UI自动化(selenium)
自动化框架介绍
这套框架依赖浏览器驱动(webdriver)操作浏览器,通过selenium库操作该驱动,然后通过unittest运行用例。
框架搭建
安装驱动
-
首先下载自己浏览器对应版本的驱动,不然驱动操作不了浏览器,这个网上到处都有
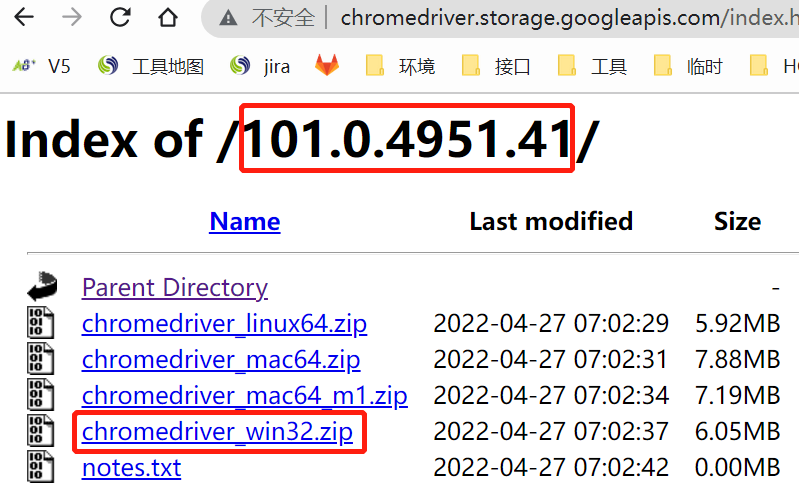
-
下载好了就把解压的驱动程序放到python安装文件中(因为python路径已经添加到环境变量了,所以放这儿也能被系统识别,而selenium能调用系统中的浏览器驱动)
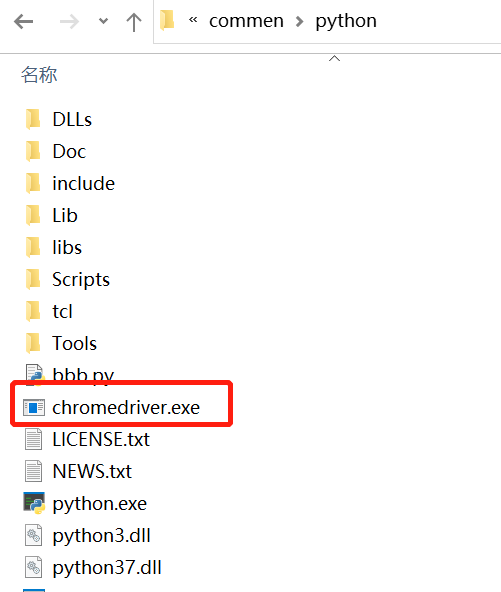
驱动传导
-
一个用例第一步是打开浏览器窗口,方法是
driver1 = webdriver.Chrome(),所以我们应该把该方法放到basecase类中,这样每个用例类都能继承该方法打开浏览器,又因为basecase类中的setup方法是每个用例都需要执行的,那将driver1 = webdriver.Chrome()放入setup方法中就显得水到渠成了。但将驱动driver放入用例basecase类中,页面类却无法继承,也就使用不到driver的元素查找、页面事件等方法,所以这个时候可以在basepage类用构造函数传入driver:
def __init__(self, driver): self.driver = driver在写继承了该构造函数的页面类方法的时候就可以使用这个事实上还没传入的虚假的driver的元素查找、页面事件等方法,但实际用例中传入的是用例类的正真的driver(需注意,打开浏览器和返回的driver是两回事,前者一个用例只打开一次,后者会在页面元素查找、事件中反复使用)。
页面层
-
说明:
一个页面做一个py文件,定义页面中的元素操作、url等,是用例最基本单元。页面中涉及的共同的一些方法可以放到basepage中,比如跳转页面、弹窗操作、传入驱动的构造函数等。 -
basepage类:
class BasePage: def __init__(self, driver): self.driver = driver # 驱动传入构造函数,继承页面类实例化需传入driver def open(self, page): # 打开url:根据传入的page类名,跳转到该页面 self.driver.get(page.url) # 该页面需要有url属性 def find_element(self, locator): # 查找元素简化方法 return self.driver.find_element(*locator) -
页面类:继承父类的方法
from selenium.webdriver.common.by import By from pages.base_page import BasePage class LoginPage(BasePage): """ 定义登录页面: - 页面地址 - 页面元素定位器 - 页面元素事件 """ url = "https://te****8.com/login/" username_locator = (By.ID, "login_loginName") password_locator = (By.ID, "login_password") submit_locator = (By.XPATH, '//*[text()="登录"]/..') # ..表示父节点 agree_locator = (By.CSS_SELECTOR, "input[type=checkbox]") def submit(self): """ 点击登录按钮 """ self.find_element(self.submit_locator).click() def username(self, username): """ 输入用户名 """ self.driver.find_element(*self.username_locator).send_keys(username) def password(self, password): """ 输入密码 """ self.driver.find_element(*self.password_locator).send_keys(password) def login(self, username, password): """ 输入用户名密码登录 """ self.username(username) self.password(password) self.submit()
用例层
-
说明
当我们写好页面,就可以写用例了。用例核心是unittest类,该类可以对其类下的所有方法进行执行。其中setup方法在一个用例类中首先执行,最后是teardown方法。还有一种在所有用例类前执行的暂不介绍。 -
basecase类:
import unittest from time import sleep from selenium import webdriver class BaseCase(unittest.TestCase): """ 1. BaseCase继承unittest,unittest的作用是只要执行该类,就会把类中的方法都执行一次 2. 普通case继承BaseCase,也就有了unittest的执行方式 3. 普通case继承BaseCase,也就继承了setUp和tearDown方法,所以也能执行 4. setUp和tearDown主要放和一条用例相关的方法和属性 """ def setUp(self) -> None: driver1 = webdriver.Chrome() # 打开浏览器 driver1.maximize_window() driver1.implicitly_wait(5) self.driver = driver1 # 这里设置类属性driver def tearDown(self) -> None: sleep(1) self.driver.quit() # 关闭浏览器 -
用例类:
整个类作为一类测试,比如都是测登录,类中的方法是一个个用例# 导入页面 from pages.login_page import LoginPage from pages.udc_apps_page import UdcAppsPage # 导入BaseCase from cases.base_case import BaseCase from time import sleep class TestNewApp(BaseCase): # 继承BaseCase """ 验证新建应用 """ def test_new_app(self): """ 新建应用 """ # 登录 user_login = LoginPage(self.driver) user_login.open(user_login) # 跳转到登录页 user_login.login("xiaobai", "12345678") sleep(1) # 新建应用 user_createApp = UdcAppsPage(self.driver) user_createApp.open(user_createApp) # 跳转到应用管理页 user_createApp.new_app_button() user_createApp.new_app_name() user_createApp.new_app_code() user_createApp.new_app_sure() -
用例执行流程:
当我们在用例页面右键执行用例类的时候,因为用例类继承了BaseCase类,而BaseCase类继承了Unittest类,所以用例类具备Unittest类的特性,即右键可对类进行执行。此外,Unittest类会优先执行类中的setup方法,也即打开浏览器并设置驱动属性,然后在无序执行类中的其他方法,最后执行teardown方法关闭浏览器。 -
用例调试补充:
如果我们用的是pycharm写代码,一般每个用例方法旁边有个小播放按钮可以进行单个用例的执行,便于调试。如果是vscode则没有,具体调试参看博主Arlick的文章。
其他层
runner层
-
说明:
上面我们可以右键对单独一个用例类进行执行,但是如果我们是有很多用例类,那就需要一个专门识别这些用例类(py文件)进行统一执行的方法。unittest有一个根据路径查可执行unittest类的方法,通过三方库HTMLTestRunnerCN可对unittest查询到的用例进行执行并生成报告。 -
报告优化三方库:可执行用例并生成报告
首先下载三方库:https://gitee.com/taokara/HTMLTestRunnerCN
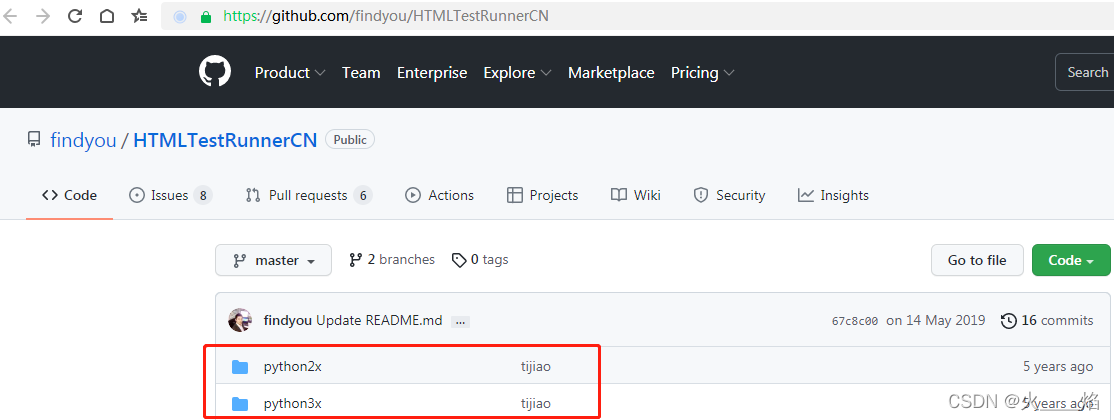
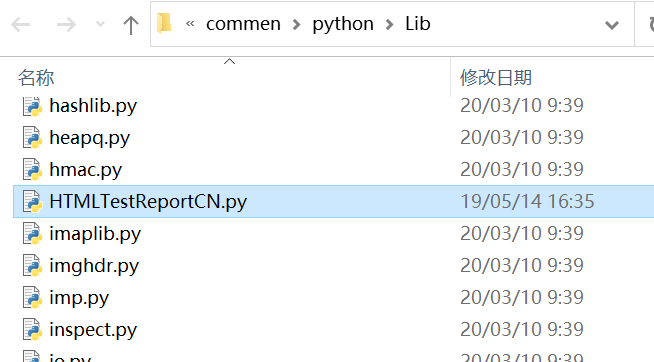
然后把对应版本的三方库放到python安装lib下面:就可以直接在项目中使用了
-
runner方法:
import unittest import time # 这个就是我们刚才下载的三方库 from HTMLTestReportCN import HTMLTestRunner suites = unittest.defaultTestLoader.discover("../cases/","test*.py") # 调用unittest的地址寻找用例方法 now = time.strftime("%Y-%m-%d %H-%M-%S") report_name = "../report/crm_report_{}.html".format(now) f = open(report_name,"wb") runner = HTMLTestRunner(stream=f,title="V8_UDC测试报告",description="这是LIJUNLONG的测试报告") # 使用报告优化三方库 runner.run(suites) # 通过三方库执行unittest找到的用例
report层
- 通过上面的runner层,我们可以看到执行后html报告需要一个地址存放,这个文件夹就是report层。
data层
- 事实上,我们的数据其实也需要专门的包来存放,这一层就是数据层。
其他层
- 有的项目还会把一些三方平台接口和工具放一层tools层,我暂时没这么做直接放到basepage里面了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号