
mysql记录
1、背景
因工作需要,需要系统学习mysql,之后mysql学习的总结将会在这篇博客中
2、知识积累
-
关于索引的知识
在mysql学习过程中,少不了关于索引的知识,索引背后的原理其实是新增了一张索引表,如果说创建一个用户表,表结构如下:
create table SUser(
`ID` bigint primary key auto_increment not null comment '主键ID', #注意大家在写sql时一定要添加comment信息,方便后期维护
`email` varchar(64) comment '用户邮箱'
);
在如上sql中我们插入一万条数据,sql如下:
DELIMITER $$
DROP PROCEDURE IF EXISTS `proc_auto_insertdata`$$
CREATE PROCEDURE `proc_auto_insertdata`()
BEGIN
DECLARE init_data INTEGER DEFAULT 1;
WHILE init_data <= 10000 DO
INSERT INTO SUser VALUES(init_data, CONCAT(init_data,'@qq.com'));
SET init_data = init_data + 1;
END WHILE;
END$$
DELIMITER ;
CALL proc_auto_insertdata();
接下来我们开始进行实验,如果不添加索引的情况,查看email=5000@qq.com的这条用户信息需要执行多少次,并查看他的执行时长

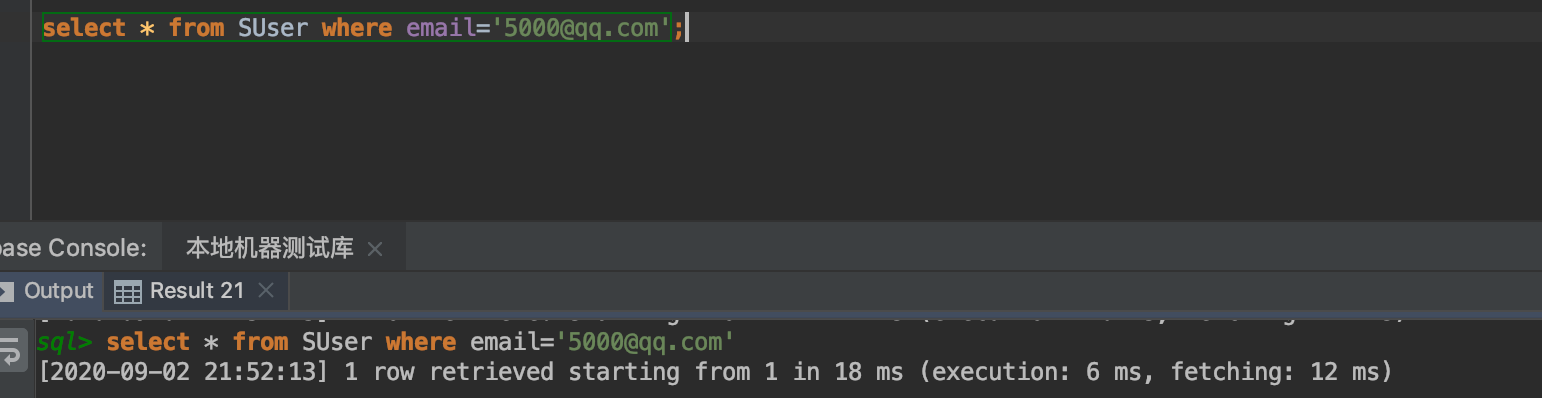
从上图看,检索了10172行(为什么不是10000行,因为explain是个估算值,不是准确值),执行花了18ms。
如果我们添加索引之后执行呢
alter table SUser add index index1(email);

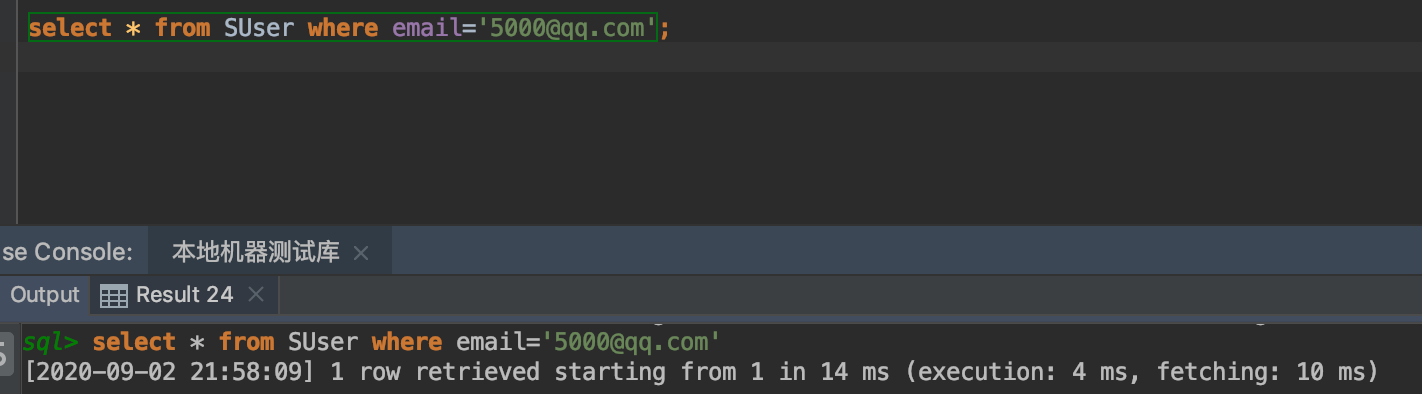
从执行结果看,检索行数变为了1行,时间从18ms变为了14ms,时间为什么不是除以10000(10000行变为1行),原因是从磁盘读取1行和10000行都只需要发生一次IO,一次IO大概是10ms左右,也就是说为什么不是10000倍的关系,但是当数据量特别大,再百万级别或者更多时,这种索引是非常有效的。
-
关于另外一种索引
从上面看给添加email的索引后能加快查询速度,我们也知道添加索引其实是新增了一个表,这个表的key是email,value是id,现在我们的key是email的全部,意味着要占用空间,那有什么办法减少空间的占用吗,有,我们按照如下去新增索引
alter table SUser add index index1(email(4))
我发现email中只有前4个字符不一样,比如从1到10000@qq.com,其中@qq.com是一样的,于是我只取前4位作为索引值也是可以的,那我们怎么判断需要取多少位呢,可以通过下面的语句判断
select count(distinct left(email,4)) as L4,count(distinct left(email,3)) as L3 from SUser;
可以查看左边3个总共有多少行数据,原则就是取覆盖到95%以上的数据就ok了
