代替 TimescaleDB,TDengine 接管数据量日增 40 亿条的光伏日电系统
小 T 导读:八五信息新能源电力物联网平台采用TDengine,存储和查询分析物联网设备的实时数据,以及光伏设备传感器的遥测数据。需支撑至少50000台设备总计400万测点的实时数据接入、处理及存储,预计日增量40多亿条。之前使用TimescaleDB,无论在读写性能,还是硬件资源上,都遇到了瓶颈,且没有集群功能。随后切换到了TDengine,读写性能提高了10倍,存储成本降低到原来1/5左右。
使用场景简介
当前业务场景
我们首先在新能源电力物联网平台上使用了TDengine,主要用于光伏设备遥测实时数据的存储、查询和分析。
新能源物联网生产运营平台通过物联网及大数据技术将现有电站数据进行整合,实现园区设备的统一运行监视,数据集中管理。给不同人员等提供全面、便捷、差异化的数据和服务。
对运维人员提供设备的状态信息、报警信息、远程故障诊断信息、实时数据等数据应用服务;对管理人员和运营人员提供各类检测数据的汇总、变化趋势等应用服务。该平台系统整体的架构如下:
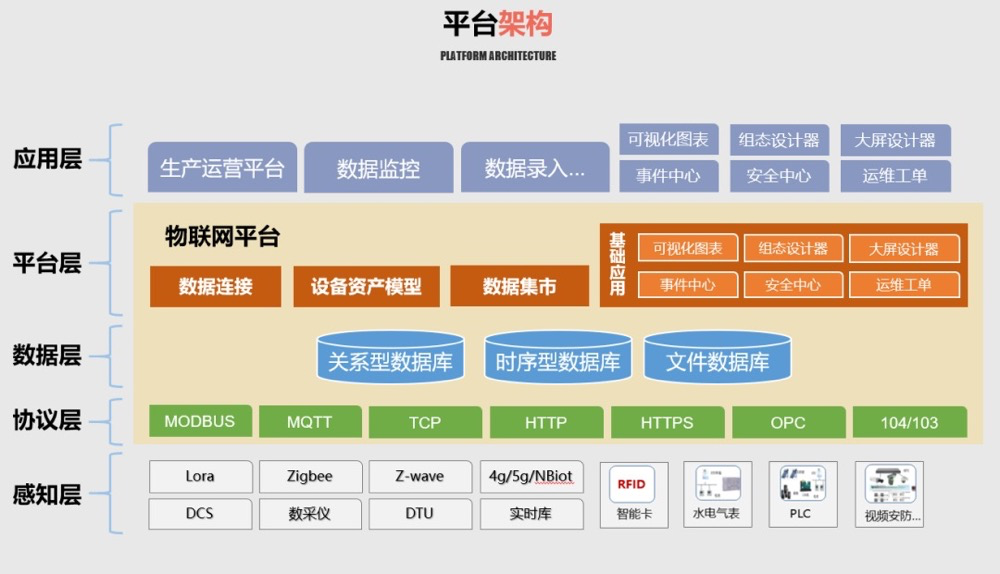
系统的总体架构按照分层实现的设计理念,在底层设计上实现各个软件系统的职能分离,确保各部分高效运转。
数据规模,查询压力等要求
规划设计数据存储规模大概在16T左右,目前数据日增量为1亿多条,全部测点接入后预计日增量为40多亿条左右;系统需支撑至少50000台设备总计400万测点(信号量和模拟量)的实时数据接入、处理及存储。
应用系统的常规查询在50QPS左右,高并发在100QPS左右。一次历史数据查询分析最大跨度为一年且支撑多测点多模式分析方式。时序数据分析界面如下:
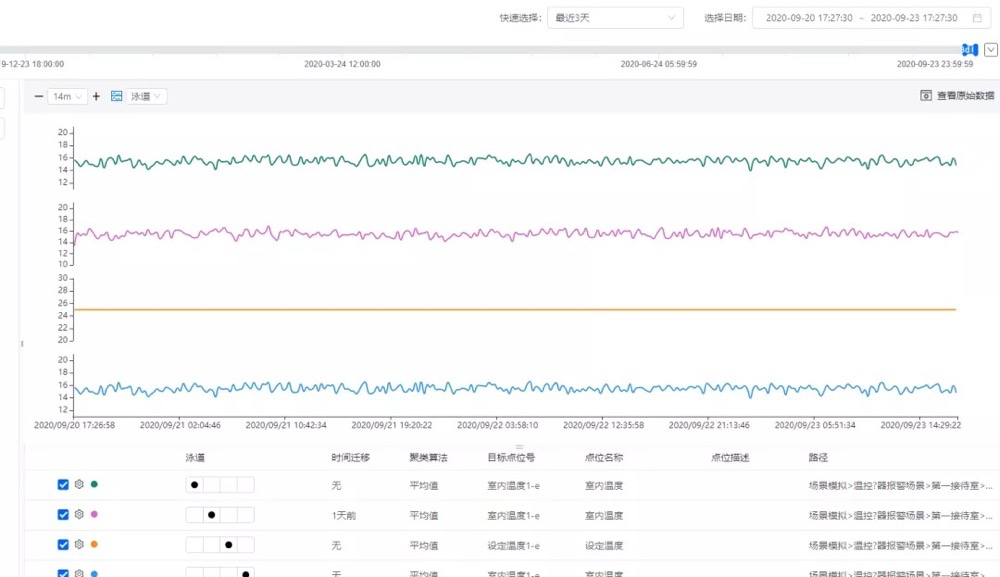
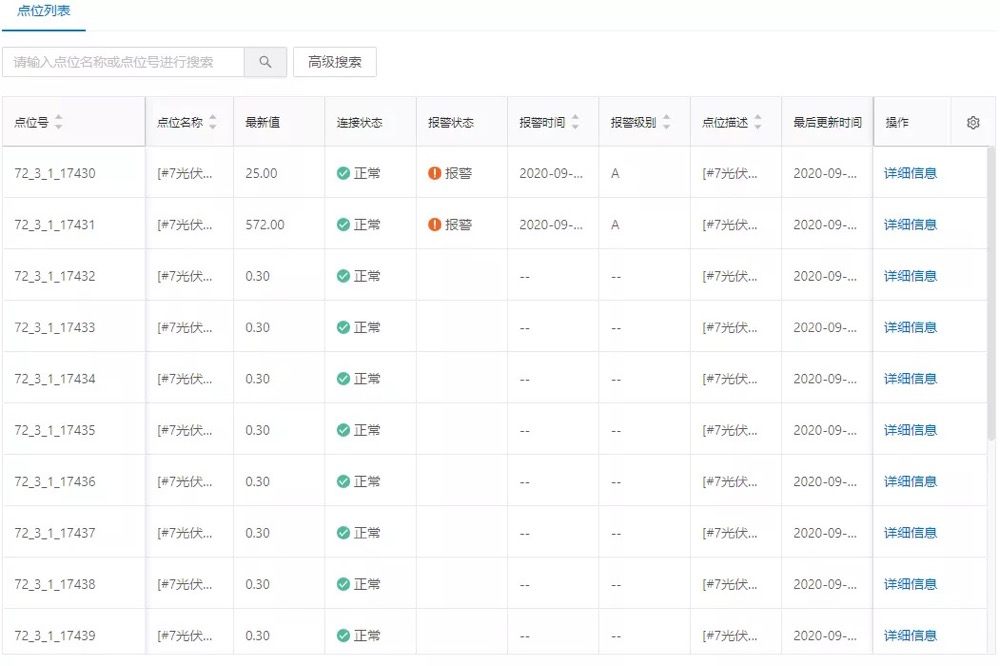
工况实时展示界面:

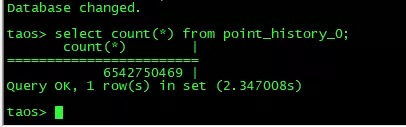
目前总数据量以及日增量:

目前创建的超级表以及子表数:
数据模型简介
目前根据不同的测点类型建立了不同的超级表。按照不同的测点ID以及测点号作为tag创建了不同的子表。这样我们针对于测点可以直接进行单表分析,处理性能高、速度快。也可以针对多测点进行分析,直接操作超级表,业务实现简单,同时兼顾了查询性能。
查询需求
· 简单查询
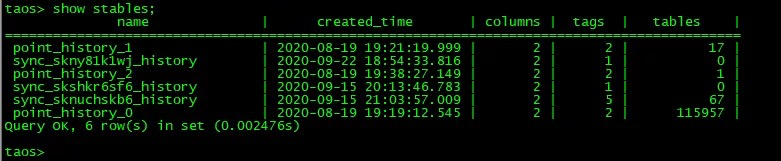
针对于单测点的历史数据查询分析以及时间间隔聚合分析。主要是对单测点的异常数据的排查和告警数据的排查确认。TDengine是把同类设备数据归入一个超级表,但每个设备都会根据超级表的结构建立自己的一张子表,查询单测点数据实际上只查询一个子表,遍历的数据量大大减少,查询分析基本毫秒级响应。简单查询SQL图例:
· 聚合查询
多测点相同时间维度不同聚合类型的时间迁移对比分析。侧重于对比,方便用户更加有效的确认不同测点下的异常和差异情况。

· 大批量测点分组聚合查询
数百测点的分组分时段聚合查询;在一定时间段内,大批量测点的查询仍然可以迅速响应。
查询压力
峰值并发为100qps,平均并发量为20qps,实际场景中并发查询压力较小,未达到TDengine的查询瓶颈。
采用TDengine带来的收益
系统功能
读写性能较原TimescaleDB数据库提高10倍左右,在数据接入层不用再担心数据库的写入性能瓶颈;数据分析查询应用层也较原系统有较大提升,尤其是在时间跨度大的聚合类分析几乎瞬间响应。
通过乱序插入功能,解决了边缘侧由于网络问题导致的数据传输不及时造成的乱序写入问题,保证了数据的完整性。
集群功能对比TimescaleDB优势较大,TimescaleDB没有集群功能但支持流复制方式的主备库;TDengine集群容易搭建且无主从节点区分,对应用改造和支撑较友好,集群版读写性能提升较大。
数据存储增加集群多副本功能,通过数据冗余提升了系统的安全和可靠性,降低了系统的运维成本。
软硬件资源
节省了系统大量的计算资源以及存储资源,降低了大约4倍左右的存储成本。
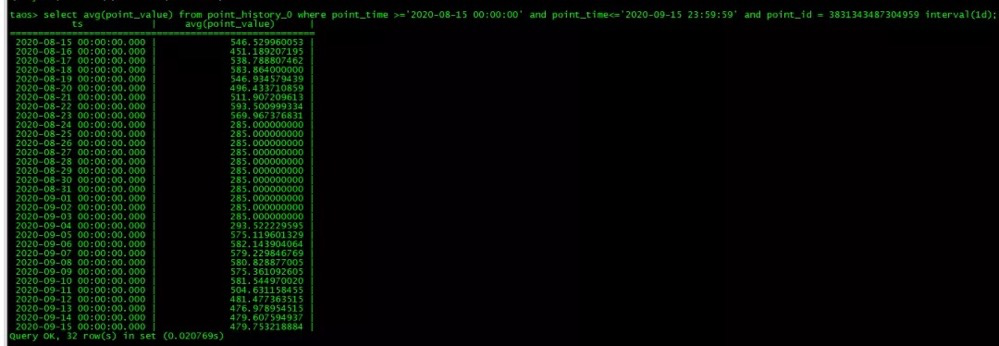
对比未使用TDengine之前TimescaleDB时序库开启压缩后对70亿数据占用磁盘为165G,且一分钟内无法查询出一个月的历史数据;而在使用TDengine之后磁盘占用空间为40G左右,毫秒级返回针对一个月的历史数据的聚合查询。相关查询如下:
应用TDengine遇到的问题与解决思路
原有时序库大数据量批量导入TDengine,在1.6版本进行批量导入非常麻烦,一次批量插入只有200条左右,后期在升级到了2.0版本以上后一次可以插入1M数据,大大提升了不同数据库不同表结构之间的批量导入性能。
未来使用TDengine的考虑
经过一段时间的线上运行,TDengine有优异的性能表现,我们决定将在后续时间将我们所有的物联网项目逐步都更新为TDengine。
TDengine功能方面的期望与建议
分析型函数增强,希望增加时序库中实用的常用分析函数;
增强连续聚合查询功能,目前连续聚合功能实用性不强;
产品生态,与Spark、Flink等开源分析工具的集成。
作者: 八五信息开发工程师李良政

 浙公网安备 33010602011771号
浙公网安备 33010602011771号