运维监控场景下,如何从 OpenTSDB 迁移到 TDengine
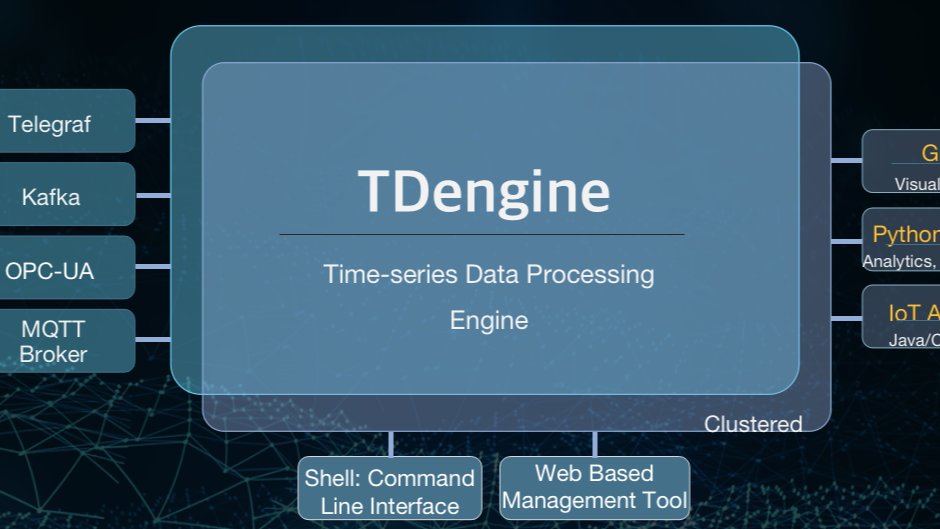 如何将基于 OpenTSDB 的应用快速、安全、可靠地迁移到 TDengine 之上。
如何将基于 OpenTSDB 的应用快速、安全、可靠地迁移到 TDengine 之上。

OpenTSDB是一个经典的时序数据库系统,它没有开发自己的存储引擎,而是基于HBase,对于已经有HBase基础服务的企业而言,降低了门槛。而且得益于其先发优势,OpenTSDB在运维监控领域有不少应用。不过也因为要依赖HBase,系统的性能、压缩效率逐渐成为瓶颈。随着业务系统规模的扩大,部署成本、运行效率等方面的问题日益严重。此外,OpenTSDB的功能升级也比较缓慢。 与之相比,TDengine有着明显的优势:
- 数据写入和查询的性能远超OpenTSDB;
- 针对时序数据的高效压缩机制,压缩后在磁盘上的存储空间不到OpenTSDB的1/5;
- 安装部署非常简单,单一安装包完成安装部署,除了taosAdapter需要依赖Go运行环境外,不依赖其他第三方软件,整个安装部署非常迅速;
- 提供的内建函数覆盖OpenTSDB支持的全部查询函数,还支持更多的时序数据查询函数、标量函数及聚合函数,支持多种时间窗口聚合、连接查询、表达式运算、多种分组聚合、用户定义排序、以及用户定义函数等高级查询功能。采用类SQL的语法规则,更加简单易学,基本上没有学习成本。
- 支持多达128个标签,标签总长度可达到16KB;
- 除HTTP之外,还提供Java、Python、C、Rust、Go等多种语言的接口。
如果我们将原本运行在OpenTSDB上的应用迁移到TDengine上,不仅可以有效降低计算和存储资源的占用、减少部署服务器的规模,还能够极大减少运行维护成本,让运维管理工作更简单、更轻松,大幅降低总拥有成本。
本文将以“使用最典型并广泛应用的运维监控场景”来说明,不用编写一行代码,如何将基于OpenTSDB的应用快速、安全、可靠地迁移到TDengine之上。
1、典型运维监控应用场景
一个典型的运维监控应用场景的系统整体的架构如下图(图1)所示。
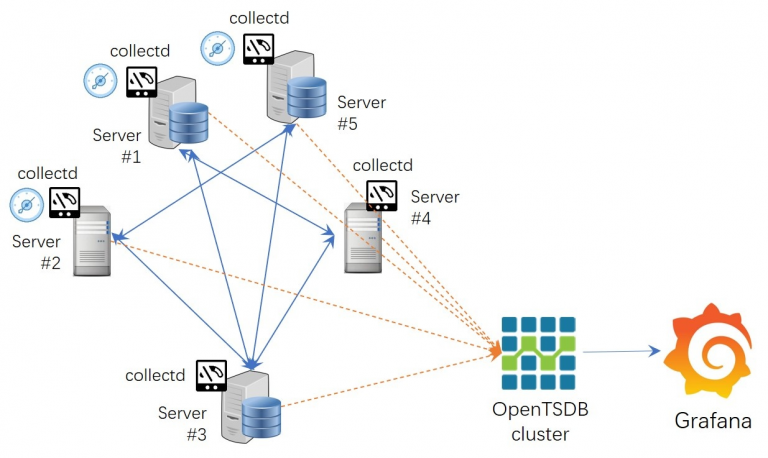
图1.运维监控场景典型架构
在该应用场景中,包含了部署在应用环境中负责收集机器度量(Metrics)、网络度量(Metrics)以及应用度量(Metrics)的Agent工具,汇聚Agent所收集信息的数据收集器,负责数据持久化存储和管理的系统以及监控数据可视化工具(例如:Grafana等)。
其中,部署在应用节点的Agent负责向collectd/Statsd提供不同来源的运行指标,collectd/StatsD则负责将汇聚的数据推送到OpenTSDB集群系统,然后使用Grafana将数据以可视化的方式呈现出来。
2、迁移服务
- TDengine安装部署
首先是TDengine的安装,从官网上下载TDengine最新稳定版,解压缩后运行install.sh进行安装。各种安装包的使用帮助可参考《TDengine多种安装包的安装和卸载》。注意,安装完成以后,不要立即启动taosd服务,在正确配置完成参数以后再启动。
- 调整数据收集器配置
在TDengine 2.3版本中,在后台服务taosd启动后,一个叫taosAdapter的HTTP的服务也会自动启用。利用taosAdapter,能够兼容Influxdb的Line Protocol和OpenTSDB的telnet/Json写入协议,所以我们可以将collectd和StatsD收集的数据直接推送到TDengine。
如果使用collectd,修改其默认位置在/etc/collectd/collectd.conf的配置文件,使其指向taosAdapter部署的节点IP地址和端口。假设taosAdapter的IP地址为192.168.1.130,端口为6046,配置如下:
LoadPlugin write_tsdb
<Plugin write_tsdb>
<Node>
Host "192.168.1.130"
Port "6046"
HostTags "status=production"
StoreRates false
AlwaysAppendDS false
</Node>
</Plugin>
这样collectd就可以通过taosAdapter将数据写入TDengine了。如果使用的是StatsD,可以相应地调整配置文件。
- 调整看板(Dashborad)系统
在数据能够正常写入TDengine后,可以调整适配Grafana,将写入TDengine的数据可视化呈现出来。在TDengine的安装目录下有为Grafana提供的连接插件(connector/grafanaplugin)。使用很简单:
首先将grafanaplugin目录下的dist目录整体拷贝到Grafana的插件目录(默认地址为/var/lib/grafana/plugins/),然后重启Grafana,即可在Add Data Source菜单下看见TDengine数据源。
此外,TDengine还提供了两套默认的Dashboard模板,供用户快速查看保存到TDengine库里的信息。只需要其导入到Grafana中并激活。
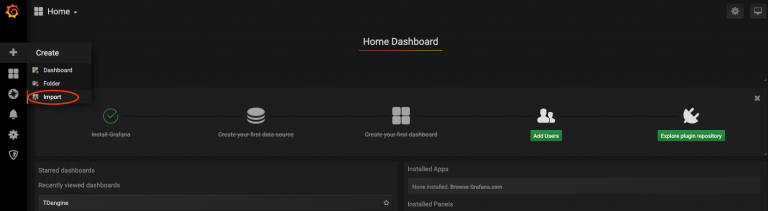
图2.导入Grafana模板
至此,我们就完成了将OpenTSDB替换成为TDengine的迁移工作。可以看到整个流程非常简单,不需要写代码,只需要调整某个配置文件。
3、迁移后架构
完成迁移以后,此时的系统整体的架构如下图(图3)所示,而整个过程中采集端、数据写入端、以及监控呈现端均保持了稳定,除了极少的配置调整外,不涉及任何重要的更改和变动。
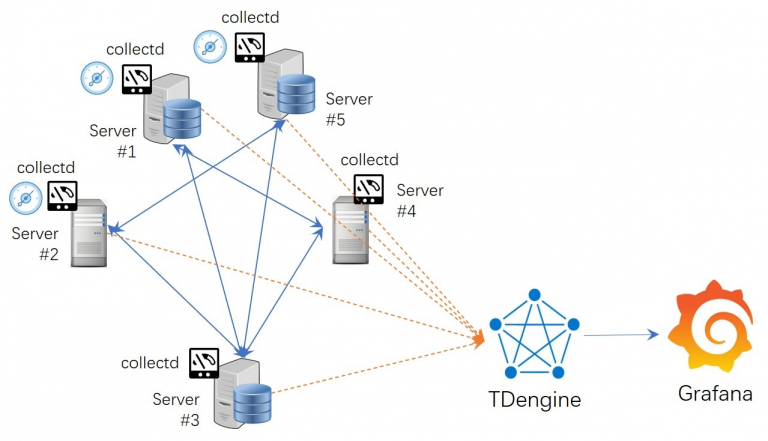
图3.迁移完成后的系统架构
OpenTSDB的主要应用场景就是运维监控,这种情况下我们可以轻松完成向TDengine的迁移,从而用上TDengine更加强大的处理能力和查询性能。
在绝大多数运维监控场景中,如果拥有一个小规模的OpenTSDB集群(3台及以下的节点)作为监控数据的存储端,依赖OpenTSDB所提供的数据存储和查询功能,那么可以安全地将其替换为TDengine,并节约更多的计算和存储资源。在同等计算资源配置情况下,单台TDengine即可实现3~5台OpenTSDB节点提供的服务能力。如果规模比较大,那便需要采用TDengine集群。
如果应用特别复杂,或者应用领域并不是运维监控场景,你可以继续阅读下一篇文章,更加全面深入地了解将OpenTSDB应用迁移到TDengine的高级话题。
🌟点击探索taosAdapter!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号