
卷积神经网络
卷积的含义
- 说明:卷积神经网络的基础就是卷积公式,所以我们要先理解卷积公式。
- 卷积公式:含义是
f(x)函数和g(t-x)这两个函数在0到t区间积分,也就是所有乘积加起来
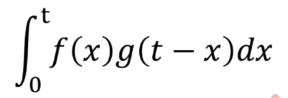
怎么理解这个公式呢?我们假设想知道一个人的某个时刻胃里有多少食物n,有两个影响因素,一是他吃的情况,二是他消化情况,这两个函数分别用f(x)和g(x)表示,假设这个时刻是t,f(x)就表示在吃这个函数上x这个点吃了多少,g(x)表示在t时刻消化了多少,那这个x就应该写成t-x,表示t到x这段时间,也就是x时刻吃下的到t时刻消化了多少。可以想象g(t-x)是一个1到0随时间递减的函数,那么x时刻吃下的东西到t时刻就还有f(x)·g(t-x)。积分就是所有时刻的加起来,不细说了。
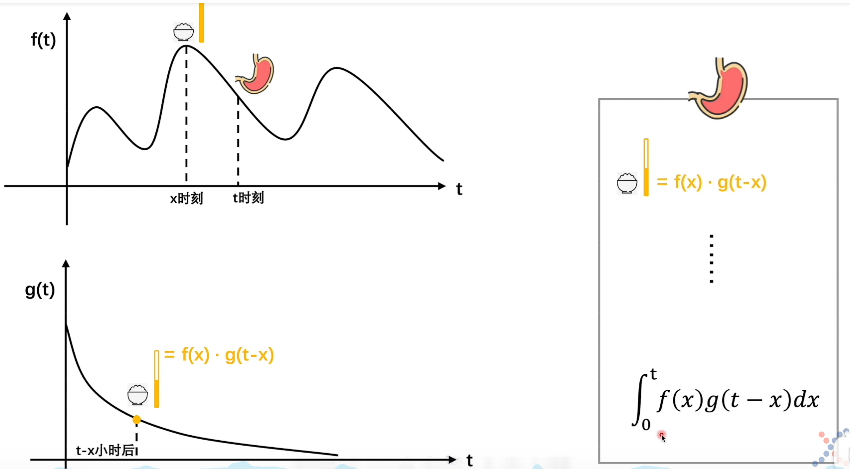
视频版解释:https://www.bilibili.com/video/BV1VV411478E
至于为什么叫卷积,因为f(x)和g(t-x)相乘,但在x轴上的位置是反着的,如果把一对对f(x)和g(t-x)用线连起来,看起来就有点卷的形象了。

- 总结:卷积可以理解成在某个时刻或者位置,函数
f(x)经受g(x)变化,得到一个累加结果。这个f(x)可以是随时间的变化,也可以是受空间的变化,既可以连续也可以是离散的点。
平滑卷积
- 说明:
- 首先图像处理对象是点,也就是点
(x,y),其次是通过该像素周围像素来处理目标像素。这里周围像素就可以理解成f(x),怎么处理用g(x)。 - 通常我们只取目标像素周围一圈像素即可,不然计算量过大。
- 所谓平滑卷积,就是指将一个图像的噪点去掉,因为我们知道,大多数图像像素过渡都是平滑的,不会突兀,当存在一个像素和周围像素差异过大,大概率是噪点,那这个时候我们就可以根据周围像素的颜色的影响(取中值、平均值等方式)来改变噪点的颜色,使得图像更加柔和无噪点。
- 首先图像处理对象是点,也就是点
- 实例:

如图所示,中心像素相当于是t时刻(位置),经受周围一圈f(x)影响,影响函数是g(x),t位置像素得到的一个结果。由于是像素,替换x成x,y,且假设目标像素是f(x,y),周围一圈像素就可以如图表示(离散点,一格设为1)。
这个g(x)也是离散点且是一个固定值函数(数值是由f(x)和g(t-x)变量相加等于t得到的),因为离散点,不用积分符号,用求和符号,然后这个函数展开就有:
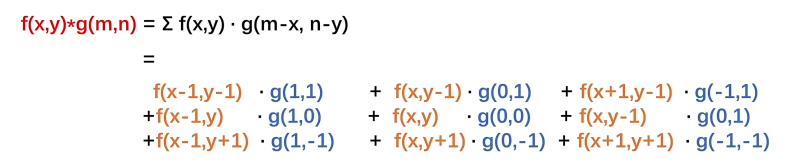
卷积核:
- 说明:
- 刚才我们说的这个
g(x,y)矩阵就是一个卷积核,叫平滑卷积核,它完全符合我们在卷积那里的总结。 - 但事实上我们知道平滑卷积核是周围一圈像素对中心像素的影响,但我们如果不想考虑一圈的影响,只想考虑上面、下面或者左右的影响,那就不是平滑卷积核了,而是垂直边界过滤器和水平边界过滤器。

- 再进一步,如果我们只考虑左斜向的三个像素,那我们还能把斜线过滤出来。到这,我们可以总结卷积核的本质,就是还是对
f(x),即图像的影响,这个影响即是选择。 - 举个例子,比如要识别手写的
X,那么我们分别用左右斜线过滤器和斜线交叉过滤器就能过滤出这个手写X的特征。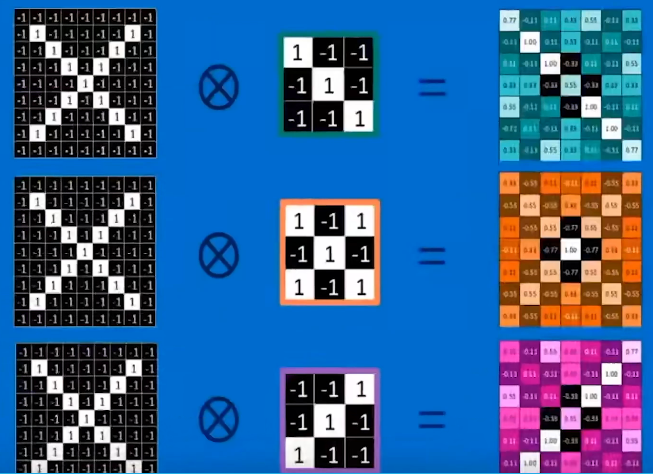
- 刚才我们说的这个
感知机:
- 说明:
- 通过卷积提取了数据特征,下面我们就需要处理数据了,神经网络最基本的处理单元叫感知机
- 单个感知机只能进行二分处理
- 感知机相对普通的一元方程优点在于它适用于任意一元情况
- 感知机的结构(公式):上面说到感知机只能处理二分问题,那肯定就有两个内容,一个是分割线(面),二一个就是判断目标数据是在线(面)的上面还是下面。感知机公式如下:
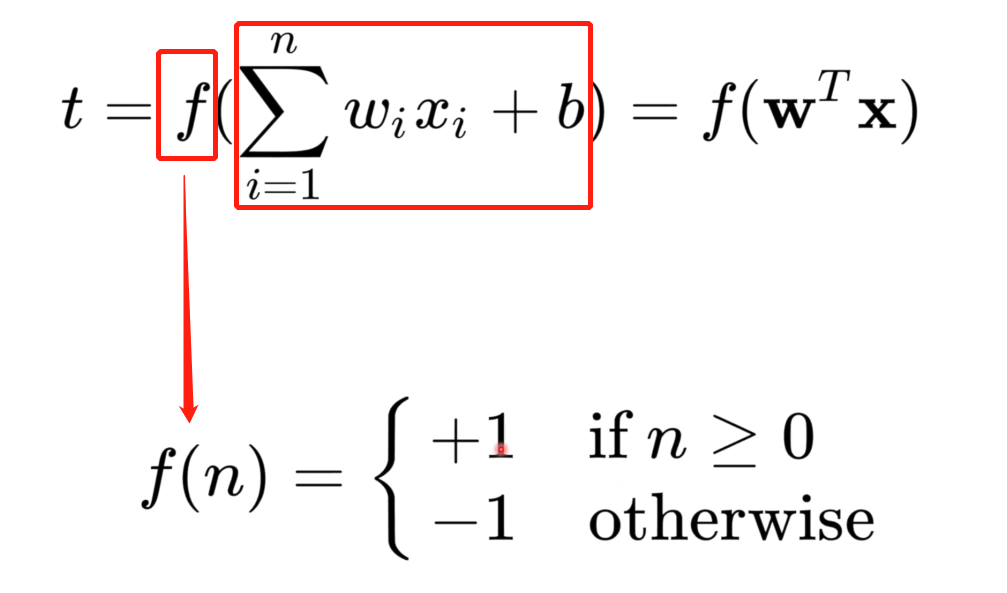
公式t包含两个部分,一个是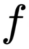 ,一个是
,一个是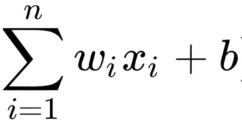 ,我们先说后面这个求和的部分,我们知道,二分可以是线和面或者高维面,但公式都类似如下:
,我们先说后面这个求和的部分,我们知道,二分可以是线和面或者高维面,但公式都类似如下:

如果维度更高,就要写成:不同下角标的W代表上面的x、y、z,通过求和符合,可以缩写成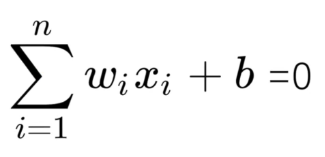 ,至于为什么要写成这样,完全是因为这样看起来简洁。
,至于为什么要写成这样,完全是因为这样看起来简洁。
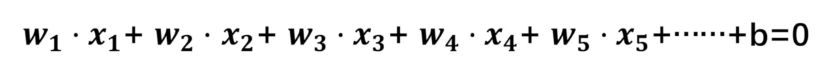
至于为什么公式t没有0,因为0表示线(面)上,而感知机是划分线(面)上或下,所以不需要0,但这里就引出了判定上还是下的函数,即感知机的激活函数,其实也很简单,就是把0替换成+1或者-1,公式上面有展示,不赘述。
当然,也可以写成矩阵的形式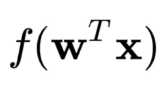 ,这个公式展开如下:
,这个公式展开如下:
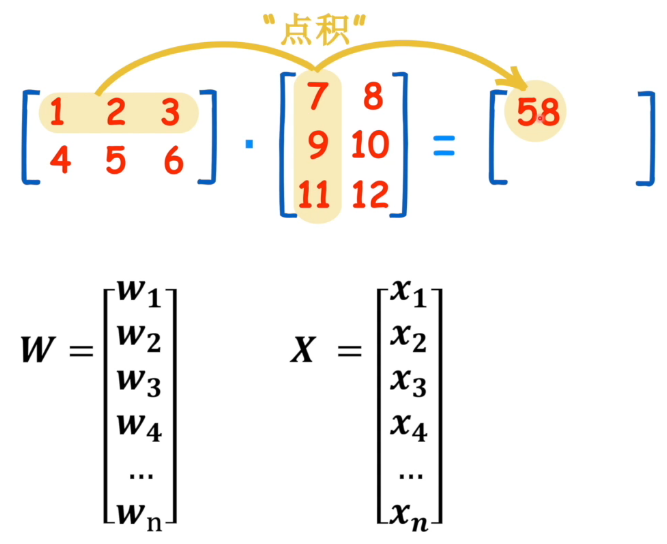
公式中的W和X分别是两个矩阵,他们的点积就正好变成上面提到的多元方程,但是矩阵的点积方向不横着的,所以需要T这个变换符号改变W矩阵的方向。
那多元方程中的b去哪了呢?应该是把X矩阵中的一个元素换成了常量b了,可以不展示。
至于为什么用矩阵,还是为了简化公式。 - 单个感知机的缺陷:感知机说白了就是一条线(面)二分数据,但
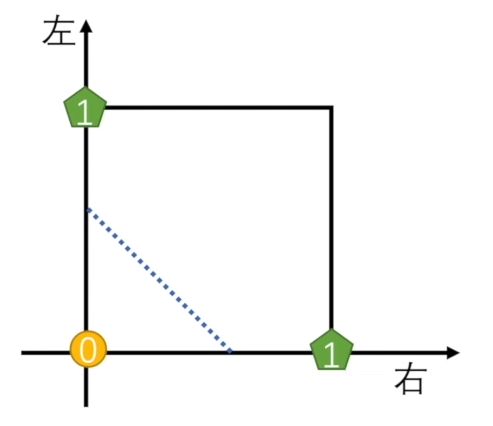
亦或不能通过一条线区分数据(黄色和绿色点表示不同数据)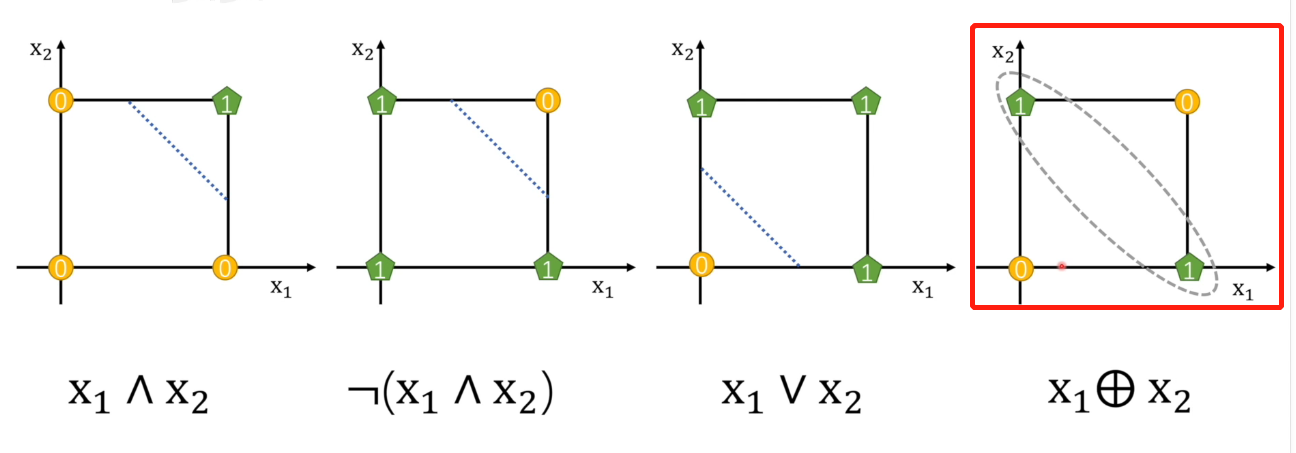
- 解决单个感知机的方法:多层(个)感知机
亦或问题是单个感知机无法解决的,首先我们了解亦或的定义:即X1和X2有且仅有一个为真,两者亦或运算值为真。
这里分两种情况,第一种是X1为真,X2为假,还有一种情况是相反的,所以用符号表示就是:
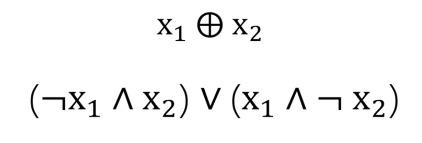
首先我们要明白,这些与或非亦或都是逻辑运算,也就是只要逻辑上通了就行,既然上面展开式就是一假一真或者一真一假结果都是真,那前两个就能分别先用感知机先得到结果,然后再用或逻辑符号(感知机)链接二者即可。注意体会这个是逻辑运算,而不坐标,坐标只是为了体现在图像上:
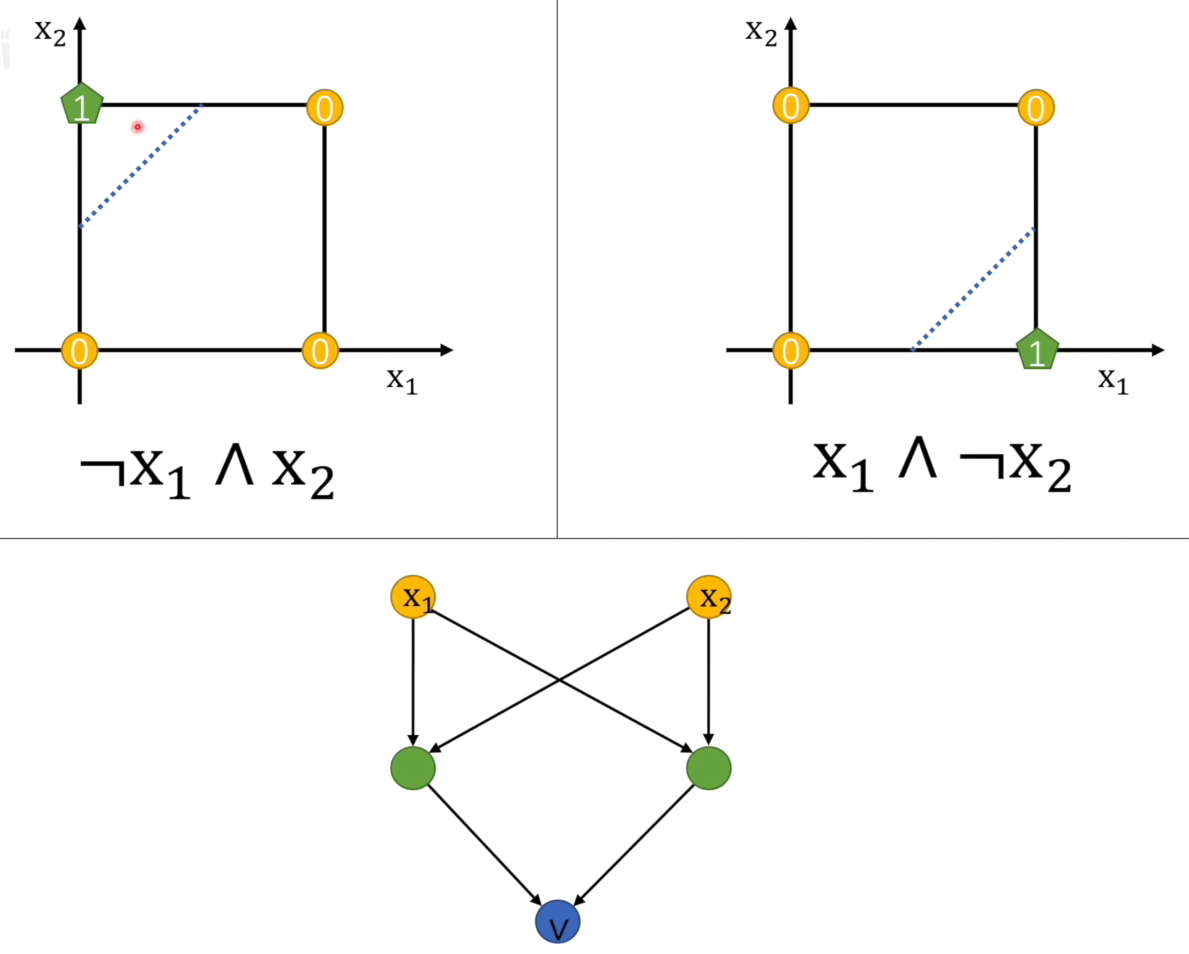
简单理解就是有且仅有一个真才会为真,否者是假。所以图中假设X1和X1都是真,那么连个绿色节点都是假,蓝色节点自然也是假,如果X1为真,X2为假,这两个数据都会分别送到绿色节点判断,所以都是真,经过或运算,所以蓝色节点也是真。
要注意的是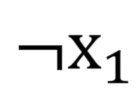 表示假,不是把
表示假,不是把X1变成假。此外我们会发现两个绿色节点必然是一样的结果,要么都是真,要么都是假,不存在一真一假,因为输入是相同的。因此,真真和假假结果都是假,所以实际在绿色节点就只有三种情况的输入,那蓝色节点就变成线性可分了:本质貌似将一个复杂的条件套条件的判断分解成最基础的判断,最后层层舍弃直到最后一层判断
激活函数:
- 说明:
我们知道,一个感知机包含一个线性函数和一个激活函数,而上面说到的激活函数只是简单的判断(01越阶函数),这里换成了sigmoid函数(上图是sgmoid,下图是01越阶函数)

为什么要替换激活函数?首先我们要理解神经网络的结构,上面讲的亦或其实就是一个简单的神经网络(两层),而判断一只猫是不是一只猫,实际上是个复杂的逻辑,我们需要判断很多东西,比如它的耳朵、胡子、体型等等实际上这就是一个,判断出的胡子有要和判断出的耳朵进行进一步的判断,依次判断最后是不是猫,但是我们如果每次都只是判断是或者不是,就会导致结果在判断中损失,什么意思呢?比如上一个节点都判断出具有胡子,那显然两只猫图片可能有一只的更像是真的,有一个不一定,这样都变成具有胡子,那结果会很差,下一步对胡子眼睛的判断就没有很好的输入数据了,如果是sgmoid这种阈值型的函数,就能将结果迭代下去,形成影响累加效果,这样我们就能通过一次次的调整阈值,实现神经网络的迭代了(当然,训练的时候是以你自己为标准,就是你打了标签的那些数据)。这里有个问题,就是sgmoid怎么来的?为什么是它而不是其他有斜率的函数?
损失函数:
-
说明:
上面说到我们打标签作为标准和神经网络计算出来的进行比较,那这个比较就是损失函数,一般有最小二乘法和极大似然估计两种方法。 -
最小二乘法:
我们最能想到的,就是把我们给出的判断(0或者1),和计算出来的值相减的绝对值,越小说明越接近。但是绝对值不适合计算,所以开个平方,由于有很多图片,需要累加,就有:
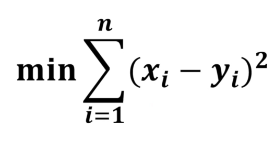
这个方法由于后面进行梯度下降不方便(函数存在多个极值,容易陷入局部解),不建议使用。 -
极大似然估计
假设有10张猫图片要判断,其中我们认定6张是猫,4张不是猫,其实我们脑子中就有一个判断猫的模型,这个模型确定了我们选出猫来的概率。然后我们让机器也来算,直到它的模型能接近我们的模型。
所谓似然函数就是在已知实验结果的情况下推测概率。如果知道概率预测实验结果就是概率函数。显然我们是在知道实验结果的情况下推测脑中的概率。
我们知道判断一个图片是不是猫,对我们人而言只有是或者不是两种情况,这就类似抛硬币。抛一次硬币,总的概率是1,正面概率是P的话,那反面一定是1-P,如果抛n次硬币(x次正面),那就符合二项分布
每一次则是符合伯努利分布,将n替换成1
由于抛一次,x只能是一次正面或者一次反面,所以x如果是1,概率就是p,如果是0,概率就是1-p。
上面说到硬币,这个硬币可能有损坏,所以P不等于1/2。那具体的概率是多少,我们只能通过实验结果来推测,如果10次硬币,3次是上,7次下,我们更相信正面向上的概率是1/3,而不是1/2这个经验。而所谓的极大似然值,其实就是求上面伯努利函数最大值。需要注意的是,由于神经网络对于每张图的判断,概率不等,所以不能认为是二项分布,二项分布的前提是p是相同的。
所以对多个图片的判断就有
简化一下就有
由于连乘不好算,通过取对数变成连加(取对数不改变函数单调性,所有最大值的位置不变),其实在这里就可以求到最大似然值了,但一般求最小比较便捷,所以往往会这前面加个负号求他的最小值
仔细思考最上面那个连乘的函数,因为每个感知机对事物的判断一次就相当于是一次硬币,概率上面是x和1-x实际就是选择到底是p还是1-p,也就是我们的判断决定到底是p还是1-p,也就是直接把是或者不是的概率留下来,这就等于说是每个感知机的p才是最终决定这个函数值的唯一核心,而p就是由感知机里的w和b决定的。
现在来看王木头说的,多个感知机对人脑模型的模拟,其实就是指的是各个感知的概率连乘起来的总感觉的最大值就是要接近人脑对多个
梯度下降
- 说明:
我们知道,一个感知机的多元函数(含w和b)计算得到的结果,经过激活函数(sigmoid)变成0-1之间的数值,这个数值只是其中一个感知机的,多个感知机的值通过极大似然估计变成一个值,这个值即是一层感知机对下一层某一个感知机的输出a,最后层层计算得到最后的输出J,这个J和我们的标签有个差值。
当然,我们要开启下一轮学习计算,首先需要调整各个感知机的系数,一种直觉的方式是我们得到J后,按照它下面一层的感知机的贡献大小来规定他改变值的大小,然后下面一层也是,层层传下去,然后感知机再安装这个改变层层计算上来。但是实际上科学家用的不是这种简单的加法分配,而是用的向量加法。这里还是假设J是最终输出,这个结果仍然需要往下传递各个感知机改变量的大小,怎么改变呢?我们把J想象成一个有w和b两参数的函数(极大似然函数),也就是一个曲面,而这曲面下降最快的方向是梯度方向(实际上就是斜率最大的方向),梯度即时曲面切面垂直等高线的斜线在平面上的投影的单位向量,向量呢其实就是一个方向。然后在这个平面上,单位向量我们用i和j表示,然后就有向量f(x,y) = aj+bj,a和b就是决定向量在x和y轴上分量的大小,如果我们需要测算下一个点的值,那向量就需要加上对应的向量值,这个即向量的加法,也就是f(x+na,y+nb),这个n也就是步长,即学习率,这个值过大会直接越过曲面顶点,所以要注意。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现