


Redis 数据结构-双向链表
Redis 数据结构-双向链表
最是人间留不住,朱颜辞镜花辞树。
1、简介
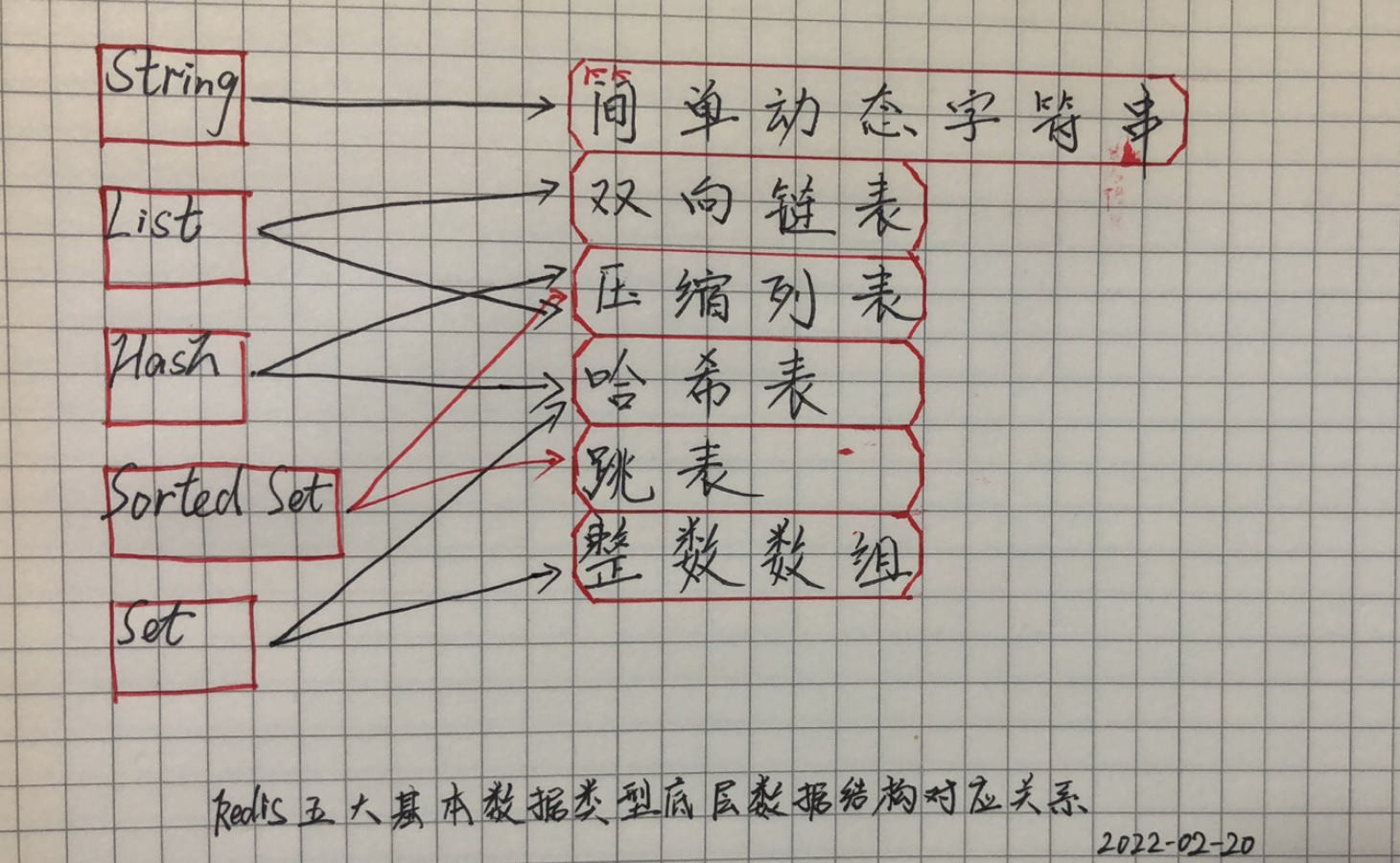
Redis 之所以快主要得益于它的数据结构、操作内存数据库、单线程和多路 I/O 复用模型,进一步窥探下它常见的五种基本数据的底层数据结构。
Redis 常见数据类型对应的的底层数据结构。
- String:简单动态字符串。
- List:双向链表、压缩列表。
- Hash:压缩列表、哈希表。
- Sorted Set:压缩列表、跳表。
- Set:哈希表、整数数组。
2、双向链表
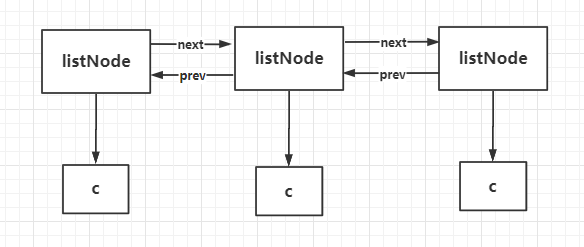
C 语言是没有内置链表这种结构,而当一个列表键包含较多的元素,或者列表中包含的元素都是比较长的字符串的时,Redis 就会使用链表作为 list 的底层实现,就自己实现了双向链表,相当于Java 语言中的LinkedList,但又不完全是。
单纯的链表优缺点:
- 双向链表数据结构,支持前后顺序遍历。
- 不需要连续的的内存空间,插入和删除的时间复杂度是 O(1) 级别的,效率较高。
- 比起数组它的缺点就是查询较慢(时间复杂度O(n))。
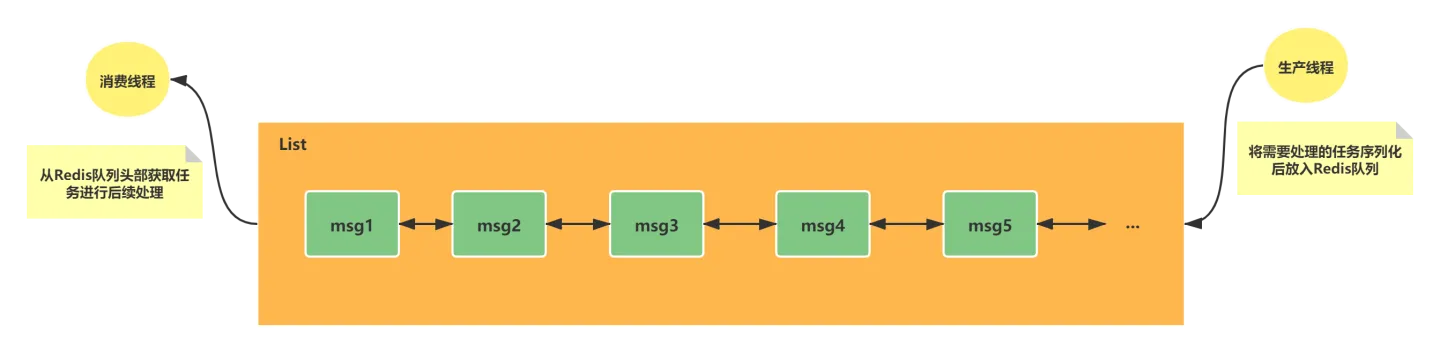
常见使用场景
双向链表的特性经常被用于异步队列的使用。实际开发中将需要延后处理的任务结构体序列化成字符串,放入Redis 的队列中,另一个线程从这个列表中获取数据进行后续的业务逻辑。
链表节点结构
从redis/src/adlist.h 源码文件中查看链表节点结构设计。
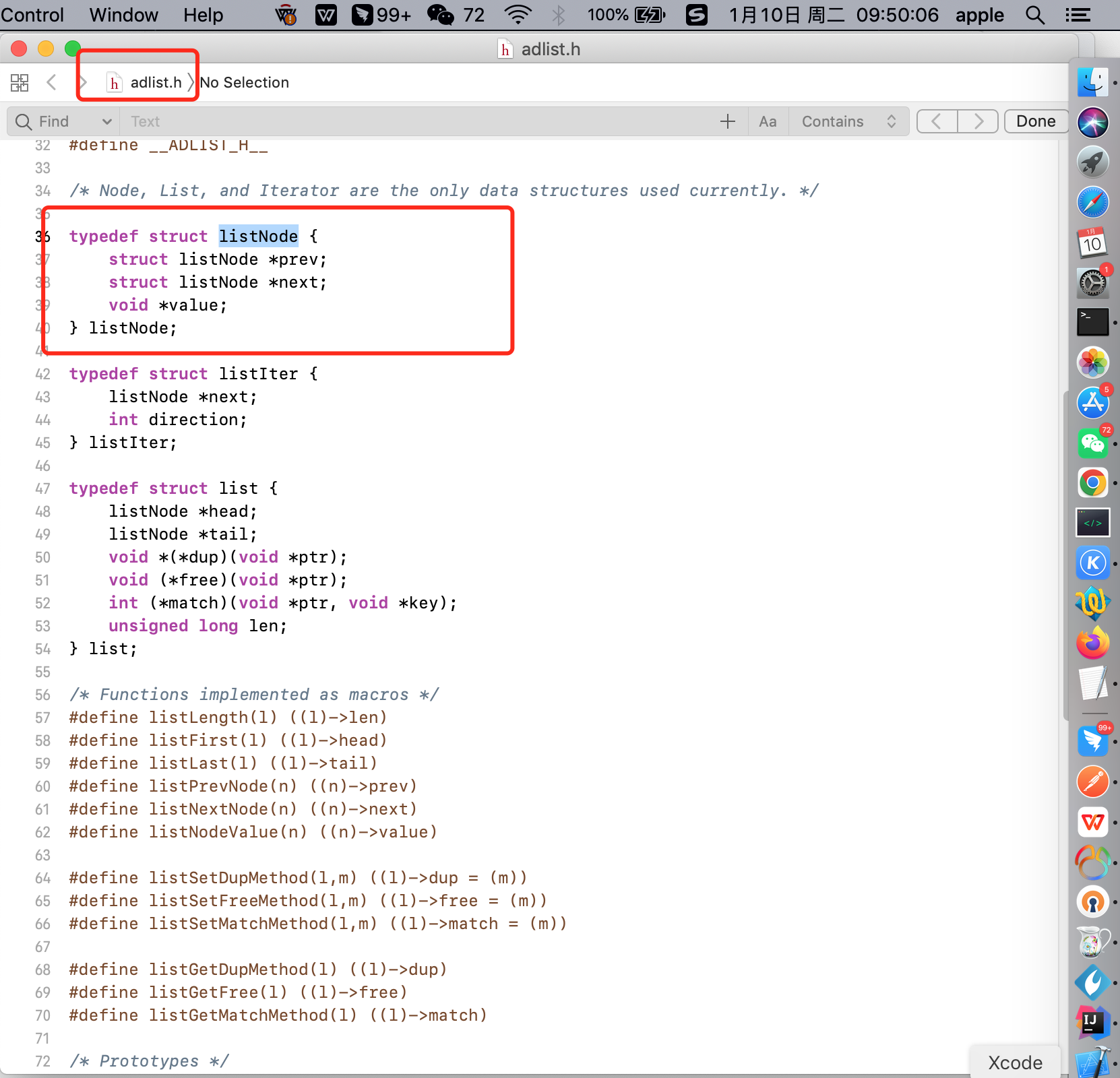
1 typedef struct listNode { 2 struct listNode *prev; // 前置节点,如果是list的头结点,则prev指向NULL 3 struct listNode *next;// 后置节点,如果是list尾部结点,则next指向NULL 4 void *value; // 记录该节点的值,能够存放任何信息(也叫万能节点) 5 } listNode;
从listNode 结构中看到一个节点由头指针 prev 、尾指针 next 以及节点的值 value 组成,这种有前置节点和后置节点很明显就是一个双向链表。
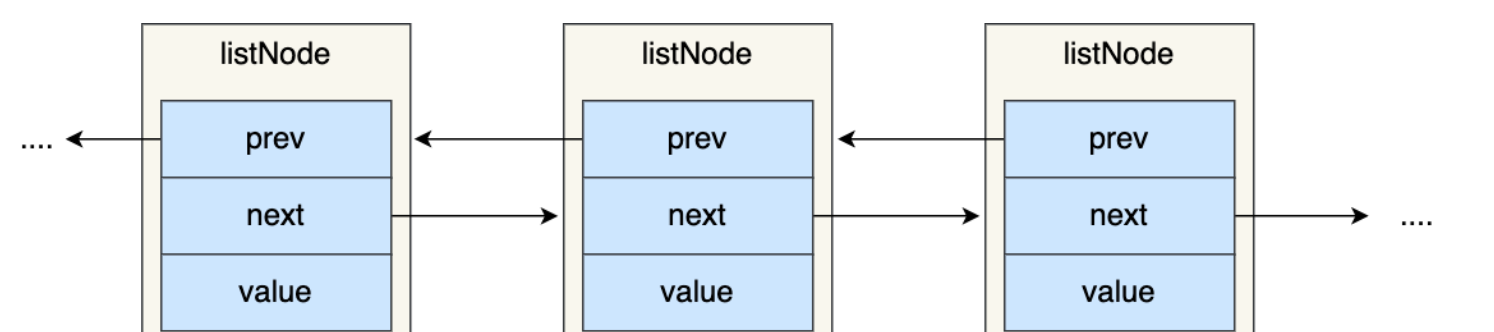
链表结构
为了方便操作,Redis 在 listNode 链表节点结构体基础上又封装了 list 这个数据结构,而且封装之后,还提供了头节点、尾节点以及一些自定义的函数。链表结构如下:
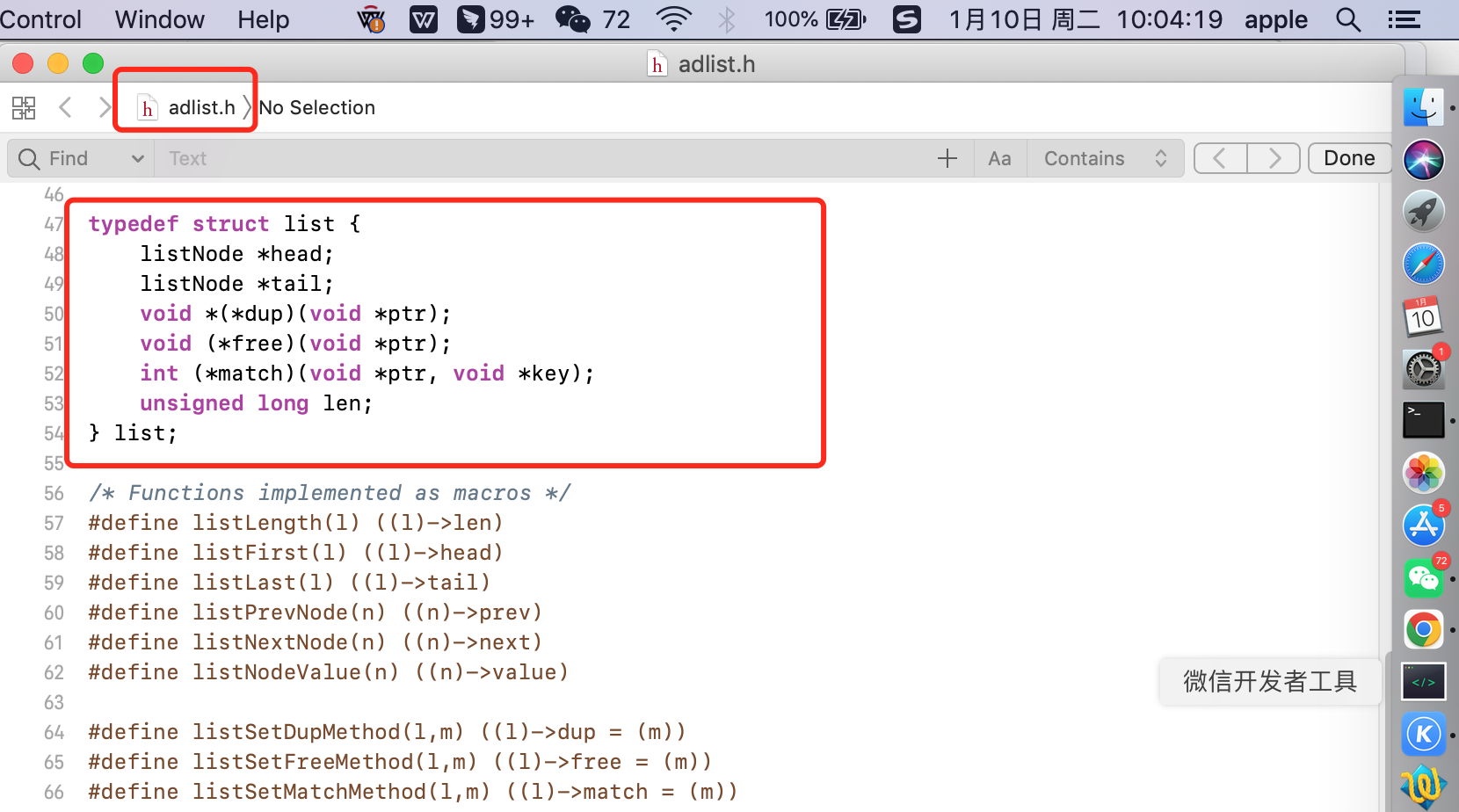
1 typedef struct list { 2 listNode *head; // 链表 头结点 指针 3 listNode *tail; // 链表 尾结点 指针 4 unsigned long len; // 链表长度计数器 即 节点的个数 5 6 // 三个函数指针 7 void *(*dup)(void *ptr); // 复制函数 复制链表节点保存的值 8 void (*free)(void *ptr); // 释放函数 释放链表节点保存的值 9 int (*match)(void *ptr, void *key); // 匹配函数 查找节点时使用 比较链表节点所保存的节点值和另一个输入的值是否相等 10 } list;
list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
- head:链表 头结点 指针,指向了双向链表的最开始的一个节点;
- tail:链表 尾结点 指针,指向了双向链表的最后一个节点;
- len:代表了双向链表节点的数量;
- dup:复制函数,用于复制双向链表节点所保存的值;
- free:释放函数,用于释放双向链表节点所保存的值;
- match:匹配函数,用于对比双向链表节点所保存的值和另外一个的输入值是否相等。
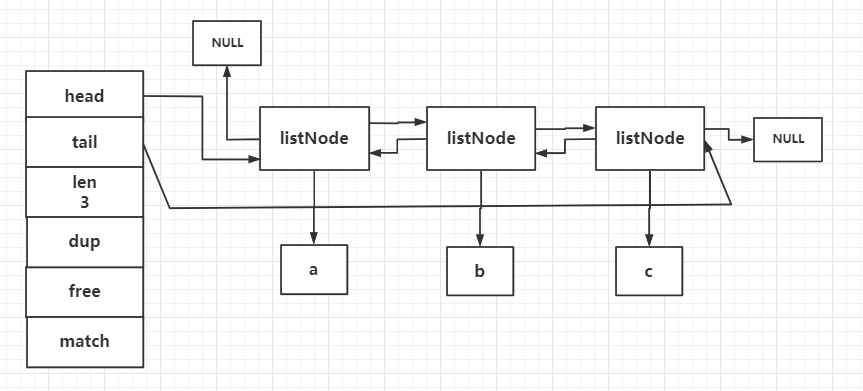
相关命令
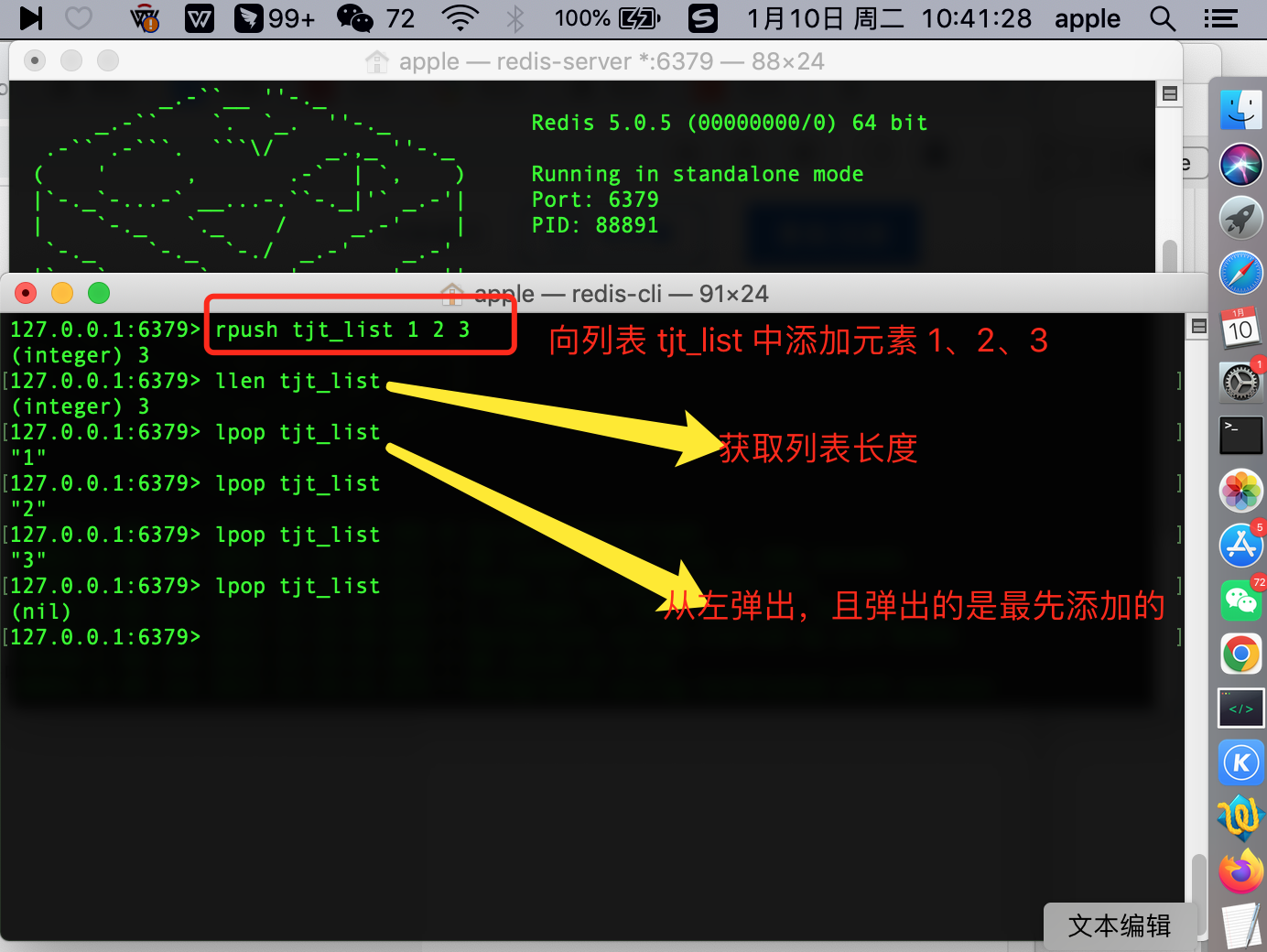
右进左出(队列)
队列在结构上是先进先出(FIFO)的数据结构(比如排队购票的顺序),常见场景如消息排队、异步处理等,用于确保元素的访问顺序。
lpush -> 从左边边添加元素
127.0.0.1:6379> lpush tjt_list 1 2 3
rpush -> 从右边添加元素
127.0.0.1:6379> rpush tjt_list 1 2 3
llen -> 获取列表的长度
127.0.0.1:6379> llen tjt_list
lpop -> 从左边弹出元素
127.0.0.1:6379> lpop tjt_list
右进右出(栈)
栈在结构上是先进后出(FILO)的数据结构(比如弹夹压入子弹,子弹被射击出去的顺序就是栈),这种数据结构一般用来处理一些逆序输出的业务场景。
lpush -> 从左边边添加元素
127.0.0.1:6379> lpush tjt_list 1 2 3
rpush -> 从右边添加元素
127.0.0.1:6379> rpush tjt_list 1 2 3
rpop -> 从右边弹出元素
127.0.0.1:6379> rpop tjt_list
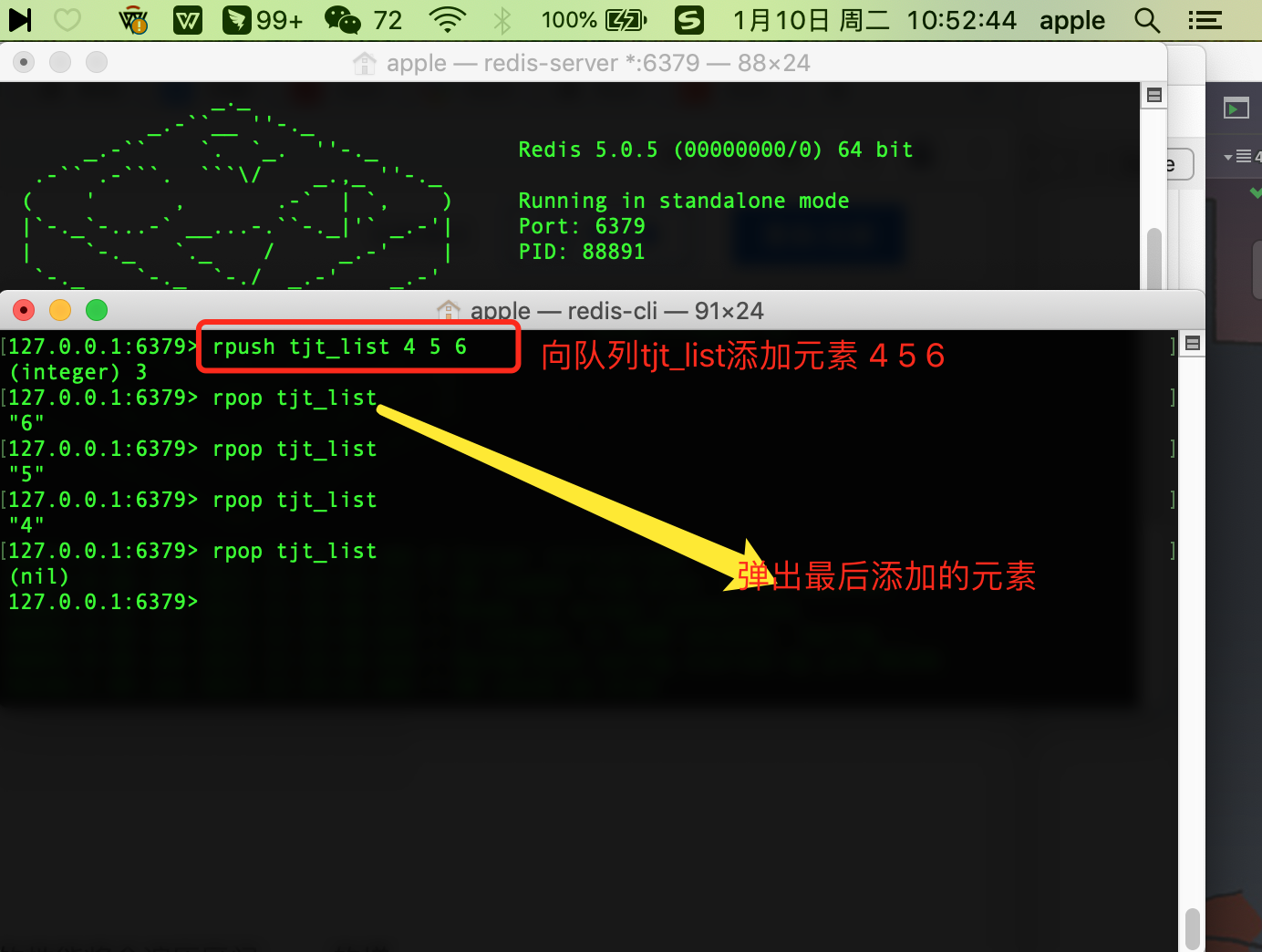
慢操作
由于列表(list)的链表数据结构,它的遍历是慢操作,所以涉及到遍历的性能将会随着遍历区间range 的增大而增大。在Redis 链表中,list 的索引运行为负数,-1代表倒数第一个,-2代表倒数第二个,其它同理。
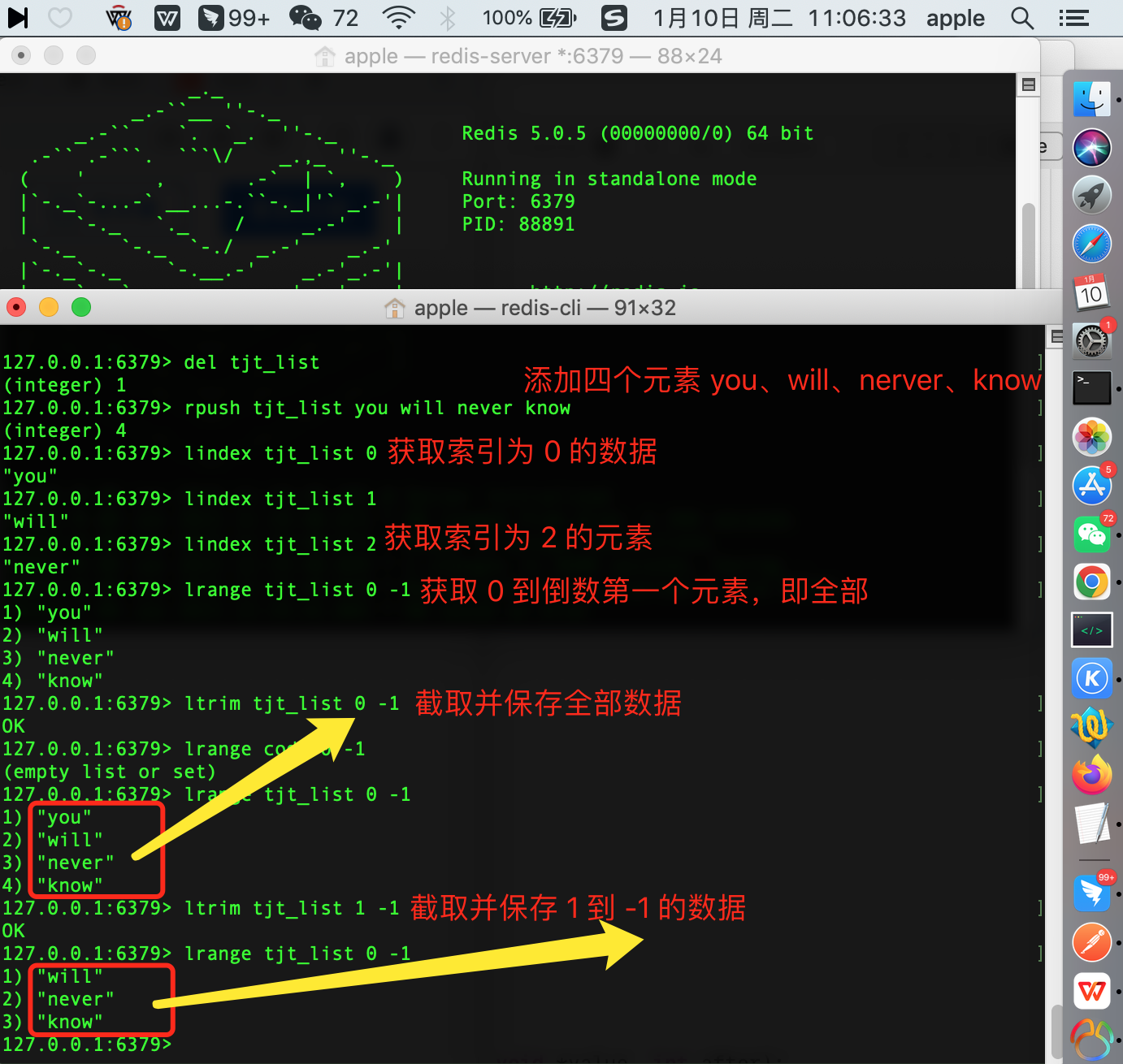
lindex -> 遍历获取列表指定索引处的值(下方所有为 0)
127.0.0.1:6379> lindex tjt_list 0 "you"
lrange -> 获取从索引start 到stop 处的全部值
127.0.0.1:6379> lrange tjt_list 0 -1 1) "you" 2) "will" 3) "never" 4) "know"
ltrim -> 截取并保存索引start 到stop 处的全部值,其它将会被删除
127.0.0.1:6379> ltrim tjt_list 1 -1 OK 127.0.0.1:6379> lrange tjt_list 0 -1 1) "will" 2) "never" 3) "know"
非普通LinkedList
前面提到了Redis 数据类型List 对应的的底层数据结构有 双向链表 和 压缩列表,因为 Redis底层存储list(列表)不是一个简单的LinkedList,而是quicklist 快速列表。
为什么用quicklist 替代LinkedList
普通的LinkedList node节点元素,都会持有一个prev-> 执行前一个node 节点和next-> 指向后一个node 节点的指针(引用),这种结构虽然支持前后顺序遍历,但是也带来了不小的内存开销,如果node 节点仅仅是一个int 类型的值,那么引用的内存比例将会更大。所以Redis 底层对于list(列表)的存储,当元素个数少的时候,它会使用一块连续的内存空间来存储,这样可以减少每个元素增加prev 和next 指针带来的内存消耗,减少内存碎片化问题。
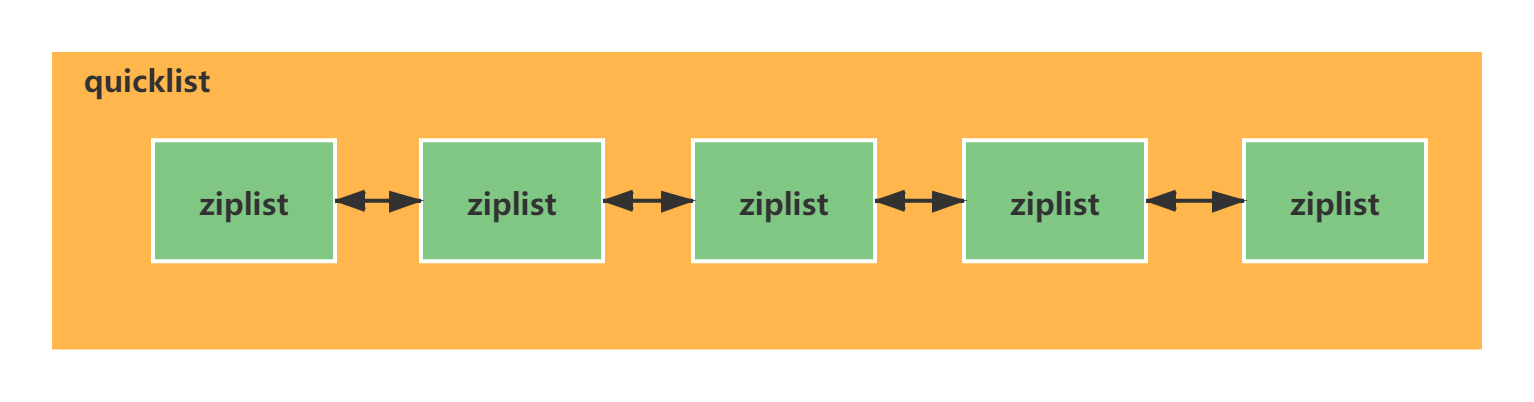
quicklist
quicklist 是多个ziplist (压缩列表)组成的双向列表。
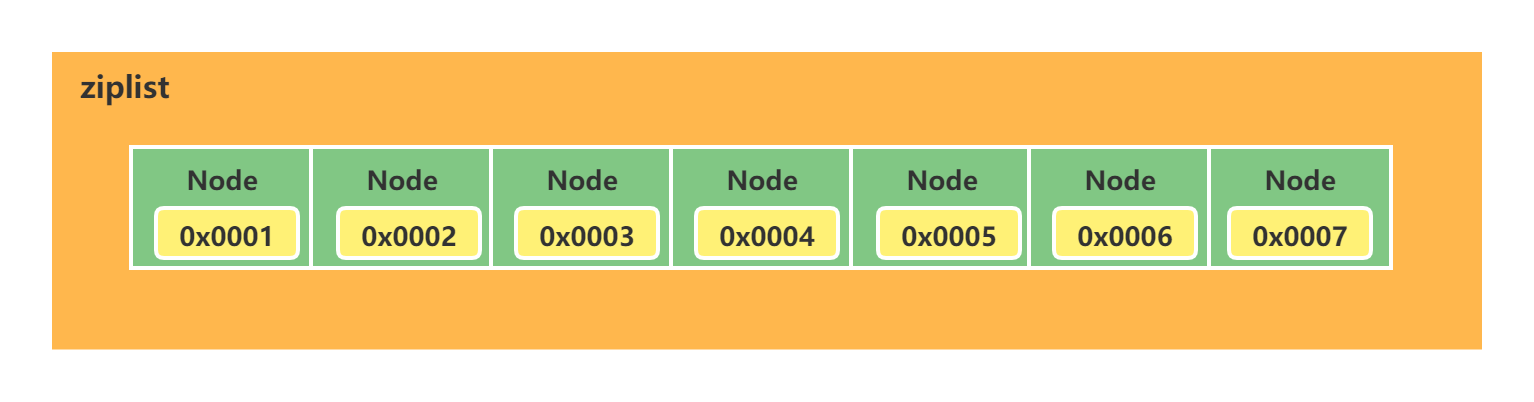
ziplist
ziplist是一块连续的内存地址,他们之间无需持有prev和next指针,能通过地址顺序寻址访问。
3、链表小结
链表优势
- listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表,对双向链表的访问以 NULL 结束;
- list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头、表尾节点的时间复杂度都是 O(1);
- list 结构因为提供了链表节点数量 len,通过 len 属性直接获取节点的数量,时间复杂度为 O(1) , 效率高;
- listNode 链表节使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值。
链表缺陷
- 链表每个节点之间的内存都是不连续的,无法很好利用 CPU 缓存。数组数据结构就能很好利用 CPU 缓存,因为数组的内存是连续的,可以充分利用 CPU 缓存来加速访问。
- 保存一个链表节点的值每次都需要为一个链表节点结构头分配空间,内存开销较大。Redis 3.0 的 List 对象在数据量比较少的情况下,会采用 压缩列表 作为底层数据结构的实现,节省内存空间,降低保存链表节点的内存开销。
