记录条数正确
- 查询总耗时
3)重复执行上述查询 3 次,记录平均耗时
具体结果为——3 次平均时延(秒):0.13785
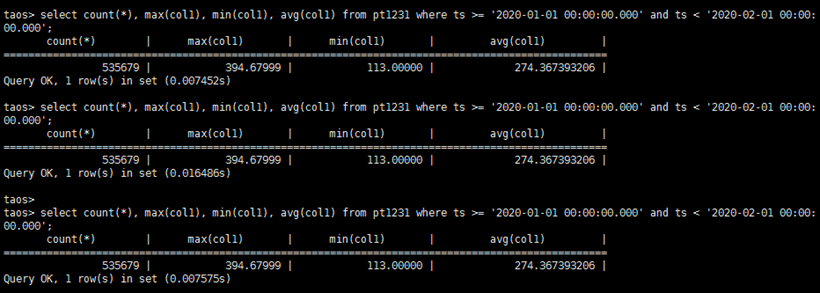
3.4 时序数据库单测点原始历史数据聚合查询性能
1)随机选择任一个测点,查询该测点在某个时间段测点采集值的 count、max、min、avg,比如从 2020-01-01 00:00:00.000 到 2020-02-01 00:00:00.000 31 天内的共 535680 条数据记录的 count、max、min、avg。数据库中对应查询语句为:
select count(*), max(col1), min(col1), avg(col1) from pt1231 where ts >= '2020-01-10 00:00:00.000' and ts < '2020-01-11 00:00:00.000'
2)记录以下内容:
- 确认查询结果正确
- 查询总耗时
3)重复执行上述查询 3 次,记录平均耗时
具体结果为——3 次平均时延(秒):0.010504
目前我们已经将 TDengine 应用在数据采集、数据处理、数据边缘计算、数据存储等诸多方面,在实际业务中也展现出了如上所示的超强性能,特别是在处理超高频的数据采集、边缘智能计算框架、数据流引擎和数据模型等方面效果显著,面对海量数据轻松实现实时全生命周期管理。
四、写在最后
在本次项目中,TDengine 展现出了强大的读写性能和数据压缩能力,聚合类查询速度非常快,也帮助我们有效降低了机器使用成本。超级表、子表、标签等概念非常适配物联网大数据应用场景,潜力无限。
未来希望 TDengine 发展能够越来越好,期待周边生态工具更加完善。
⬇️点击下方图片查看活动详情,把iPhone 13 Pro带回家!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号