
TDengine 助力国产芯片打造“梦芯解算”,监测地质灾害 24 小时无间断
小 T 导读:TDengine 承担着梦芯形变安全监测解算系统核心数据库的角色,帮助梦芯刻印机解决了高效率记录站点的原始数据、解算后的形变数据等海量数据的存取及使用上的巨大难题。本文分享了基于本项目进行数据库选型、搭建和实际效果的具体经验。
公司简介
武汉梦芯科技是一家专业从事高集成度芯片设计和高性能室内外定位研究的高新技术企业,致力于为各类智能终端产品提供北斗定位核心技术和元器件,为北斗在高精度应用领域的推广提供差异化的完整解决方案。梦芯科技自主研发的启梦芯片系列产品入选中国卫星导航专项北斗基础产品推荐名录,在国家北斗办组织的权威比测中名列前茅,以第一梯队的成绩获得国家北斗办资金支持,并多次获得卫星导航定位科技进步奖一等奖、卫星导航定位创新应用奖“金奖”等荣誉。
项目介绍
地质灾害隐患点多分布在交通、通讯、电力保障等都极为不方便的地区,一旦发生大都会造成严重损害,其原因往往是因为难以事先准确预报灾害发生的地点、时间和强度。对地质灾害隐患,特别是滑坡、泥石流等危害极大的地质灾害进行低成本、便捷、长期、自动化的监测,并及时将灾害发生的实时状况反映到相关管理部门,是保障人民生命安全、减少人民财产损失的必要手段。
基于上述背景,梦芯形变安全监测解算系统应运而生。其采用梦芯高精度定位方案,能够为应用目标提供 24h 不间断监测,实时掌握隐患点的位移变化情况,具有较高的监测精度。系统支持 BDS、GPS、GLONASS、Galileo 等卫星定位系统数据观测,支持无线网络,可实现数据的远程传输,提供日、周、月、年的数据统计结果。基准站和监测站均可采用梦芯高精度 GNSS 监测专用接收机,最大程度上降低成本。
在此项目中,TDengine 承担着核心数据库的角色,它帮助我们解决了高效率记录站点的原始数据、解算后的形变数据等海量数据的存取及使用上的巨大难题。
一、基于业务场景进行数据库选型
形变安全监测解算系统由数据分析管理和数据显示预警两部分组成。数据分析管理系统包括站点管理、信息管理、统计分析、隐患点管理、系统管理等,数据显示预警系统包括实时监控、图像监测、预警管理等。
数据分析管理服务负责对接收到的 GNSS 数据进行解码和解算,获取监测点的实时位置坐标,并对数据处理结果进行管理和数据共享、用户管理、定期自动备份等,以实现监测区域全天候在无人值守的情况下也能确保系统长期处于工作状态,满足实时监控需求,节约人力资源成本。
数据显示预警系统负责对解算出的监测点位置坐标进行集中和图形化显示,根据解算结果自动生成形变历史曲线、卫星分布图、载噪比柱状图,实时展现各监测点的实时状态,并根据预设的警戒值进行风险判别,以声光、短消息等形式进行多渠道预警信息发布,及时将灾害发生的实时状况反映到相关管理部门。
平台业务部分截图如下:
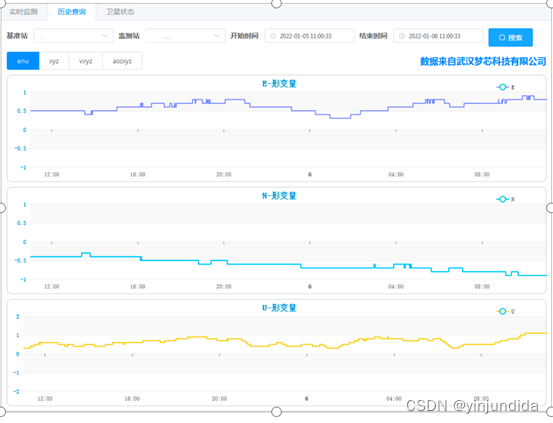
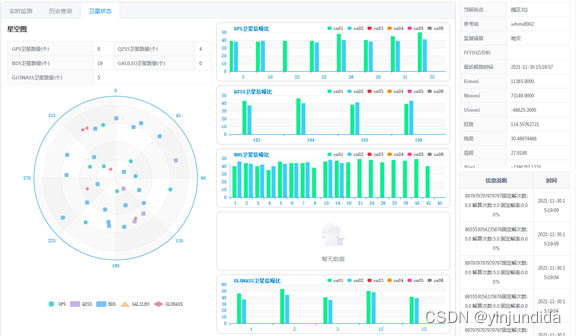 图:卫星数据
图:卫星数据
对数据进行分析后可知,系统的工作场景基于大并发、高频、大数据量,主要包含以下几类:
- 一体化智能监测站上传监测数据频率最高 1 赫兹
- 解算后的实时形变数据频率最高 1 赫兹
- 依据以上数据产生的更大量级衍生数据
形变安全监测解算系统需要针对监测目标进行实时监测,如何高效率地记录站点的原始数据、解算后的形变数据,是保障整个平台运行效率和稳定监测至关重要的一环。由于该项目设备量大、数据量大、频率高,单是进行存储已经不易,如果还要对数据进行查询下载等操作,无疑是难上加难。这些问题横亘眼前,也让我们在数据库选择上尤为慎重。
在此之前,我们的业务架构如下图所示,实际运行过程中遇到了很多痛点。比如说,当时数据保存在 MySQL 中且采用了分库分表的形式,当需要查询较大跨度时间内的数据时,由于数据量大,系统的性能会显著下降,前端查询展示一天的形变数据就需要数分钟,这显然是不能接受的。
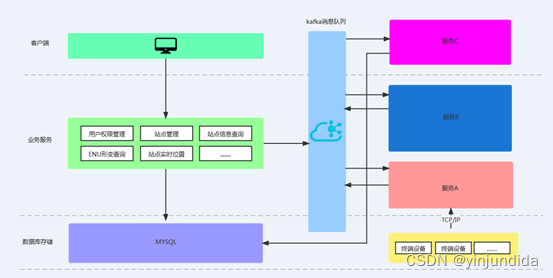
后来,我们对需要存储的业务场景进行了梳理,如下图所示:
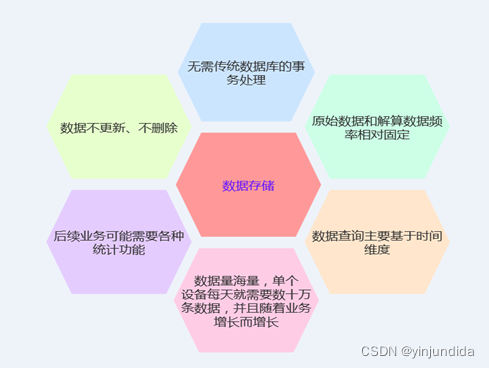
基于缜密考虑,我们把目光锁定在时序数据库上,在技术调研阶段,对比了 InfluxDB、DolphinDB、TDengine 在内的三款常用的主流数据库。综合对比后结果如下:
- 由于目前 InfluxDB 集群版已经闭源商业化,开源版仅支持单机模式。单机版性能逊于集群版,同时没有集群的冗余,当服务器不可用时写入和查询会立即失败,相比新兴的时序数据库其性能要差一些。
- 目前 DolphinDB 主要应用在金融领域,且是闭源。
- TDengine 性能强悍,且为国产自主研发、集群功能开源,具有典型的分布式数据库特征,压缩比例也非常高。
通过严谨的对比和技术调研,TDengine 不仅满足我司支持国产数据库的初衷,而且其很多优秀特性也能够满足我们的业务场景。
二、落地经验
目前我们整个系统采用了数台高性能的云服务器,暂时采用的是单节点部署,后续会增加多节点。从 2021 年 10 月运行至今,共创建了 2 张超级表以及近百张子表,总数据量超过 2.5 亿条,压缩后的数据量大小为 200G 左右。

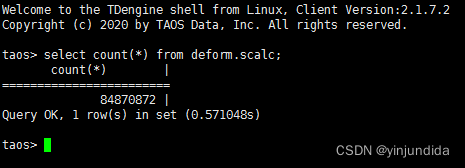
下面以地灾监测站 1 赫兹上报的原始数据为例说明下存储情况。sraw 是我们的超级表,其中存储了 1.6 亿条数据,分散在 109 张子表中,由于 TDengine 的标签是内存存储,再加上列式存储便于压缩的加持,帮助我们节省了大量的存储空间(仅占用 100G 左右的空间),也为数据查询性能打下了良好的基础。

由于是初次使用开源版,中间也遇到了很多问题,好在 TDengine 官方技术群里有专人做技术支持,进行一对一的免费指导,让我们切身体验到了开源数据库的友好和国产数据库的价值。
 深入研究下咨询 TDengine 使用细节,有问必答
深入研究下咨询 TDengine 使用细节,有问必答
三、性能表现
在查询方面,我们主要的查询逻辑是按时间查询所有的原始数据和解算数据。TDengine 以其优异的性能完成了上述查询分析过程。
具体操作如下:
1. 超级表统计功能测试:
-
select avg(sat_num), max(e), min(n) from deform.scalc;
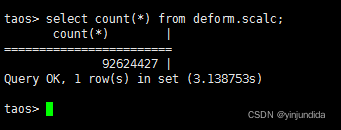

对这张近亿行的超级表进行统计操作,仅用了 1.9 秒左右就返回了结果,充分证明了在实际应用中 TDengine 也确实表现卓越。
2. 子表按时段查询功能:
-
select * from deform.dm860936050878150 where ts > '2021-10-02 16:11:20.933' and ts < '2021-12-02 16:11:20.933' >> test.txt;

返回 187,681 行数据并写入 test.txt 文件,共 300MB 数据用时 8.1 秒,性能超出我们的预期。
四、写在最后
由于目前仅仅是初期的项目需求,我们没有采用多节点部署,但随着业务的增长,多节点部署也迫在眉睫。而且后续会需要更大量的数据来做更复杂的分析,届时我们将会更为深入地应用到 TDengine 的其他核心特性,如数据订阅、多表聚合查询、众多计算函数等等。但仅就当下而言,TDengine 强大的存储和快速查询能力也已经非常令我们惊喜,让我们对未来更加深入的合作充满期待。最后,感谢涛思数据,希望贵公司能够继续完善产品、完善生态、拥抱开源,向下一个顶峰攀登。
作者简介
马威,武汉科技大学计算机专业,从事软件开发 9 年的工作经验,供职于武汉梦芯科技有限公司软件部高级工程师。在车载物联网平台、形变安全监测解算系统、AGNSS 加速定位服务、DGNSS 精确定位服务等多方面有着长期技术积累和大量成功经验。
想了解更多TDengine 的具体细节,欢迎大家在GitHub上查看相关源代码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号