Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0


查看java版本,需要1.8版本 java -version yum -y install java 创建用户,因为elasticsearch不能root操作 useradd panfeng 设置密码 passwd panfeng 输入123456,上面说无效小于8字符,又让输入一次,再输入123456 切换用户,带有-参数是把当前环境也切换过去 su - panfeng 这时候用ftp把elasticsearch-6.3.0.tar.gz放到/home/panfeng 退出用户 exit 进入目录 cd /home/panfeng 查看详情 ll 总用量 89284 -rw-r--r--. 1 root root 91423553 7月 4 22:33 elasticsearch-6.3.0.tar.gz 把权限乐优 chown panfeng:panfeng elasticsearch-6.3.0.tar.gz 再查看详情 ll 总用量 89284 -rw-r--r--. 1 panfeng panfeng 91423553 7月 4 22:33 elasticsearch-6.3.0.tar.gz 修改文件权限 chmod 755 elasticsearch-6.3.0.tar.gz 再次查看详情,这时的elasticsearch-6.3.0.tar.gz就会变为绿色 ll 总用量 89284 -rwxr-xr-x. 1 panfeng panfeng 91423553 7月 4 22:33 elasticsearch-6.3.0.tar.gz 切换用户 su - panfeng 解压文件 tar -zxvf elasticsearch-6.3.0.tar.gz 修改解压后的文件夹名称为elasticsearch mv elasticsearch-6.3.0 elasticsearch 进入目录 cd elasticsearch 查看详:bin执行的脚本,config配置,lib依赖,logs日志,modules模块,plugins插件 ll 进入目录 cd config 查看详情,elasticsearch.yml是elasticsearch的核心配置文件,jvm.options是Java虚拟机参数 ll 编辑Java虚拟机参数 vim jvm.options 把22和23行的1g改为512m 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 编辑elasticsearch核心配置文件elasticsearch.yml vim elasticsearch.yml 把33行 数据目录位置改为 path.data: /home/panfeng/elasticsearch/data 把37行 日志目录位置改为 path.logs: /home/panfeng/elasticsearch/logs 把55行 修改绑定的ip,默认只允许本机访问,修改为0.0.0.0后则可以远程访问,改为 network.host: 0.0.0.0 Elasticsearch的插件要求至少3.5以上版本,这里最好禁用这个插件,修改elasticsearch.yml文件,在最下面添加如下配置:在文件最下面另起一行 添加 bootstrap.system_call_filter: false 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 退出用户 exit 修改文件权限 vim /etc/security/limits.conf 在# End of file上面添加下面四行数据 * soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 修改线程数 vim /etc/security/limits.d/90-nproc.conf * soft nproc 4096 root soft nproc unlimited 如果有和两行代码直接把*对应的改为4096就行了,如果没有就直接添加 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 修改虚拟内存 vim /etc/sysctl.conf 添加vm.max_map_count=655360 如果有就修改 输入 I 插入进行编辑,编辑好之后按 Esc 输入:wq 保存并退出 修改虚拟内存生效 sysctl -p 如果显示 vm.max_map_count = 655360 就修改成功了~ 进入目录 cd /home/panfeng/elasticsearch 创建data目录,logs目录已经存在就不用创建了 mkdir data 进入目录 cd /home/panfeng/elasticsearch/bin/ 运行elasticsearch ./elasticsearch 这时候在Windows浏览器输入 虚拟机ip:9200 来访问是否启动成功
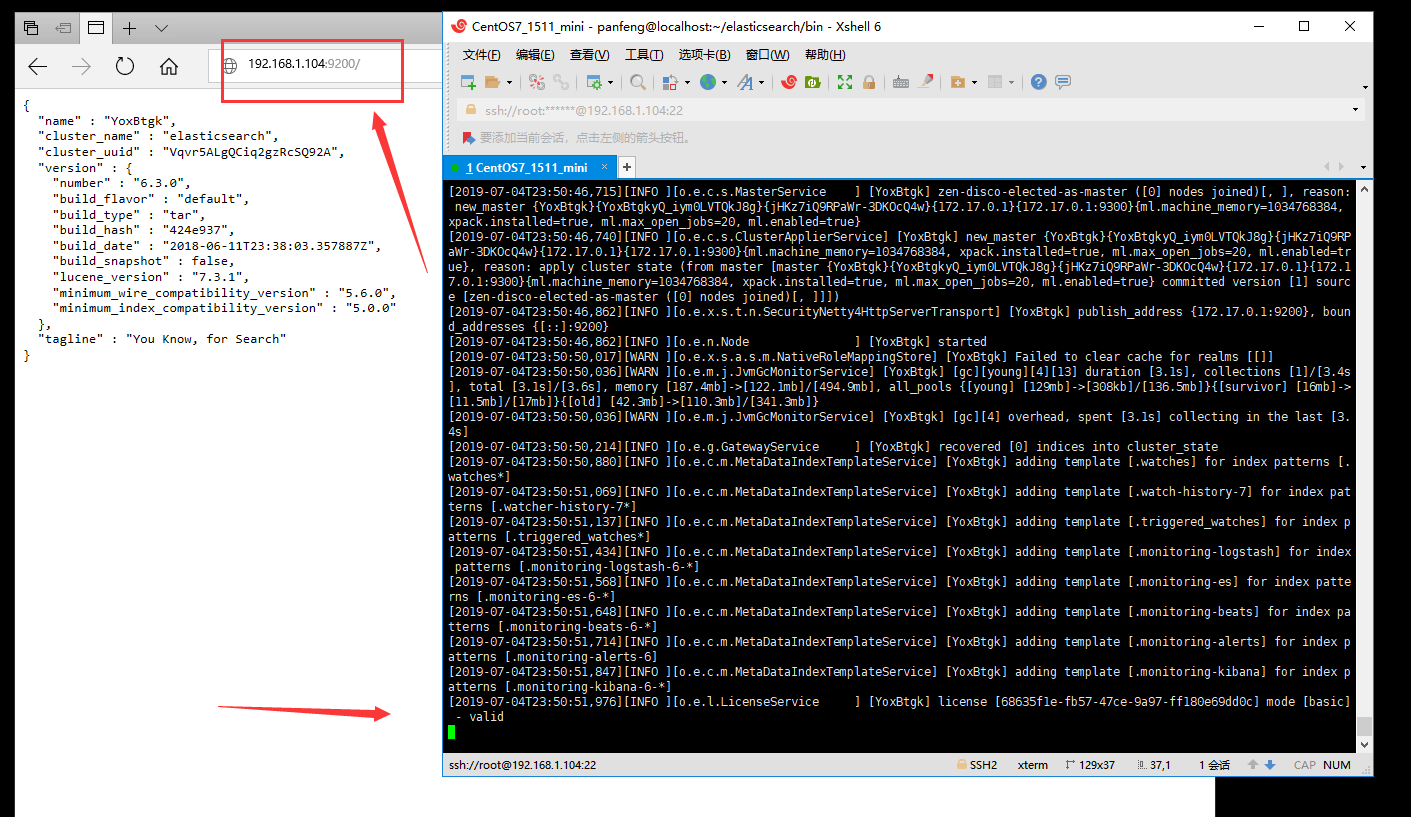
安装ik分词器插件,以及使用Kibana测试Elasticsearch
用ftp上传elasticsearch-analysis-ik-6.3.0.zip到/home/panfeng/elasticsearch/plugins/ 进入目录 cd /home/panfeng/elasticsearch/plugins/ 使用unzip解压ik分词器 unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer 删除elasticsearch-analysis-ik-6.3.0.zip,因为这个是插件目录,这个zip文件会解析错误 rm -f elasticsearch-analysis-ik-6.3.0.zip Windows下解压kibana kibana-6.3.0-windows-x86_64.zip 解压后,进入安装目录下的config目录,修改kibana.yml文件 我的虚拟机地址192.168.1.104,所以第28行修改为 elasticsearch.url: "http://192.168.1.104:9200" 进入安装目录下的bin目录,双击运行kibana.bat,第一次运行慢,等待一会,如果几分钟还是不行的话,就再关闭窗口,再重新双击运行kibana.bat
先用RestClient测试
-
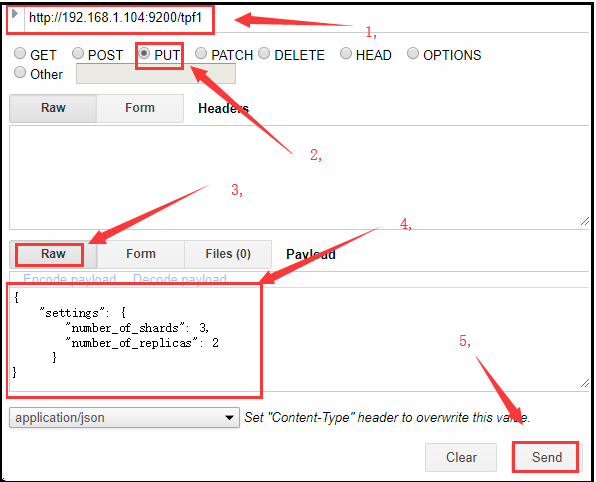
请求方式:PUT 请求路径:/索引库名 请求参数:json格式 { "settings": { "number_of_shards": 3, "number_of_replicas": 2 } } settings:索引库的设置 number_of_shards:分片数量 number_of_replicas:副本数量
- 发送
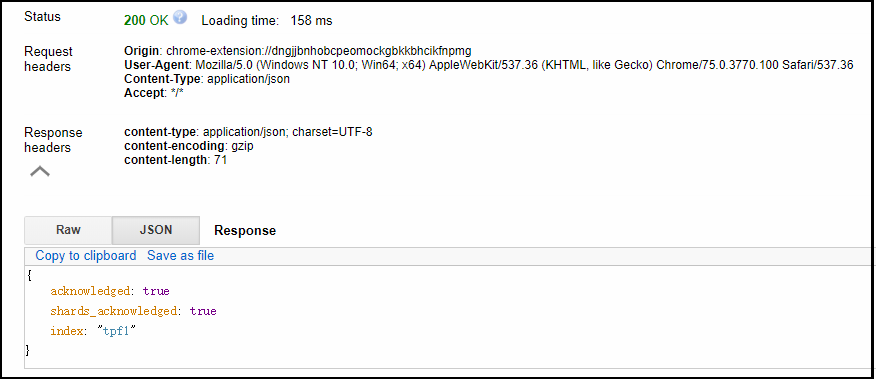
- 响应
Kibana操作Elasticsearch
-
操作索引
-
创建索引

-
查看索引设置
查看指定索引
GET /索引库名
查看所有所有
GET *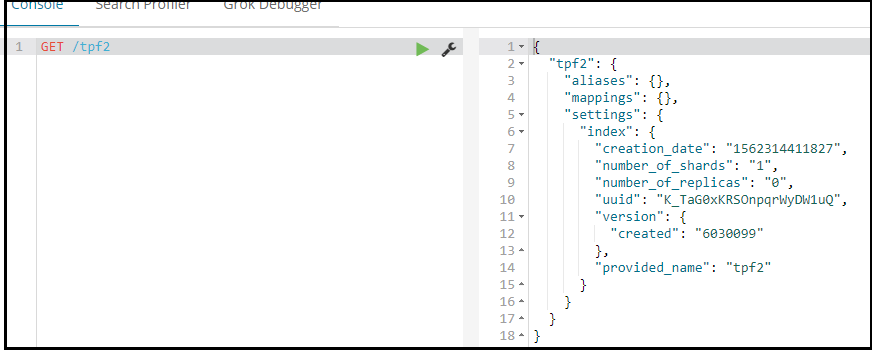
-
删除索引
DELETE /索引库名
-
-
映射配置
-
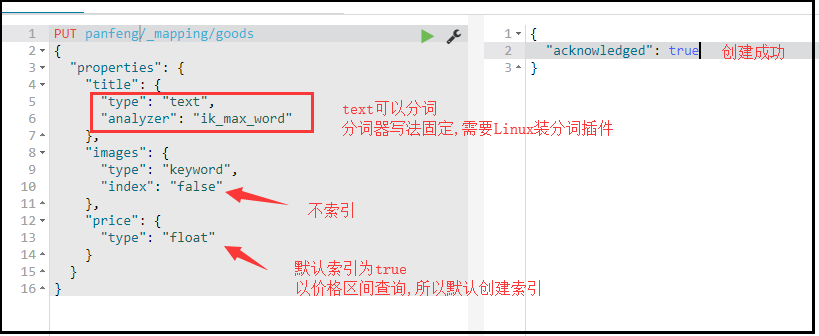
创建映射字段
PUT /索引库名/_mapping/类型名称 { "properties": { "字段名": { "type": "类型", "index": true, "store": true, "analyzer": "分词器" } } } 类型名称:就是前面将的type的概念,类似于数据库中的不同表 字段名:任意填写,可以指定许多属性,例如: type:类型,可以是text,long,short,date,integer,object等,String的text可以分词,String的keyword不可以分词 index:是否索引,默认为true store:是否存储,默认为false,默认保存到_source analyzer:分词器,这里的`ik_max_word`即使用ik分词器,固定写法
-
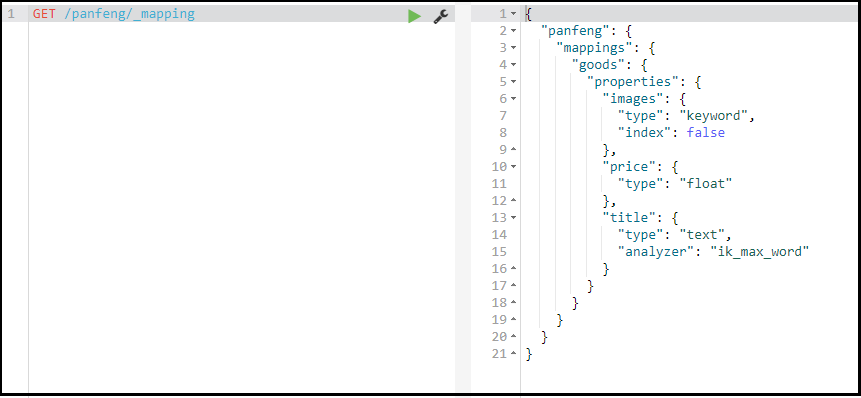
查看映射信息
GET /索引库名/_mapping
-
字段属性详解
- type
- String类型,又分两种: - text:可分词,不可参与聚合 - keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合 - Numerical:数值类型,分两类 - 基本数据类型(一般使用long,interger):long、interger、short、byte、double、float、half_float - 浮点数的高精度类型:scaled_float - 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。 - Date:日期类型 elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
- index
index影响字段的索引情况。 - true:字段会被索引,则可以用来进行搜索。默认值就是true - false:字段不会被索引,不能用来搜索 index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。 但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
- store
是否将数据进行额外存储。 在学习lucene和solr时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。 但是在Elasticsearch中,即便store设置为false,也可以搜索到结果。 原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做`_source`的属性中。而且我们可以通过过滤`_source`来选择哪些要显示,哪些不显示。 而如果设置store为true,就会在`_source`以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,**store的默认值就是false。**
- type
-
-
新增数据
-
随机生成id
POST /索引库名/类型名 { "key":"value" }
_source:源文档信息,所有的数据都在里面。
_id:这条文档的唯一标示,与文档自己的id字段没有关联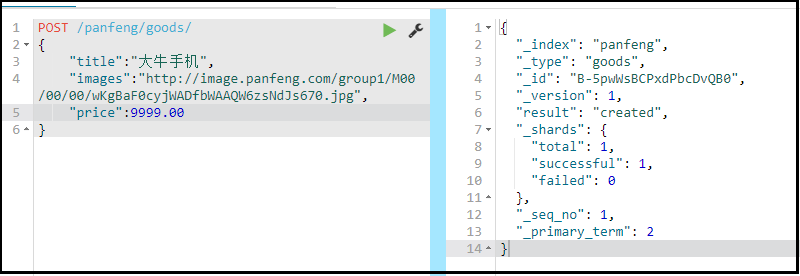
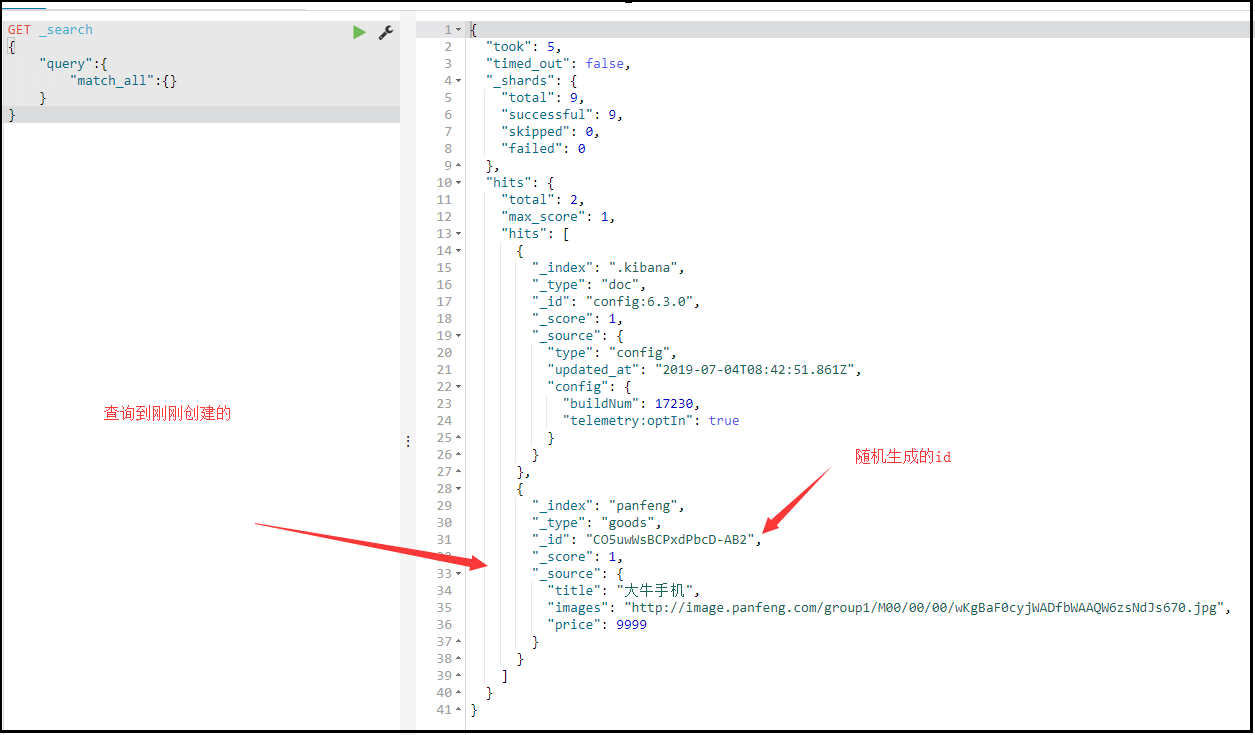
-
自定义id
POST /索引库名/类型/id值 { ... }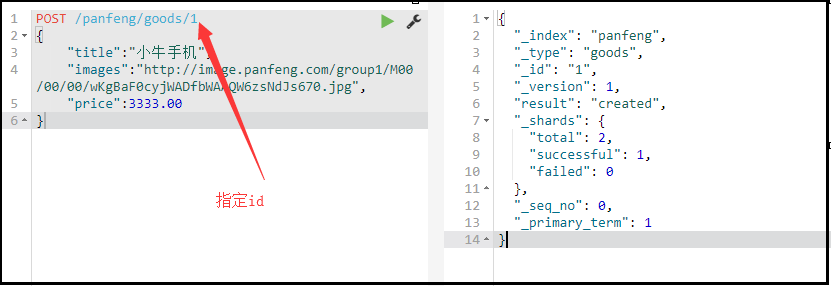
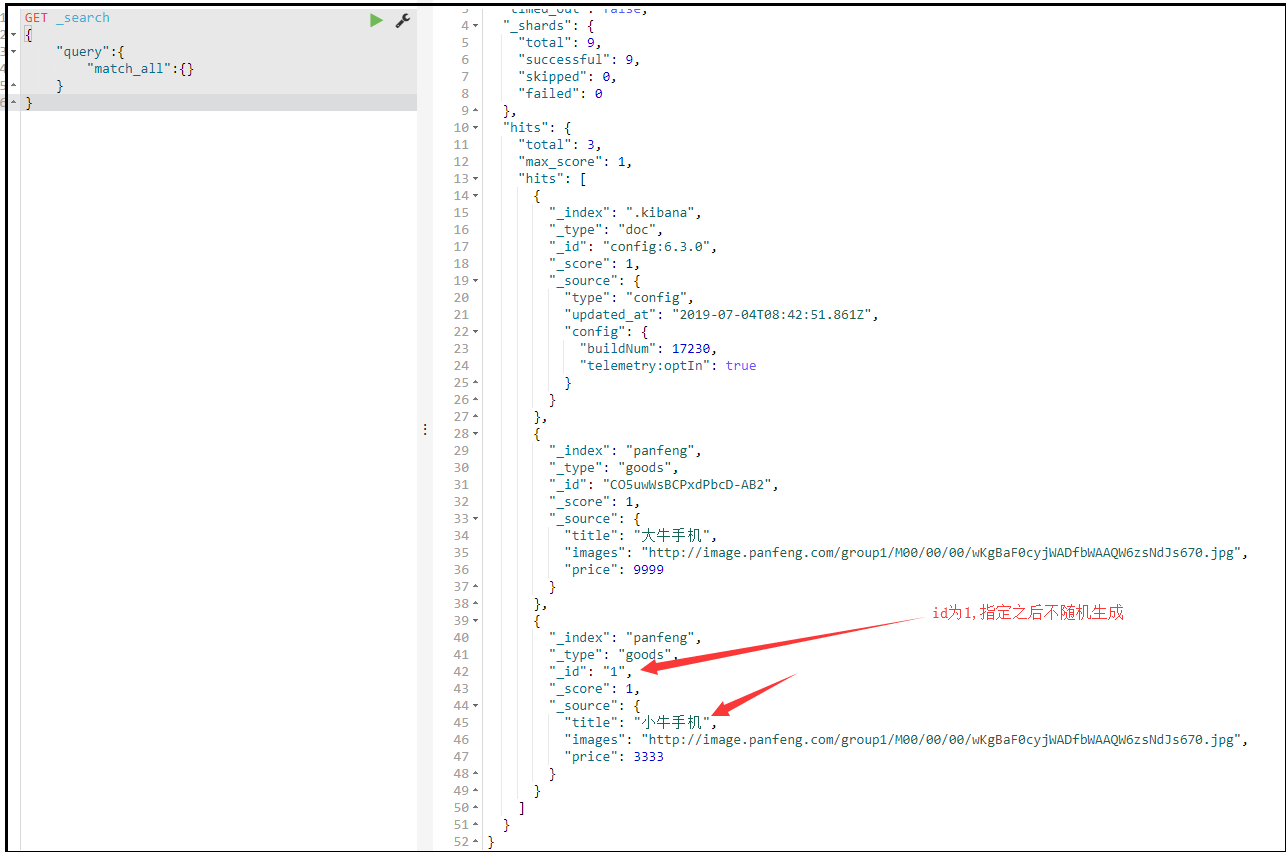
-
添加字段,修改数据
修改必须指定id, - id对应文档存在,则修改 - id对应文档不存在,则新增
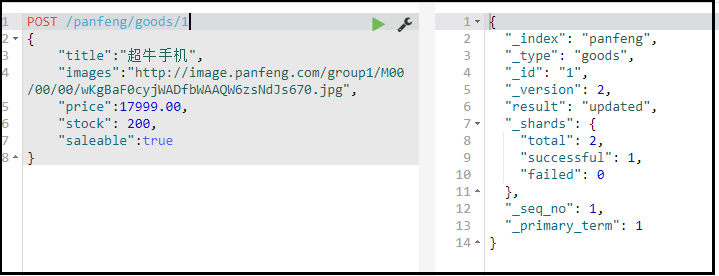
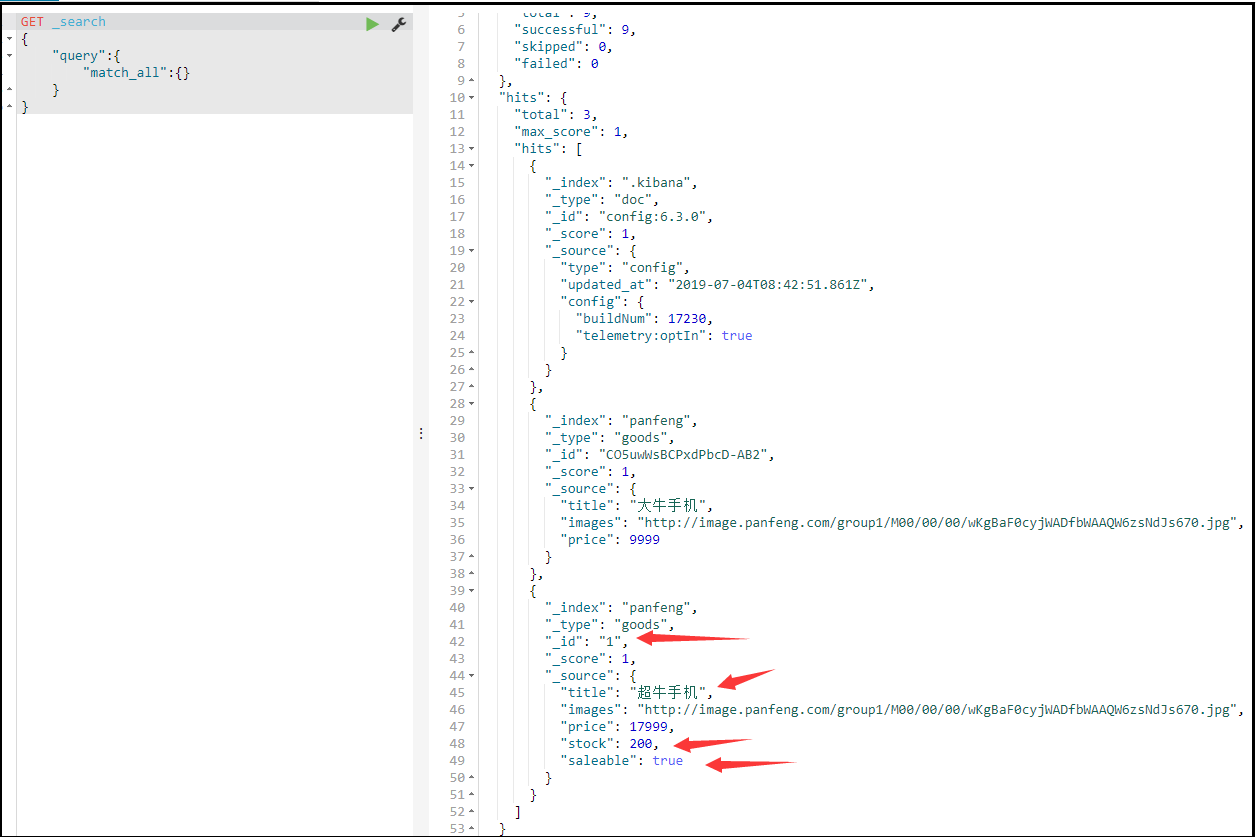
-
删除数据
DELETE /索引库名/类型名/id值

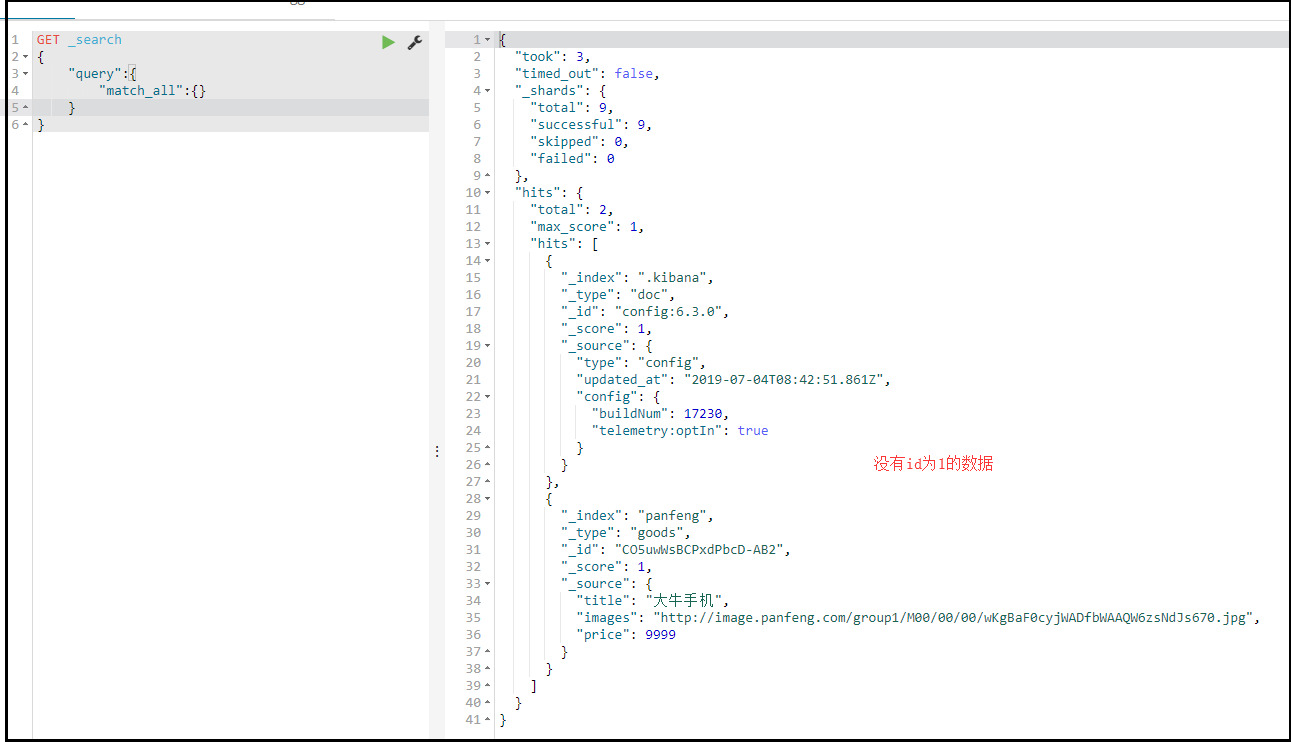
-
-
*查询
-
基本查询
-
基本语法
GET /索引库名/_search { "query":{ "查询类型":{ "查询条件":"查询条件值" } } }
查询类型为 match_all , match , multi_match , term , terms -
查询所有 match_all
GET /heima/_search { "query":{ "match_all": {} } }
query:代表查询对象 match_all:代表查询所有
-
匹配查询 match
匹配查询 match查询"title"内容有"大牛"的数据 GET /panfeng/_search { "query":{ "match": { "title": "大牛" } } } or关系,查询"title"内容有"大牛"或"手机"的数据,因为分词器会分词 GET /panfeng/_search { "query":{ "match": { "title": "大牛手机" } } } and关系,查询"title"内容有"大牛"并且也含有"手机"的数据,因为分词器会分词 GET /panfeng/_search { "query":{ "match": { "title": { "query": "大牛手机", "operator": "and" } } } } "大牛手机"可以分词"大牛","手机"两个词,匹配任何一个都可以,如果把1改为3不匹配任何 GET /panfeng/_search { "query":{ "match":{ "title":{ "query":"大牛手机", "minimum_should_match": 1 } } } } "大牛智能手机"可以分词"大牛","智能","手机"三个词 最小匹配3x0.66=1.98,因为1.98<2,所以能匹配三个当中任何一个词都可以 GET /panfeng/_search { "query":{ "match":{ "title":{ "query":"大牛智能手机", "minimum_should_match": "66%" } } } } "大牛智能手机"可以分词"大牛","智能","手机"三个词 最小匹配3x0.67=2.01,因为2.01>2,所以能匹配三个当中任何两个词都可以 GET /panfeng/_search { "query":{ "match":{ "title":{ "query":"大牛智能手机", "minimum_should_match": "67%" } } } }
-
多字段查询 multi_match
多字段查询 multi_match可以匹配字段"title"或"name" 内容为"大牛"的数据 GET /panfeng/_search { "query":{ "multi_match": { "query": "大牛", "fields": [ "title", "name" ] } } }
-
词条查询 term
词条查询 term在"title"中,可以匹配到词为"大牛"的数据 GET /panfeng/_search { "query":{ "term":{ "title": { "value": "大牛" } } } } 因为"大牛手机"不是一个词,所以也无法匹配到title中含有"大牛手机"的数据 因为"快快乐乐"是一个词,所以可以匹配到title中含有"快快乐乐"的数据 GET /panfeng/_search { "query":{ "term":{ "title": { "value": "大牛手机" } } } }
-
多词条精确查询 terms
多词条精确查询 terms只能匹配到title中含有"大牛"的数据,因为"大牛"是一个词,而"二蛋"不是一个词 如果换成"title": ["大牛","牛牛"],则就可以匹配到title中含有"大牛"或"牛牛"的数据 GET /panfeng/_search { "query":{ "terms":{ "title": ["大牛","二蛋"] } } }
-
-
_source过滤
-
直接指定字段
直接指定字段在查询结果的_source中只显示字段"title","price" GET /panfeng/_search { "_source": ["title","price"], "query": { "term": { "title": { "value": "大牛" } } } }
-
指定includes和excludes
指定includes和excludesincludes:来指定想要显示的字段 GET /panfeng/_search { "_source": { "includes":["title","price"] }, "query": { "term": { "title": "大牛" } } } excludes:来指定不想要显示的字段 GET /panfeng/_search { "_source": { "excludes":["title","price"] }, "query": { "term": { "title": "大牛" } } }
-
-
结果过滤
-
布尔组合 bool
"bool"把各种其它查询通过"must"与,"must_not"非,"should"或 的方式进行组合查询title为手机,price为2222或者3333的数据 GET panfeng/_search { "query": { "bool": { "must": [ { "match": { "title": "手机" } }, { "terms": { "price": ["2222","3333"] } } ] } } } title不为大牛并且价格不为2222或3333的数据 GET panfeng/_search { "query": { "bool": { "must_not": [ { "match": { "title": "大牛" } }, { "terms": { "price": ["2222","3333"] } } ] } } } title为大牛或者price为2222或3333的数据 GET panfeng/_search { "query": { "bool": { "should": [ { "match": { "title": "大牛" } }, { "terms": { "price": ["2222","3333"] } } ] } } }
-
范围查询
在range中 gt:大于 gte:大于等于 lt:小于 lte:小于等于在range中 gt:大于 gte:大于等于 lt:小于 lte:小于等于 大于 greater than 小于 less than 等于 equal 查询价格大于等于3.01小于5.01的数据,不可以匹配3,可以匹配3.01,可以匹配5,不可以匹配5.01 GET /panfeng/_search { "query":{ "range": { "price": { "gte": 3.01, "lt": 5.01 } } } }
-
模糊查询
-
-
高级查询
-
排序
-
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
-
1
